Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Scaling Django with Distributed Systems
Search
Andrew Godwin
April 07, 2017
Programming
2.4k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Scaling Django with Distributed Systems
A talk I gave at PyCon Ukraine 2017.
Andrew Godwin
April 07, 2017
More Decks by Andrew Godwin
See All by Andrew Godwin
Reconciling Everything
andrewgodwin
1
400
Django Through The Years
andrewgodwin
0
330
Writing Maintainable Software At Scale
andrewgodwin
0
530
A Newcomer's Guide To Airflow's Architecture
andrewgodwin
0
430
Async, Python, and the Future
andrewgodwin
2
750
How To Break Django: With Async
andrewgodwin
1
830
Taking Django's ORM Async
andrewgodwin
0
850
The Long Road To Asynchrony
andrewgodwin
0
770
The Scientist & The Engineer
andrewgodwin
1
860
Other Decks in Programming
See All in Programming
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
1.1k
Build-to-own AI: Agentic Development for Humans
inesmontani
PRO
0
130
全PRの83%がAIレビューだけでマージできるようになった開発組織はその後どうなったか
athug
0
650
作るコストが小さくなった時代 幸せに働くために改めて考えたいこと 〜エンジニアとして価値を出し続けるために注視している二分野〜
yuppeeng
0
140
Japan Community Day at Kubecon + CloudNativeCon Japan 2026: Learning Container Privilege Control by Building My Own Low-Level Container Runtime
ternbusty
1
100
属人化した知識を、 AIが辿れる地図にする
pkshadeck
PRO
1
130
複数の Claude Code が"放置"されてしまう問題をCLI ダッシュボードを自作して解決した話
sumihiro3
0
580
JAWS-UG横浜 #102 AWSサ終供養LT会 成仏できない AWS サービスたち 〜本日、三体供養します〜
maroon1st
0
280
そこに3びきプロダクトがいるじゃろう——生成AI時代における“価値が届かない理由”の構造
kosuket
0
350
Terraform標準の組織で AWS CDKをどう使うか
mu7889yoon
1
440
AIエージェントで 変わるAndroid開発環境
takahirom
2
750
琵琶湖の水は止められてもNet--HTTPのリトライは止められない / You might be able to stop the water flow of Lake Biwa but you can't stop Net::HTTP retries
luccafort
PRO
0
500
Featured
See All Featured
Design in an AI World
tapps
1
270
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
480
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
Product Roadmaps are Hard
iamctodd
55
12k
Code Reviewing Like a Champion
maltzj
528
40k
Faster Mobile Websites
deanohume
310
32k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
Transcript
None
Andrew Godwin Hi, I'm Django core developer Senior Software Engineer
at Used to complain about migrations a lot
Distributed Systems
c = 299,792,458 m/s
Early CPUs c = 60m propagation distance Clock ~2cm 5
MHz
Modern CPUs c = 10cm propagation distance 3 GHz
Distributed systems are made of independent components
They are slower and harder to write than synchronous systems
But they can be scaled up much, much further
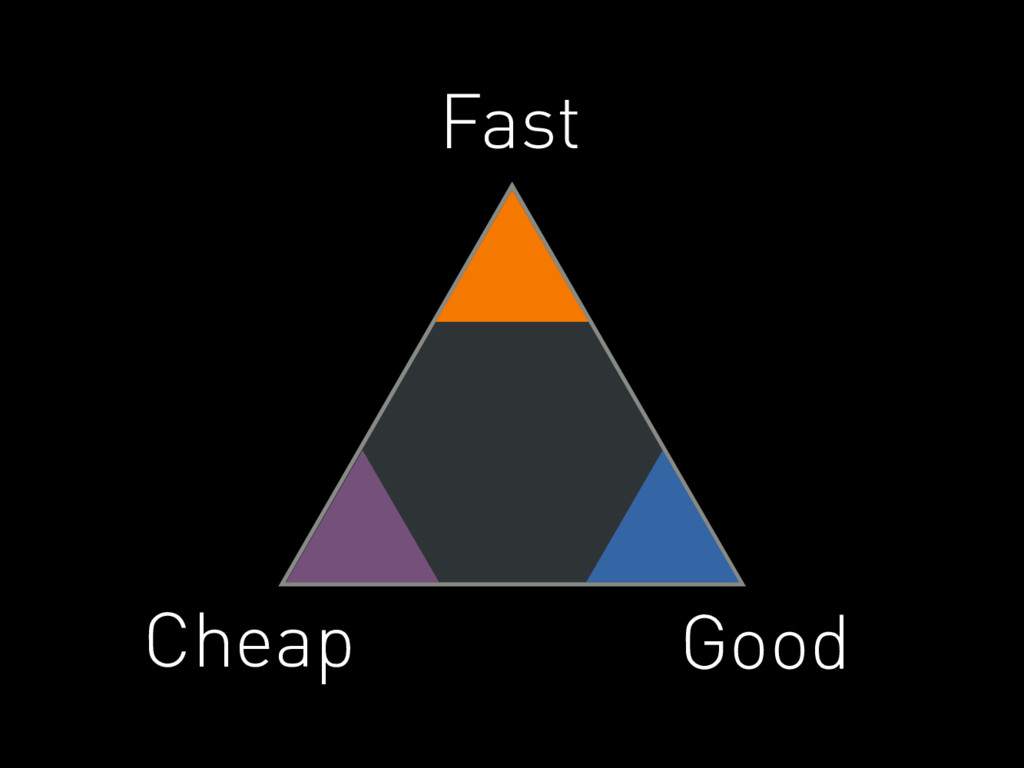
Trade-offs
There is never a perfect solution.
