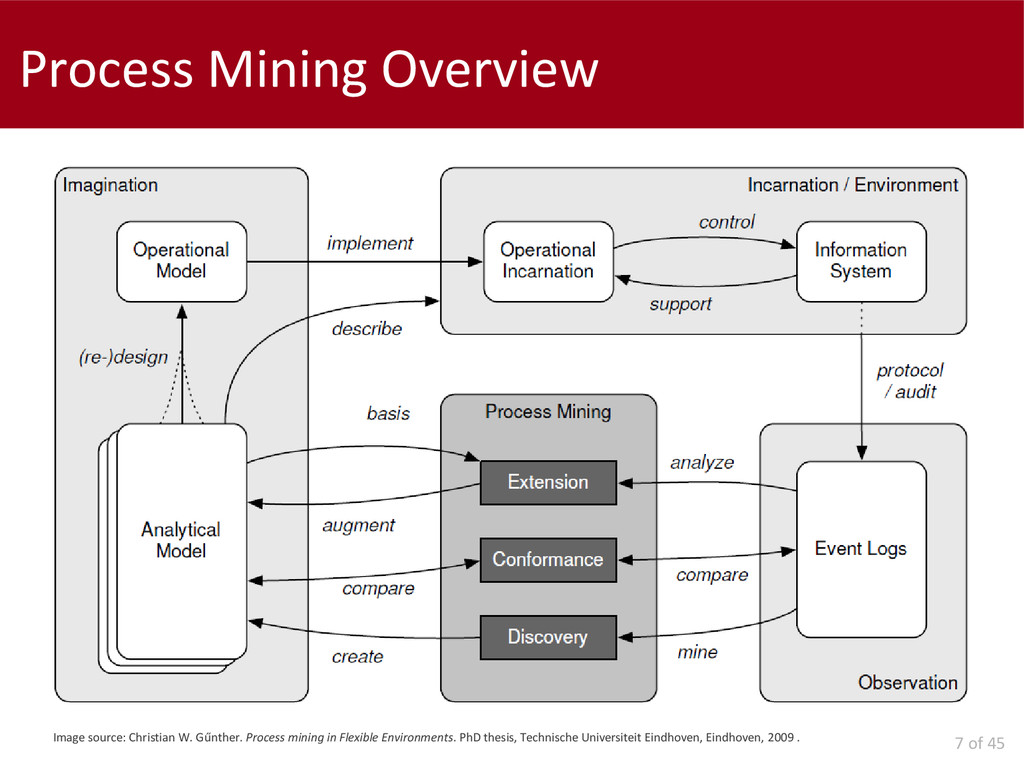
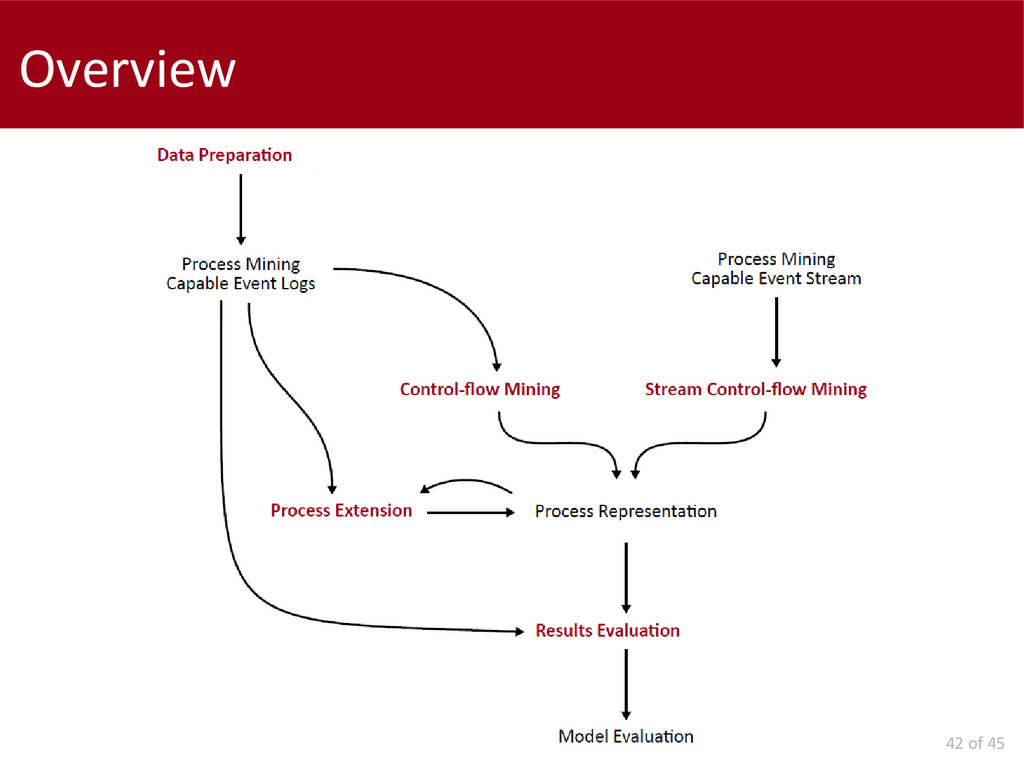
This thesis analyses problems related to the applicability, in business environments, of Process Mining tools and techniques.
