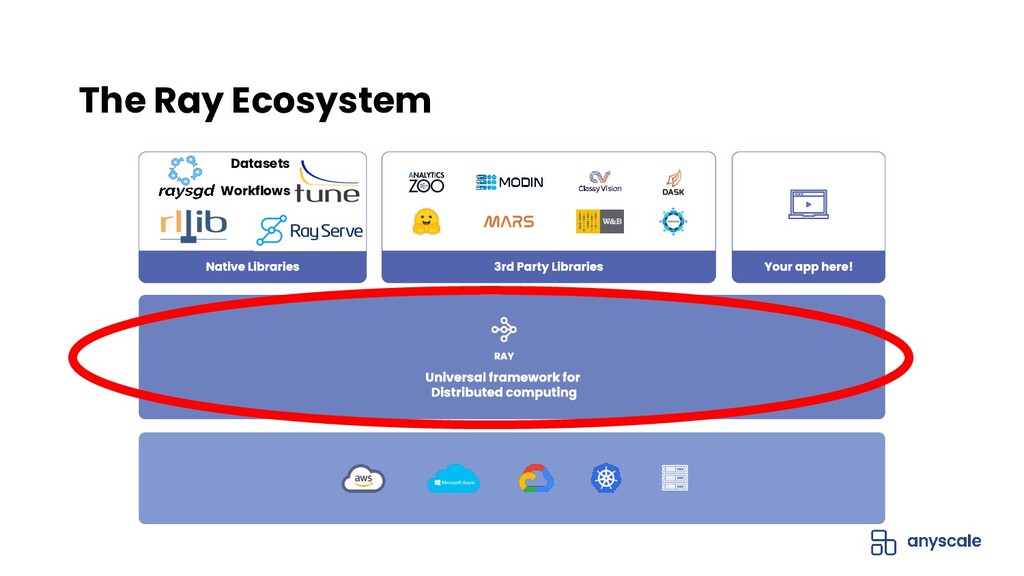
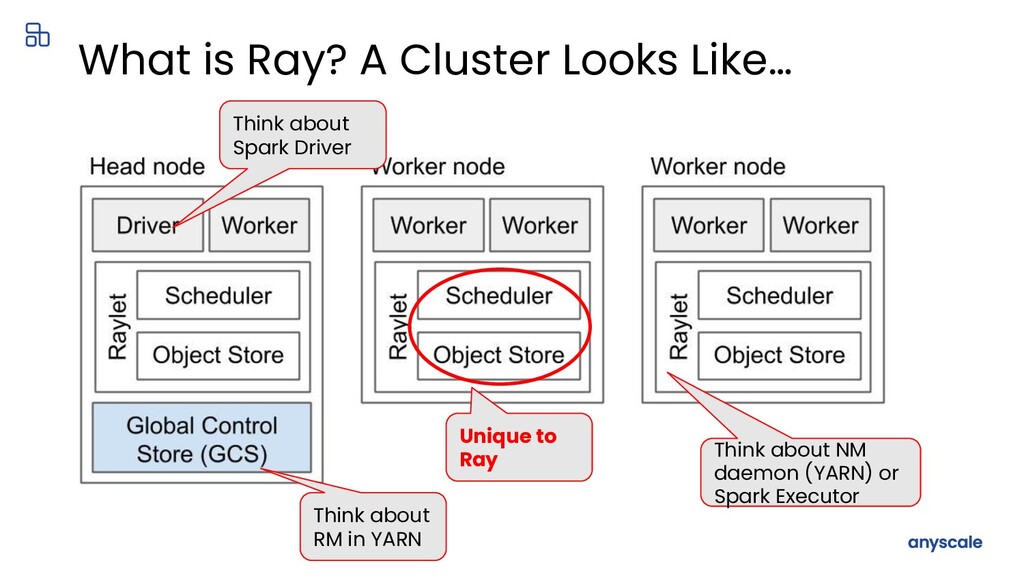
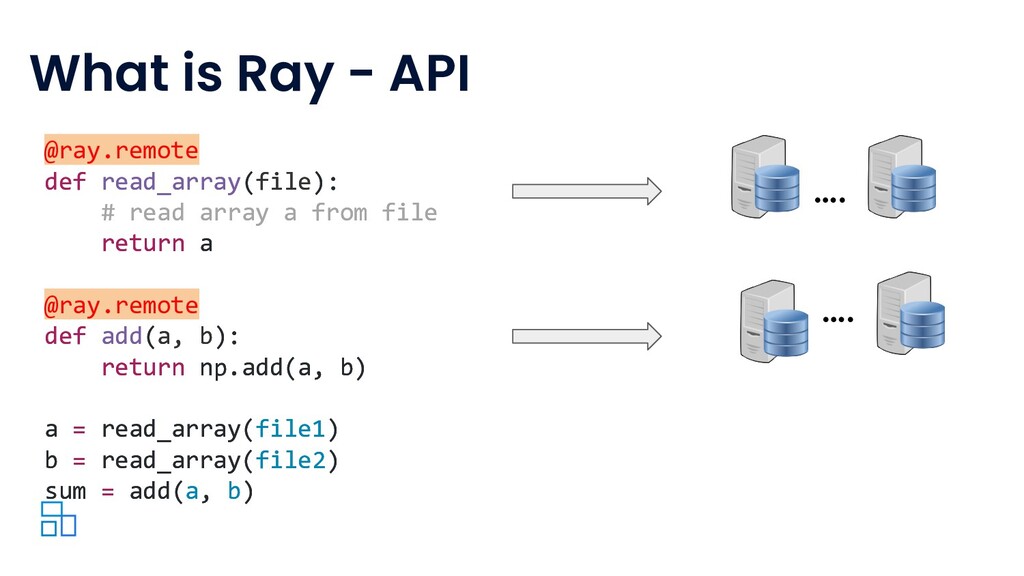
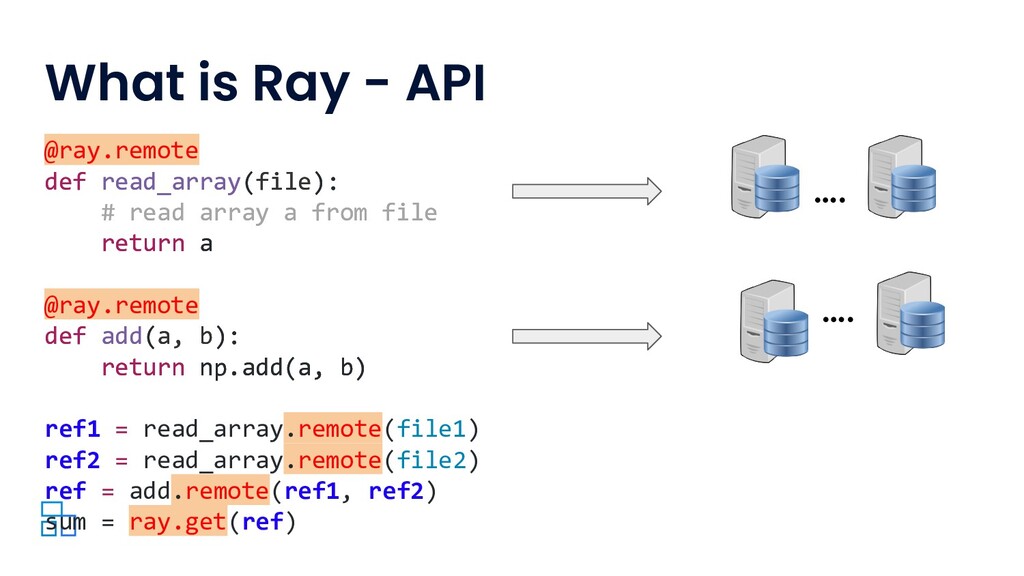
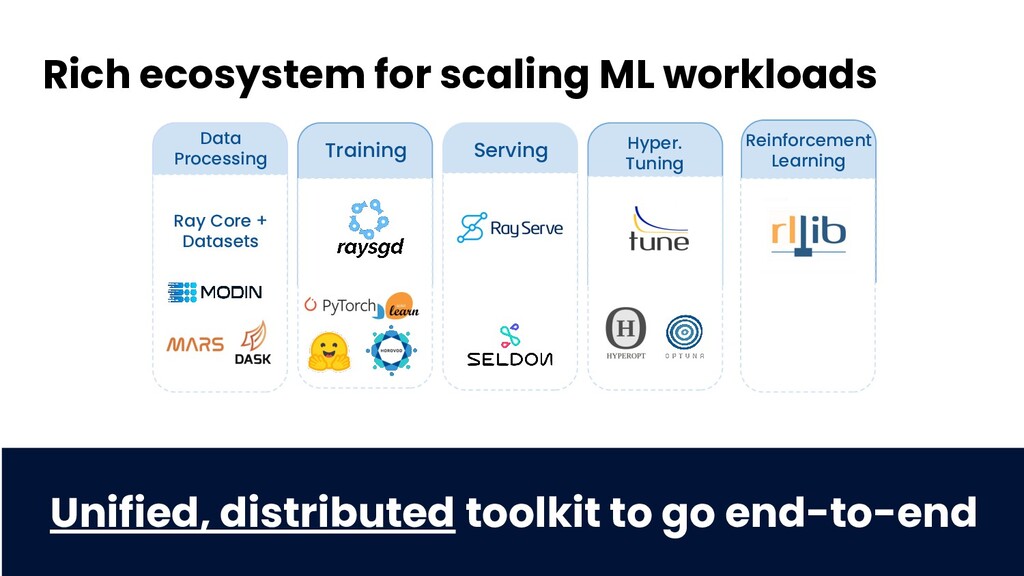
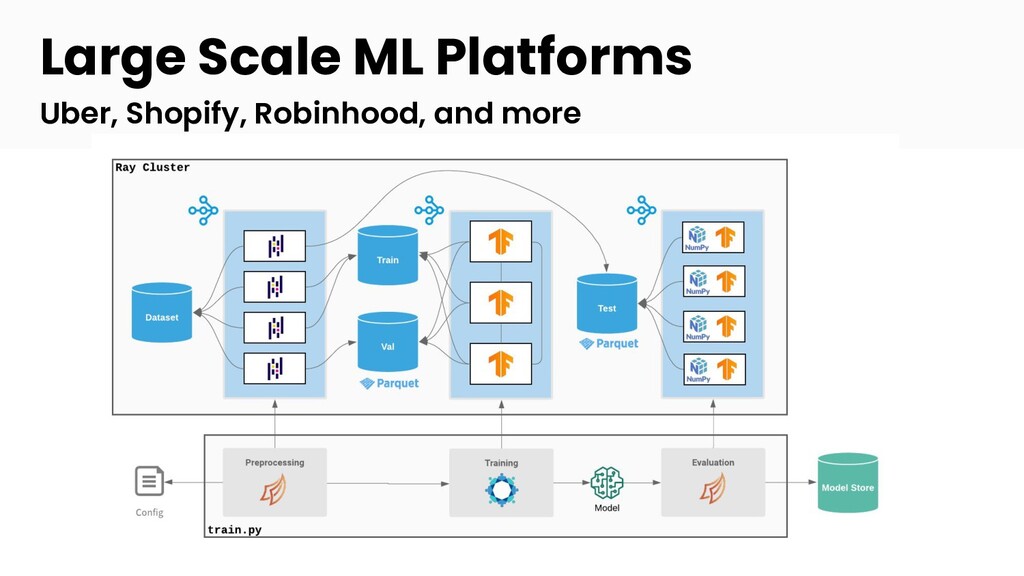
Modern machine learning (ML) workloads, such as deep learning and large-scale