Large-scale model training has generally been out of reach for people in open source because it requires an engineer to learn how to set up an infrastructure, how to build composable software systems, and how to set up robust machine learning scripts.
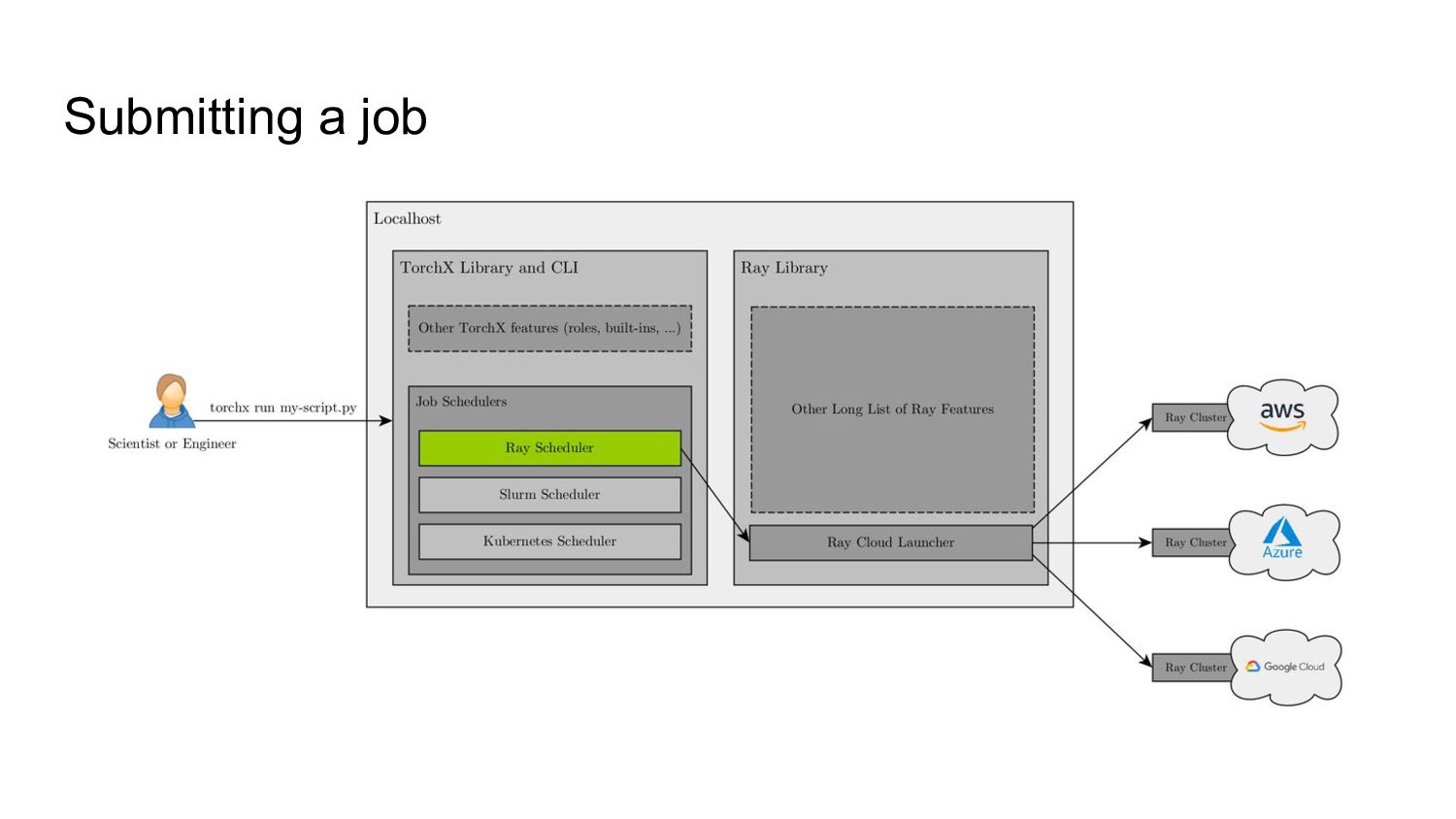