The first contribution is a presentation of the state of the art of Process Mining and a characterization of companies, in terms of their "process awareness". The work continues identifying circumstance where problems can emerge: data preparation; actual mining; and results interpretation. Other problems are the configuration of parameters by not-expert users and computational complexity.
We concentrate on two possible scenarios: "batch" and "on-line" Process Mining.
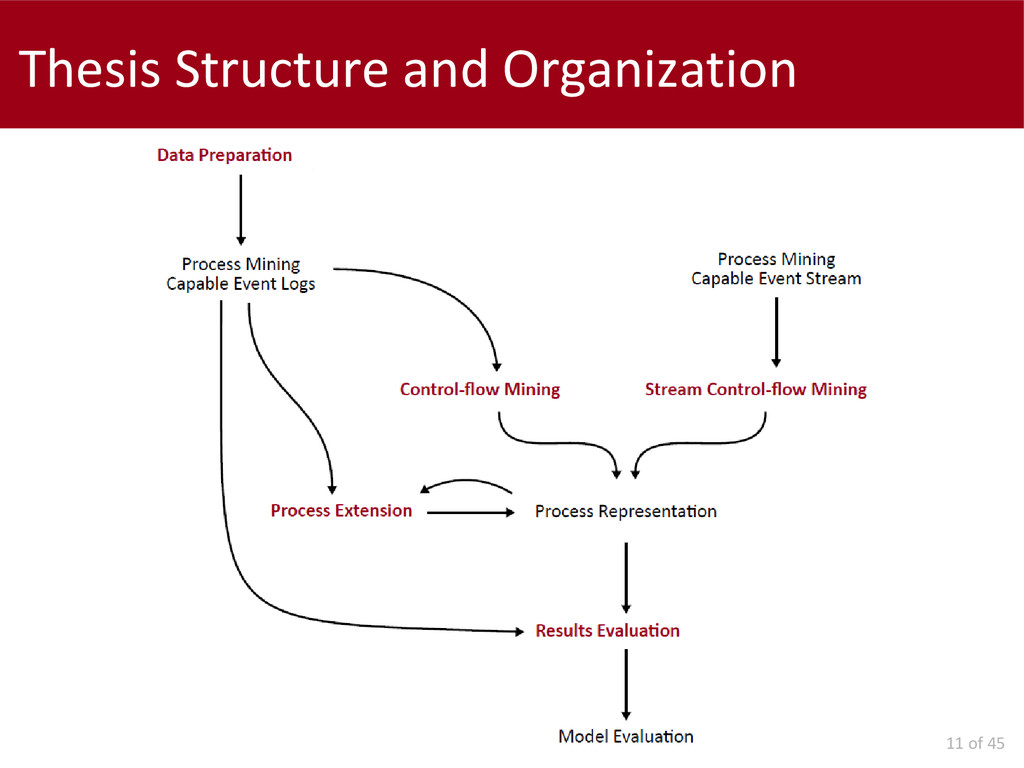
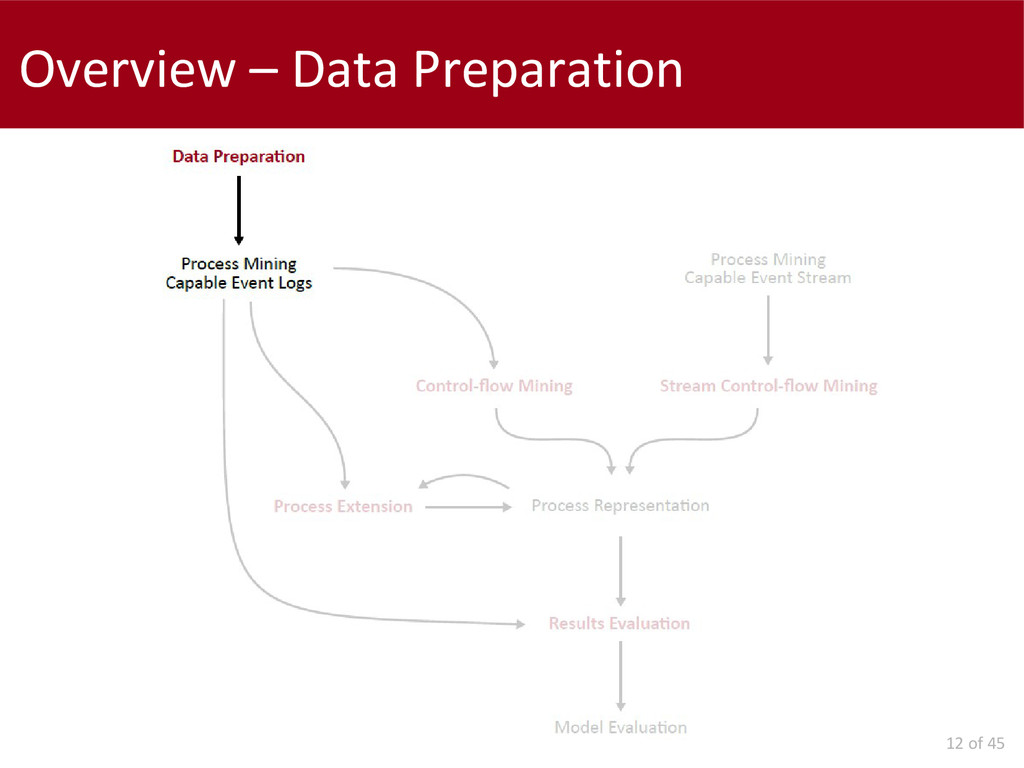
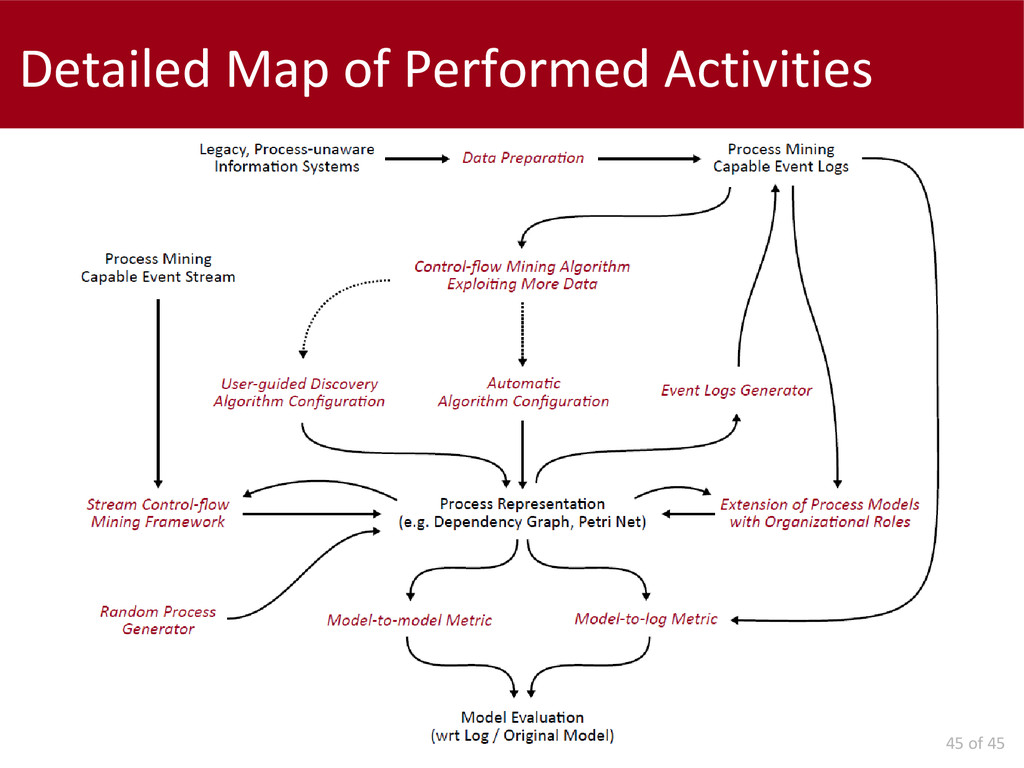
Concerning the batch Process Mining, we first investigated the data preparation problem and we proposed a solution for the identification of the "case-ids" whenever this field is not explicitly indicated.
