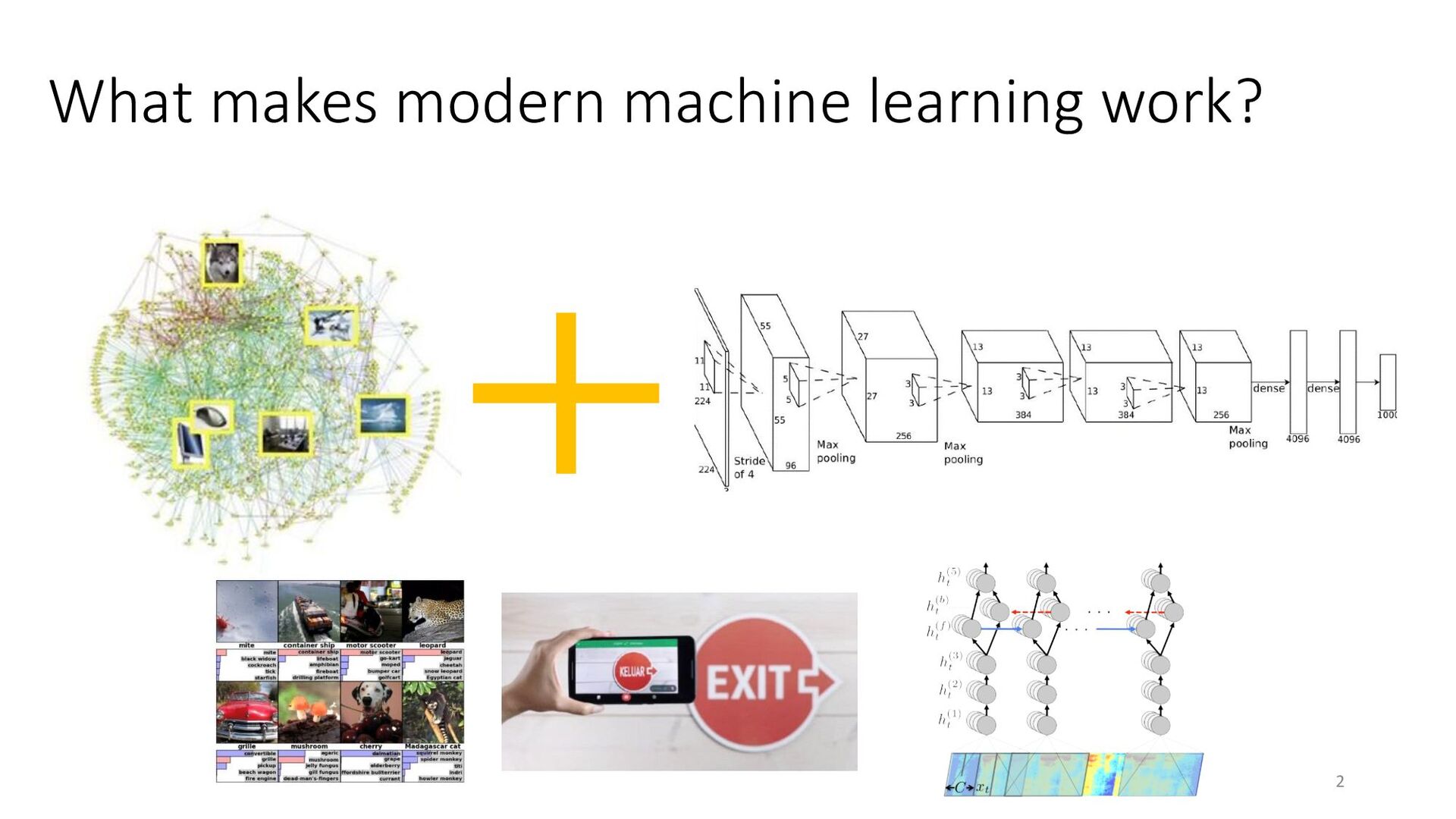
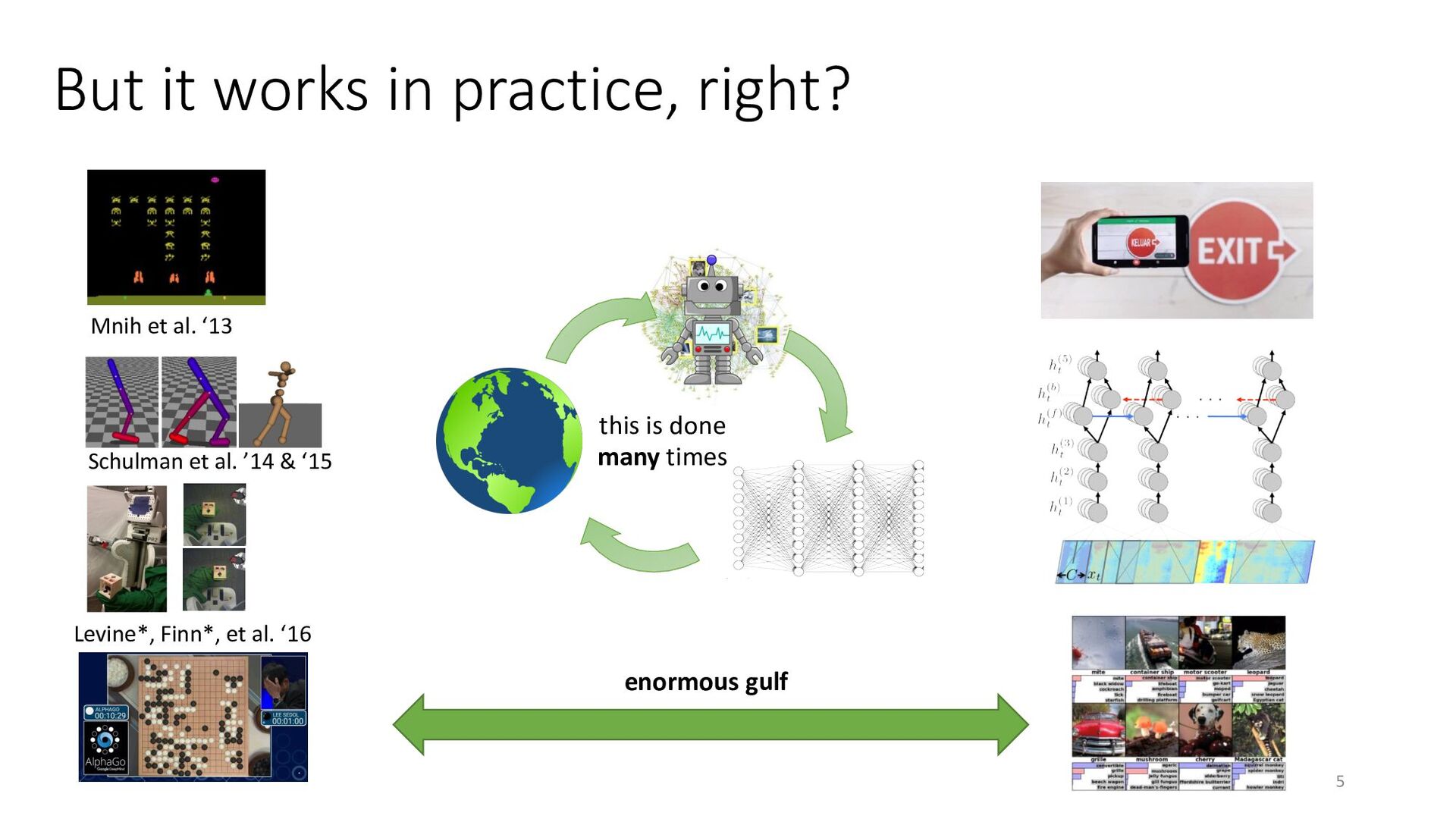
Reinforcement learning (RL) provides an algorithmic framework for rational sequential decision making. However, the kinds of problem domains where RL has been applied successfully seem to differ substantially from the settings where supervised machine learning has been successful. RL algorithms can learn to play Atari or board games, whereas supervised machine learning algorithms can make highly accurate predictions in complex open-world settings.
