[データブリックス レイクハウス プラットフォームにおける最新動向 LT大会 登壇資料]
長谷川 亮氏 (データブリックス)
イベント開催日:2023年7月26日
イベントの趣旨:
データブリックス社とエーピーコミュニケーションズ共同開催のLTイベントです。
6月にサンフランシスコで行われたDatabricks社主催の世界最大のデータ&分析&AIをテーマにしたカンファレンス「DATA+AI SUMMIT 2023」の内容から、関連した情報や今後のDatabricksにおける技術情報などをテーマとしています。
データ分析基盤に少しでも興味のある方、データブリックスやLLM(大規模言語モデル)、AIなどデータ分析基盤の導入を検討中のユーザー様を対象にしています。
アーカイブ動画:https://youtu.be/RDcjUBjygBI
{kind=link}
{kind=link}
{kind=link}
{kind=link}
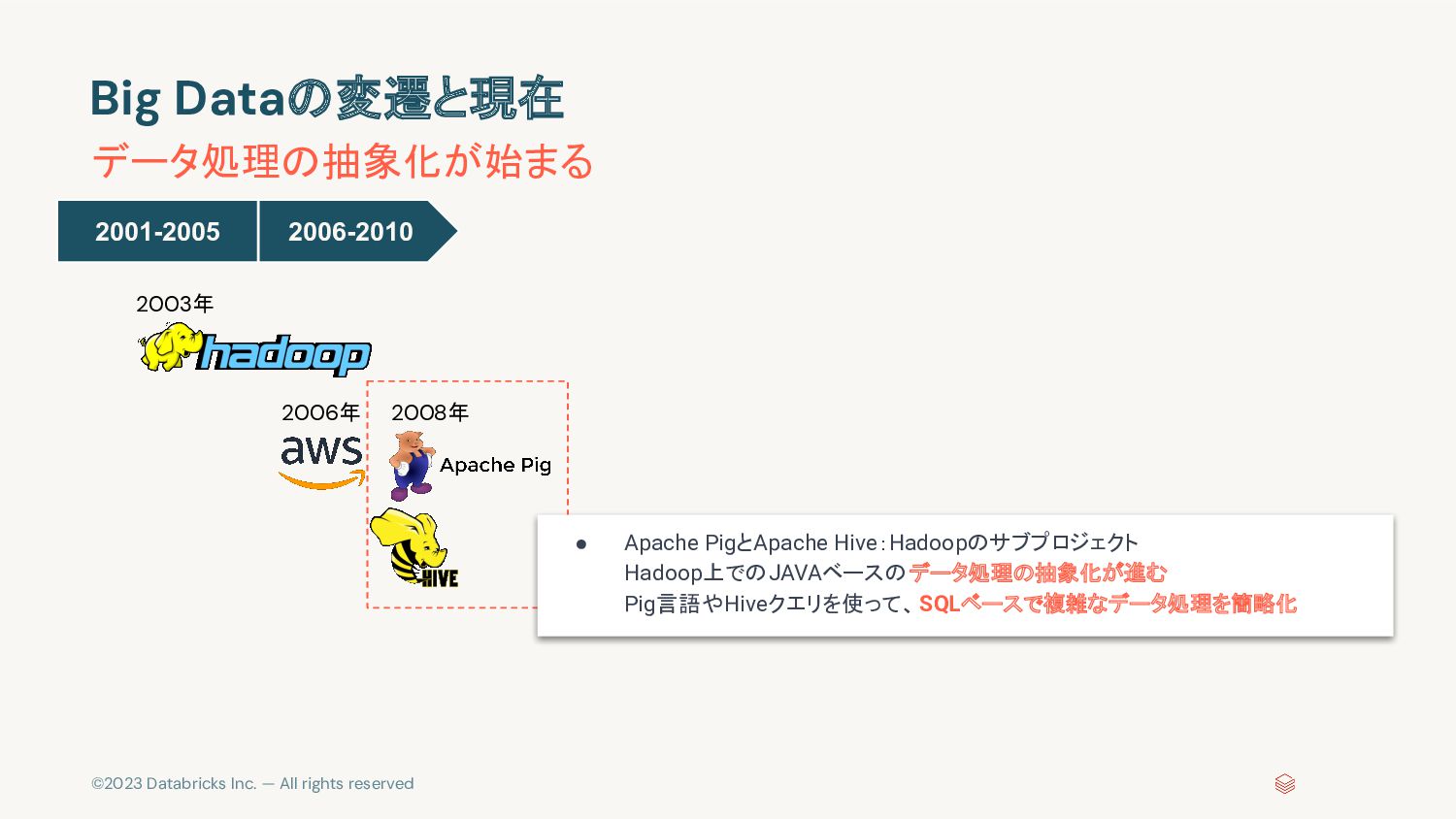{kind=link}
{kind=link}
{kind=link}
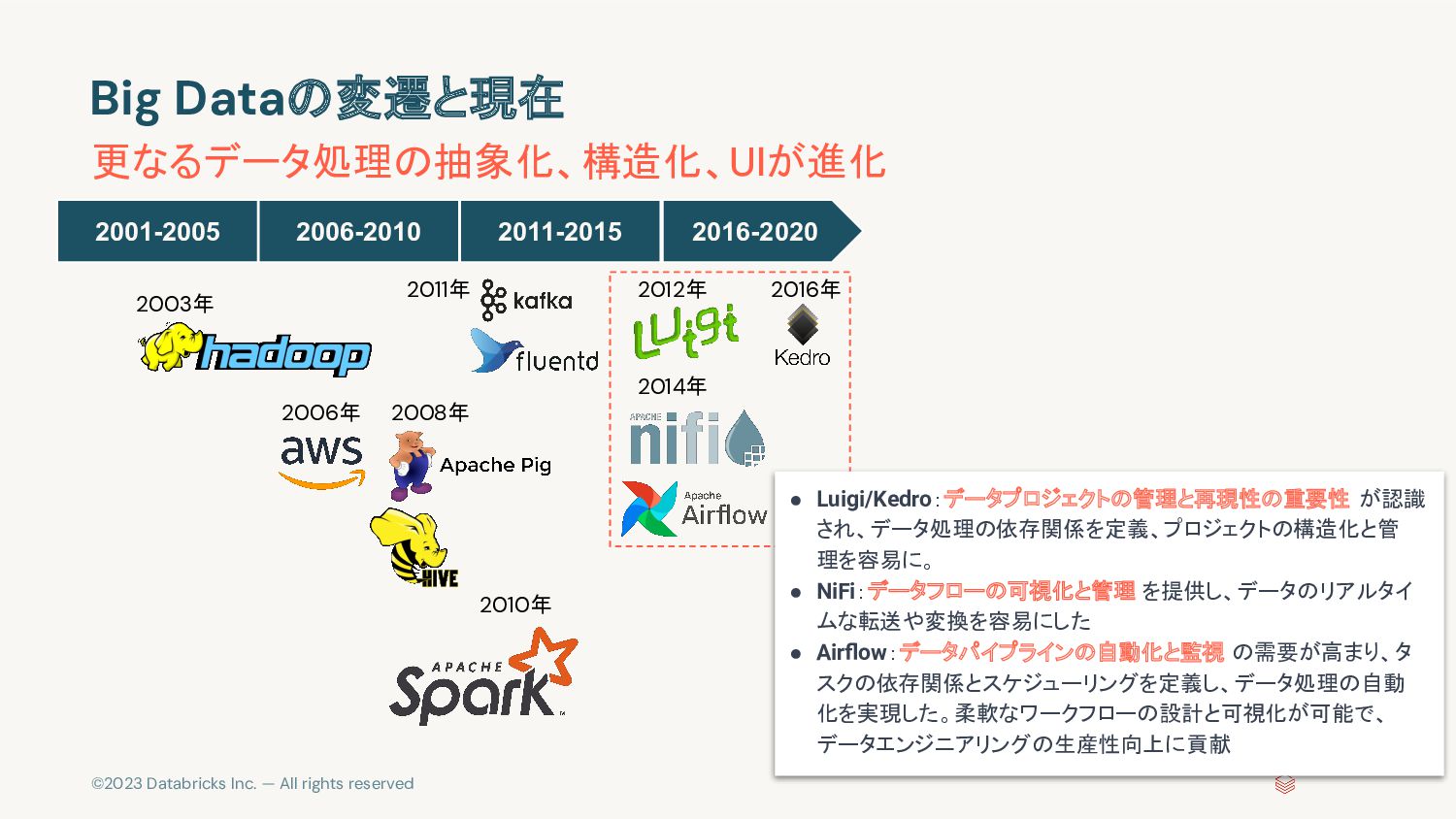{kind=link}
