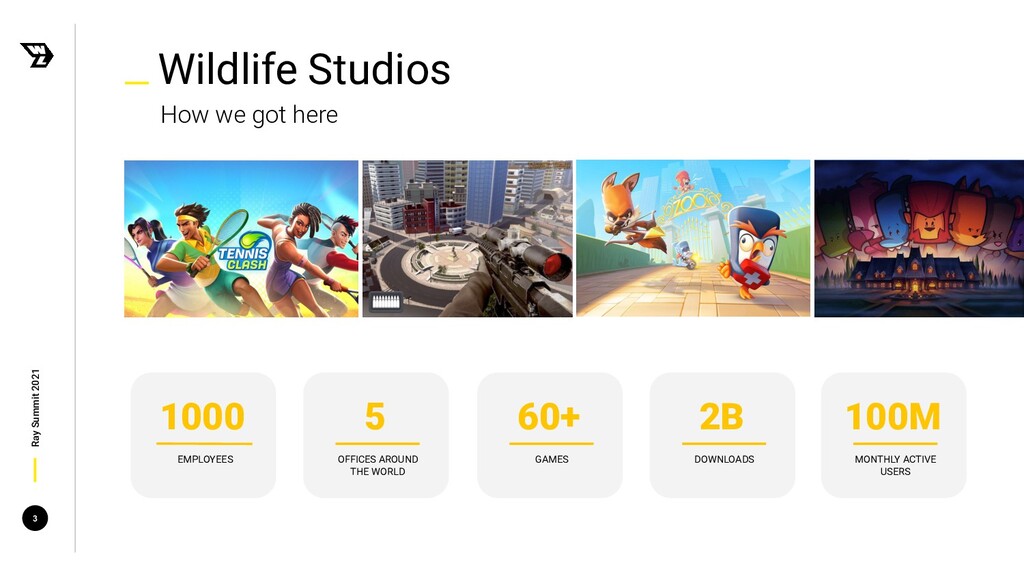
A significant part of mobile games revenue comes from In-App Purchases (IAP), and offers play a relevant role there. Offers are defined as sales opportunities that present a set of virtual items (like gems, for example) with a discount when compared to regular purchases in the game store. Additionally, the player base is very diverse: most of our users never make a purchase in our apps, and there are casual as well as hardcore players. This diversity pushes us to personalize user experience.
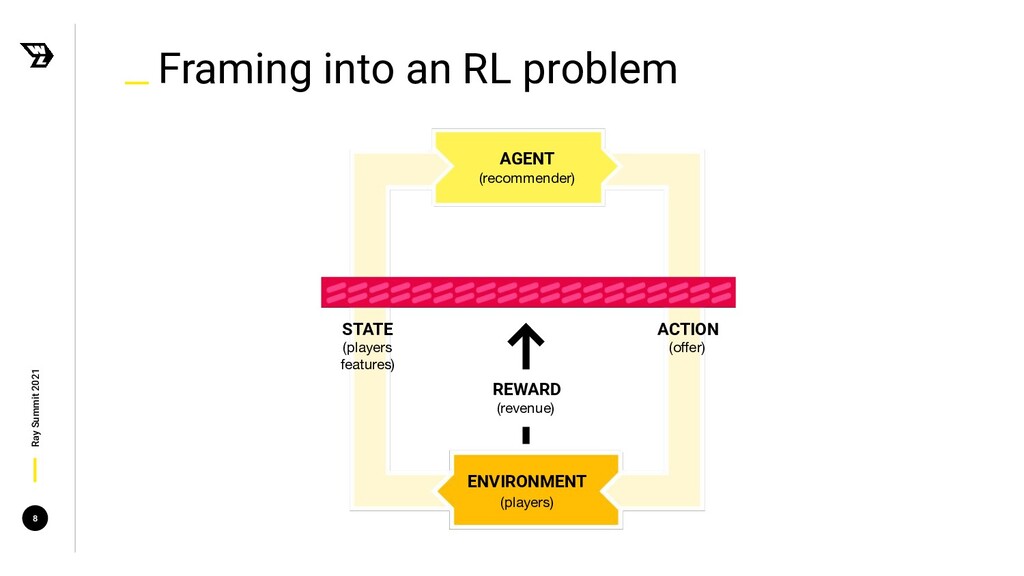
The key goal is to define, for any given player at any given time, what is the best offer that we can show to maximize long-term profits. With that in mind, we are encouraged to frame this system as a very particular optimization problem: what is the best policy, the one that will help us make the best sequence of decisions, maximizing revenue in the long run?
