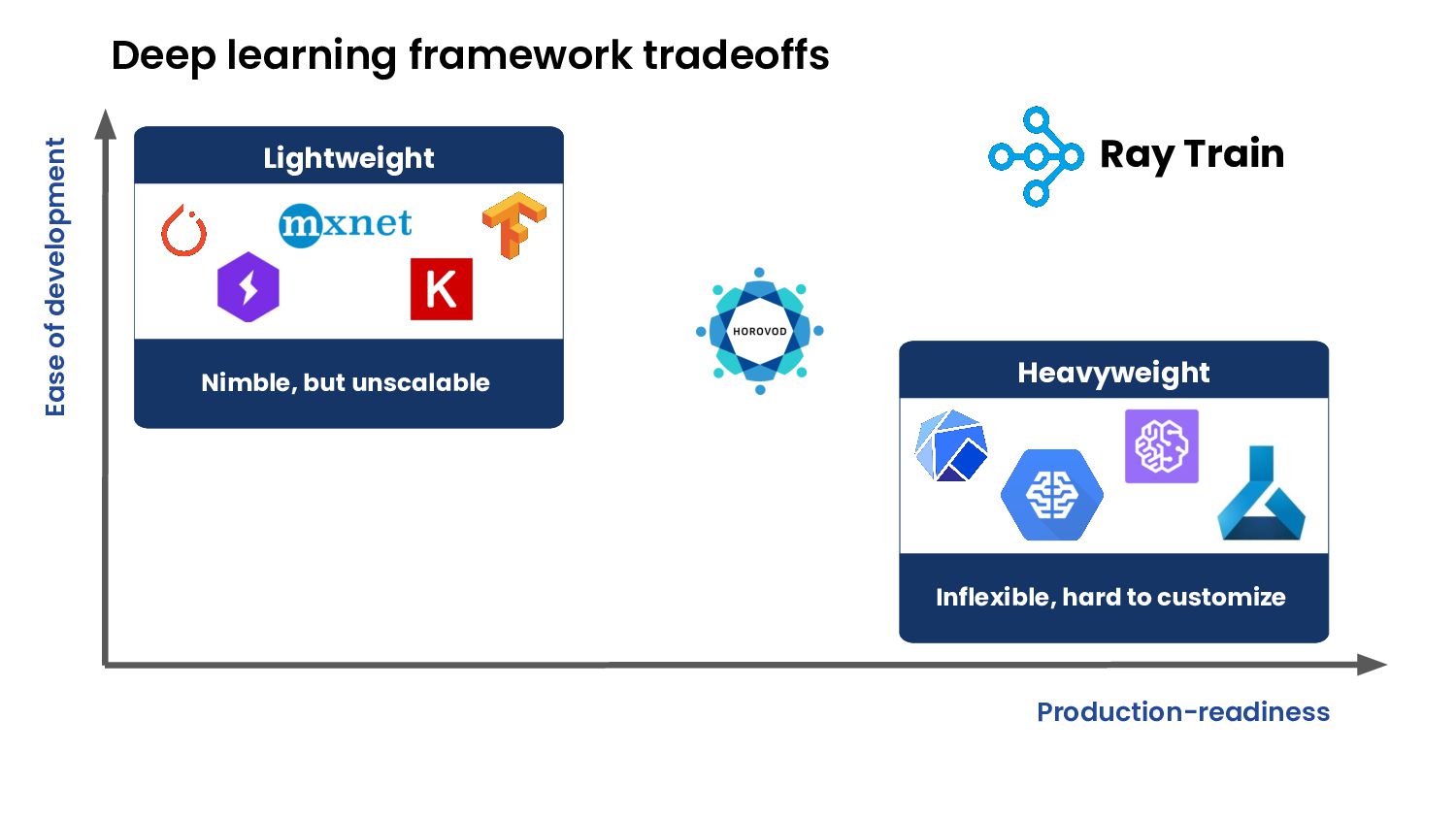
Today, most frameworks for deep learning prototyping, training, and distributing to a cluster are either powerful and inflexible, or nimble and toy-like. Data scientists are forced to choose between a great developer experience and a production-ready framework.
To fix this gap, the Ray ML team has developed Ray Train.