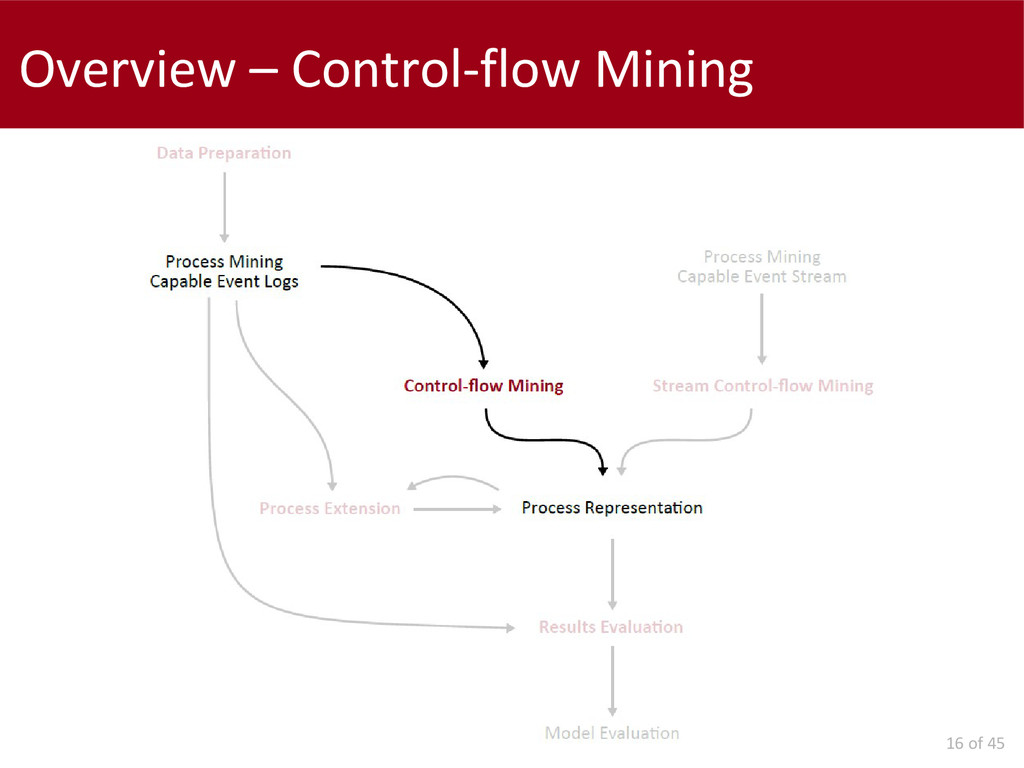
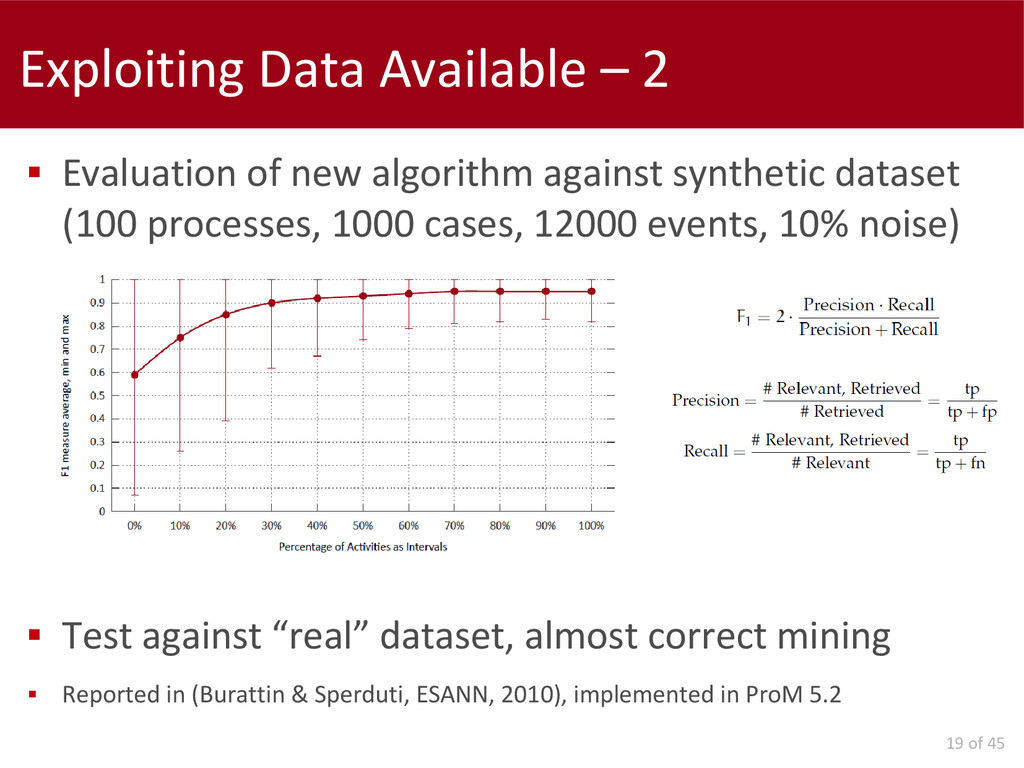
After that, we concentrated on problems at mining time and we propose the generalization of a well-known control-flow discovery algorithm in order to exploit non instantaneous events. The usage of interval-based recording leads to an important improvement of performance.