model training, are compute-intensive and require distributed execution. Ray was created in the UC Berkeley RISELab to make it easy for every engineer to scale their applications and ML workloads, without requiring any distributed systems expertise, making distributed programming easy.
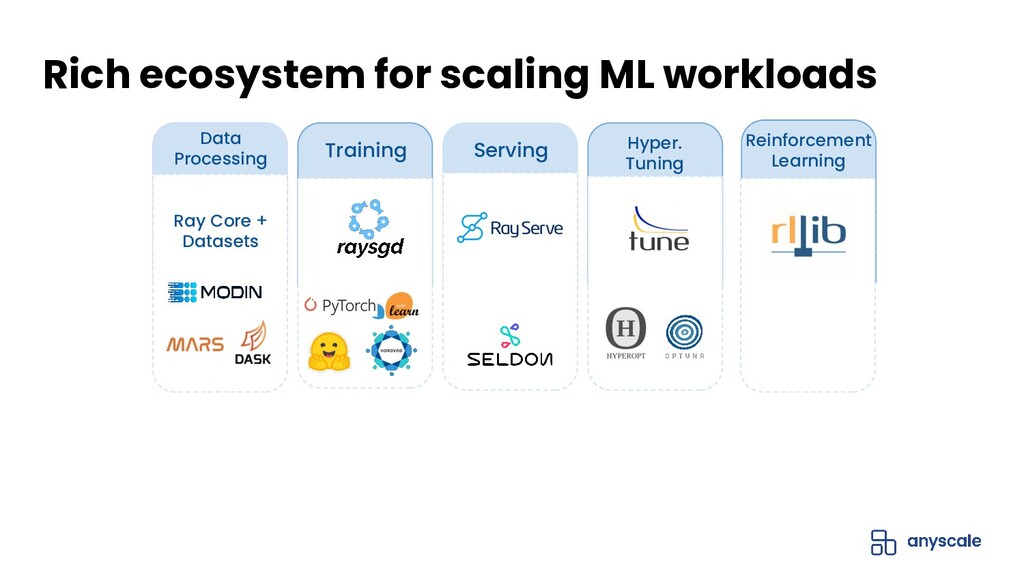