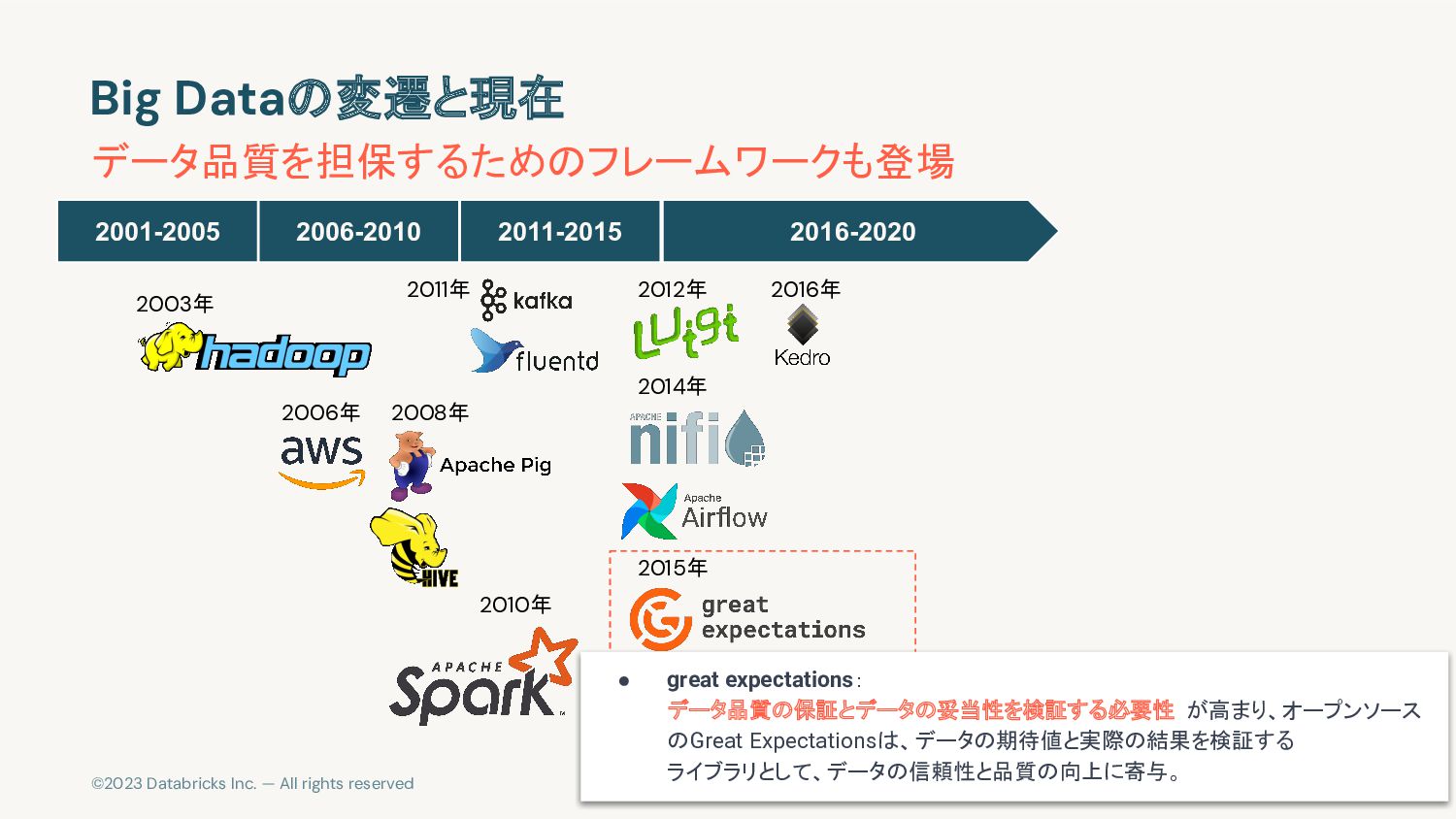{kind=link}
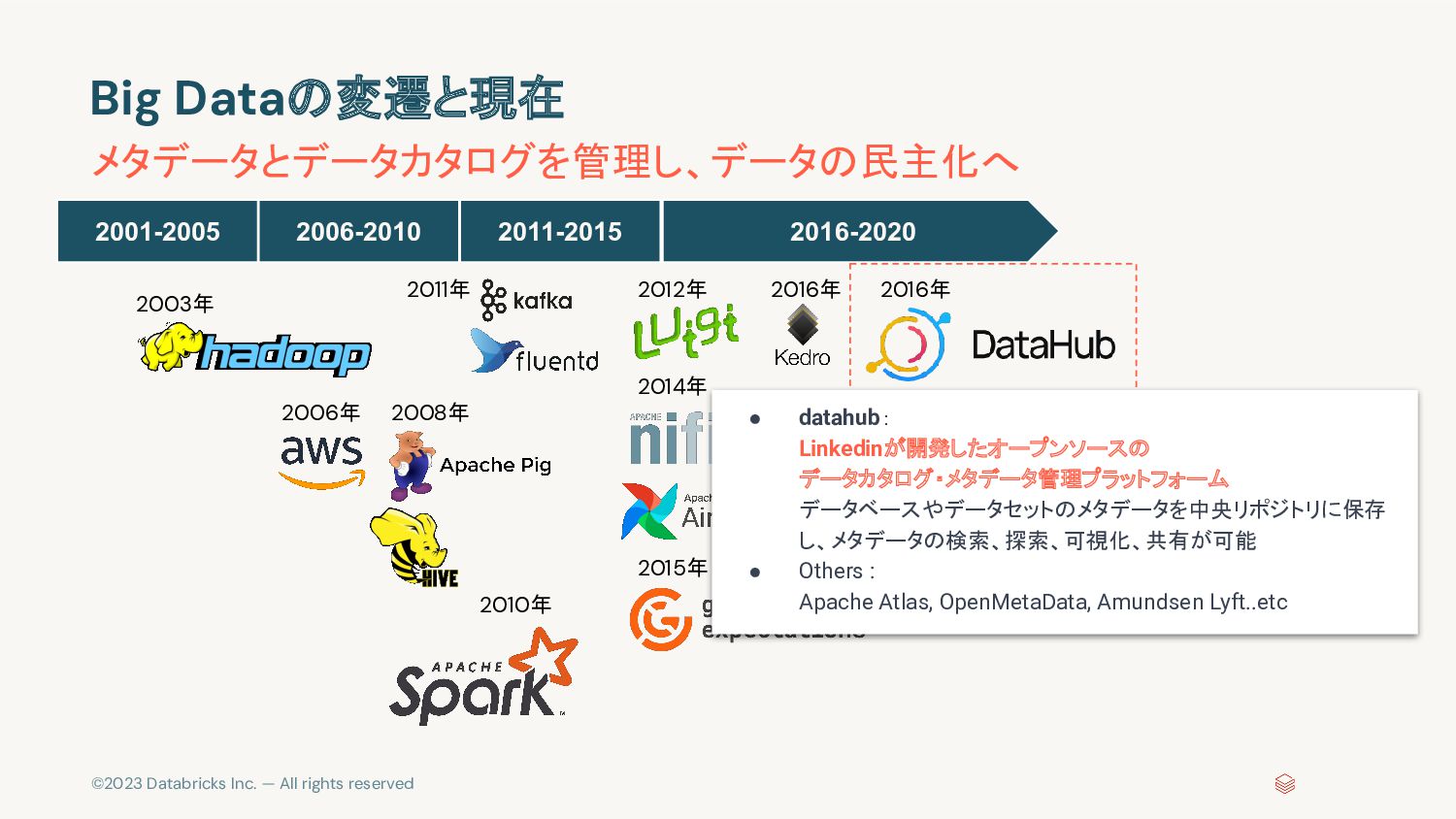{kind=link}