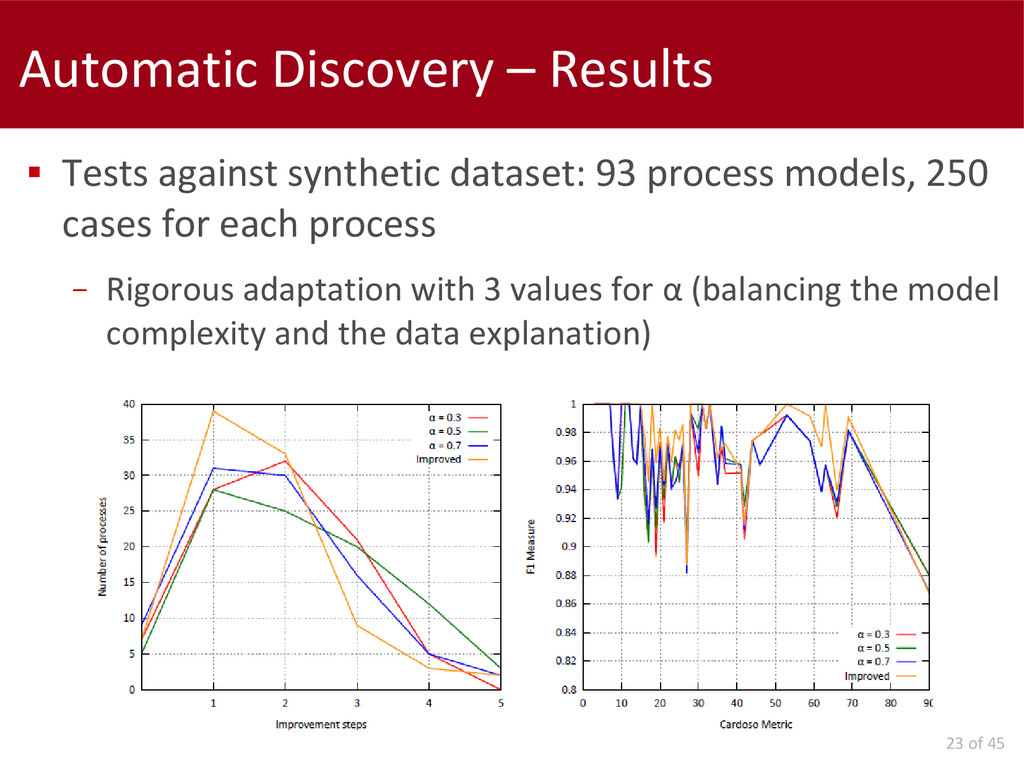
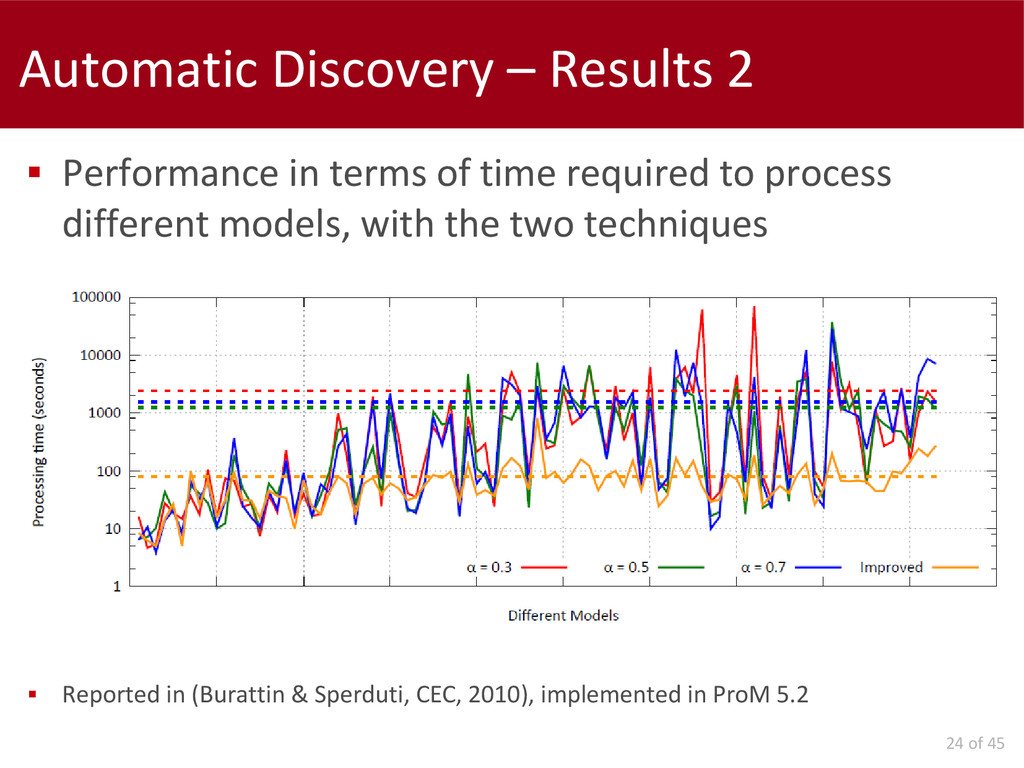
Later on, we report our work on the parameters configuration for not-expert users. We present two approaches to select the "best" parameters configuration: one is completely autonomous; the other requires human interaction to navigate a hierarchy of candidate models.