Ray Train is a library built on top of the Ray ecosystem that simplifies distributed deep learning. Currently in stable beta in Ray 1.9, Ray Train offers the following features:
- Scales to multi-GPU and multi-node training with zero code changes
- Runs seamlessly on any cloud (AWS, GCP, Azure, Kubernetes, or on-prem)
- Supports PyTorch, TensorFlow, and Horovod
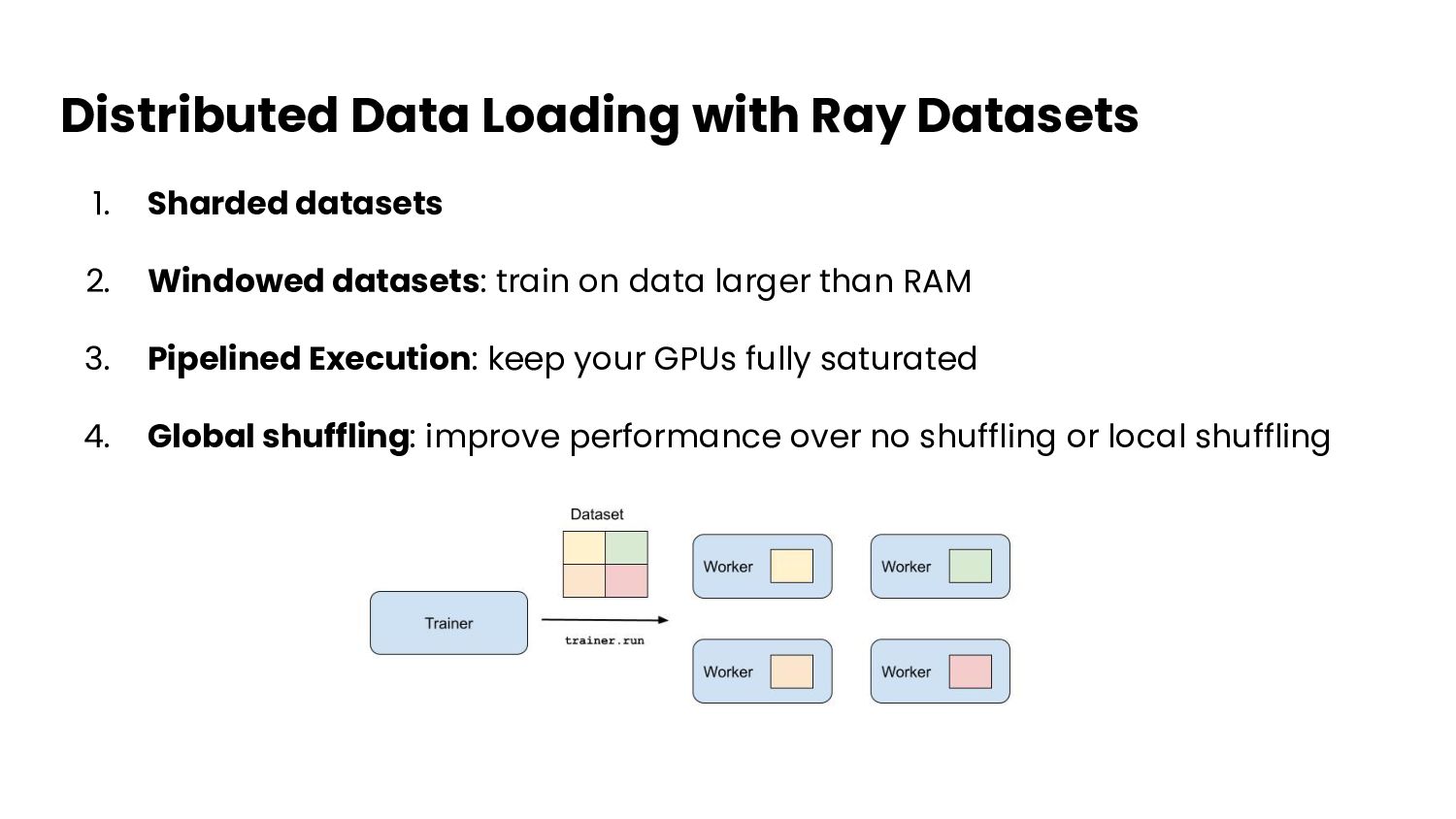