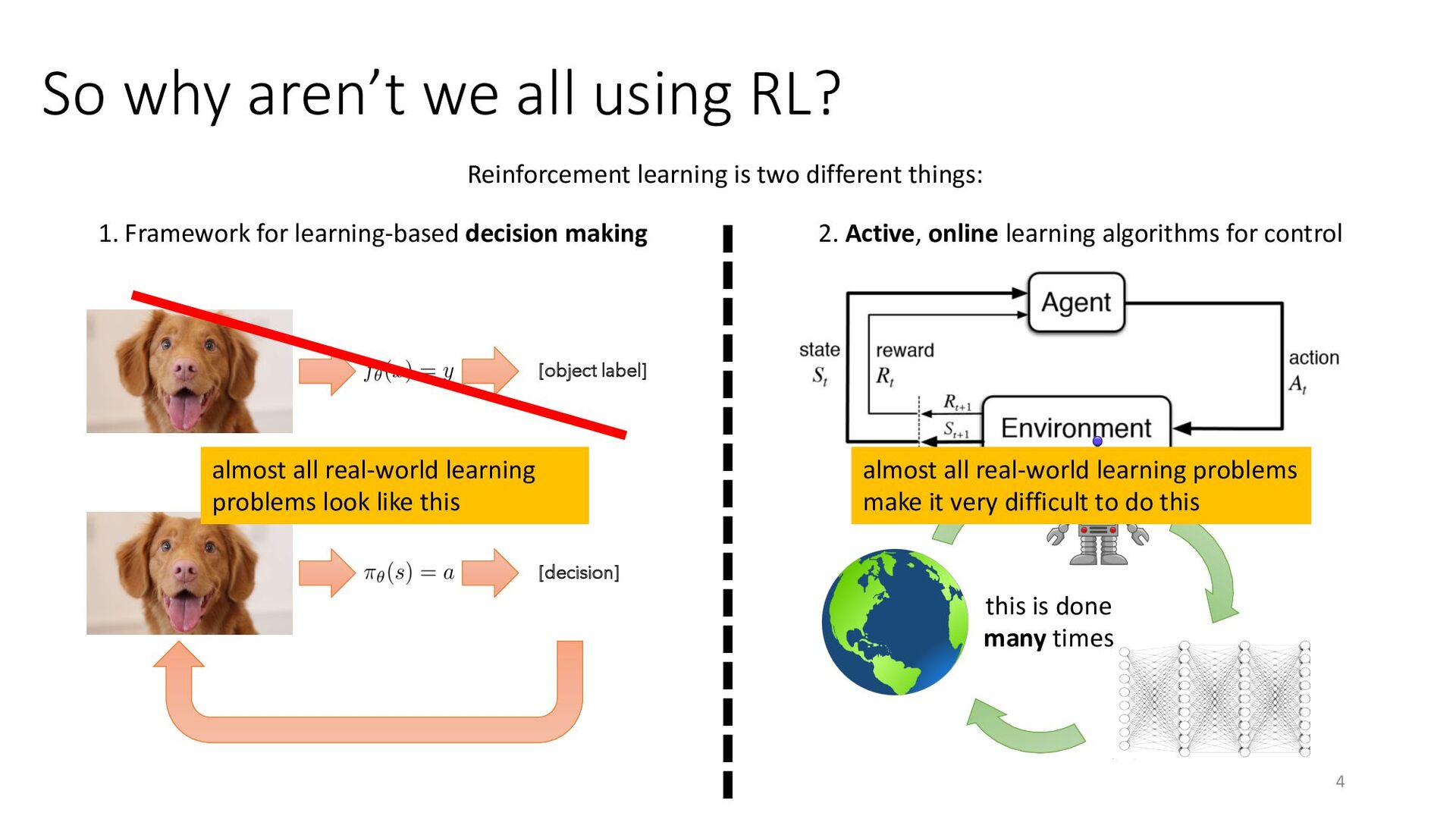
Virtually all the problems that we want to solve with machine learning are really decision making problems — deciding which product to show to a customer, deciding how to tag a photo, or deciding how to translate a string of text — so why aren't we solving them all with RL? One of the biggest issues with modern RL is that it does not effectively utilize the kinds of large and highly diverse datasets that have been instrumental to the success of supervised machine learning.