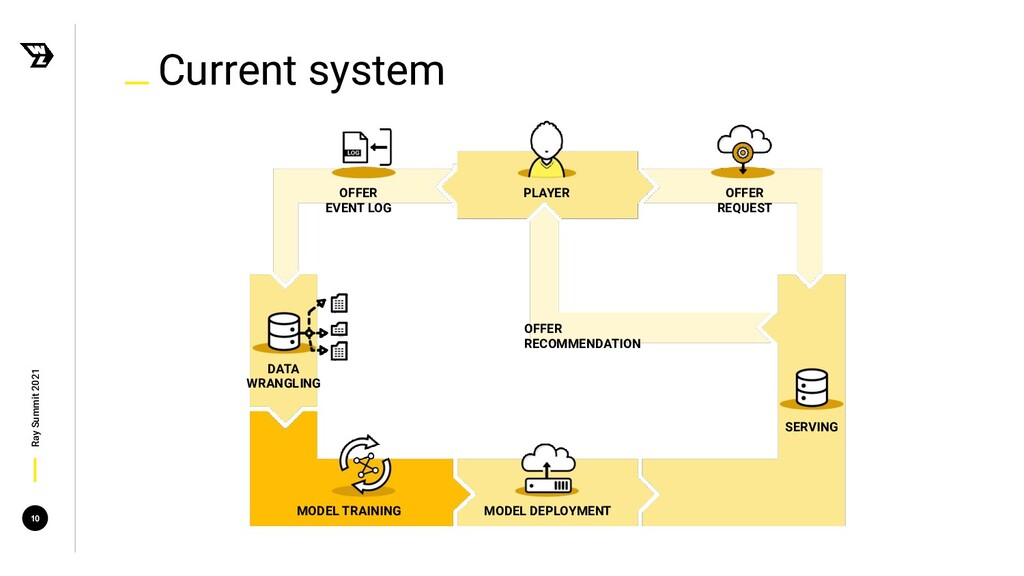
In this talk, we'll explain how we used Reinforcement Learning (RL) algorithms and Ray to tackle this problem, from formulating the problem and setting up our clusters, to the RL agents' deployment in production. We'll provide an overview of the main issues we faced and how we managed to