Fast Good Cheap
None
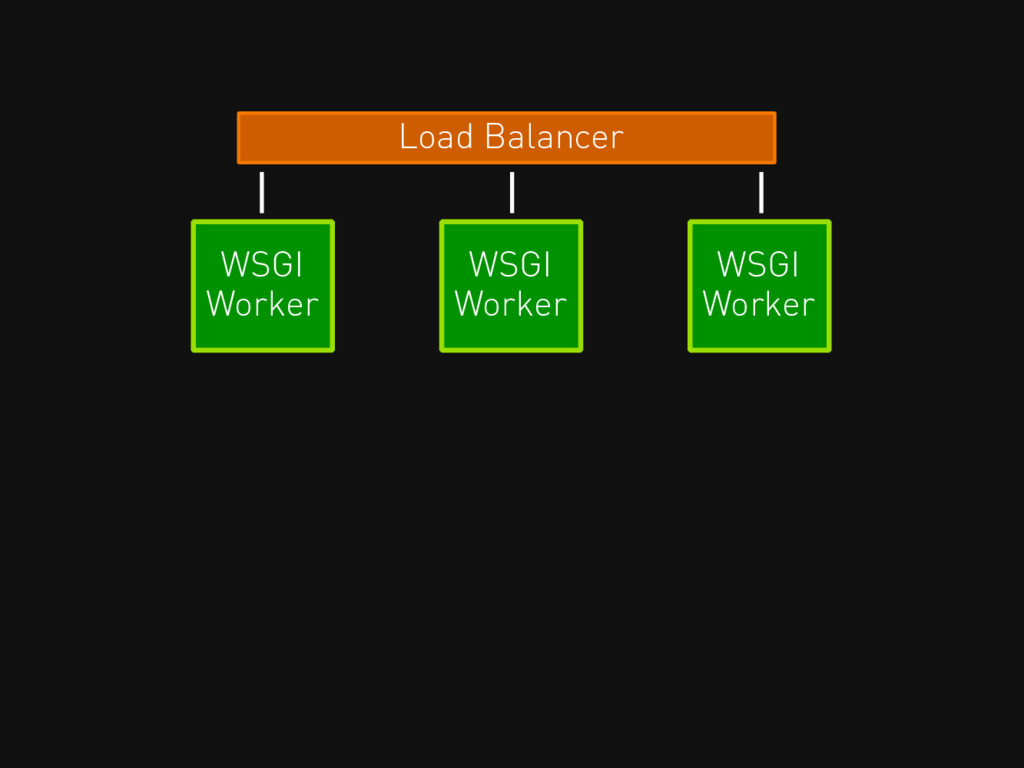
Load Balancer WSGI Worker WSGI Worker WSGI Worker
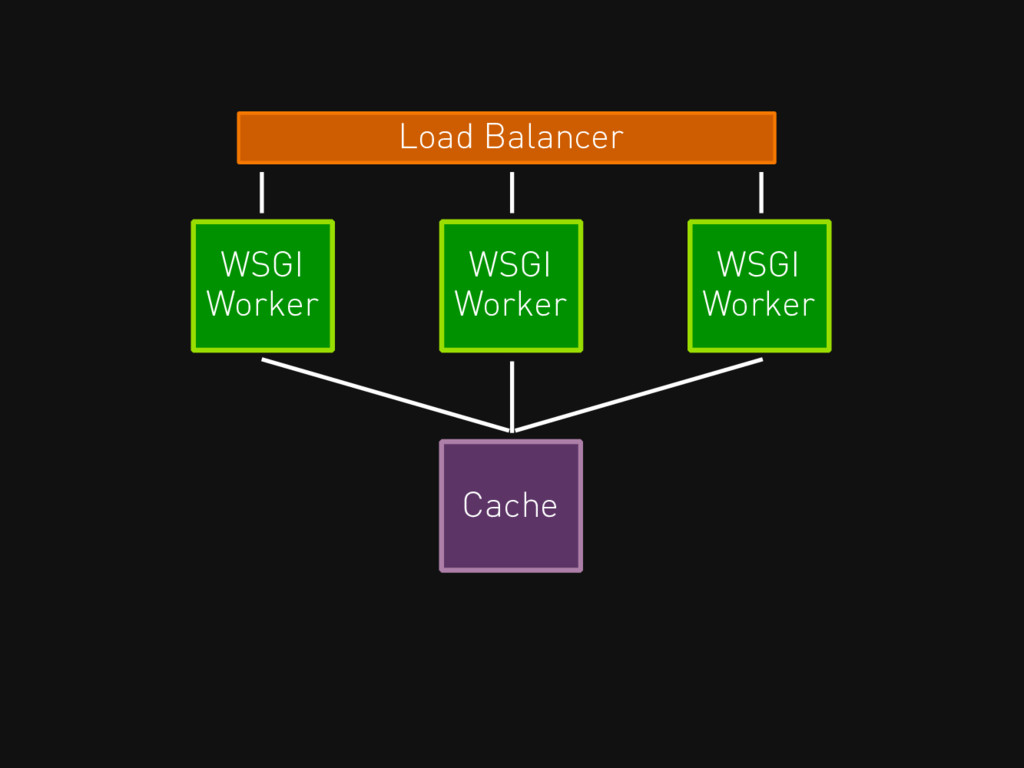
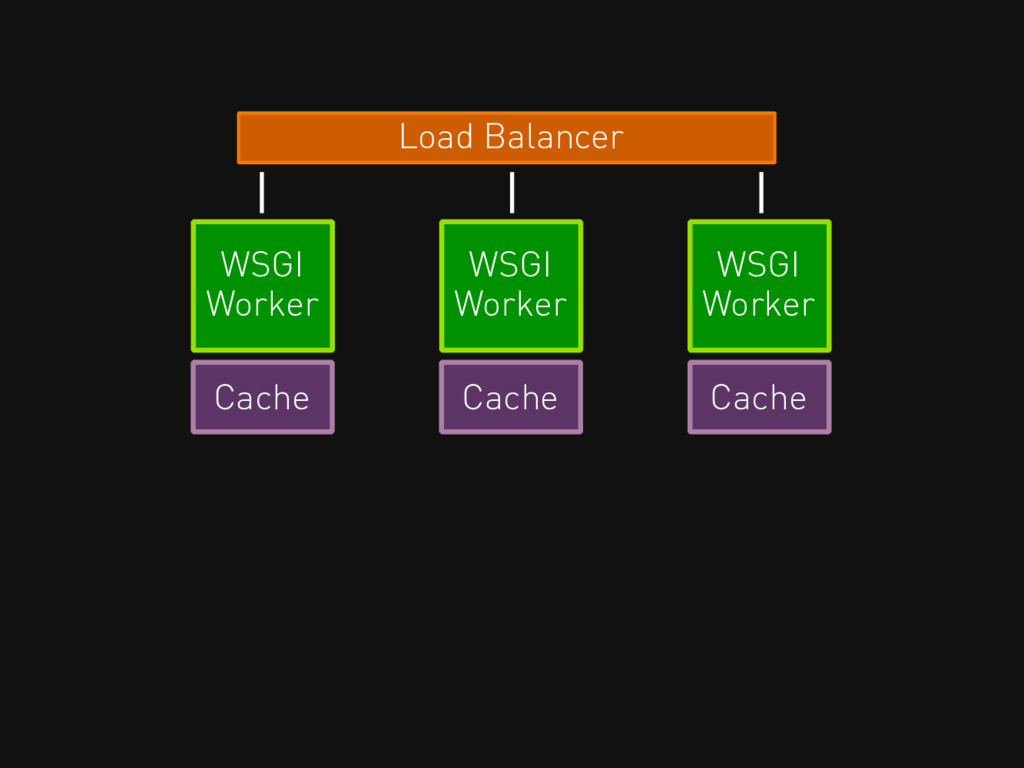
Load Balancer WSGI Worker WSGI Worker WSGI Worker Cache
Load Balancer WSGI Worker WSGI Worker WSGI Worker Cache Cache
Cache
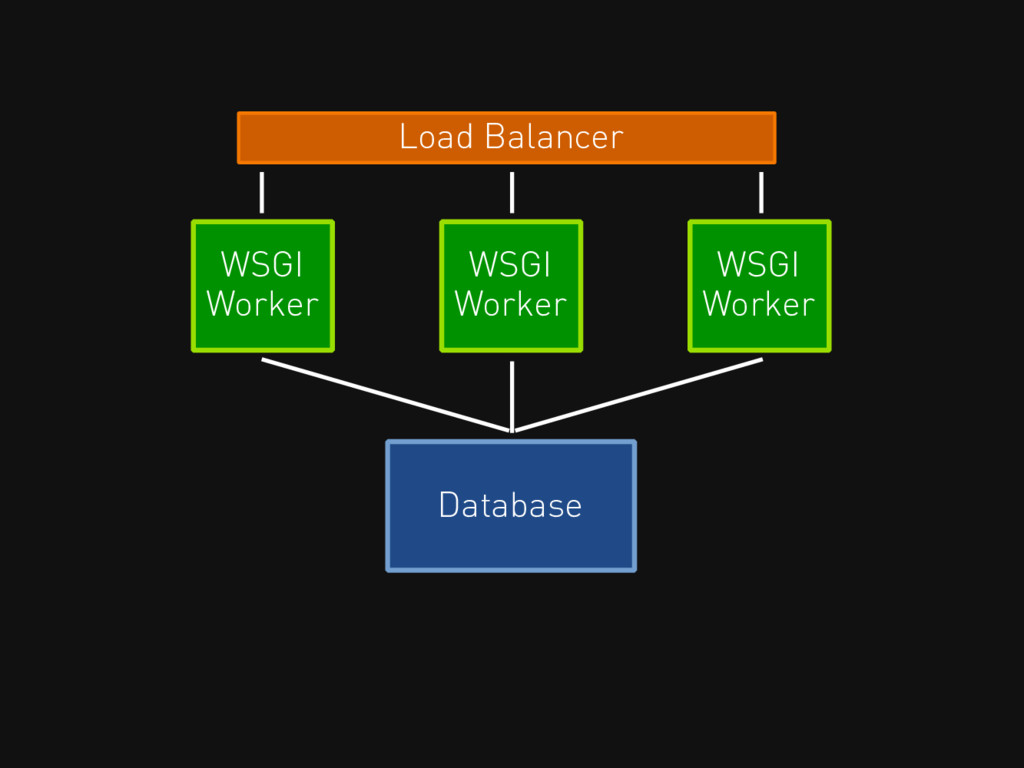
Load Balancer WSGI Worker WSGI Worker WSGI Worker Database
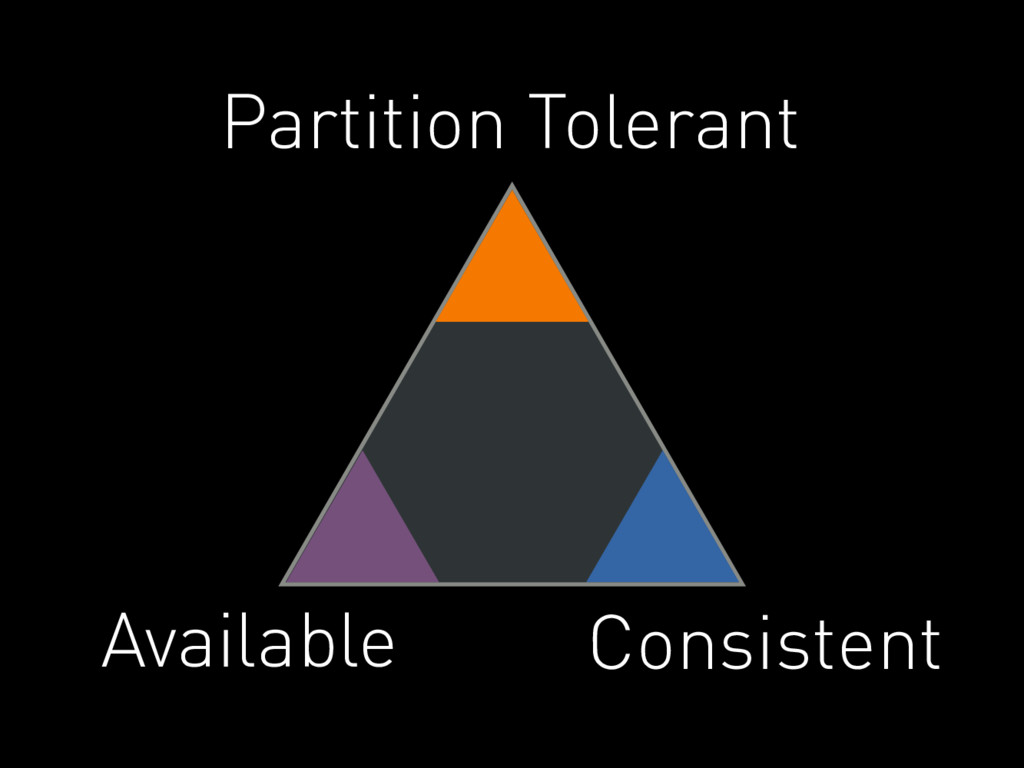
CAP Theorem
