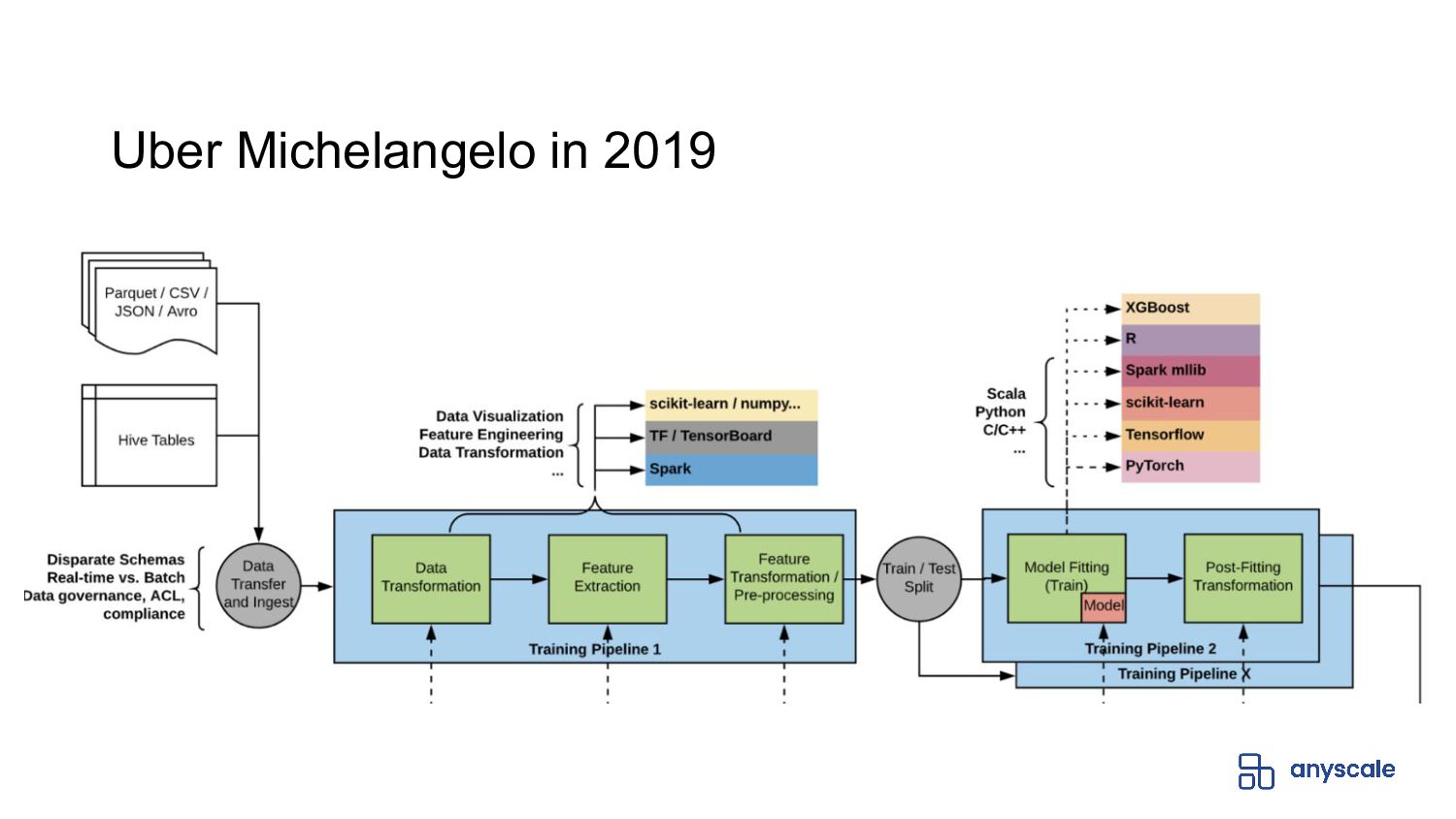
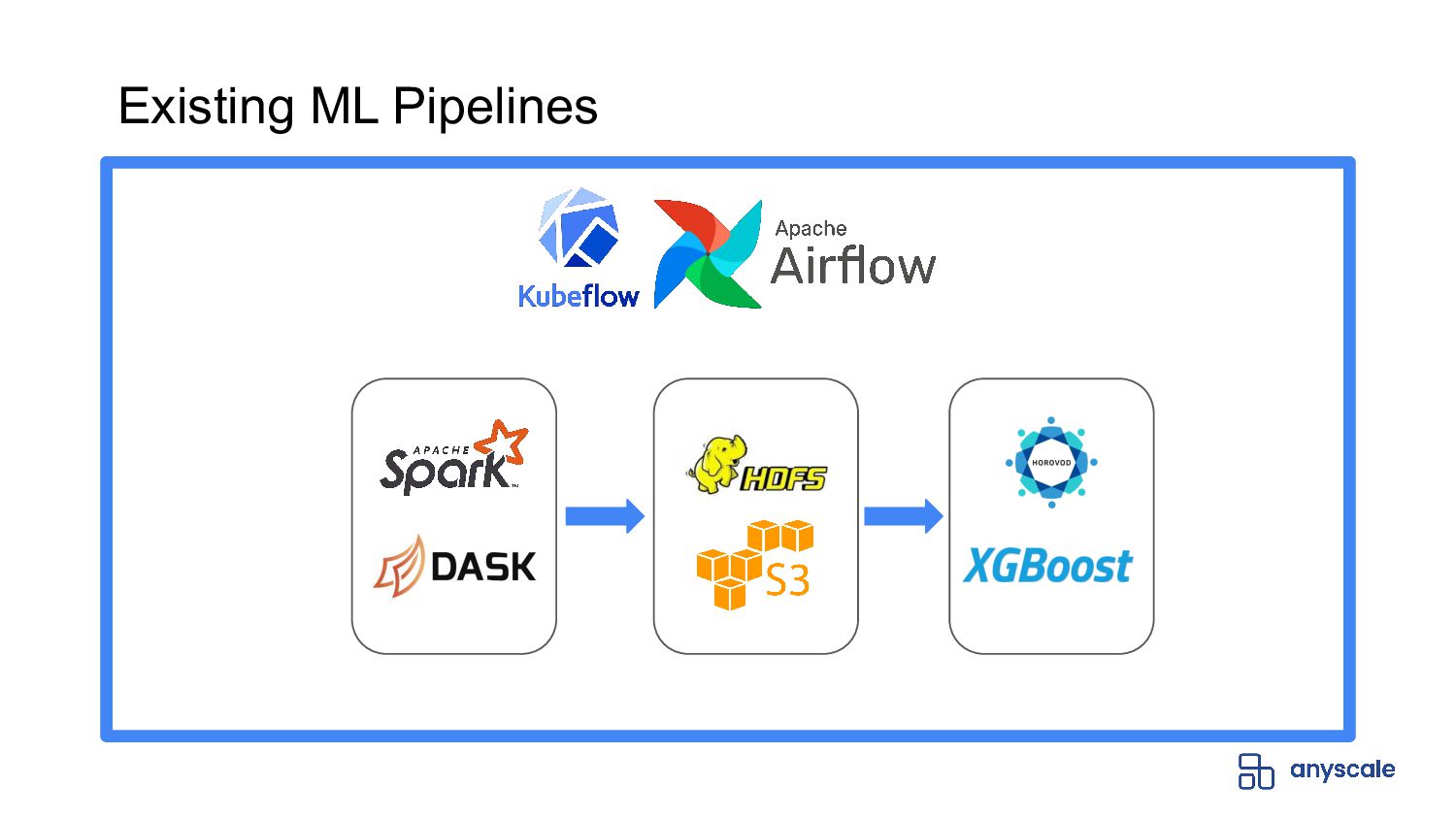
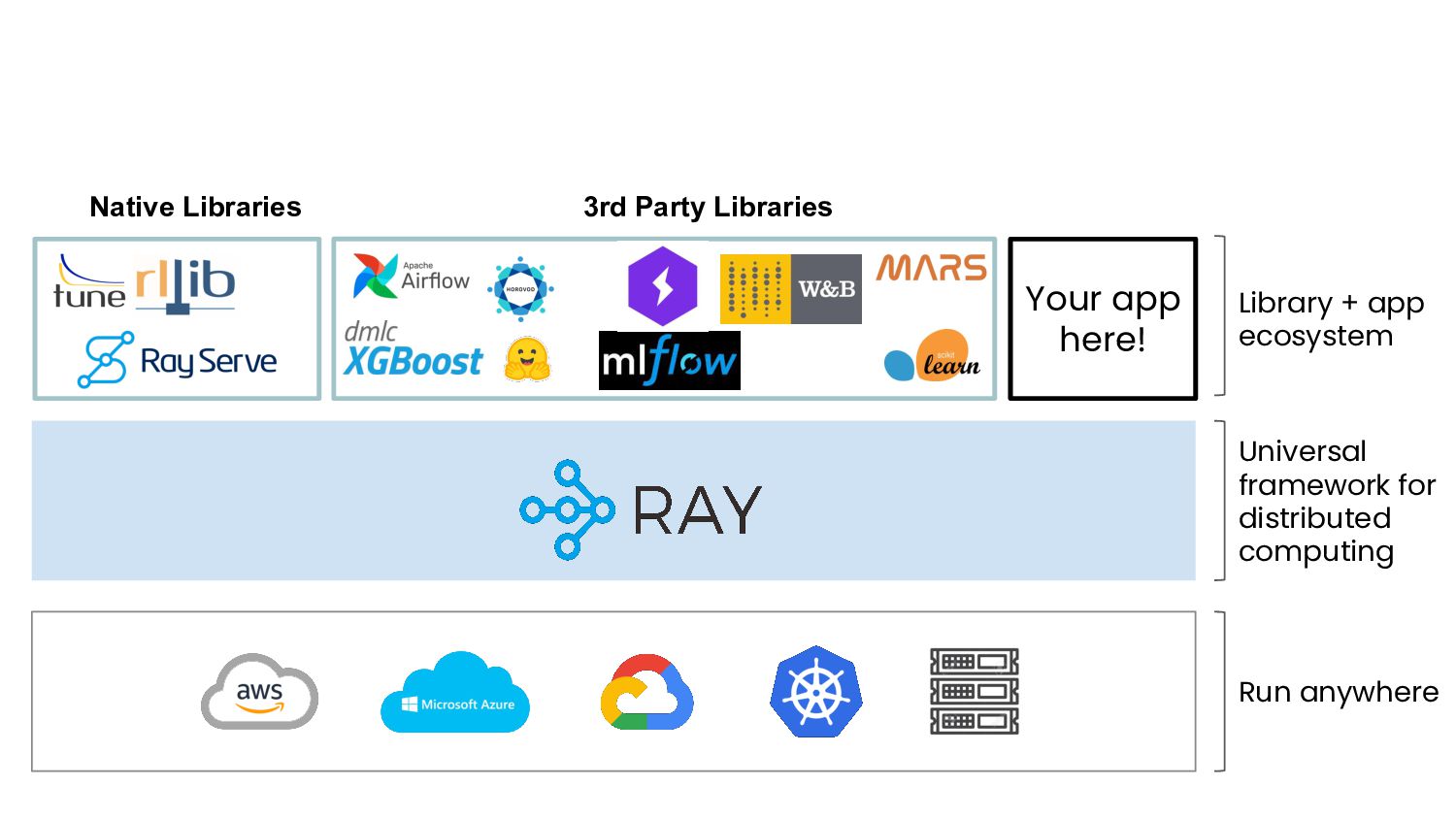
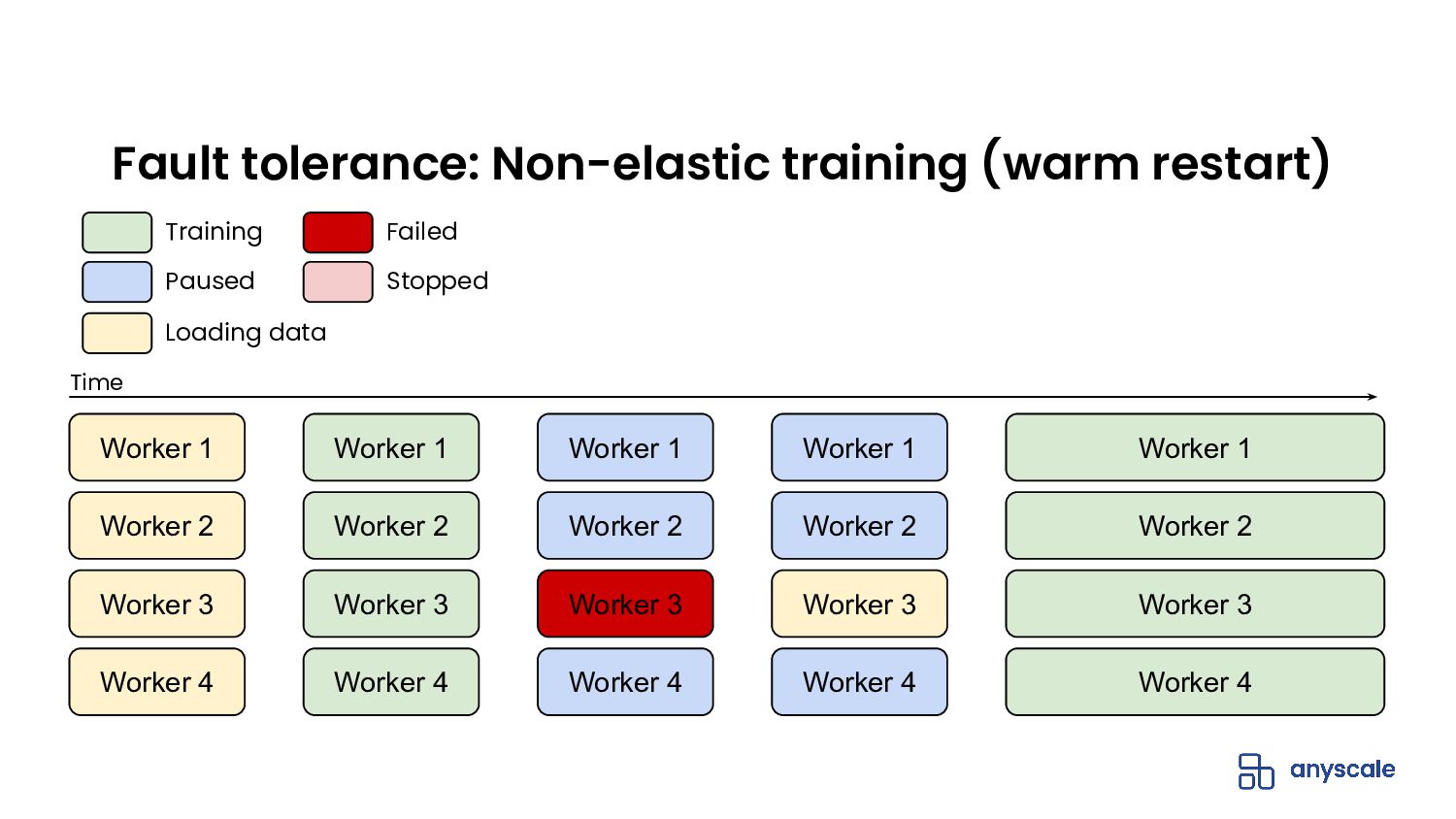
