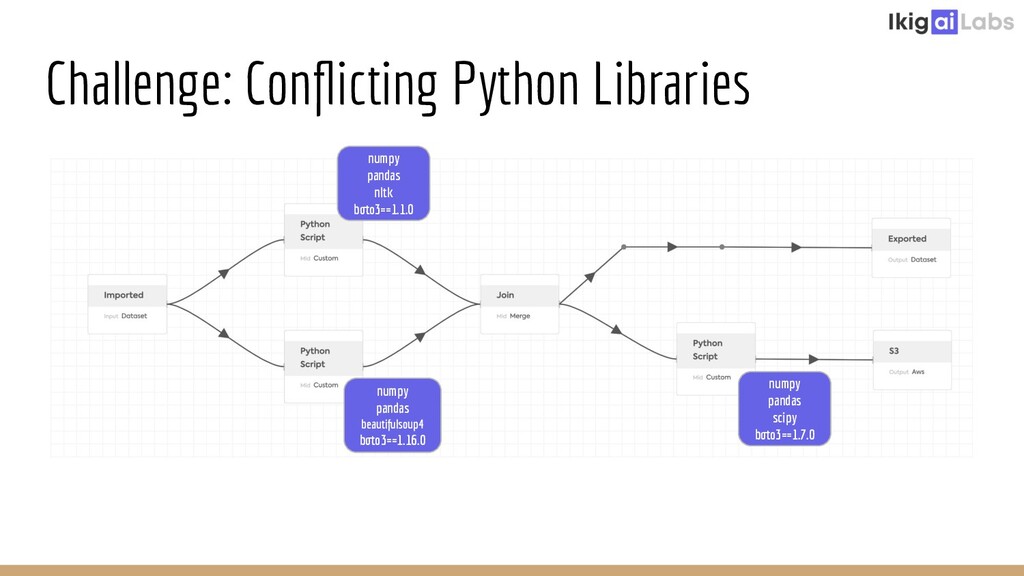
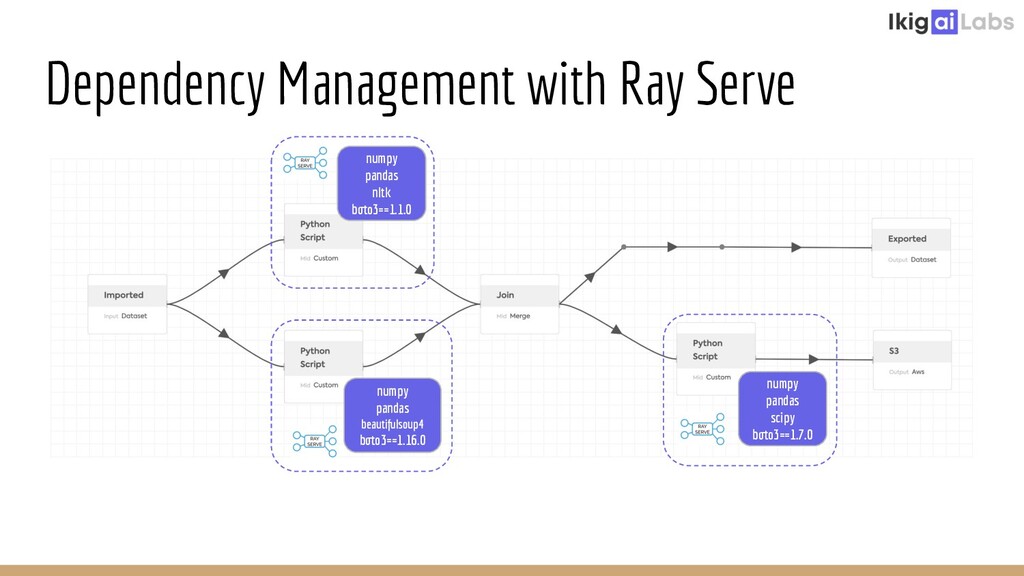
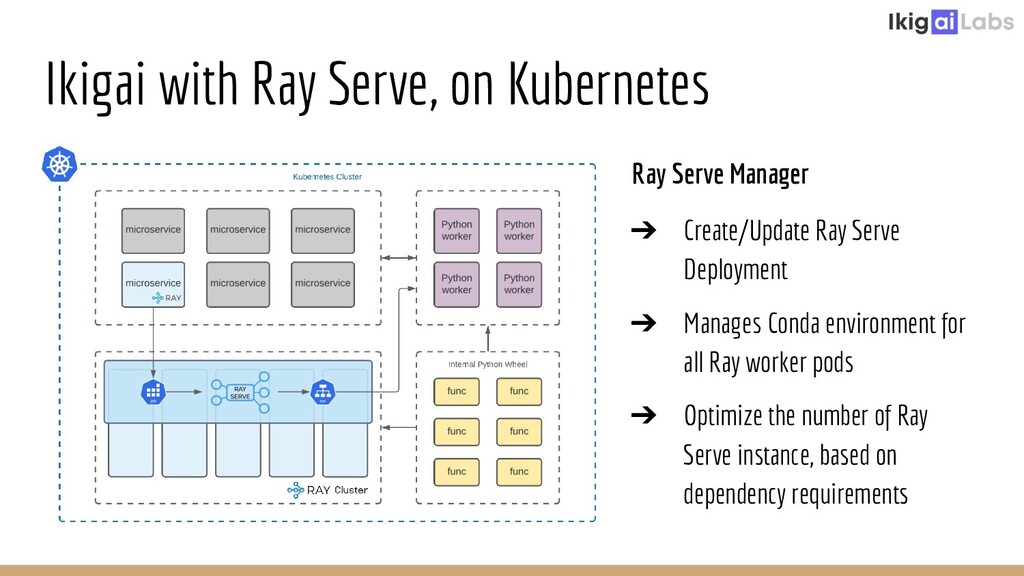
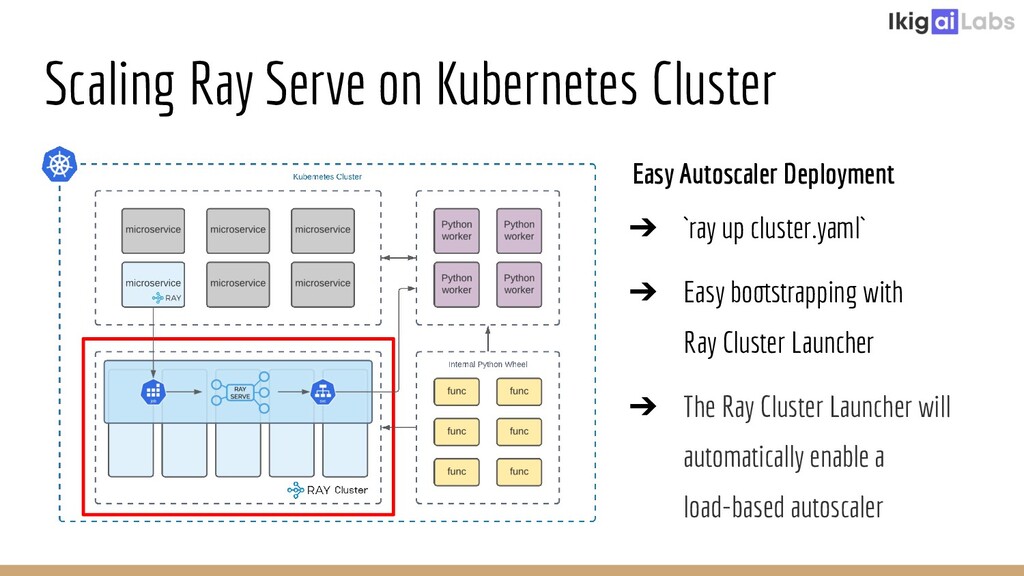
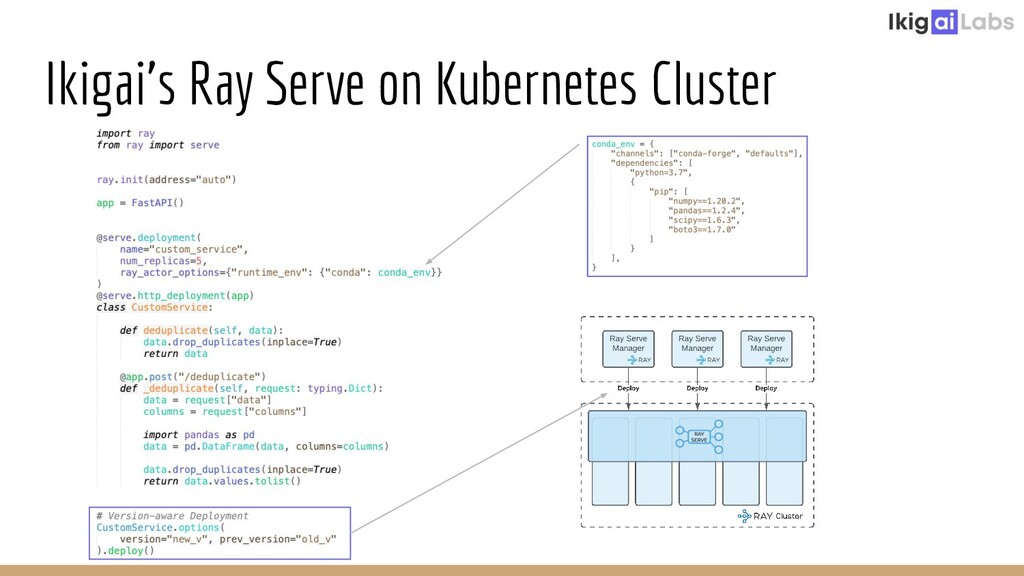