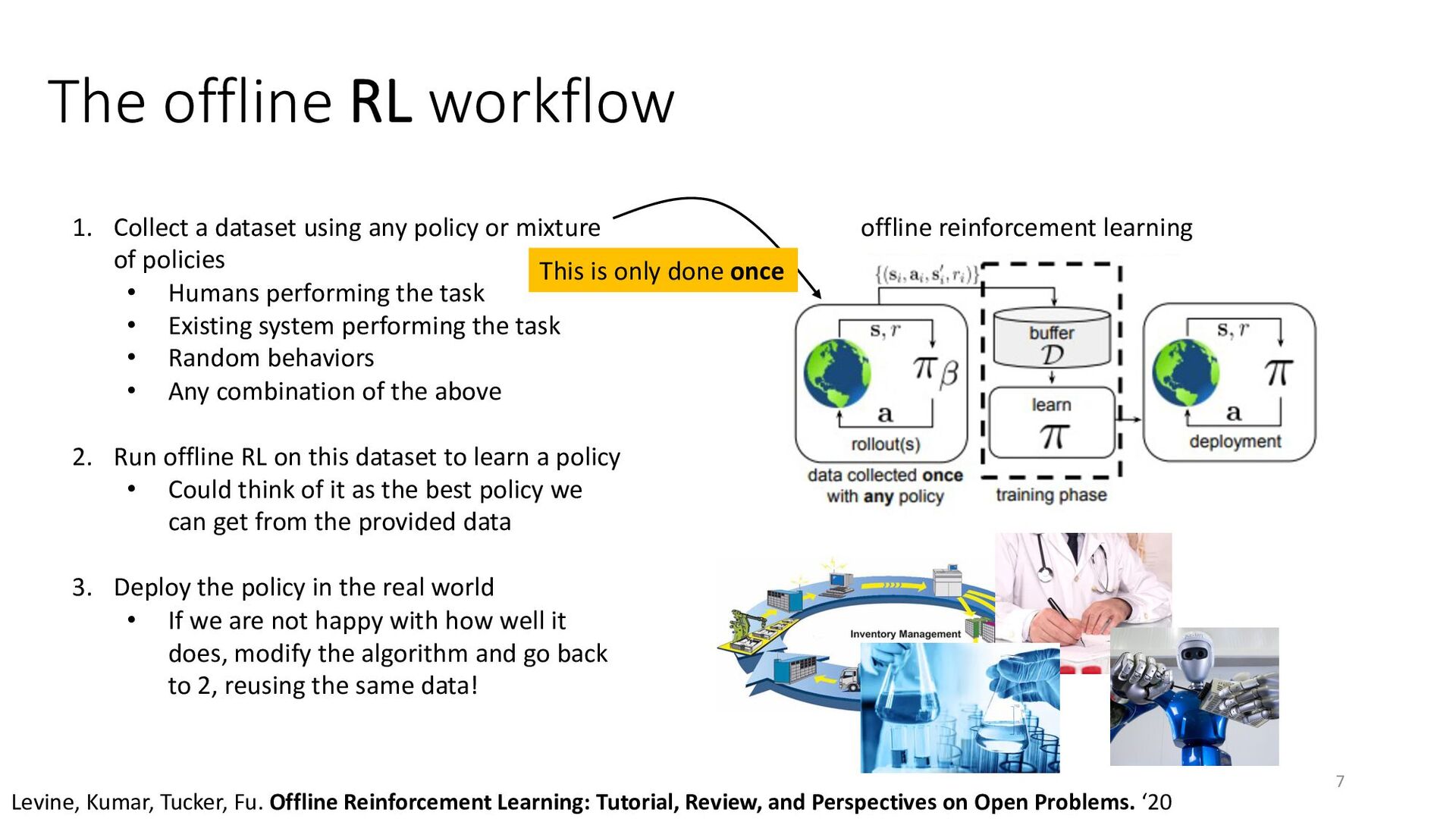
In this talk, I will discuss the technologies that can help us address this issue: enabling RL methods to use large datasets via offline RL. Offline RL algorithms