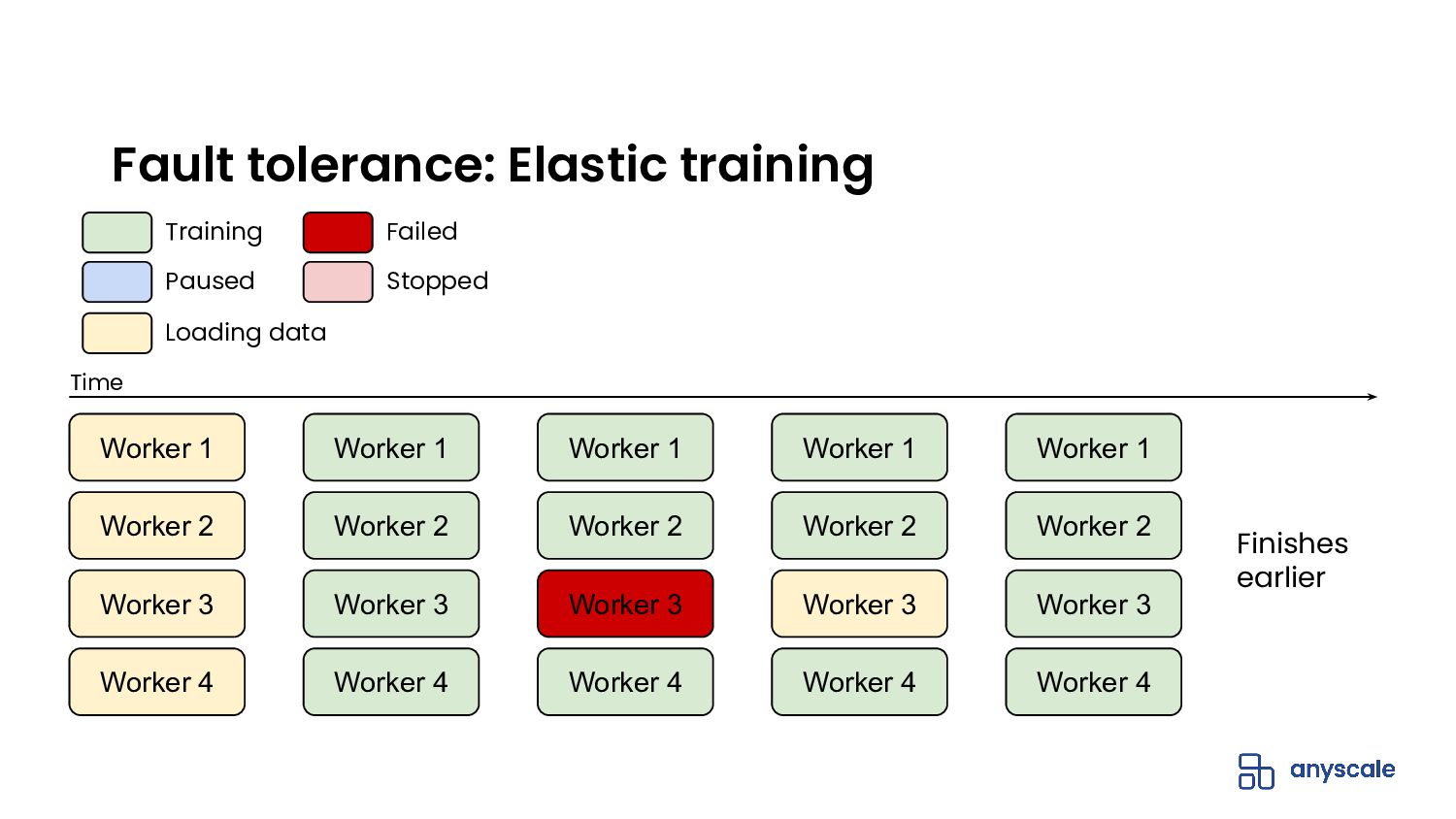
In this webinar, we will cover how Ray, a universal distributed computing framework running on Anyscale, simplifies the end-to-end machine learning lifecycle and provides serverless compute without limits. We will go through an example from beginning to end using XGBoost.