overcome them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
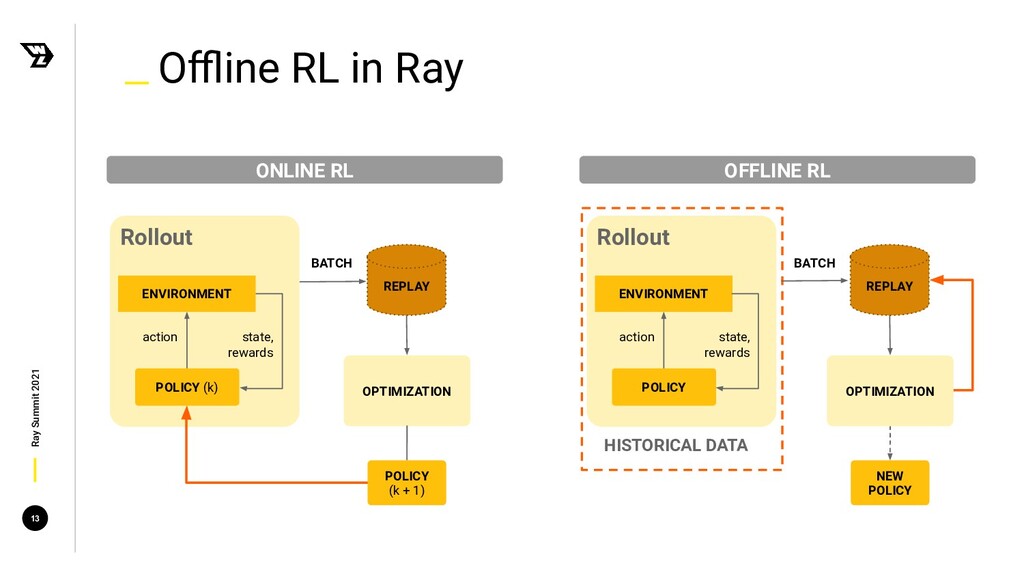{kind=link}
{kind=link}
{kind=link}
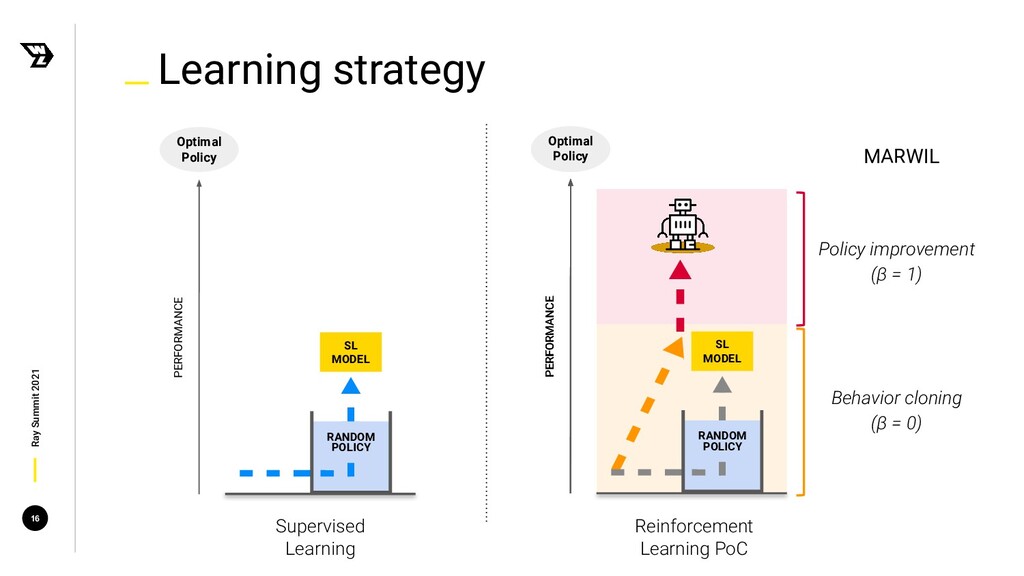{kind=link}
{kind=link}
{kind=link}
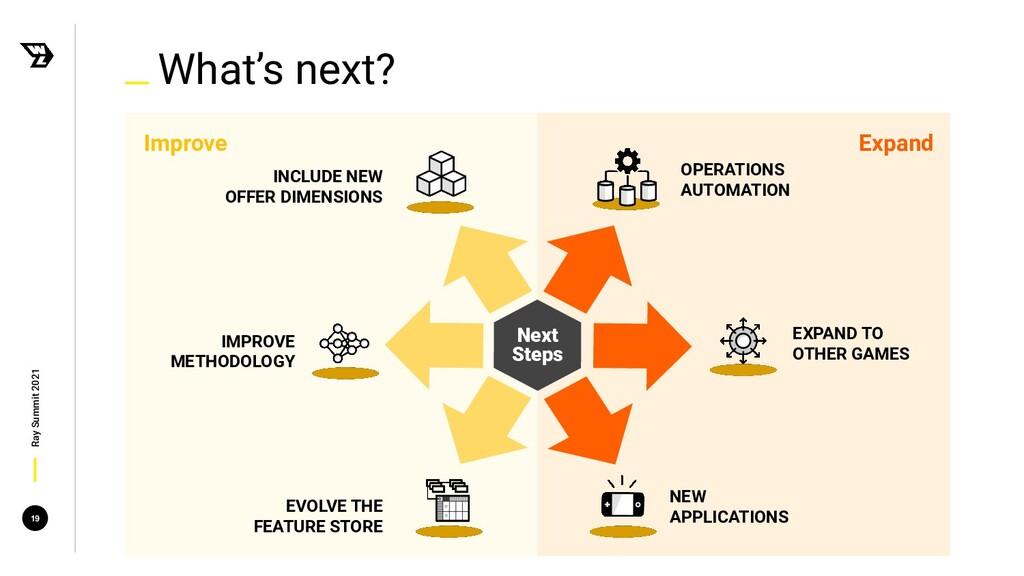{kind=link}
{kind=link}
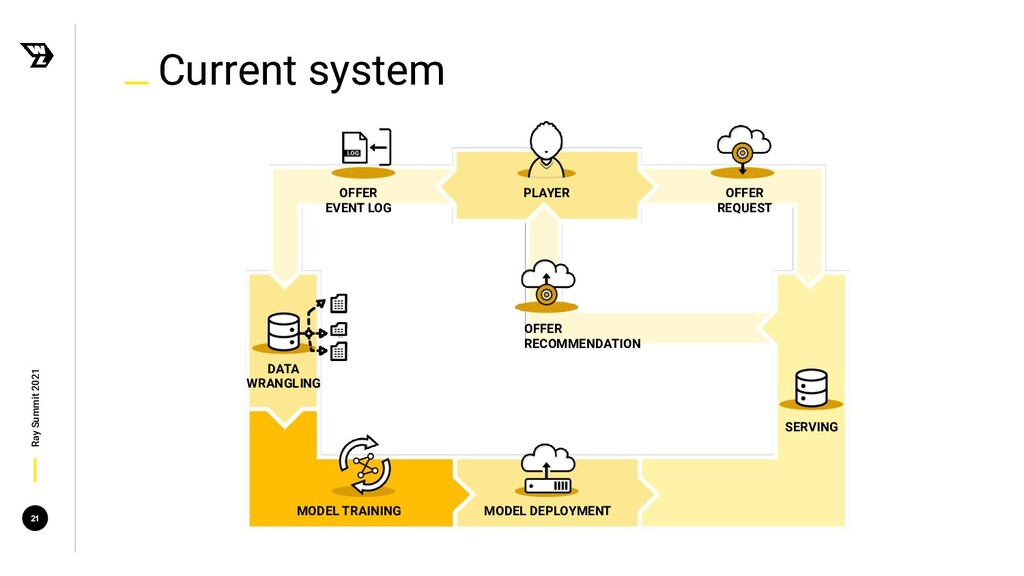{kind=link}