Partition Tolerant Consistent Available
PostgreSQL: CP Consistent everywhere Handles network latency/drops Can't write if
main server is down
Cassandra: AP Can read/write to any node Handles network latency/drops
Data can be inconsistent
It's hard to design a product that might be inconsistent
But if you take the tradeoff, scaling is easy
Otherwise, you must find other solutions
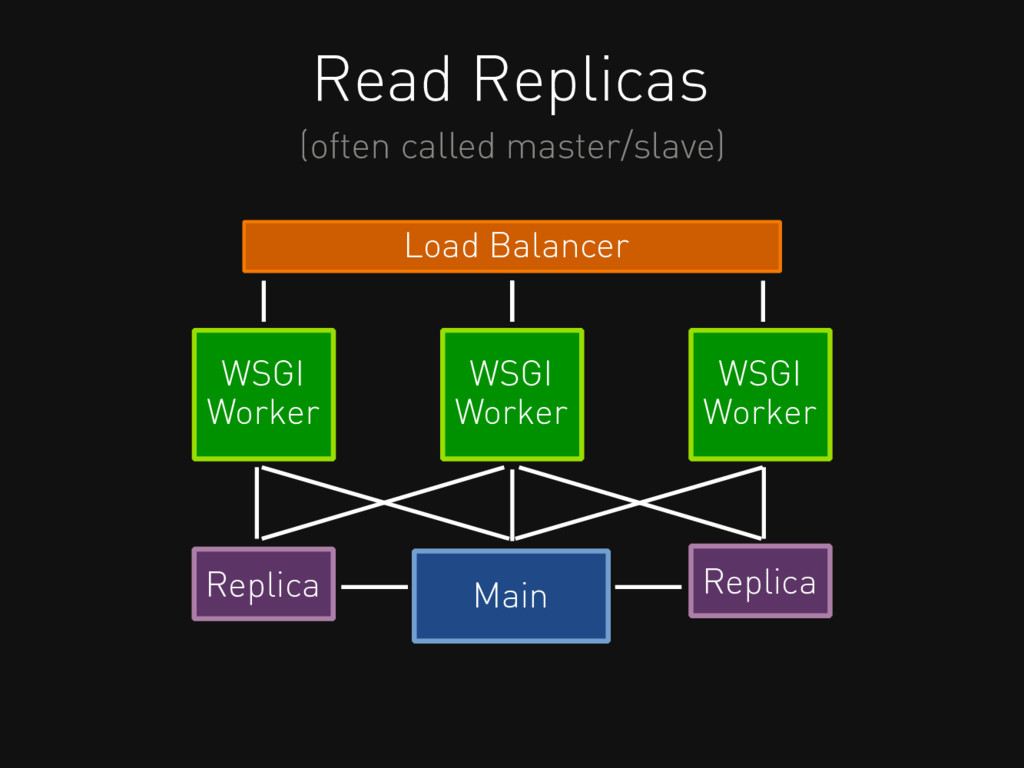
Read Replicas (often called master/slave) Load Balancer WSGI Worker WSGI