See first hand how to:
- Load data with Ray Datasets
- Train an XGBoost model on Ray
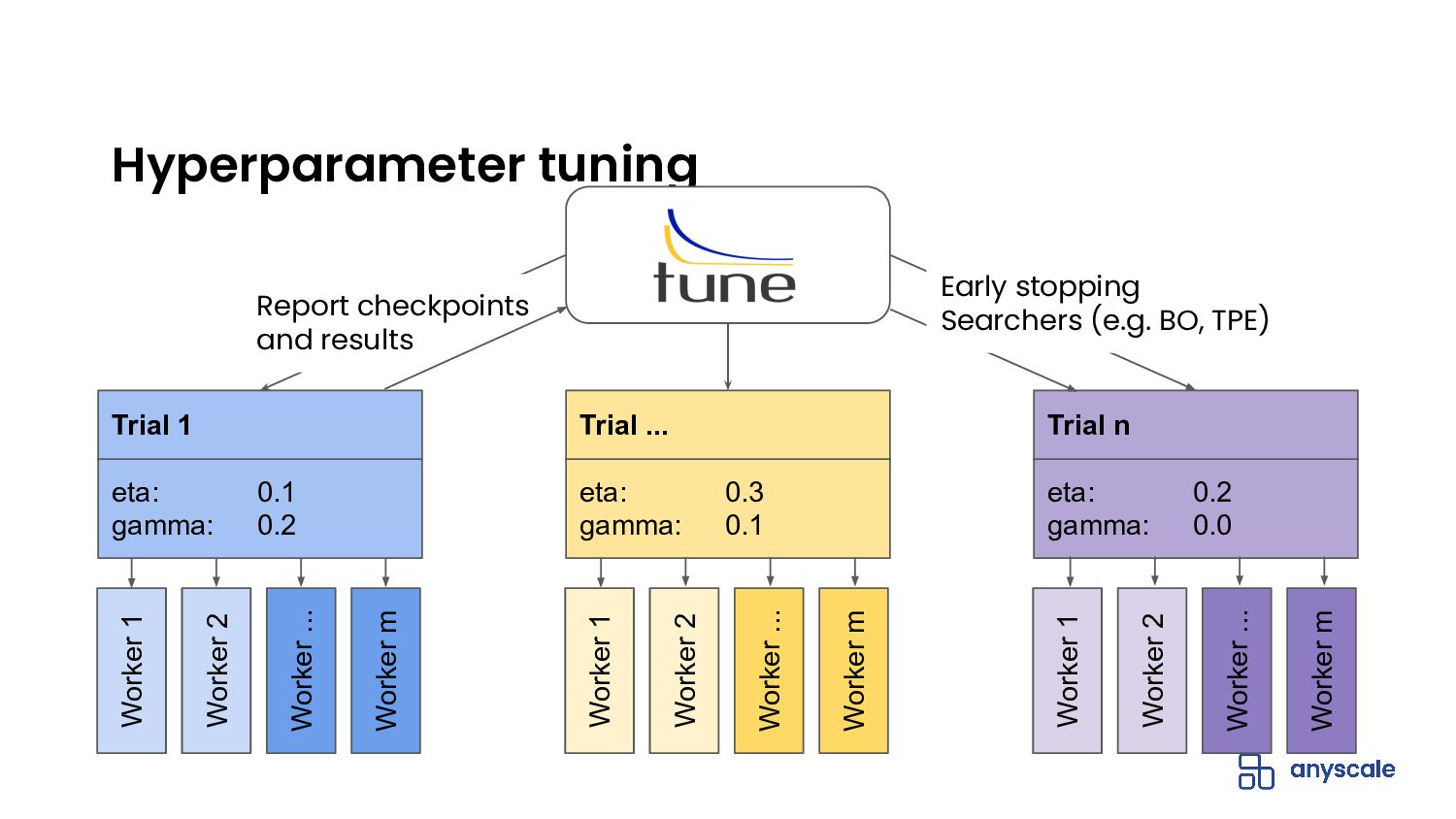
- Perform hyperparameter tuning with Ray Tune
