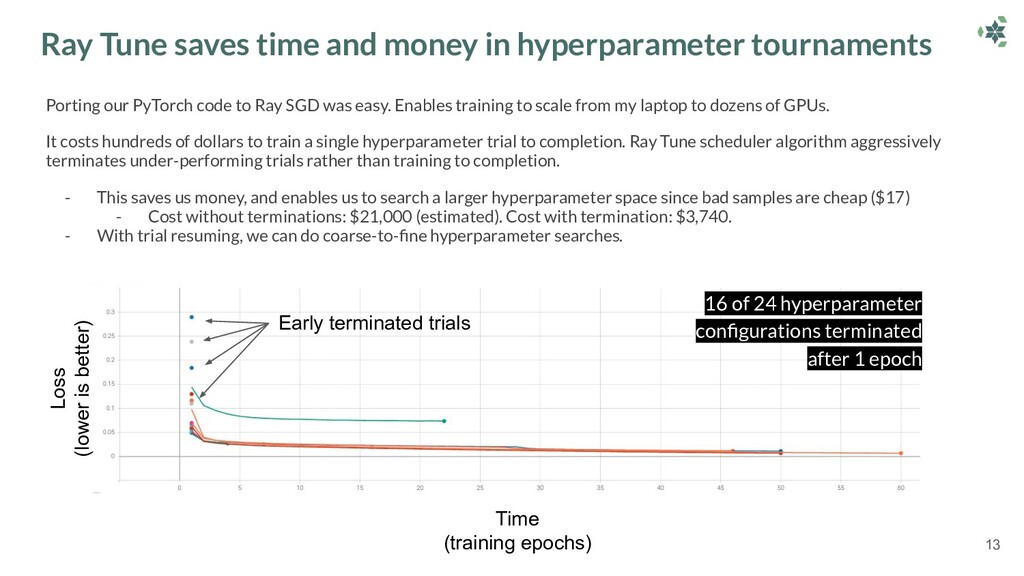
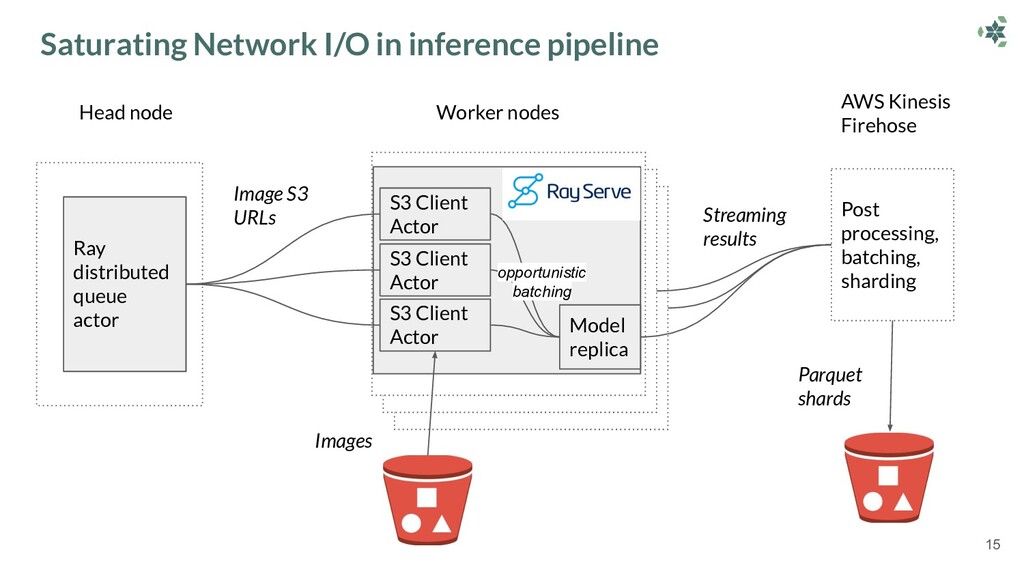
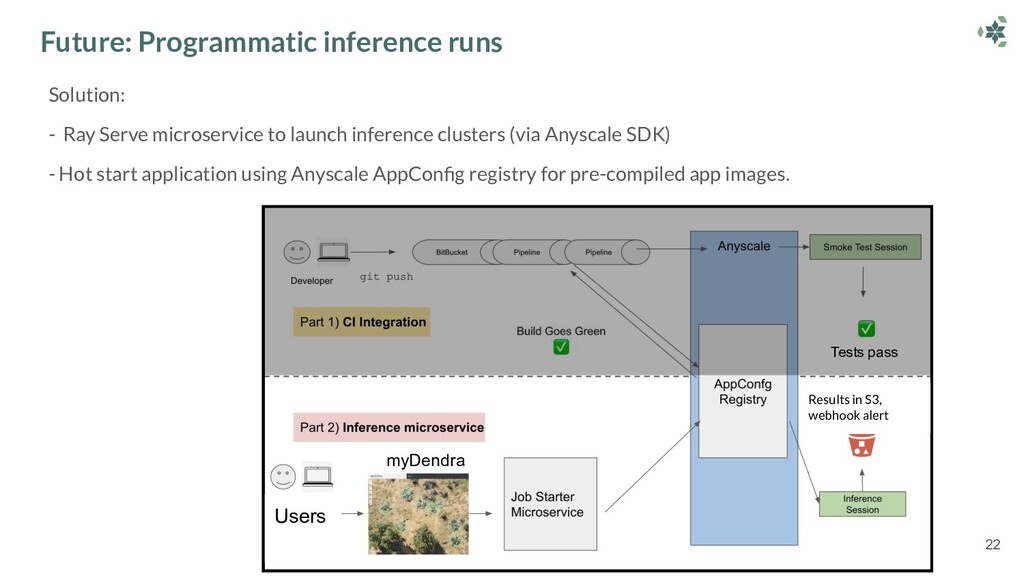
This talk outlines how Dendra Systems leverage Ray and Anyscale to parallelize their workloads across a cluster containing dozens of GPUs in a single Python script. Richard discusses how Dendra optimized their inference pipelines to saturate their clusters' network I/O limits using Ray Serve.