Worker WSGI Worker Replica Replica Main
Replicas scale reads forever... But writes must go to one
place
If a request writes to a table it must be
pinned there, so later reads do not get old data
When your write load is too high, you must then
shard
Vertical Sharding Users Tickets Events Payments
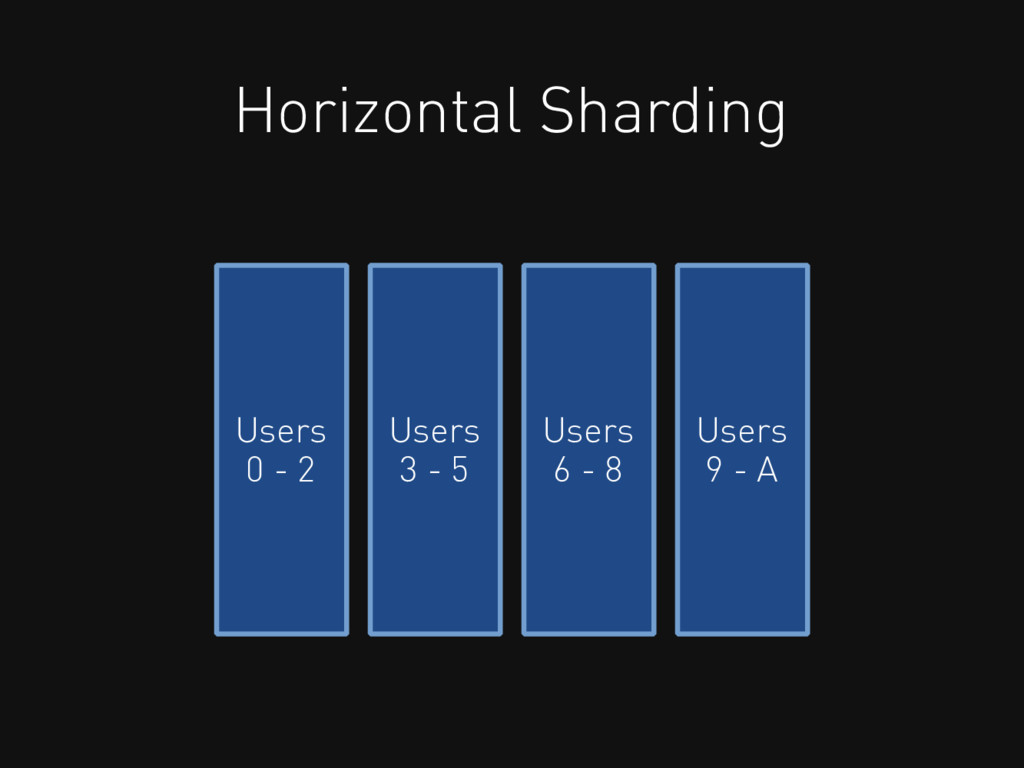
Horizontal Sharding Users 0 - 2 Users 3 - 5
Users 6 - 8 Users 9 - A
Both Users 0 - 2 Users 3 - 5 Users