- Scale from your laptop to Anyscale with zero code changes
- Experiment tracking with Weight and Biases
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
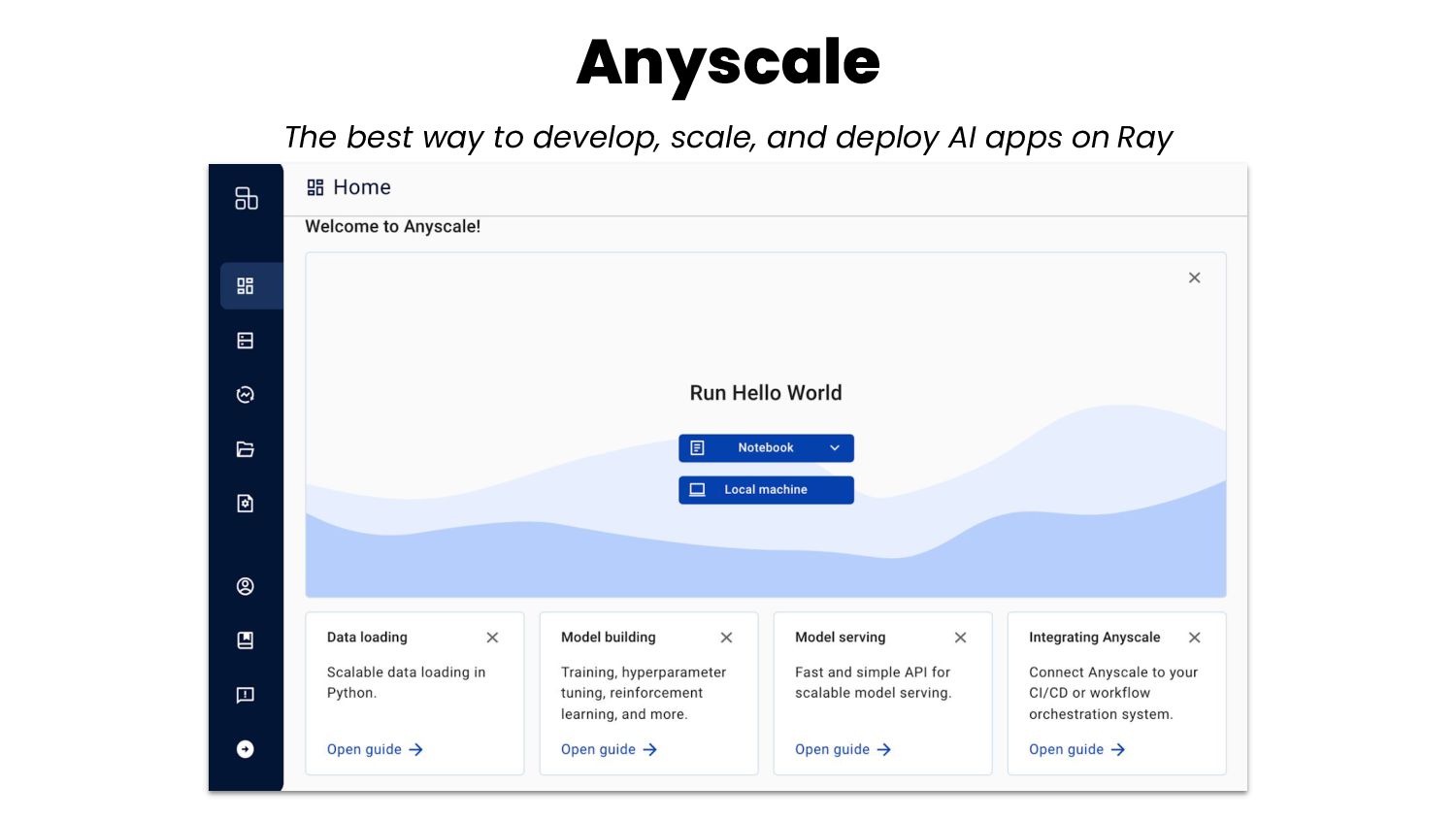{kind=link}
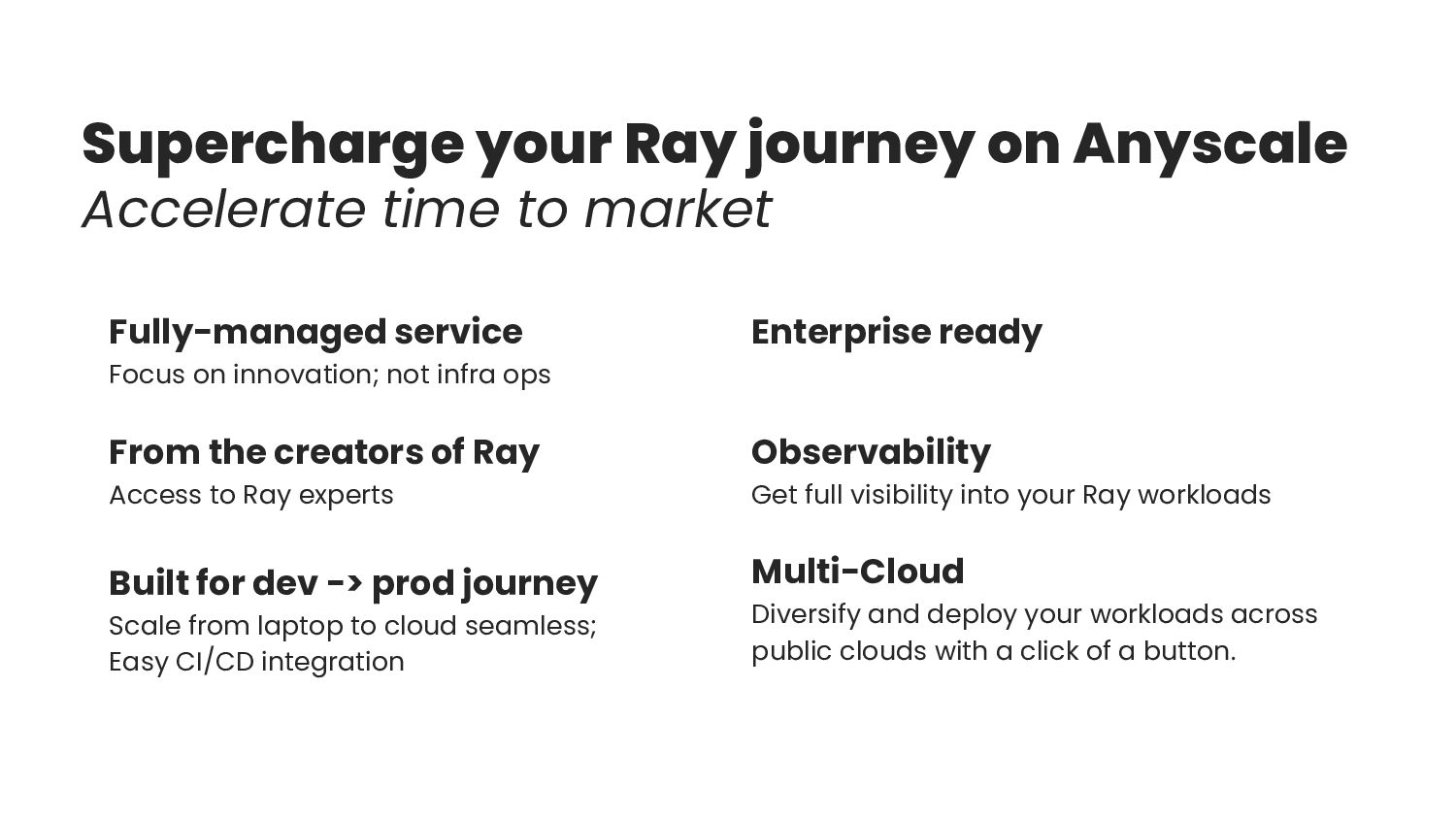{kind=link}
{kind=link}
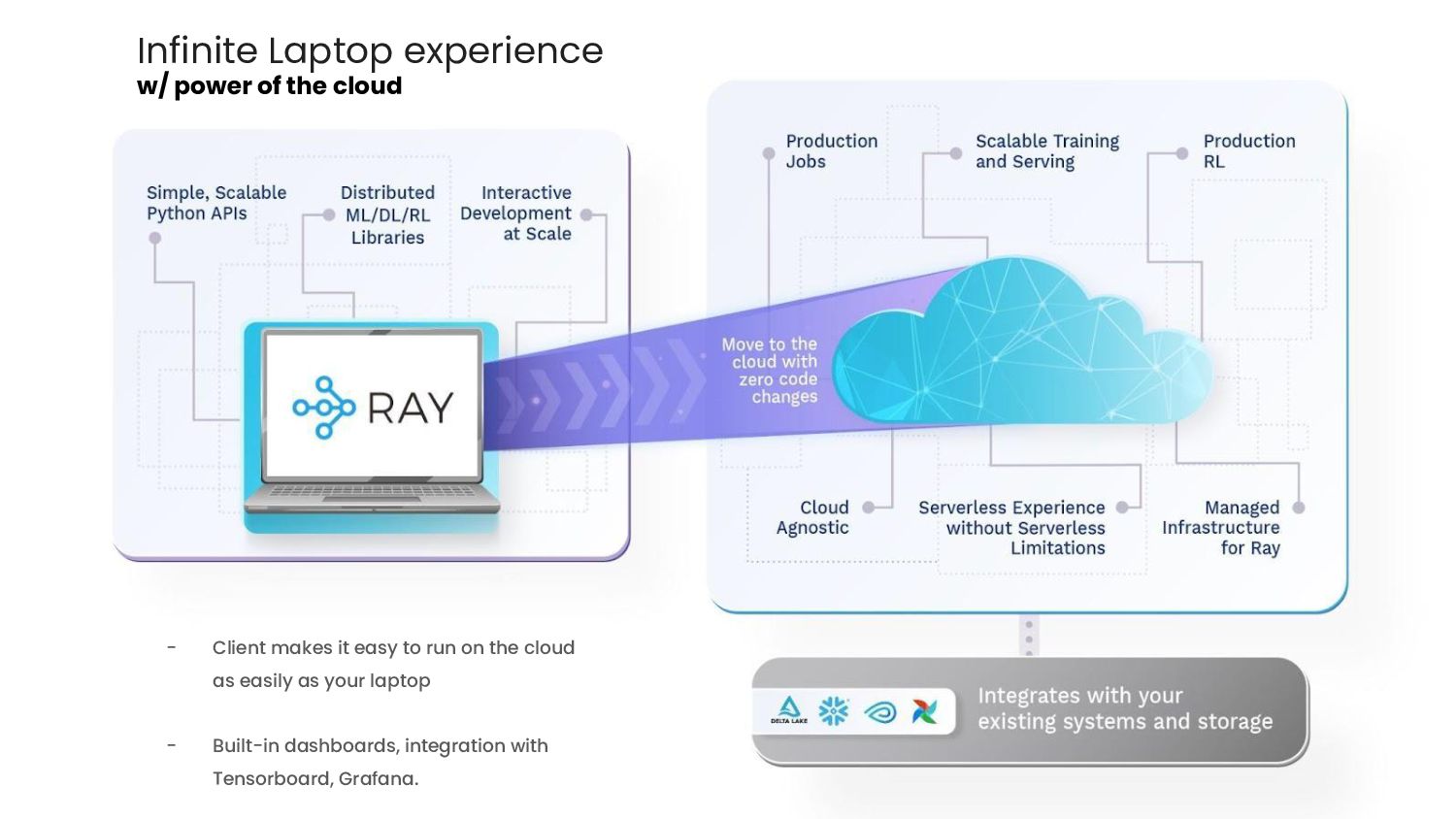{kind=link}