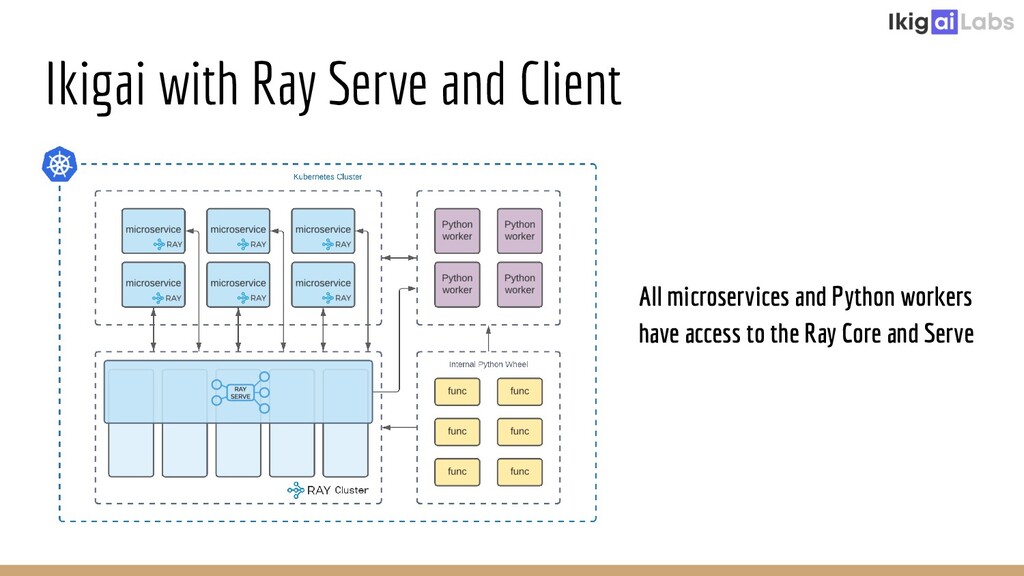
Creating a scalable and highly interactive data pipelining platform is a challenging task. Ikigai Labs is tackling this problem by enabling users to inject custom Python