( http://sprocket.io/blog/2007/10/string-concatenation-performance-in- python/ ) add: a + b + c + d add equals: a += b; a += c; a += d format strings: ‘%s%s%s%s’ % (a, b, c, d) named format strings:‘%(a)s%(b)s%(c)s%(d)s’ % {‘a’: a, ‘b’: b, ‘c’: c, ‘d’: d}” join: ”.join([a,b,c,d]) #!/usr/bin/python # benchmark various string concatenation methods. Run each 5*1,000,000 times # and pick the best time out of the 5. Repeats for string lengths of # 4, 16, 64, 256, 1024, and 4096. Outputs in CSV format via stdout. import timeit tests = { 'add': "x = a + b + c + d", 'join': "x = ''.join([a,b,c,d])", 'addequals': "x = a; x += b; x += c; x += d", 'format': "x = '%s%s%s%s' % (a, b, c, d)", 'full_format': "x = '%(a)s%(b)s%(c)s%(d)s' % {'a': a, 'b': b, 'c': c, 'd': d}" } count = 1 for i in range(6): count = count * 4 init = "a = '%s'; b = '%s'; c = '%s'; d = '%s'" % \ ('a' * count, 'b' * count, 'c' * count, 'd' * count) for test in tests: t = timeit.Timer(tests[test], init) best = min(t.repeat(5, 1000000)) print "'%s',%s,%s" % (test, count, best)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