- Distributed data shuffling and loading with Ray Datasets
- Distributed hyperparameter tuning with Ray Tune
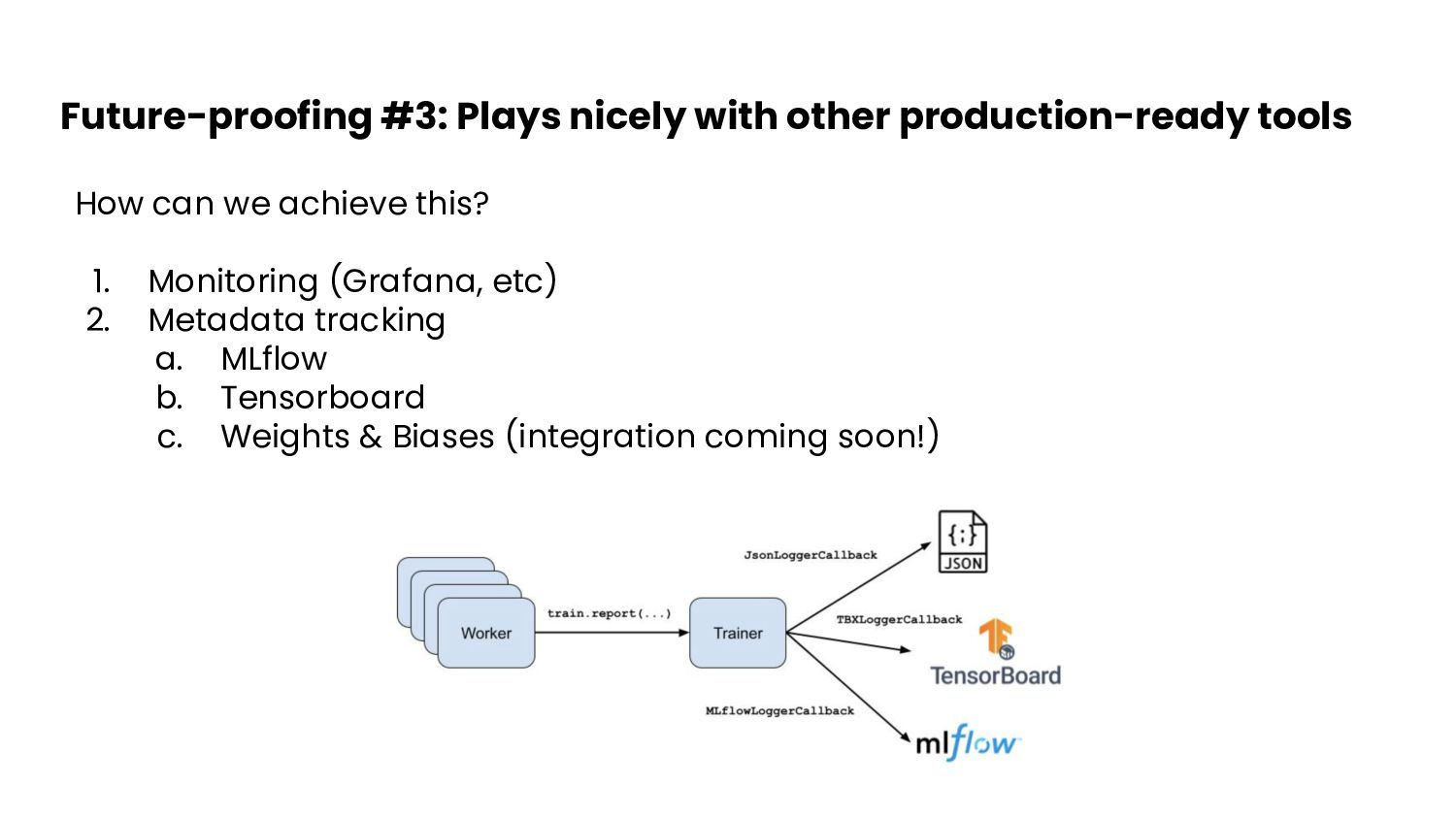
- Built-in loggers for TensorBoard and MLflow
In this webinar, we'll talk through some of the challenges in large-scale computer vision ML training, and show a demo of Ray Train in action.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}