code into a traditional data pipelining platform. The challenges of such a flexible platform create non-traditional problems. Ray and Ray Serve enable solutions at scale without hurting data interactivity. We’ll explore the challenges we faced and how Ray and Ray Serve provided excellent flexibility in resolving those challenges. We will conclude with the potential of Ray Client to push the bar even further in the future.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
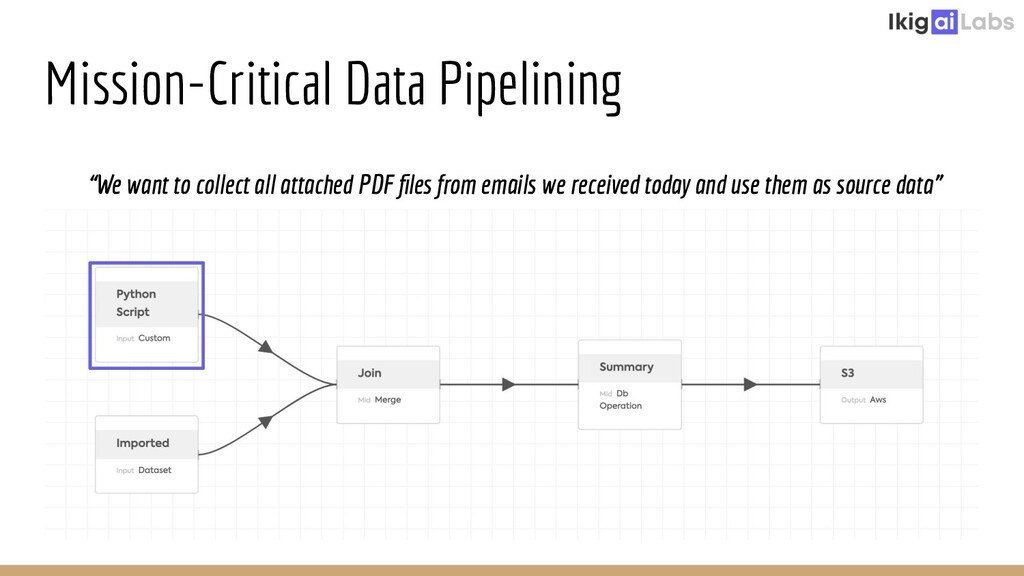{kind=link}
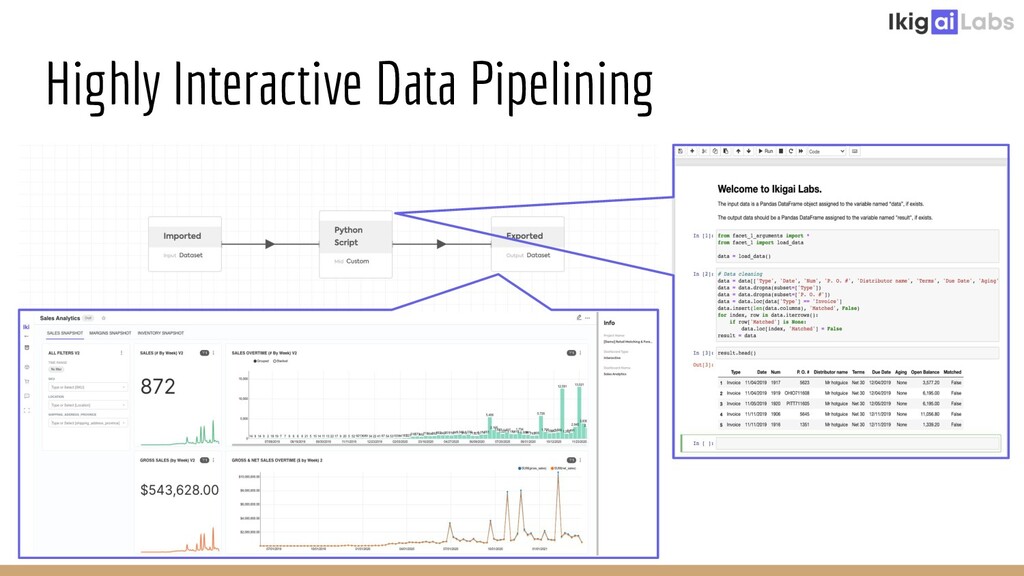{kind=link}
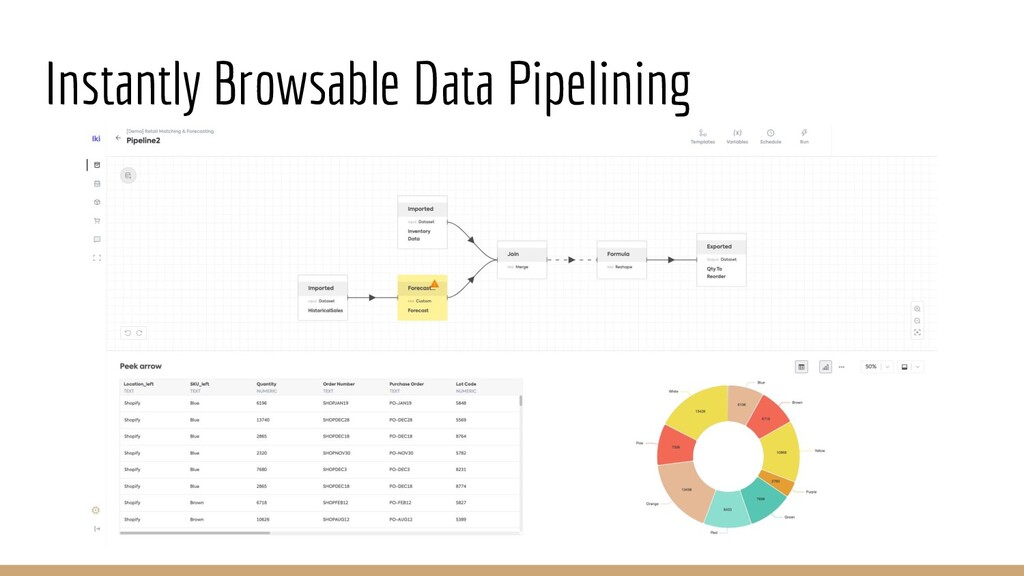{kind=link}