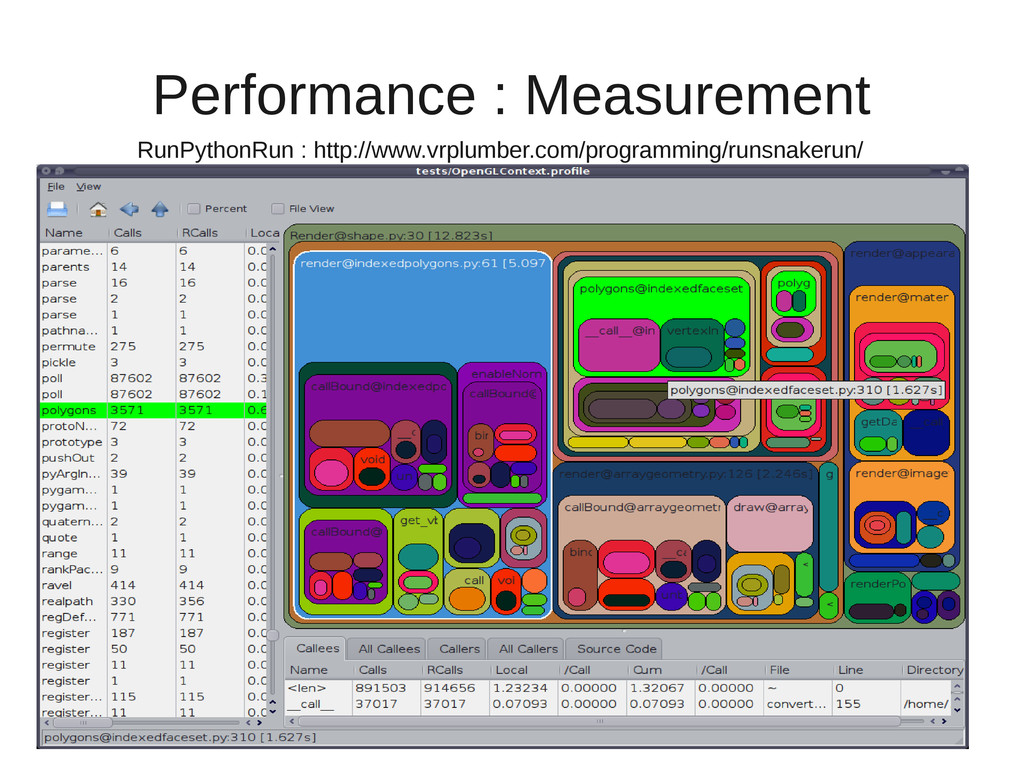{kind=link}
{kind=link}
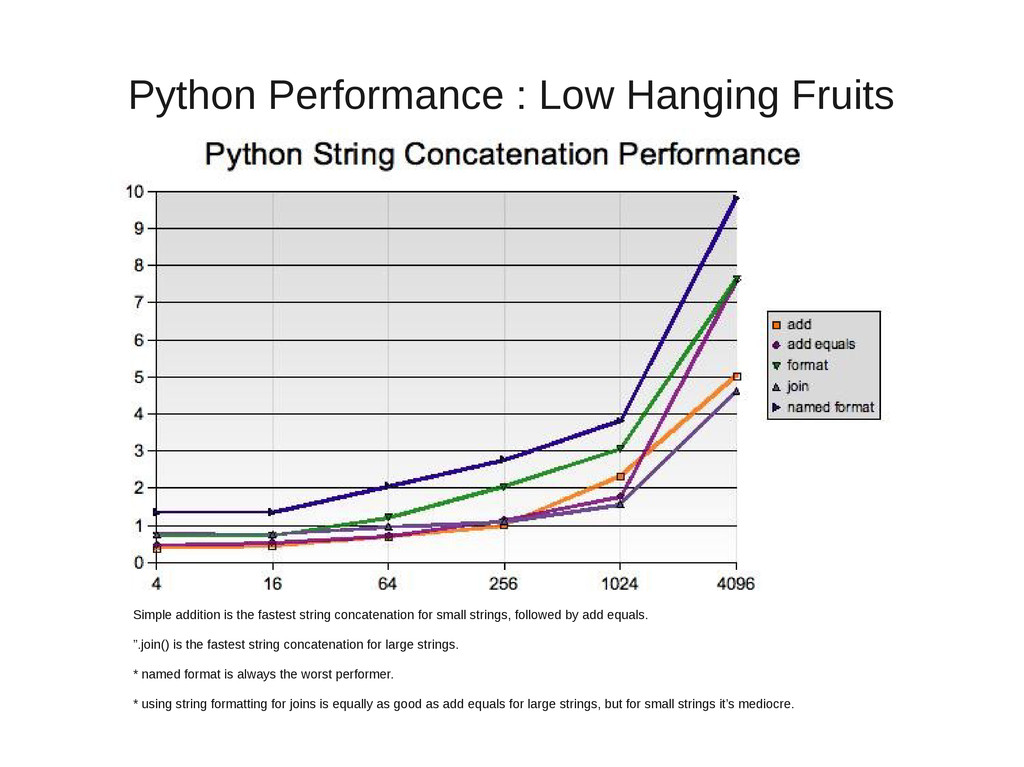{kind=link}
![Python Performance : Low Hanging Fruits newlist = [] for](https://files.speakerdeck.com/presentations/4e80cf4ad7da0c0060000056/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
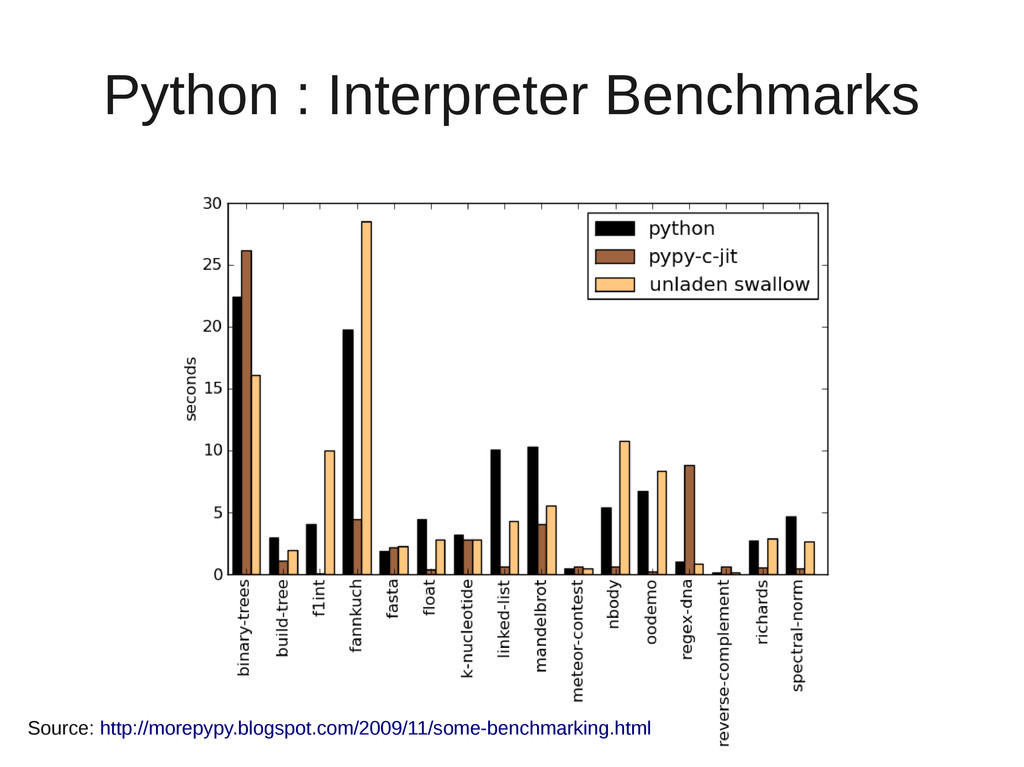{kind=link}
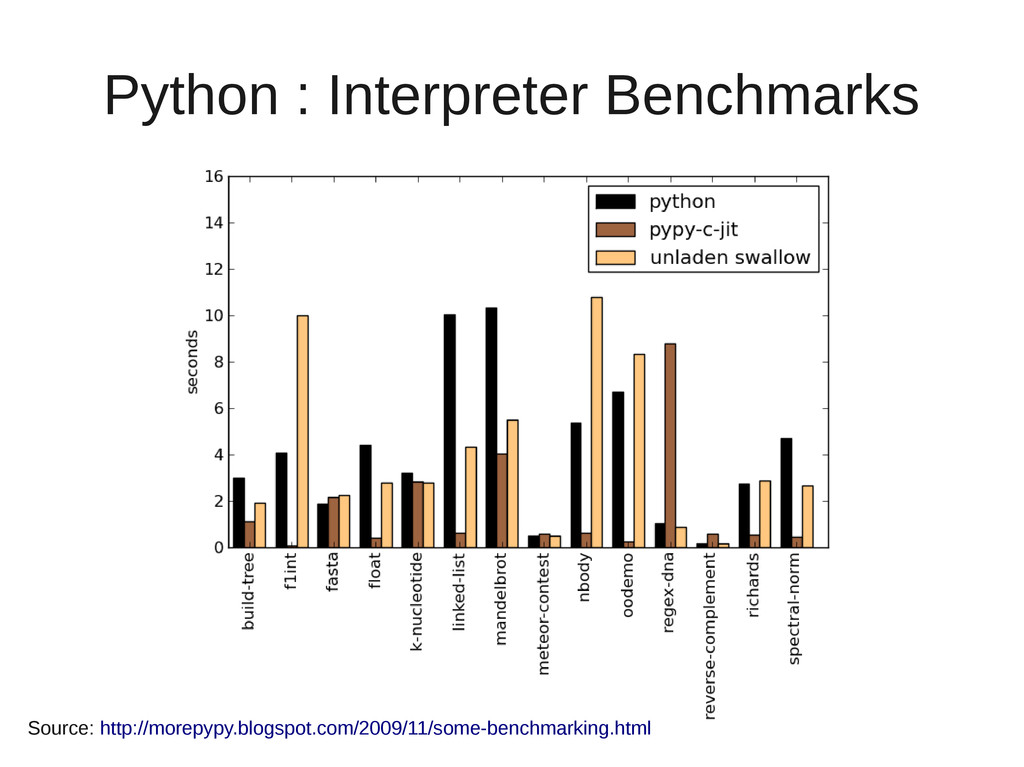{kind=link}
{kind=link}
{kind=link}
{kind=link}