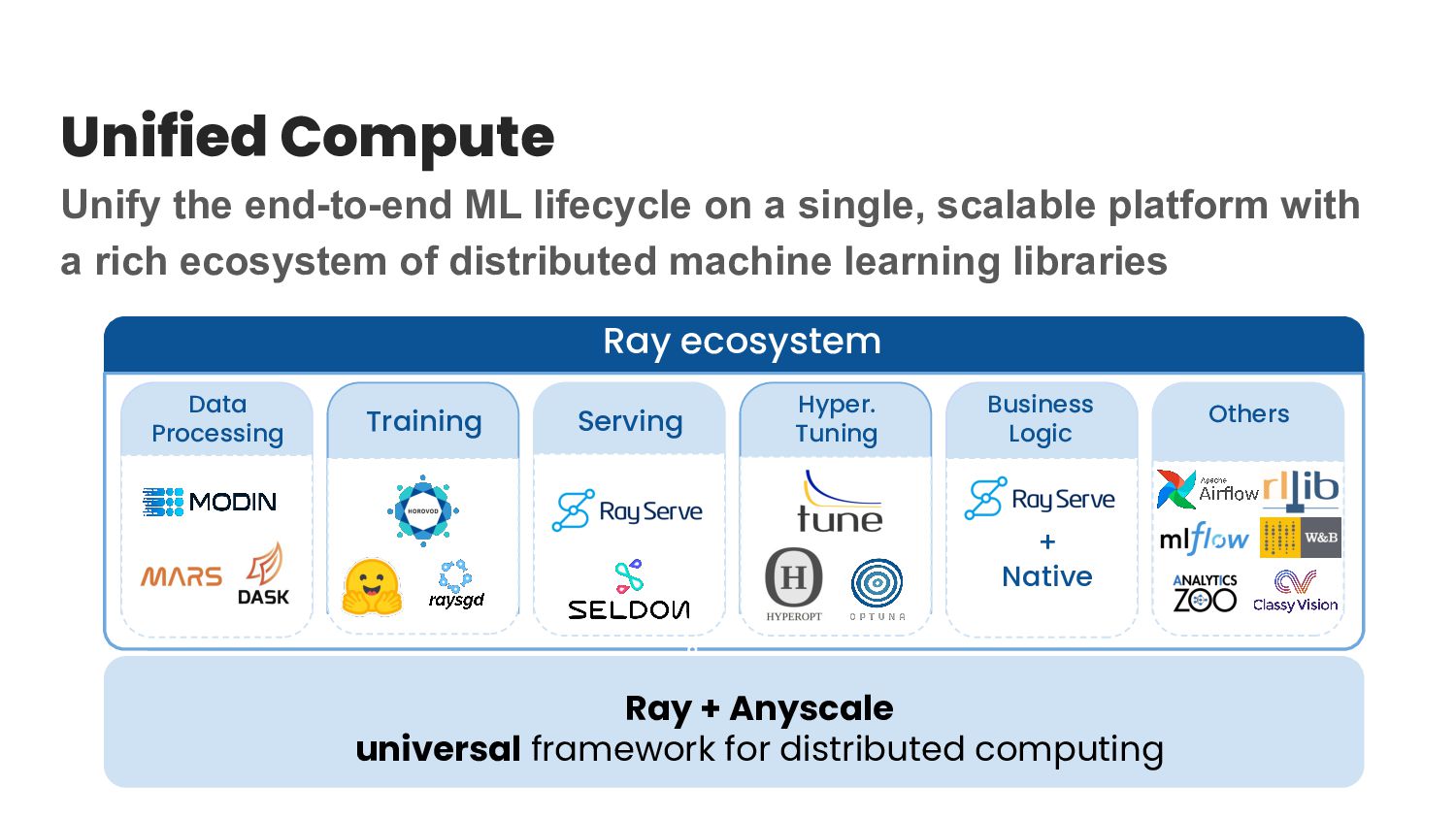{kind=link}
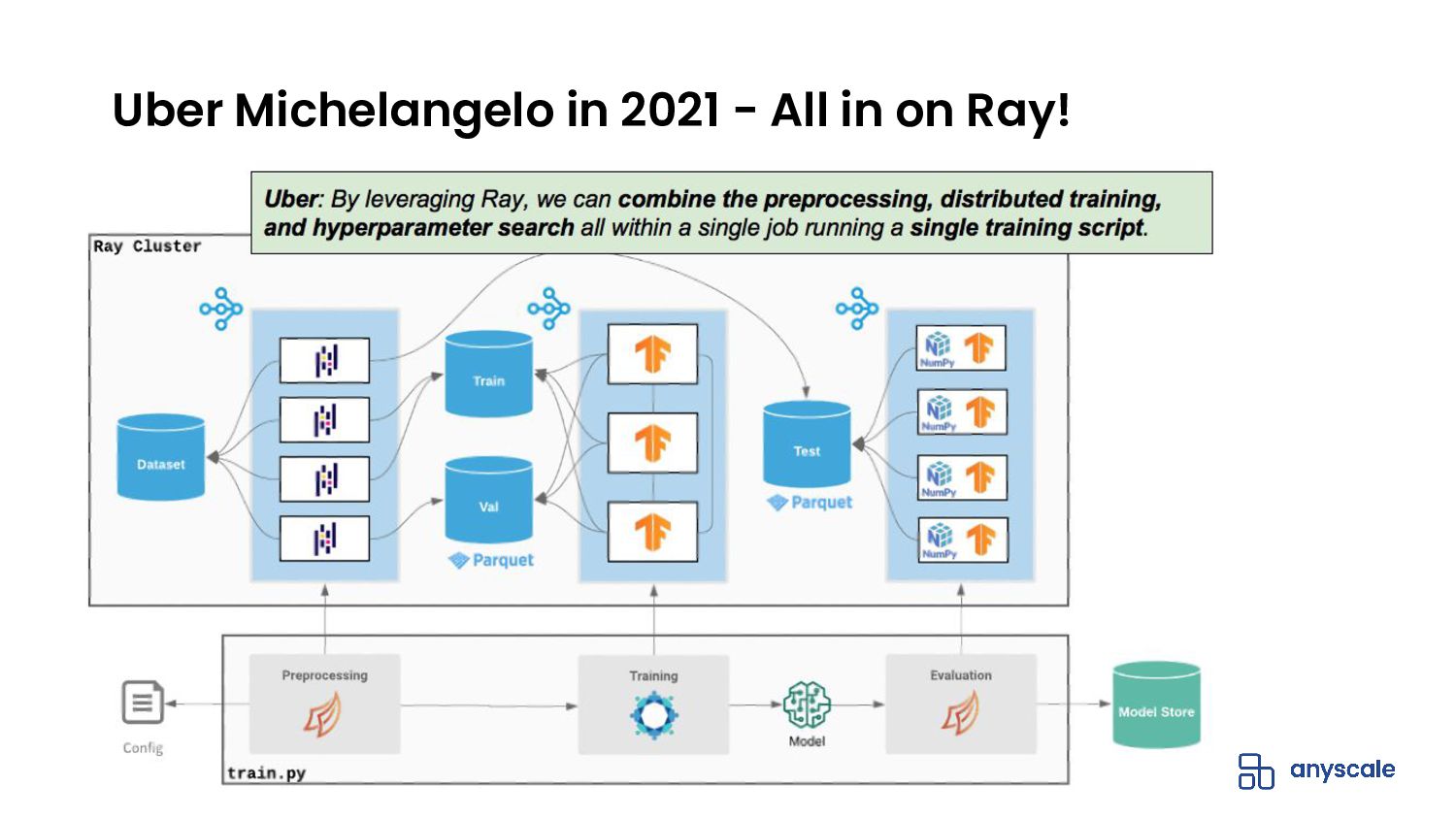{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
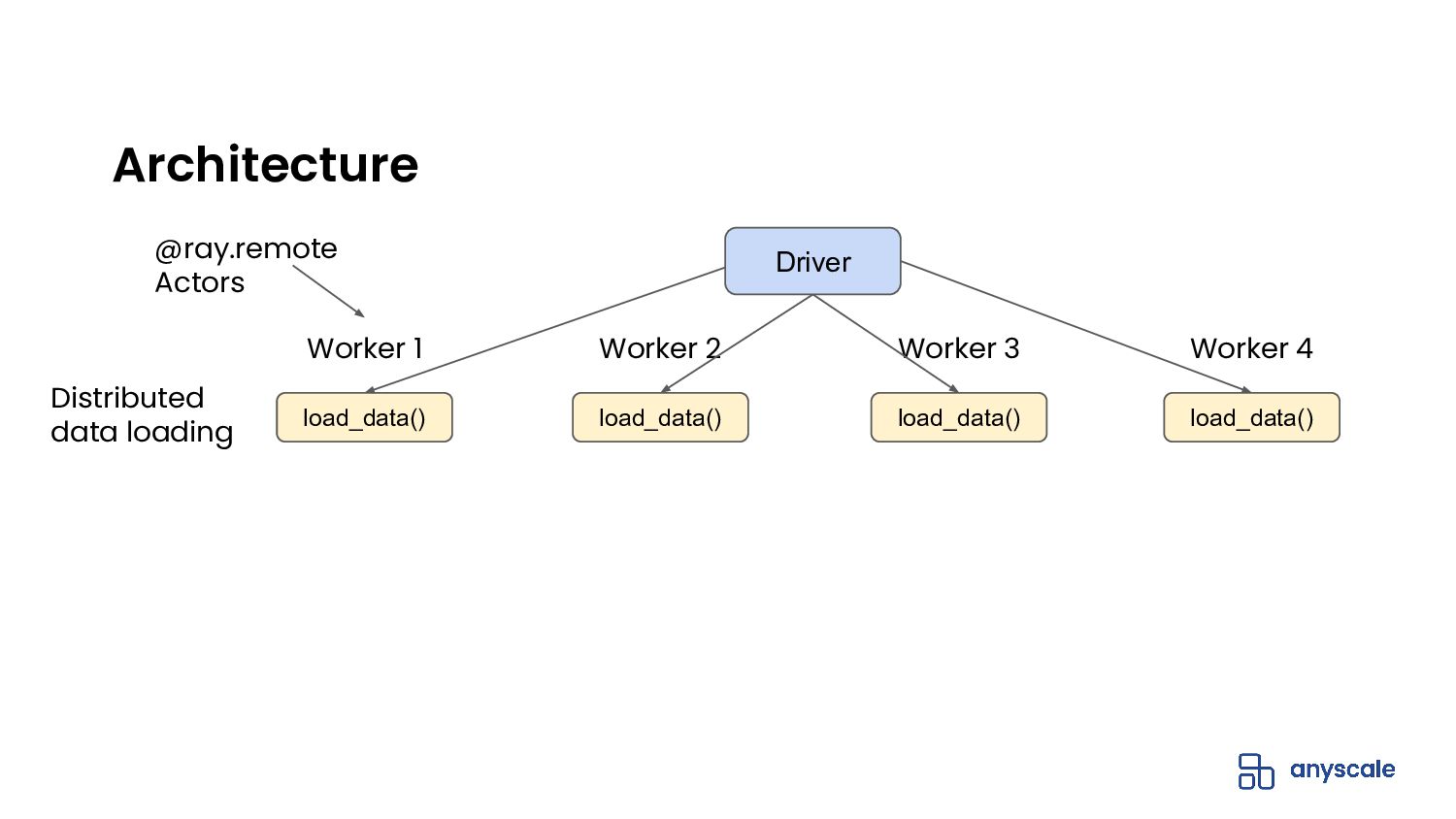{kind=link}