{kind=link}
{kind=link}
{kind=link}
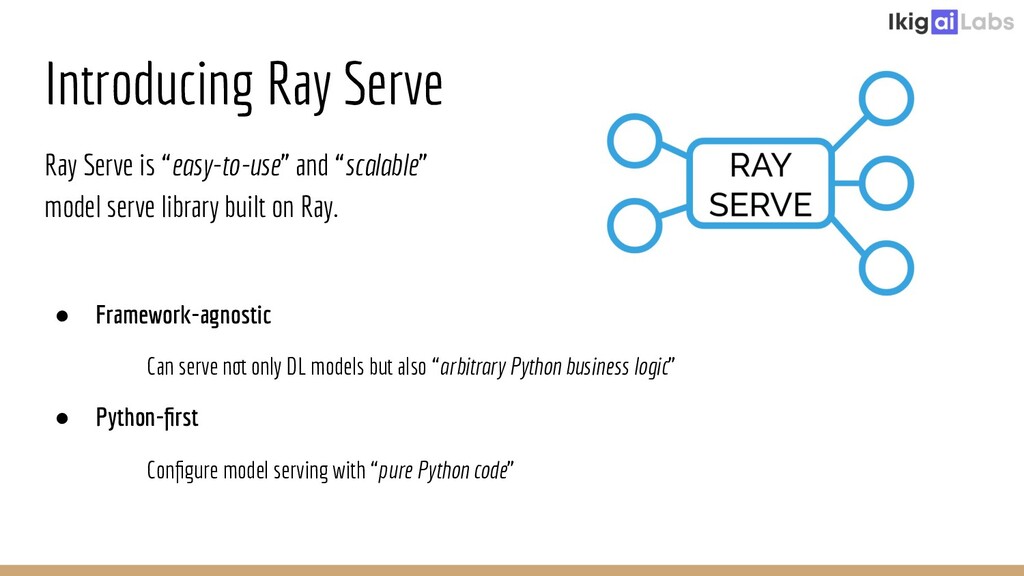{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
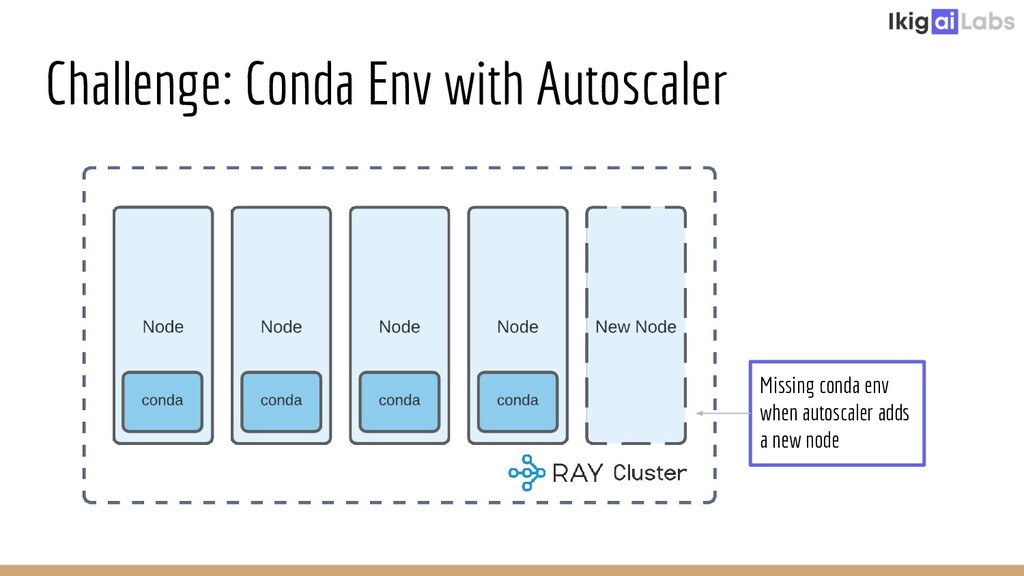{kind=link}
{kind=link}