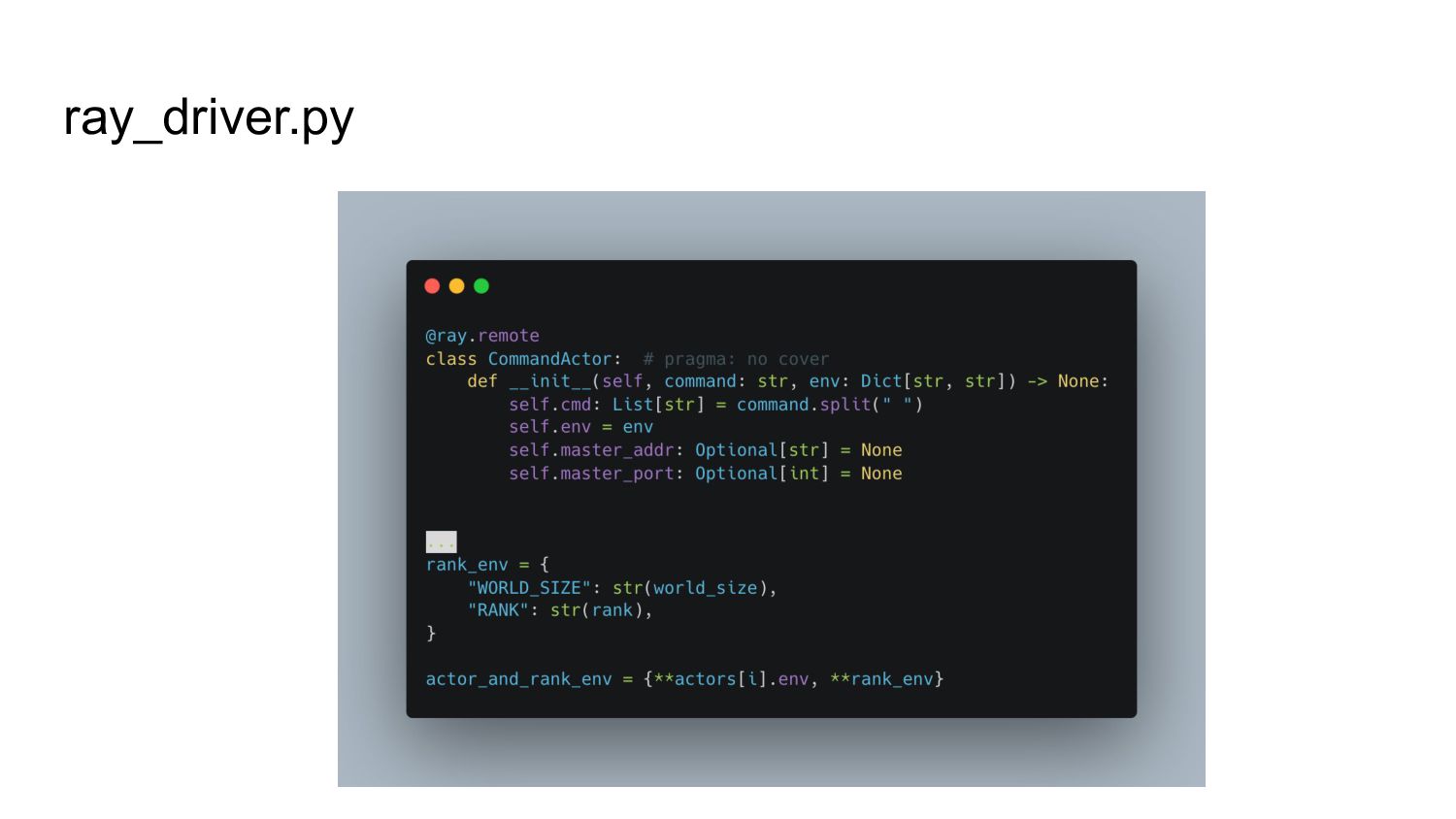
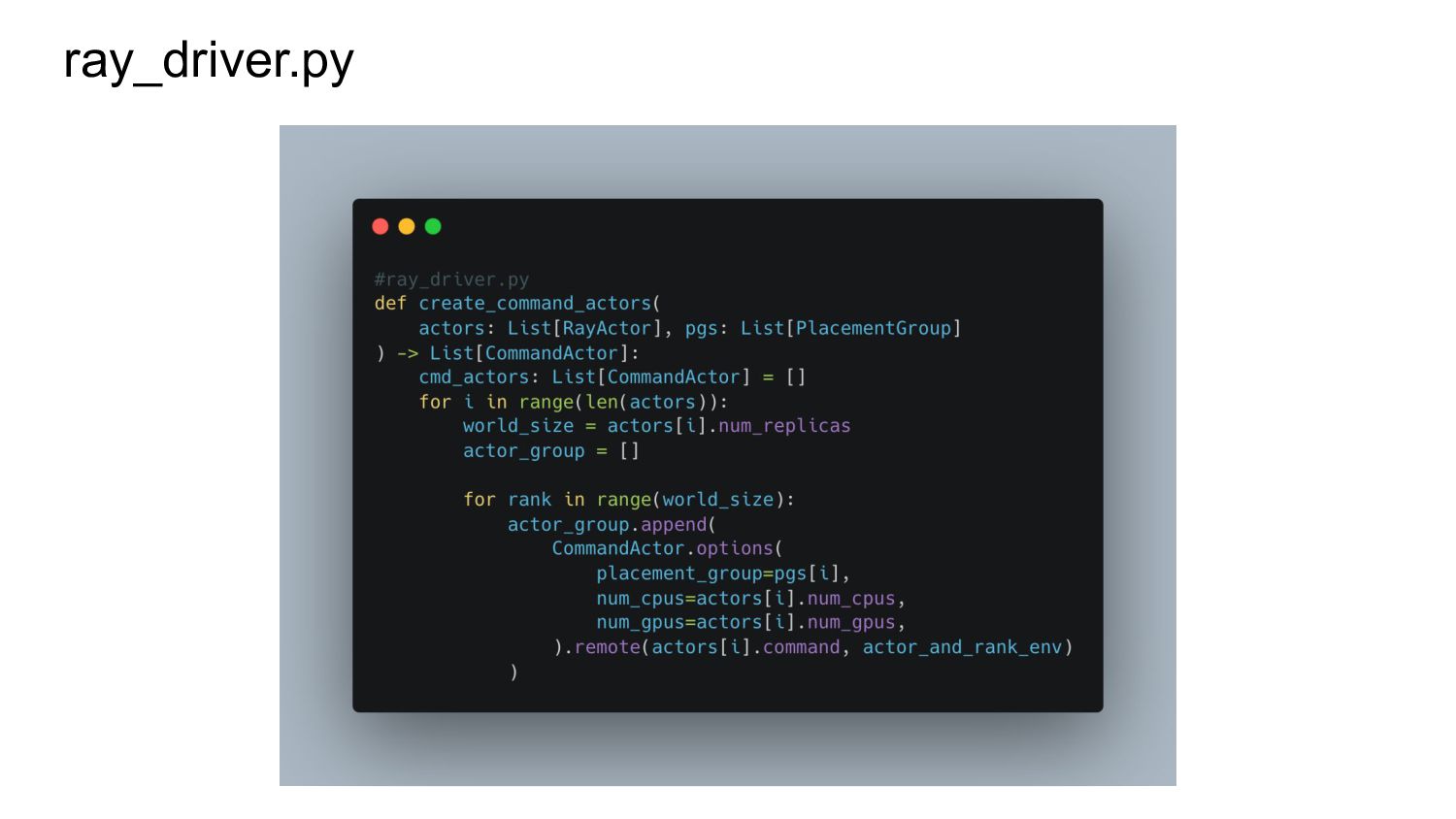
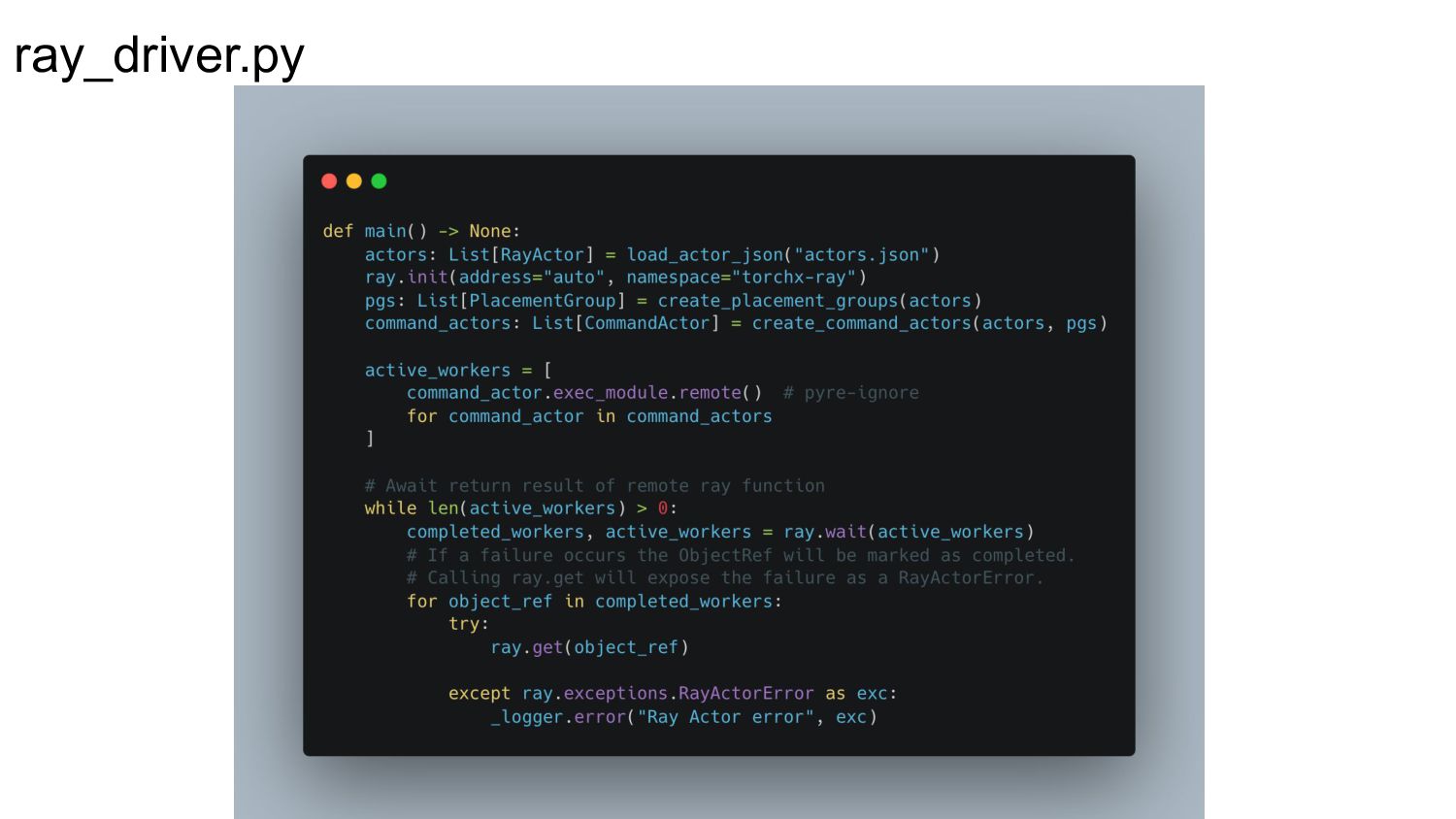
To that end, we’ve built the TorchX Ray scheduler which leverages the newly created Ray Job API to allow scientists to focus on writing their scripts and making infrastructure and systems setup relatively easy.