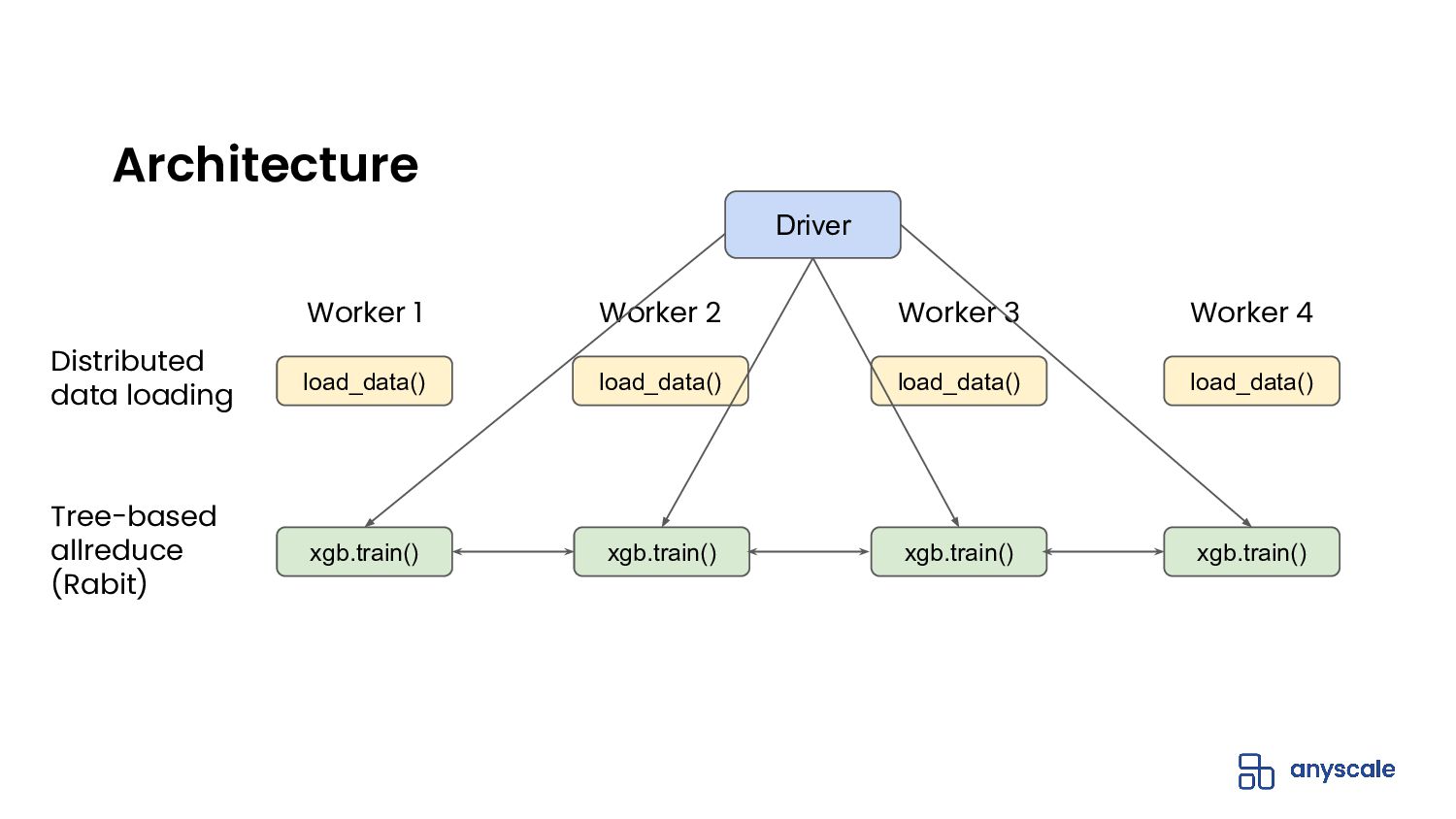{kind=link}
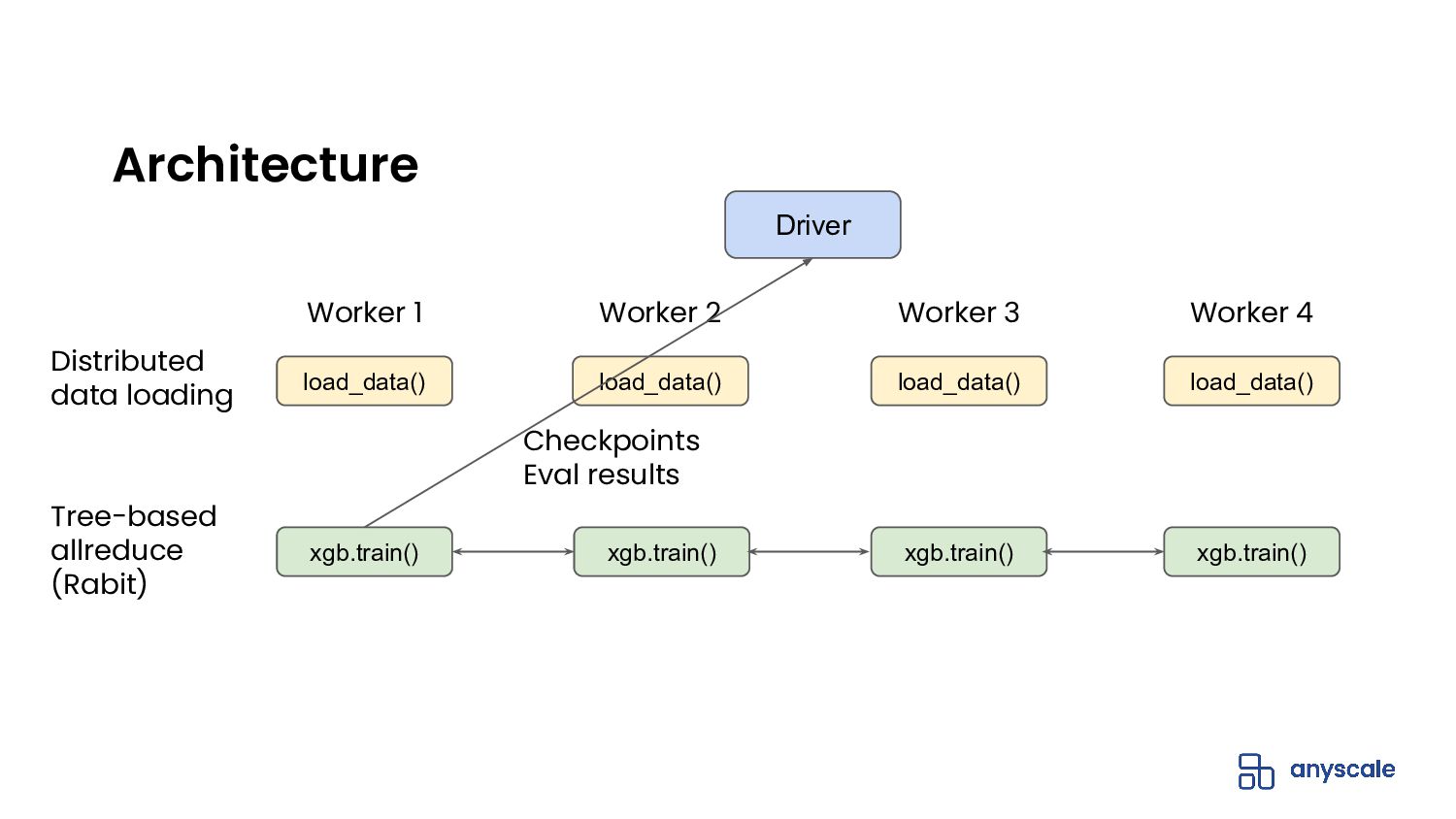{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}