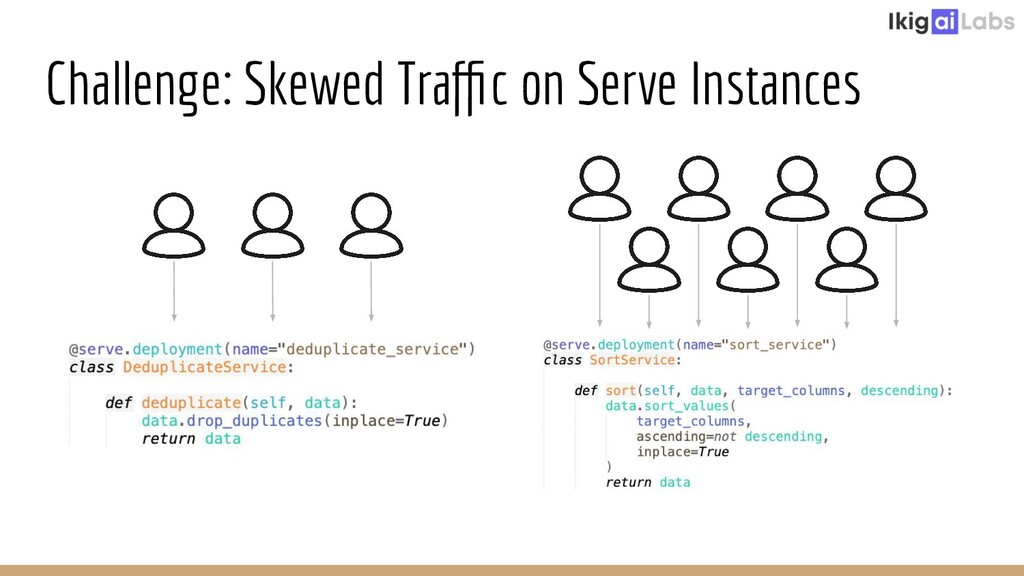{kind=link}
{kind=link}
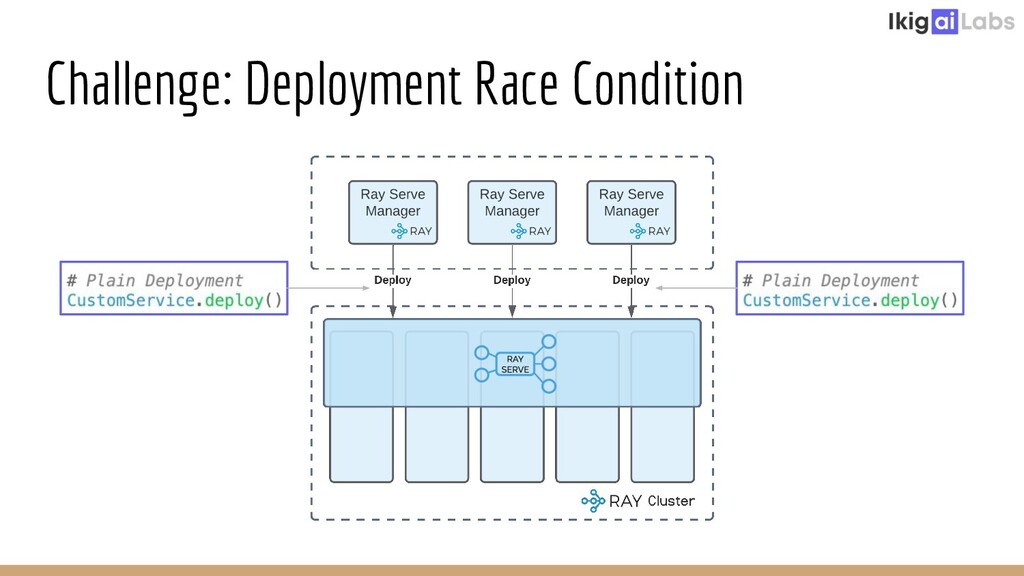{kind=link}
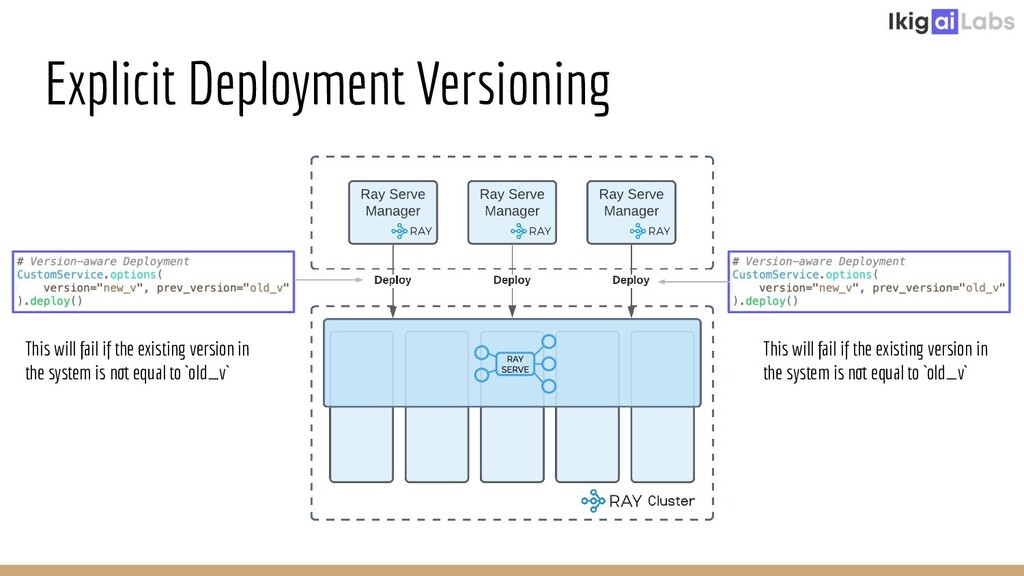{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}