can analyze large, previously collected datasets to extract the most effective policies, and then fine-tune these policies with additional online interaction as needed. I will cover the technical foundations of offline RL, discuss recent algorithm advances, and present several applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![6 Making RL look more like supervised learning [decision] on-policy](https://files.speakerdeck.com/presentations/eca1d80c147b4cd4912f3d2babc5c8b4/slide_5.jpg){kind=link}
{kind=link}
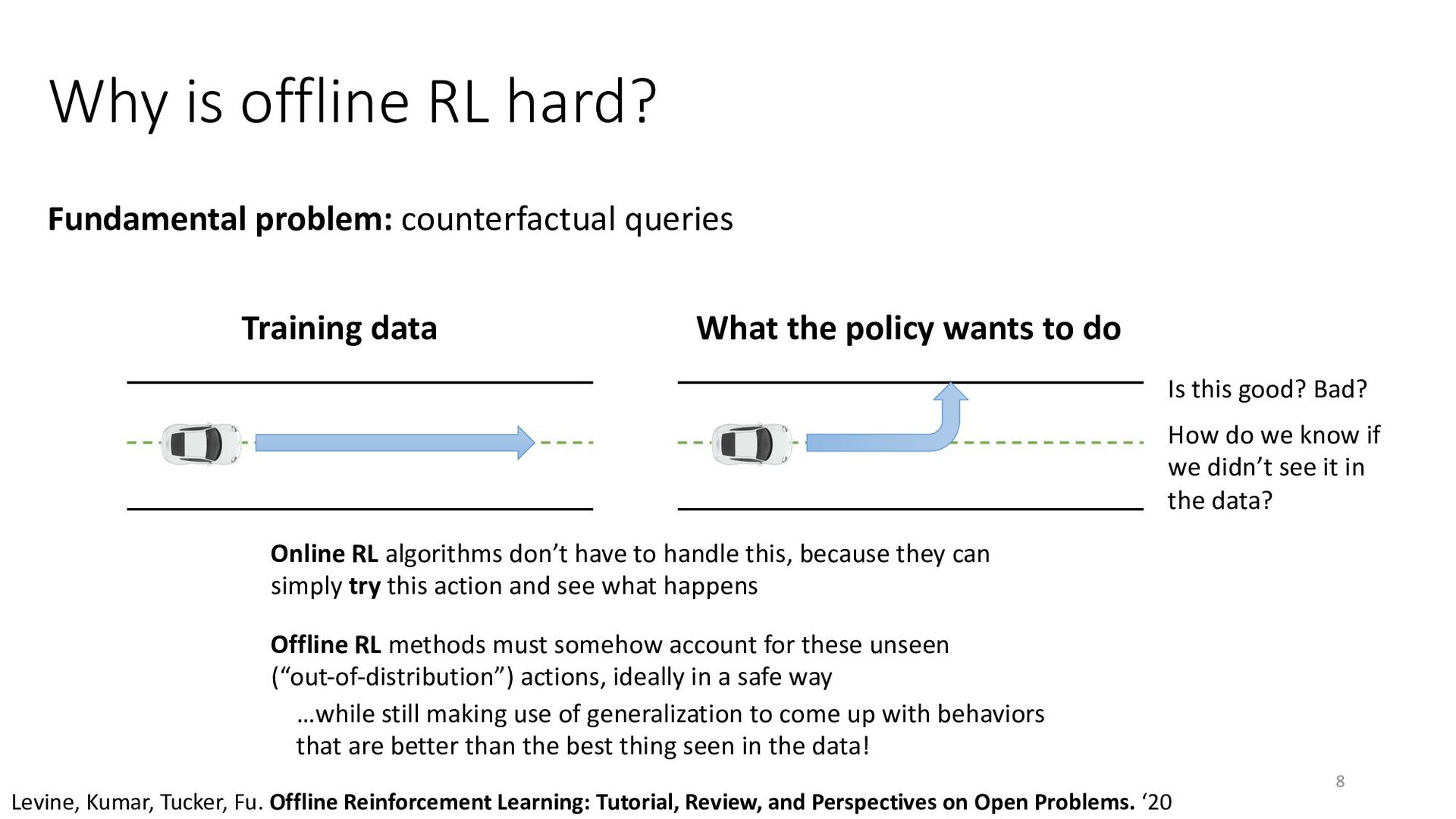{kind=link}
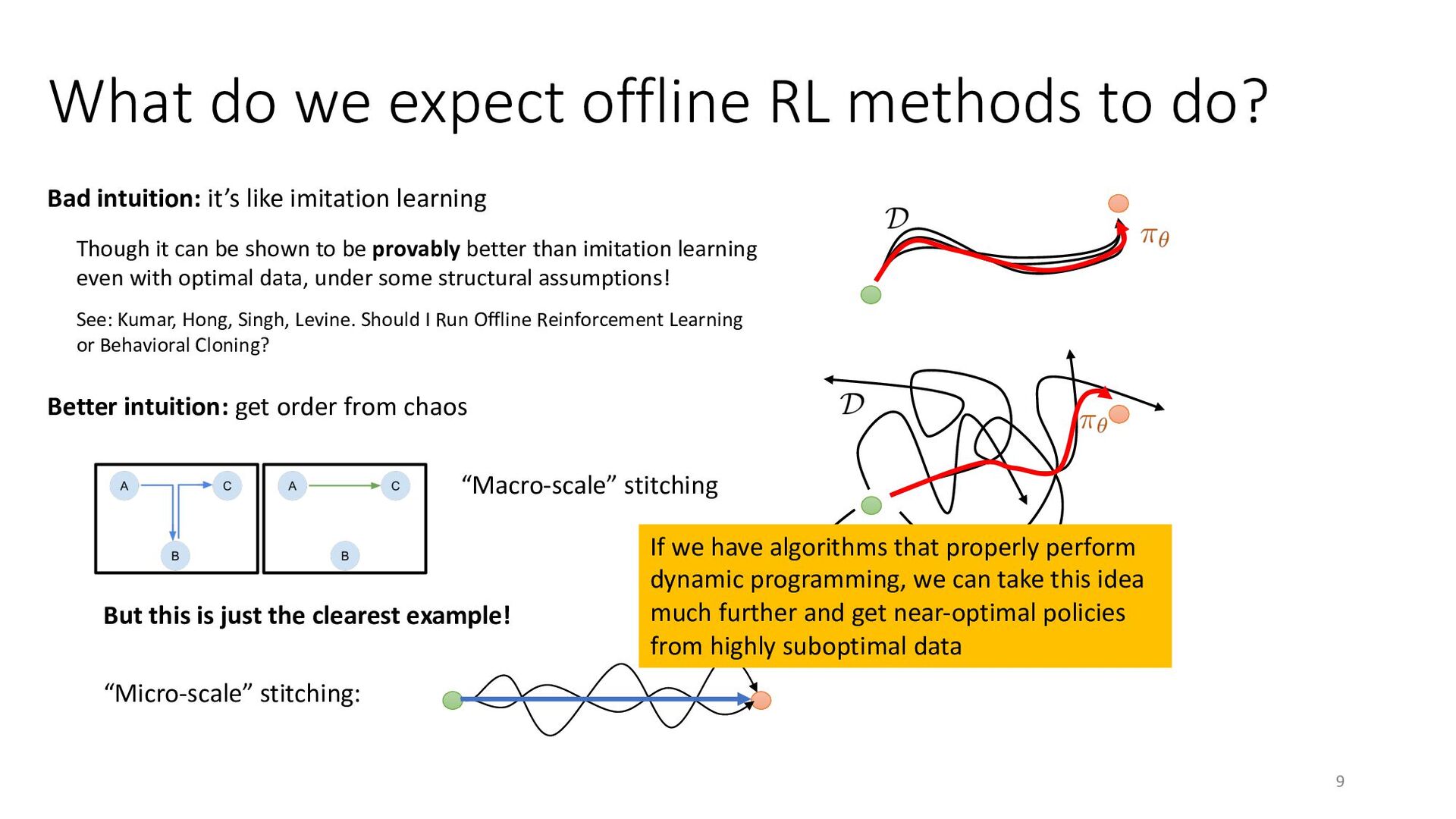{kind=link}