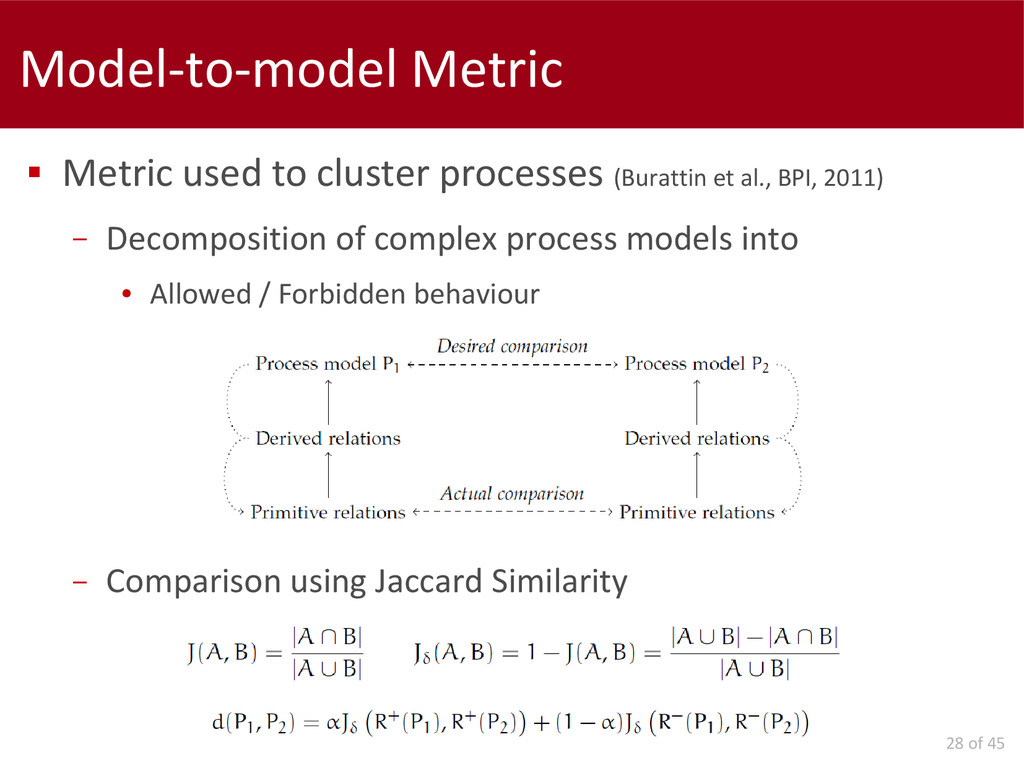
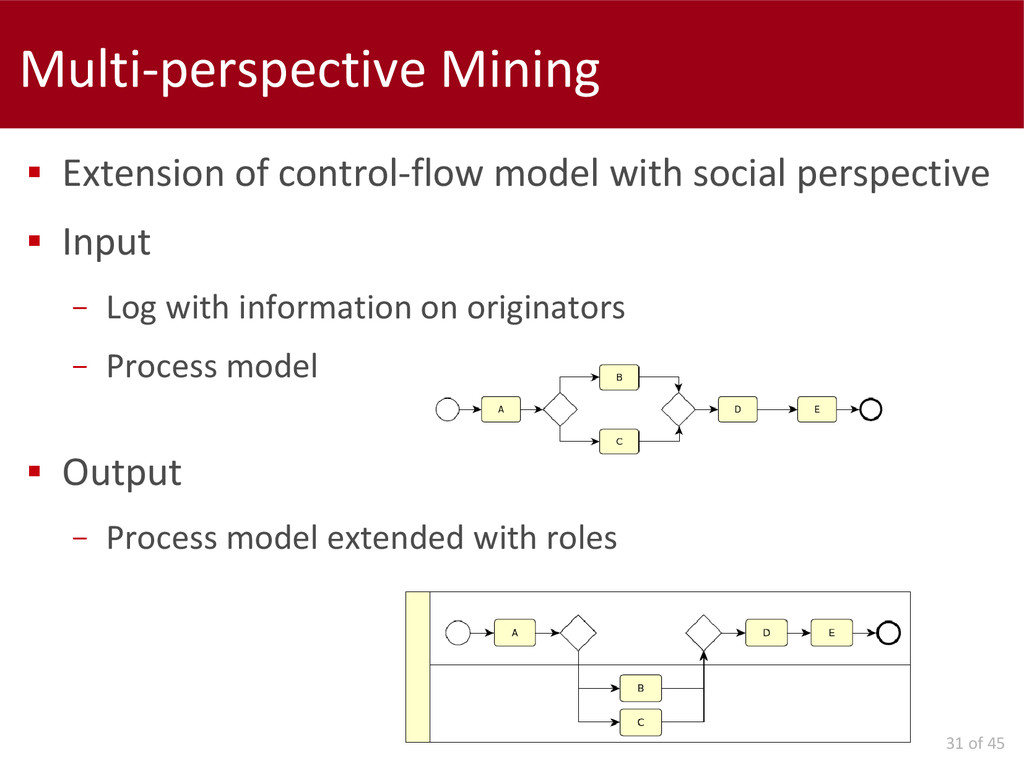
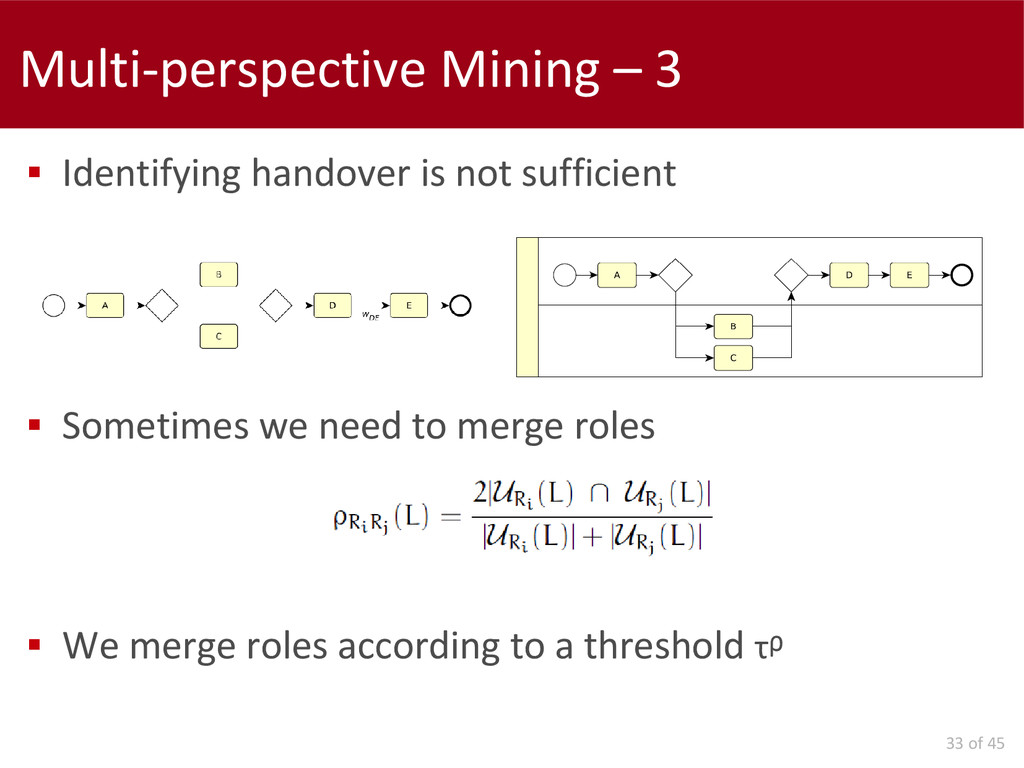
Concerning the data interpretation and results evaluation, we propose two metrics: a model-to-model and a model-to-log. Finally, we present an automatic approach for the extension of a control-flow model with social information, in order to simplify the analysis of these perspectives.