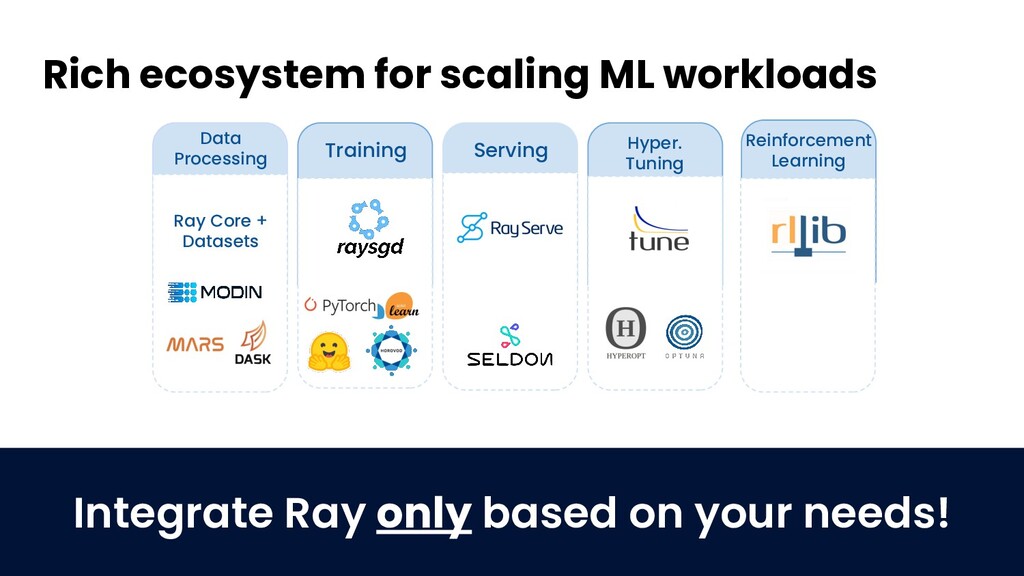
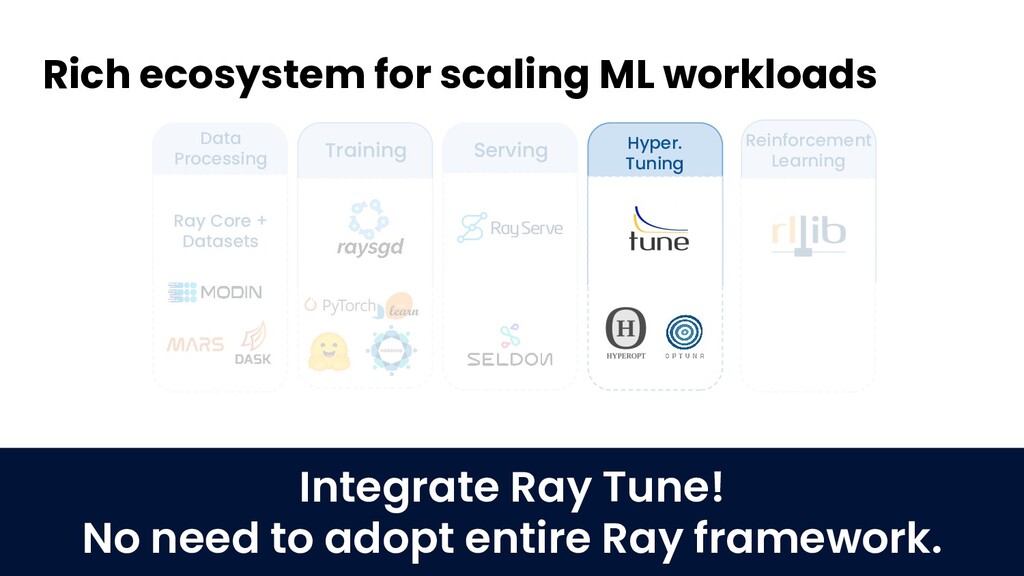
Join Jules S. Damji, developer advocate at Anyscale, and Antoni Baum, software engineer at Anyscale, for an introduction to Ray for scaling your ML workloads. Learn how Ray libraries (eg., Ray Tune, Ray Serve, etc) help you easily scale every step of your ML pipeline — from model training and hyperparameter search to inference and production serving.
Highlights include:
- Ray overview & core concepts
- Library ecosystem and use cases
- Demo: Ray for scaling ML workflows
- Getting started resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}