6 - 8 Users 9 - A Events 0 - 2 Events 3 - 5 Events 6 - 8 Events 9 - A Tickets 0 - 2 Tickets 3 - 5 Tickets 6 - 8 Tickets 9 - A
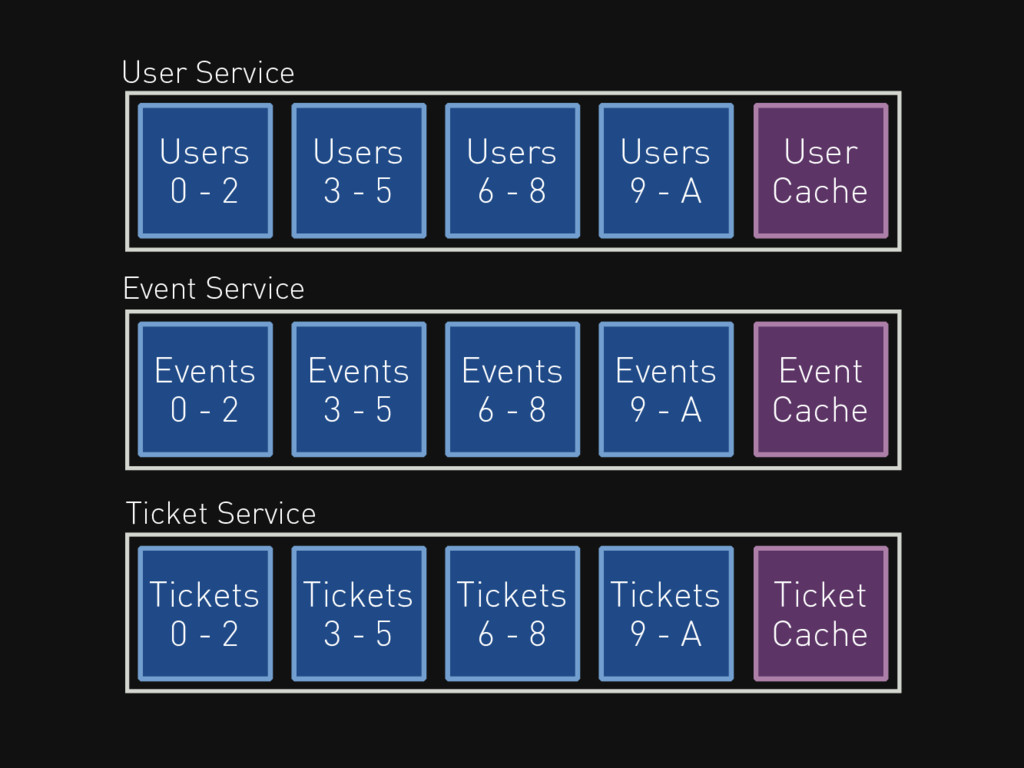
Both plus caching Users 0 - 2 Users 3 -
5 Users 6 - 8 Users 9 - A Events 0 - 2 Events 3 - 5 Events 6 - 8 Events 9 - A Tickets 0 - 2 Tickets 3 - 5 Tickets 6 - 8 Tickets 9 - A User Cache Event Cache Ticket Cache
Teams have to scale too; nobody should have to understand
eveything in a big system.