{kind=link}
{kind=link}
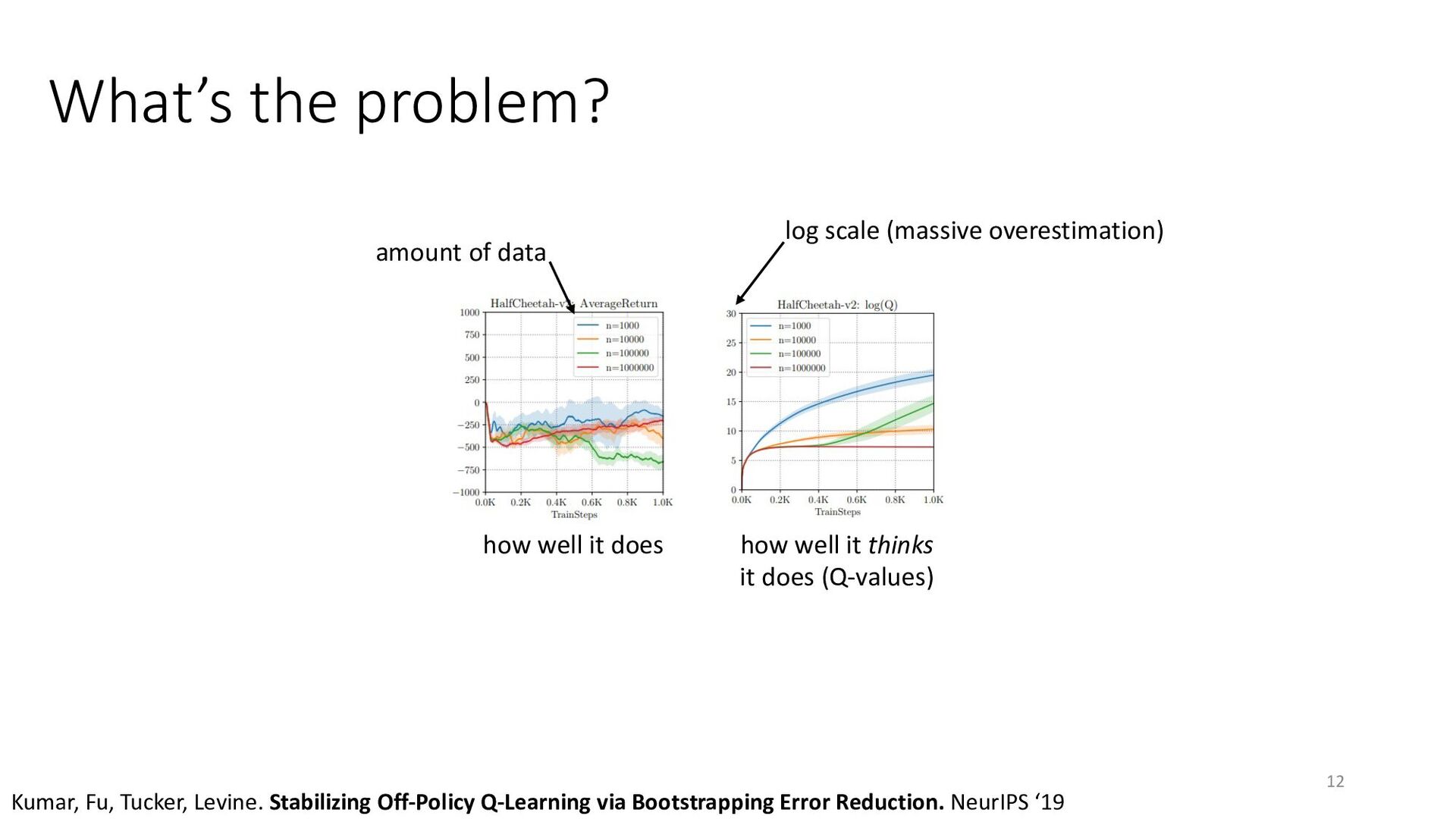{kind=link}
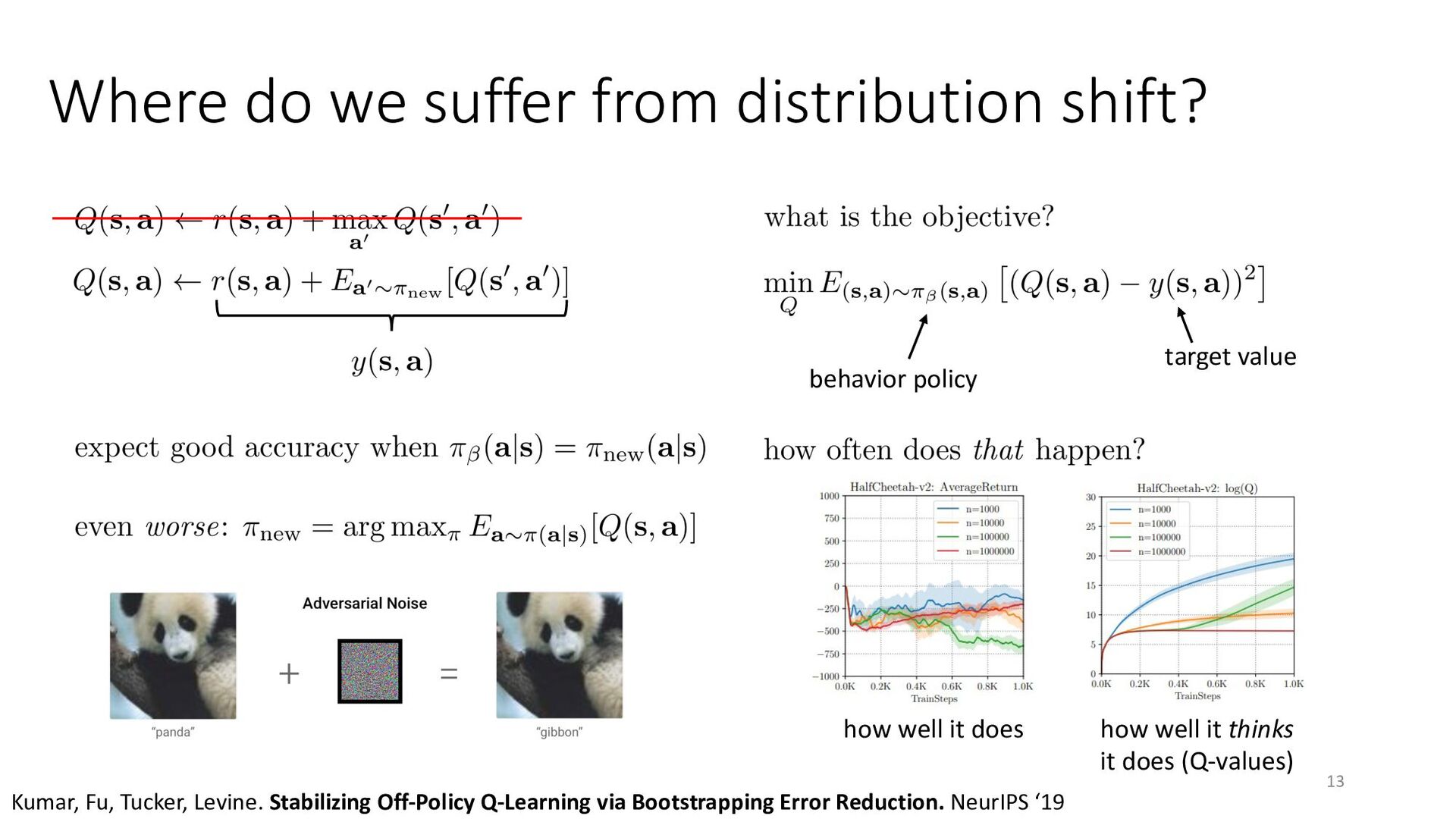{kind=link}
{kind=link}
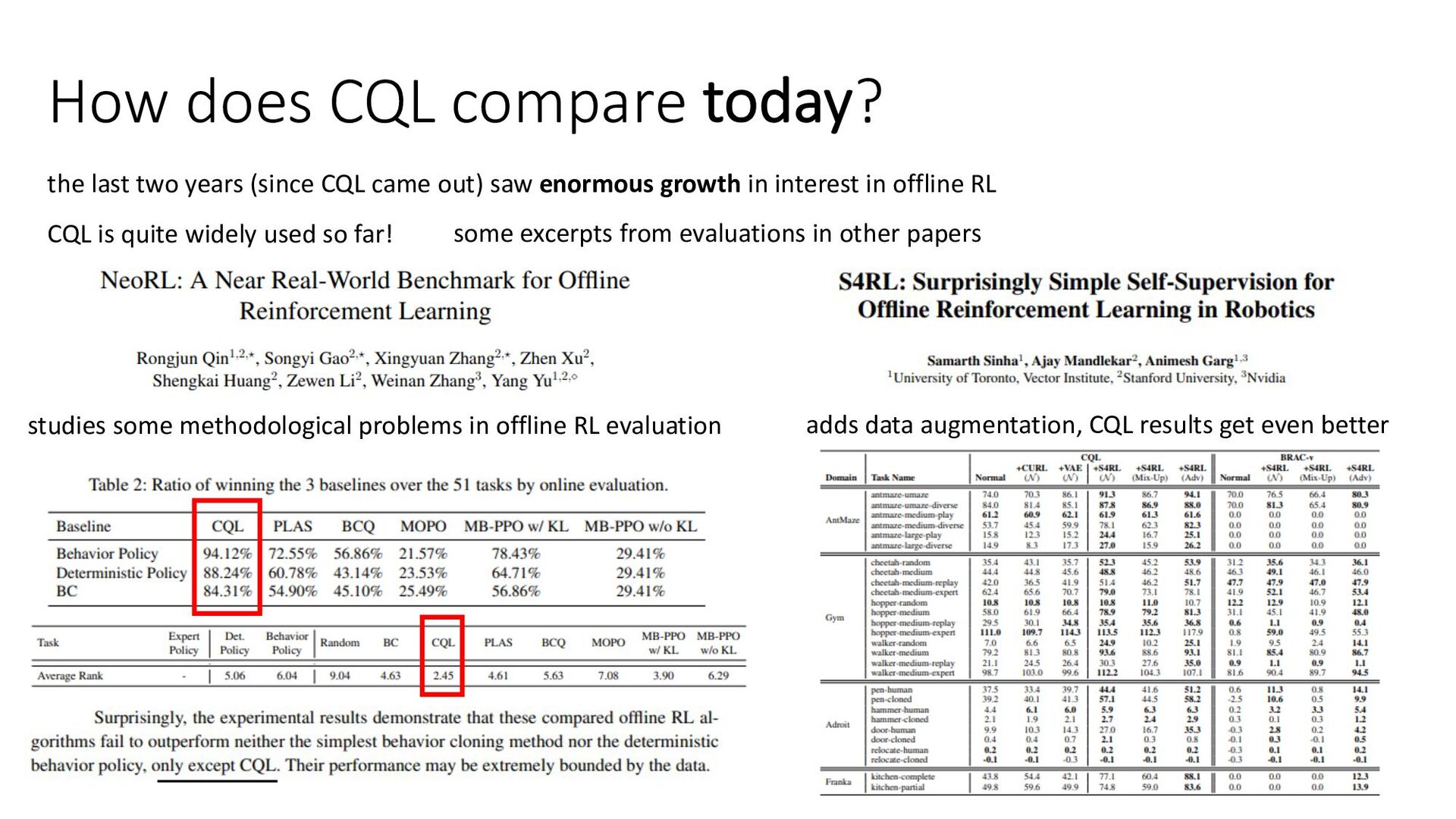{kind=link}
