In this talk, Srinivasa discusses:
* Traditional approaches to detect the sensitive data for data protection and data loss prevention and the drawbacks of the traditional approaches
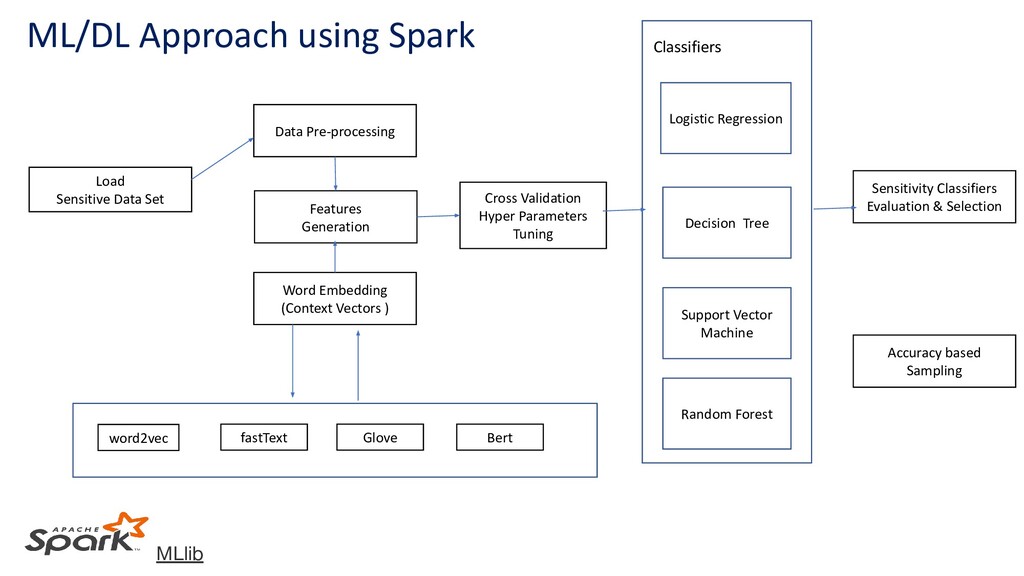
* Novel ways of using ML , DL, and NLP along with Spark/Ray to detect the sensitive data in peta bytes scale
* Novel approaches/algorithm to address the scaling challenges in detection of sensitive data
* Benchmark numbers and accuracy results with the novel approach
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}