Services allow complexity to be reduced - for a tradeoff
of speed
Users 0 - 2 Users 3 - 5 Users 6
- 8 Users 9 - A Events 0 - 2 Events 3 - 5 Events 6 - 8 Events 9 - A Tickets 0 - 2 Tickets 3 - 5 Tickets 6 - 8 Tickets 9 - A User Cache Event Cache Ticket Cache User Service Event Service Ticket Service
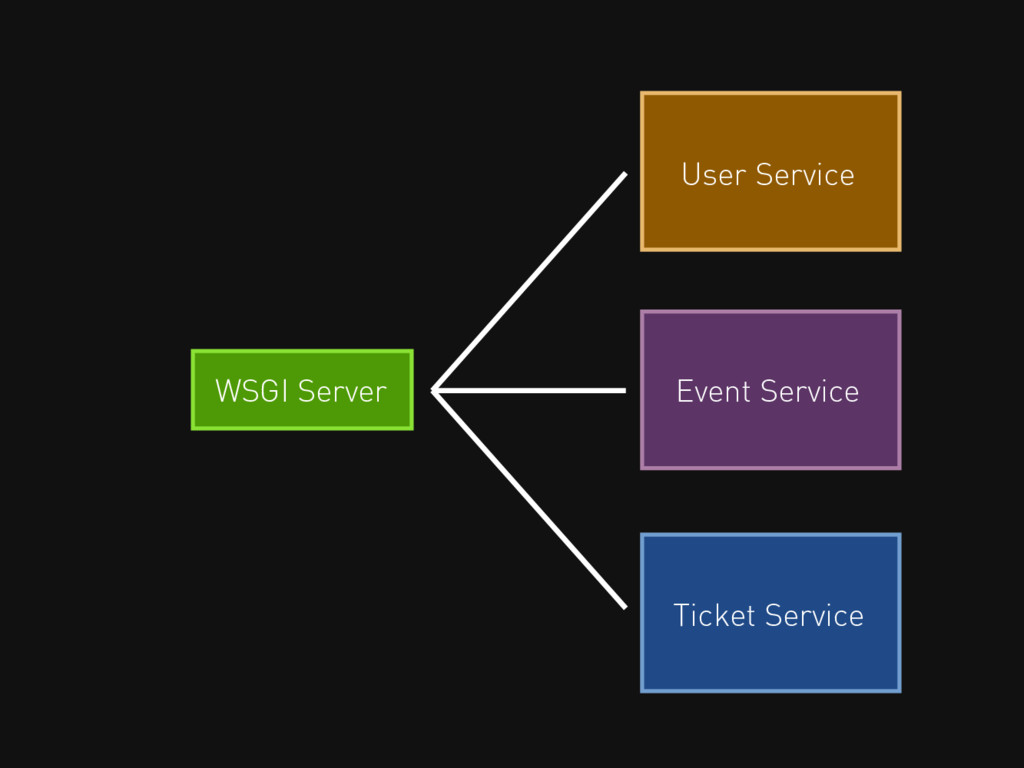
User Service Event Service Ticket Service WSGI Server
Each service is its own, smaller project, managed and scaled
separately.
But how do you communicate between them?