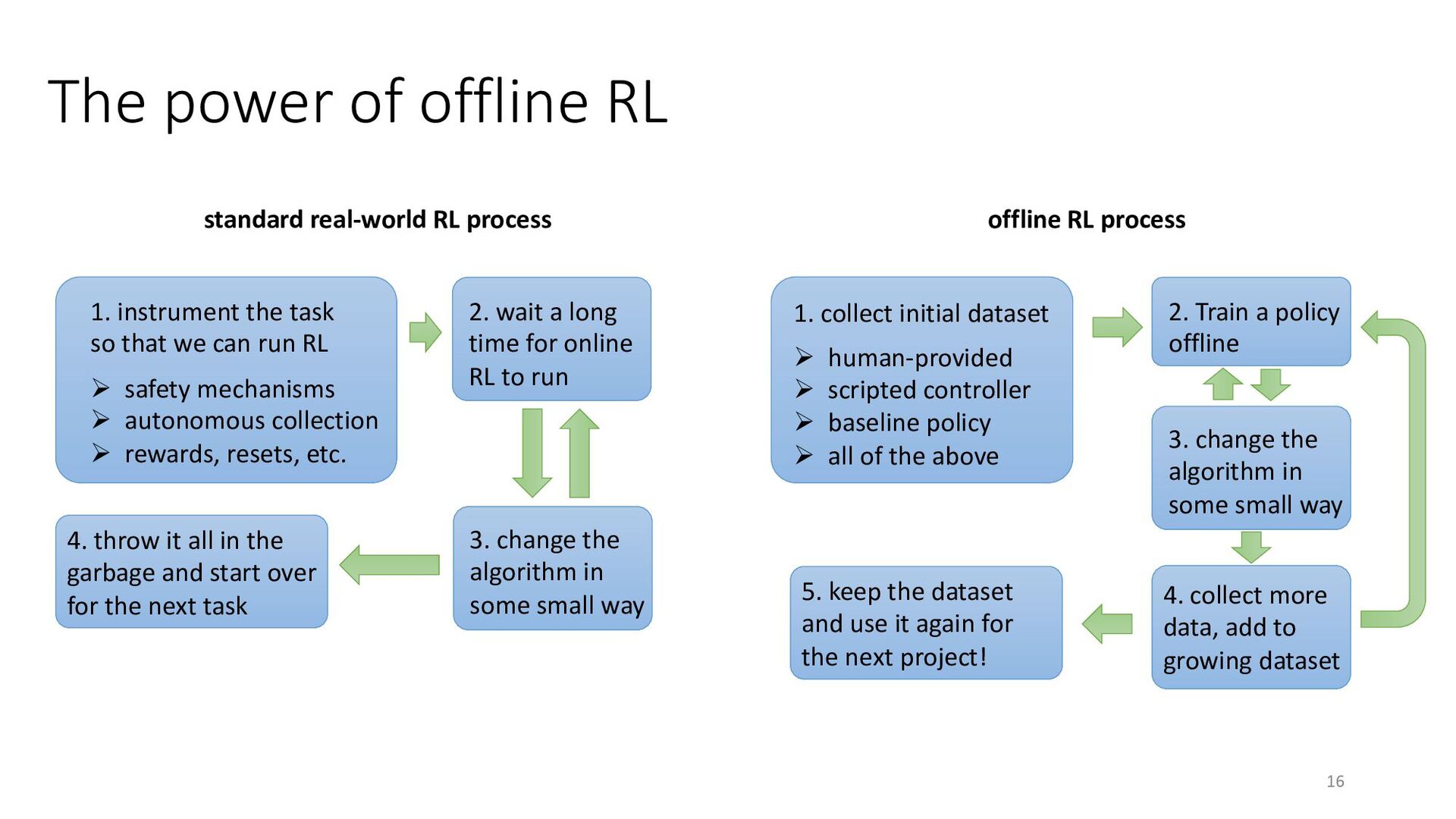{kind=link}
{kind=link}
{kind=link}
{kind=link}
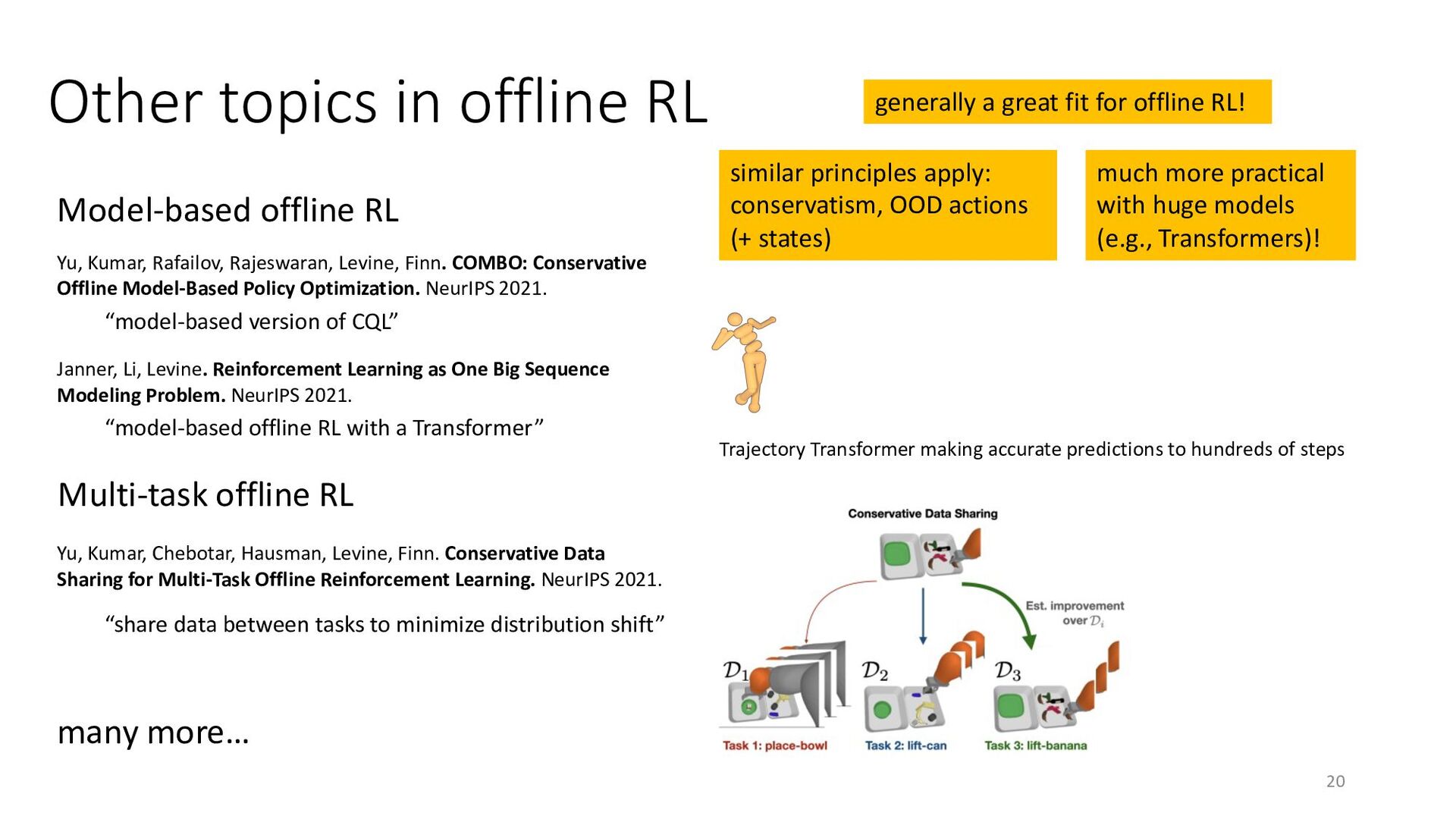{kind=link}
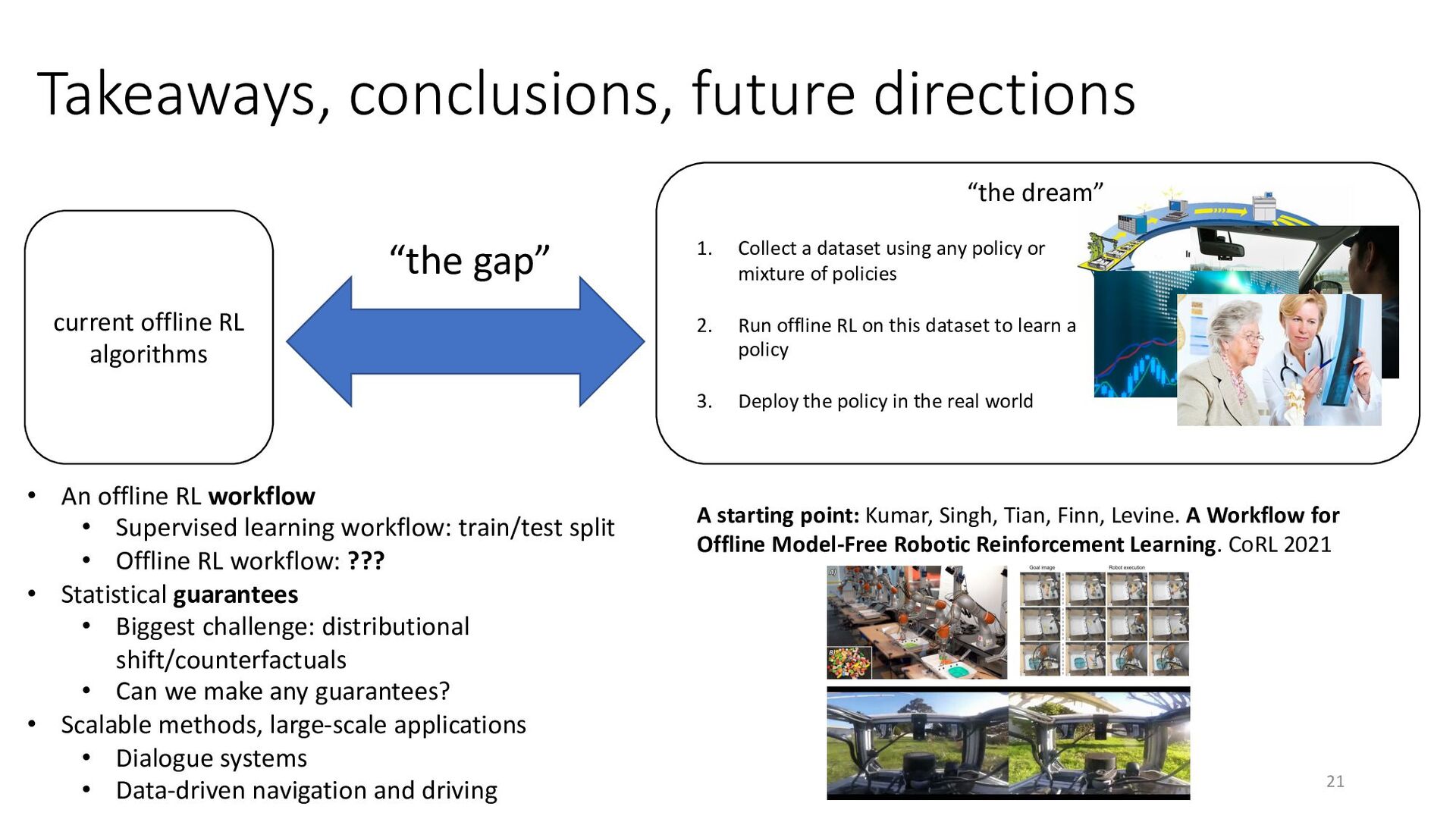{kind=link}
{kind=link}