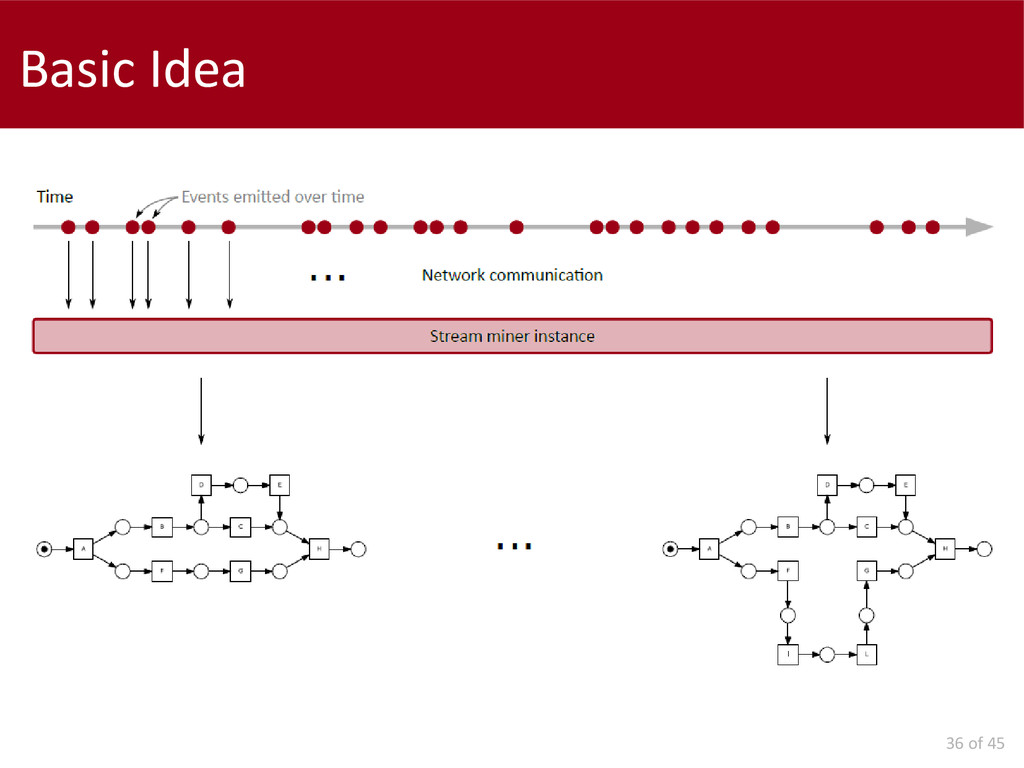
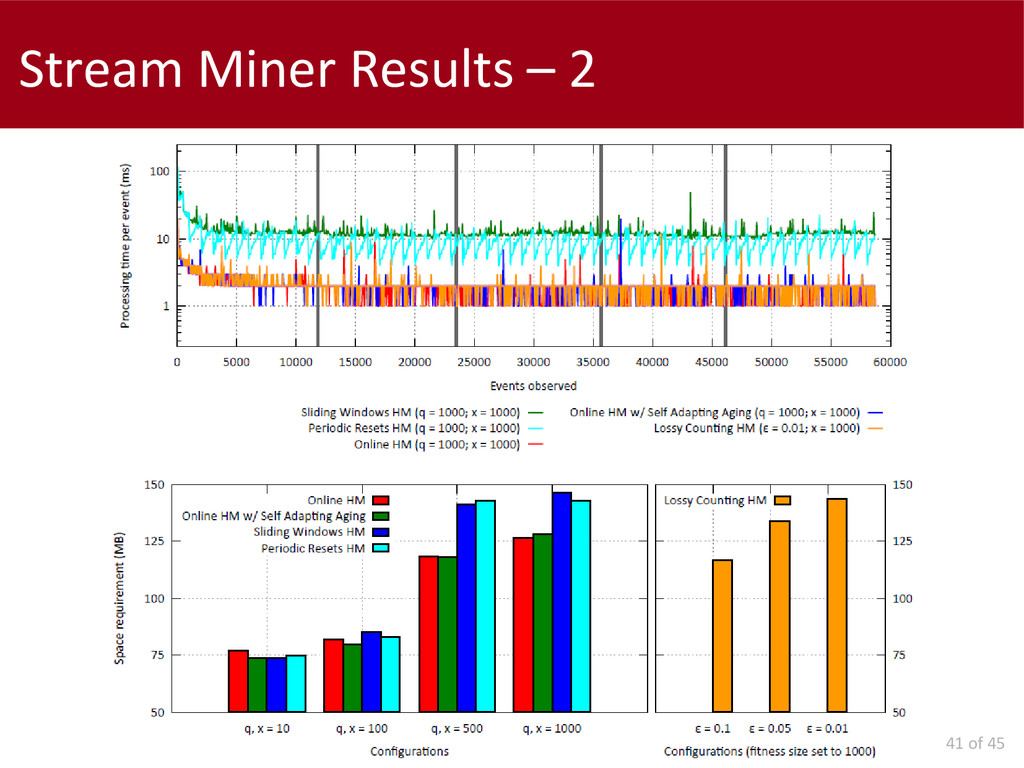
The second part of this thesis deals with control-flow discovery algorithms in on-line settings. We propose a formal definition of the problem, and two baseline approaches. The actual mining algorithms proposed are two: the first is the adaptation, to the control-flow discovery problem, of a frequency counting algorithm; the second constitutes a framework of models which can be used for different kinds of streams (stationary versus evolving).
Thesis available at http://andrea.burattin.net/publications/2013-phd-thesis
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}