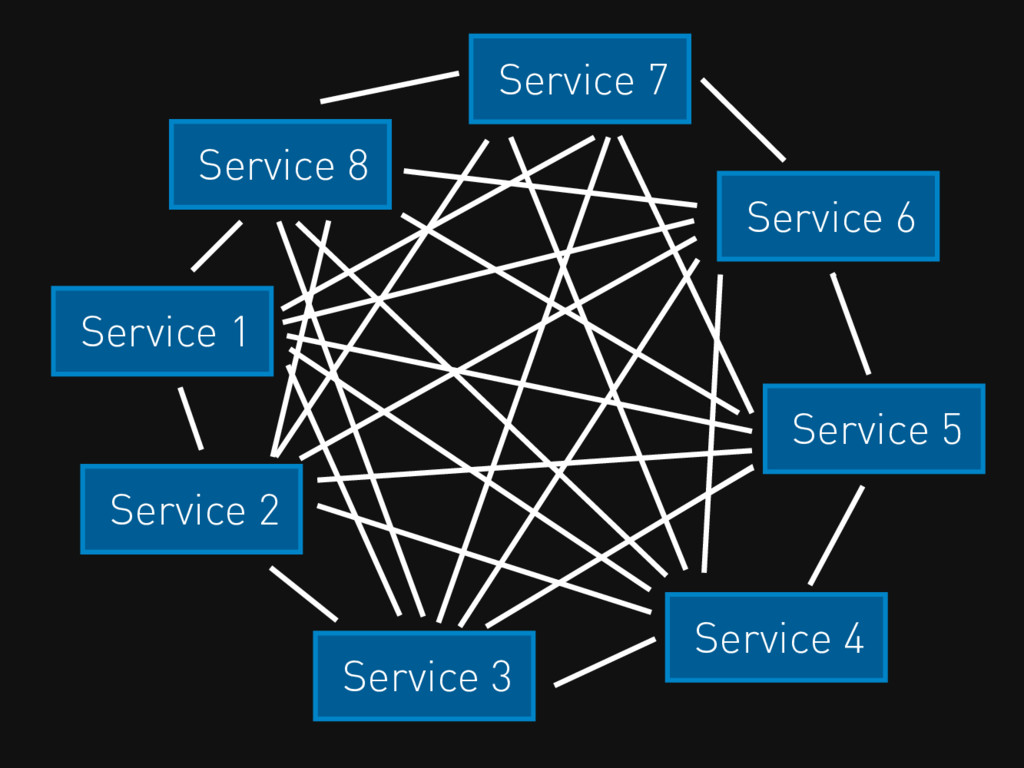
Service 2 Service 3 Service 1 Direct Communication
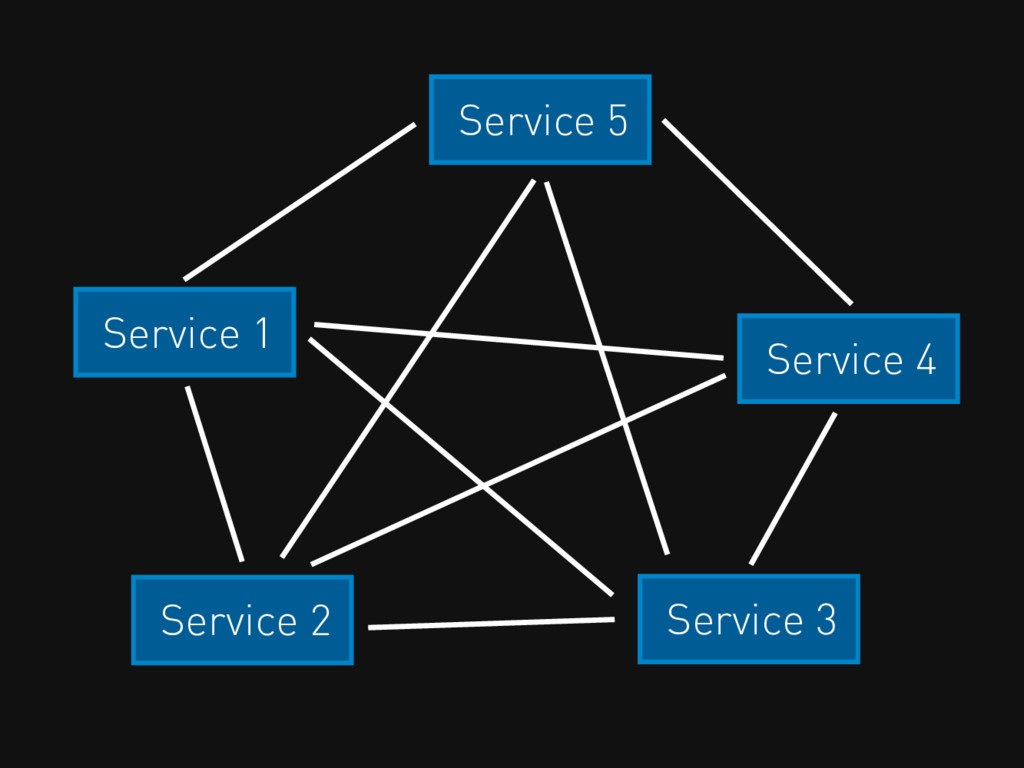
Service 2 Service 3 Service 1 Service 4 Service 5
Service 2 Service 3 Service 1 Service 4 Service 5
Service 6 Service 7 Service 8
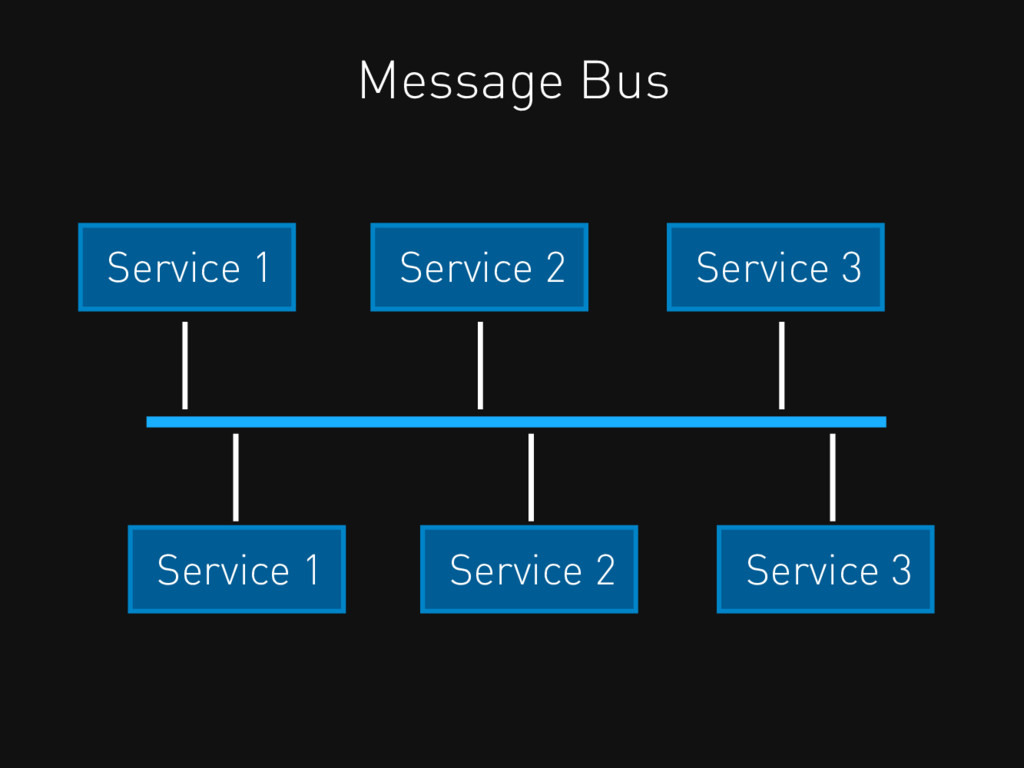
Service 2 Service 3 Service 1 Message Bus Service 2
Service 3 Service 1
A single point of failure is not always bad -
if the alternative is multiple, fragile ones
Channels and ASGI provide a standard message bus built with
certain tradeoffs
Backing Store e.g. Redis, RabbitMQ ASGI (Channel Layer) Channels Library
Django Django Channels Project
Backing Store e.g. Redis, RabbitMQ ASGI (Channel Layer) Pure Python
Failure Mode At most once Messages either do not arrive,
or arrive once. At least once Messages arrive once, or arrive multiple times
Guarantees vs. Latency Low latency Messages arrive very quickly but