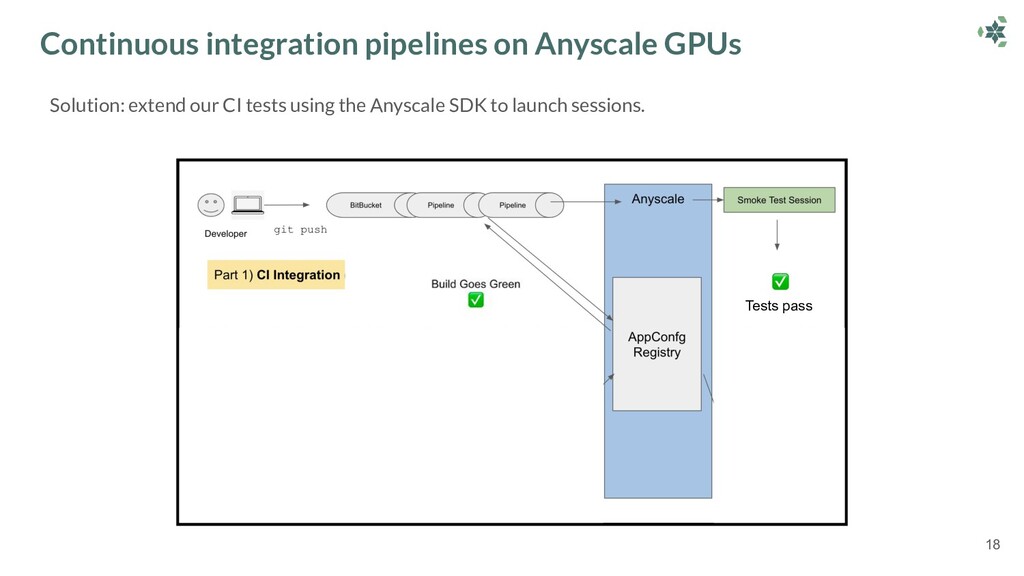
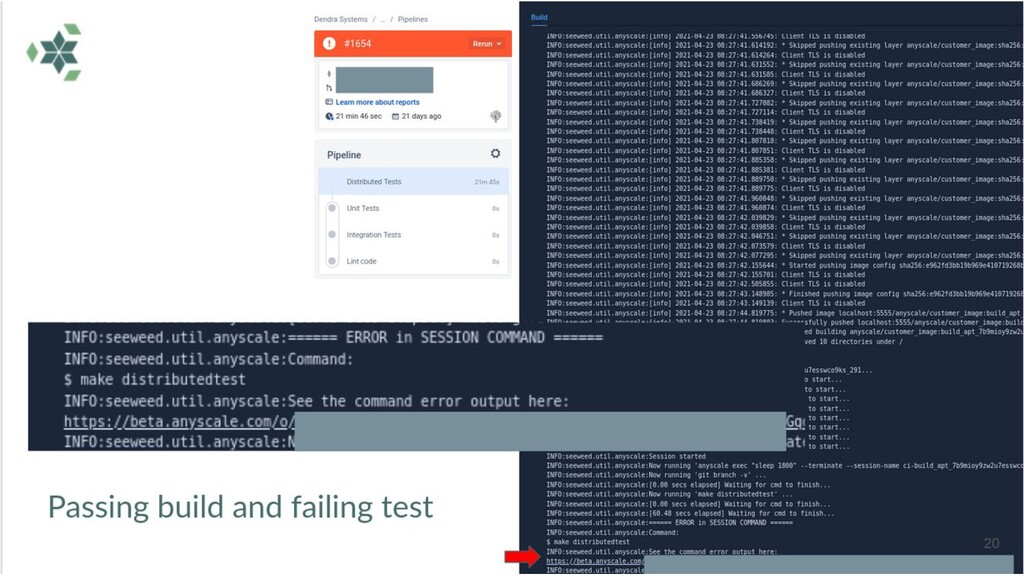
Richard then describes how Anyscale makes it easy to run this Ray application in production: running seamlessly in their BitBucket CI and also supporting a microservice to launch jobs programmatically.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}