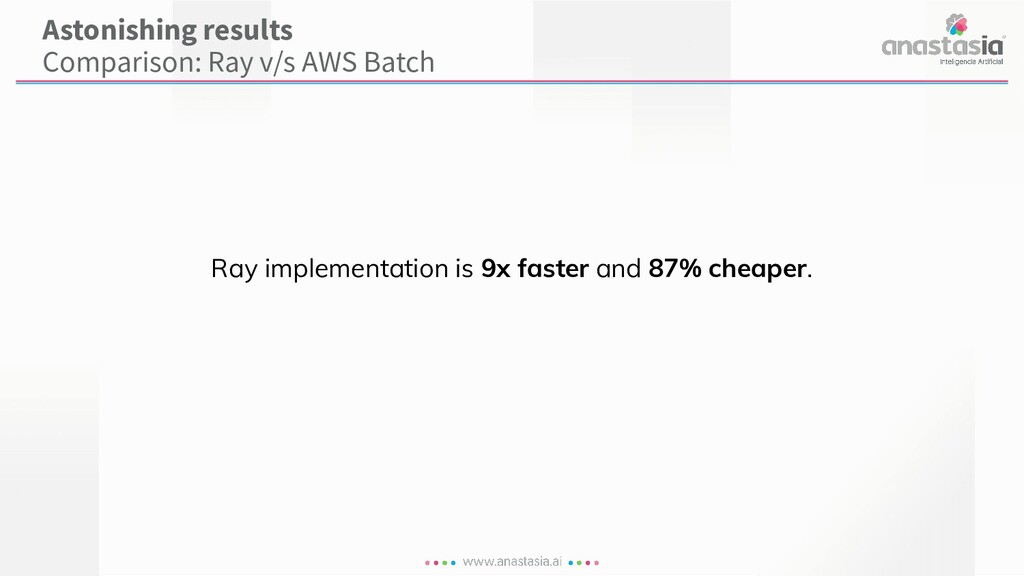
When in need of scaling Ray applications, the go-to resource for developers has been Ray’s own Cluster Launcher. Recently, Anyscale was launched in private beta as a fully-managed alternative. In this talk, we will have a look into a real-life workflow running in both scenarios. We will also highlight the key differences between them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Juan Roberto Honorato [email protected] Domingo Ortuzar [email protected]](https://files.speakerdeck.com/presentations/5751783238804f8d9ecd71952e9344c8/slide_18.jpg){kind=link}