go missing more Low loss rate Messages are almost never lost but arrive slower
Queuing Type First In First Out Consistent performance for all
users First In Last Out Hides backlogs but makes them worse
Queue Sizing Finite Queues Sending can fail Infinite queues Makes
problems even worse
You must understand what you are making (This is surprisingly
uncommon)
Design as much as possible around shared-nothing
Per-machine caches On-demand thumbnailing Signed cookie sessions
Has to be shared? Try to split it
Has to be shared? Try sharding it.
Django's job is to be slowly replaced by your code
Just make sure you match the API contract of what
you're replacing!
Don't try to scale too early; you'll pick the wrong
tradeoffs.
Thanks. Andrew Godwin @andrewgodwin channels.readthedocs.io
{kind=link}
{kind=link}
{kind=link}
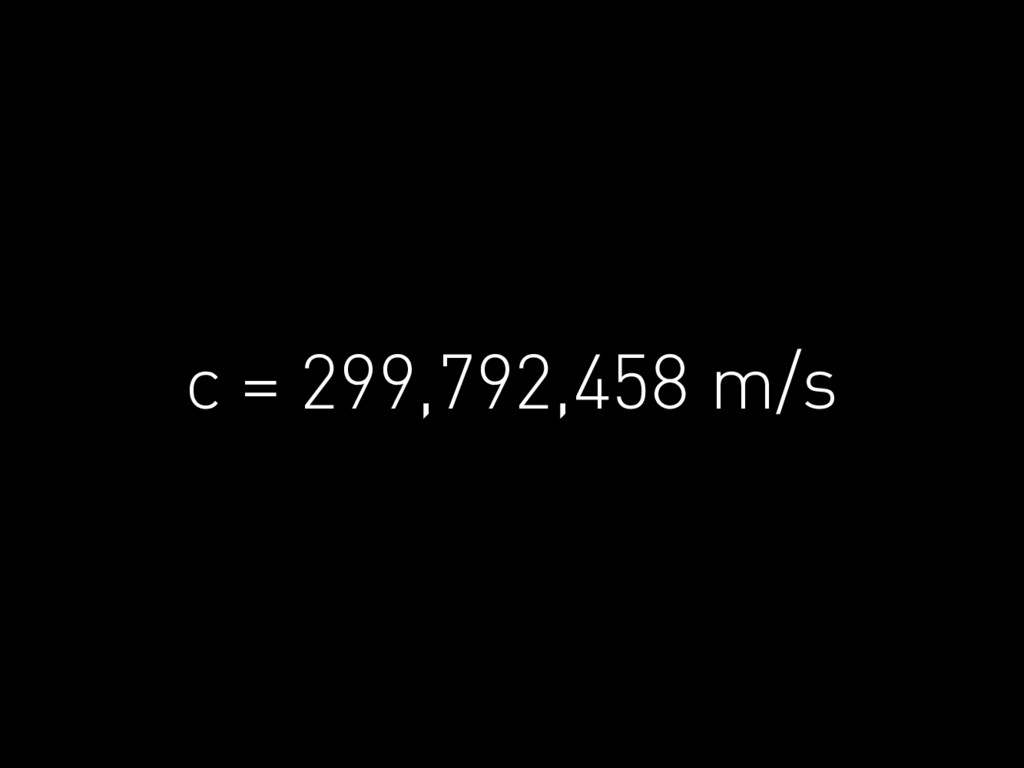{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}