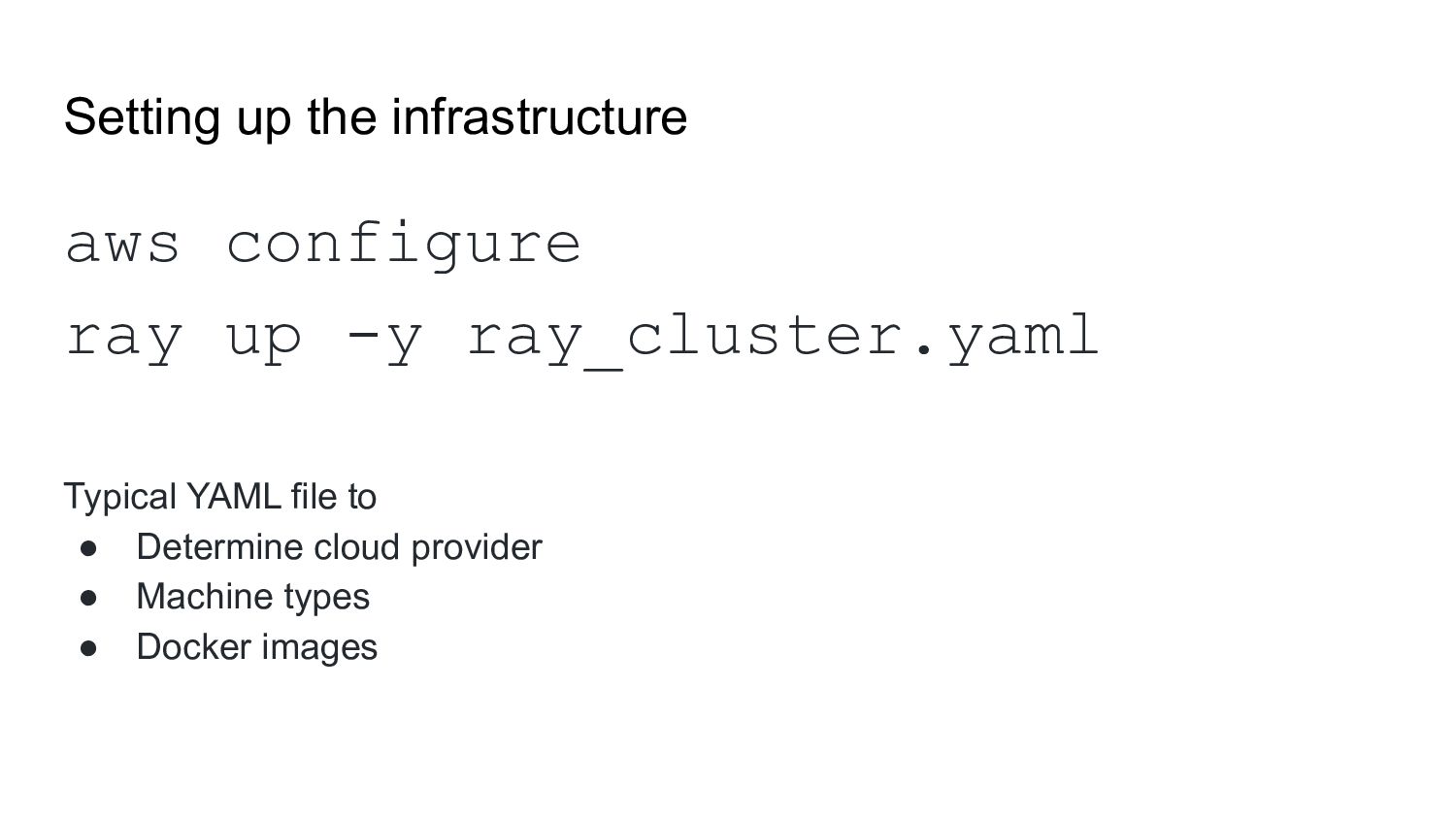
1. Setting up a multi GPU setup on any cloud provider is as easy as calling ray up the cluster.yaml
2. TorchX embraces a component-based approach to designing systems that makes your ops workflows composable
3. Running a distributed PyTorch script is then as simple as calling torchx run
In this session, we’ll go through a practical live demo of how to train multi GPU models, set up the infrastructure live, and provide some tips and best practices to productionize such workflows
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}