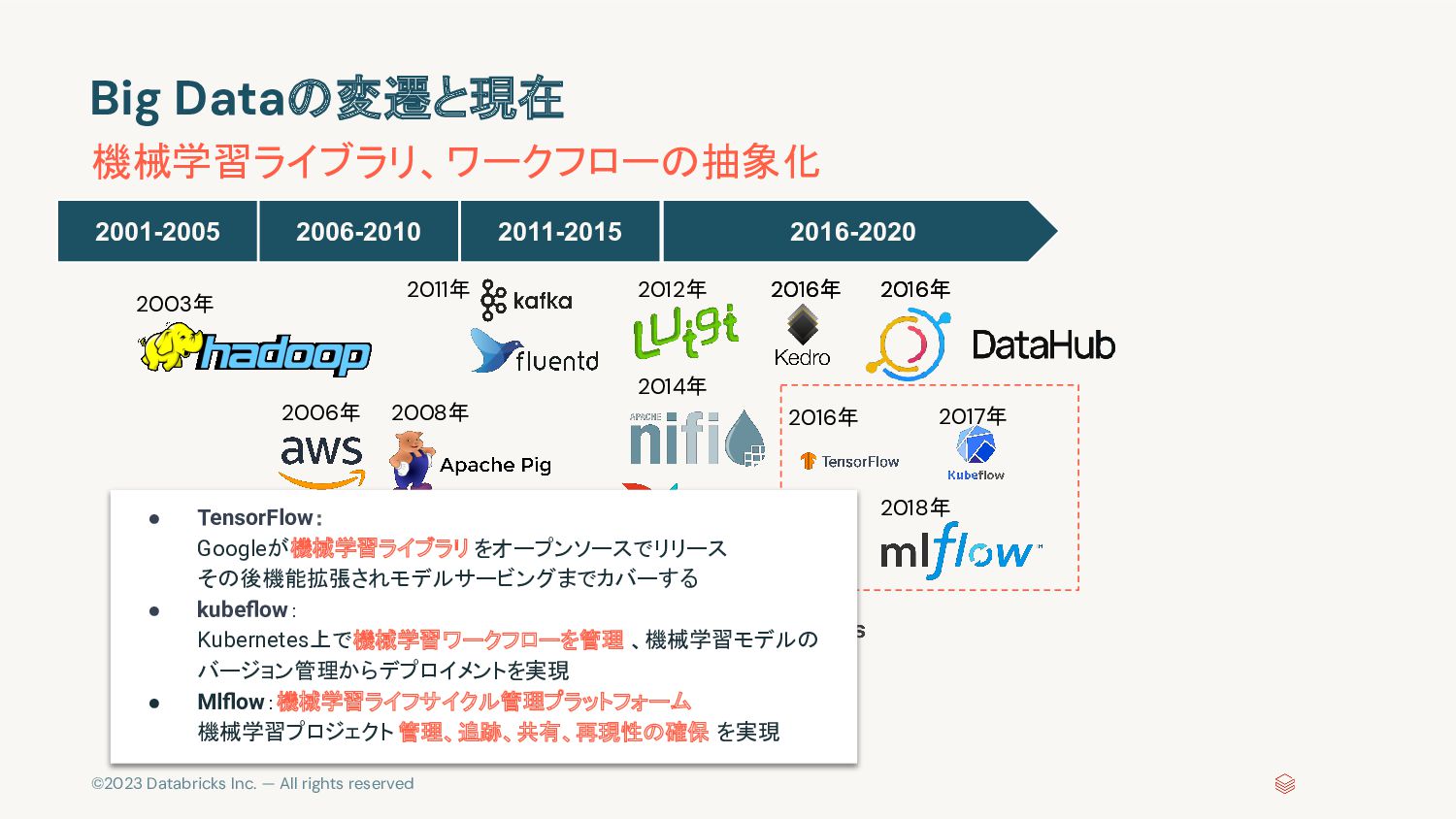{kind=link}
{kind=link}
{kind=link}
{kind=link}
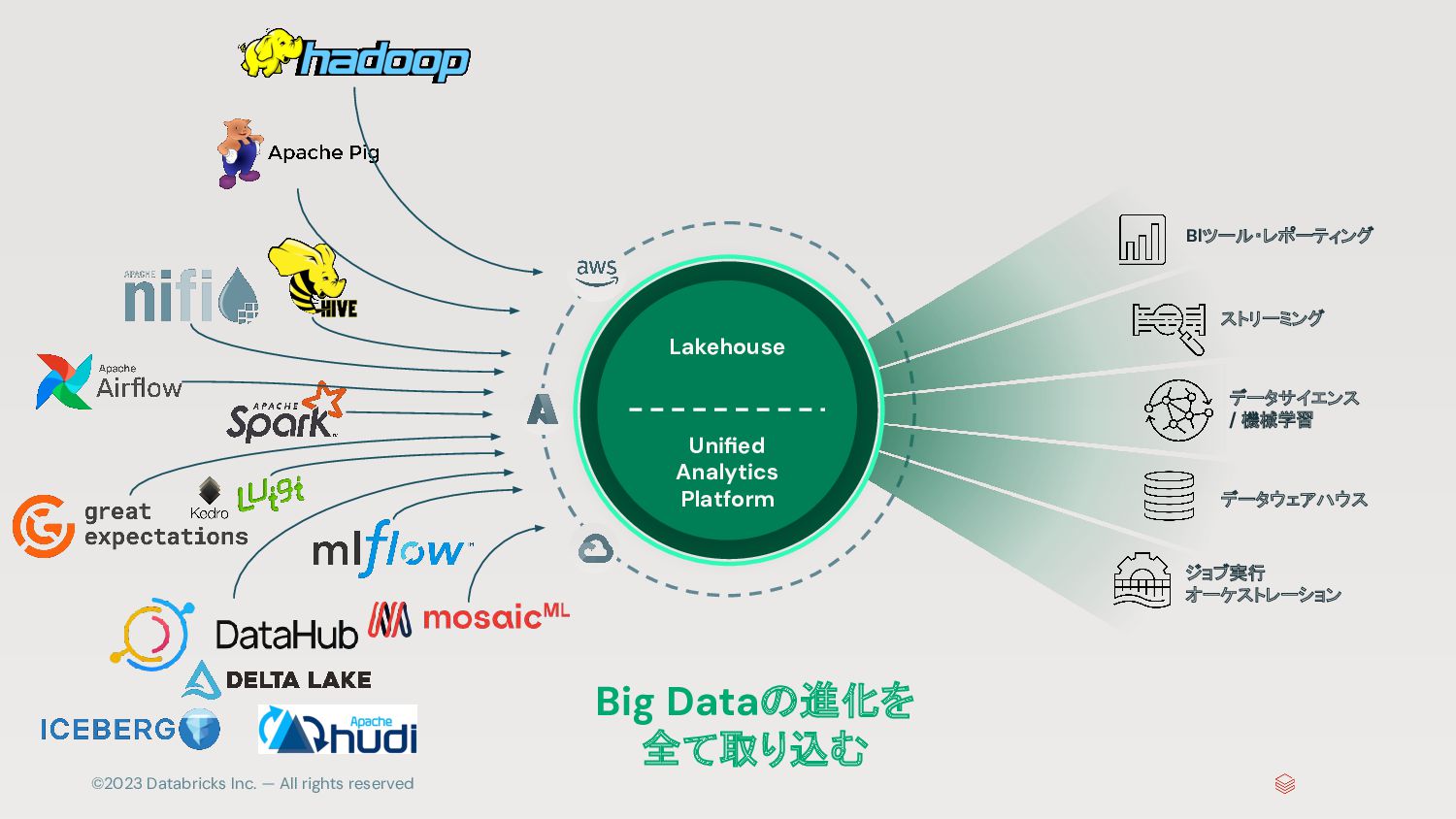{kind=link}
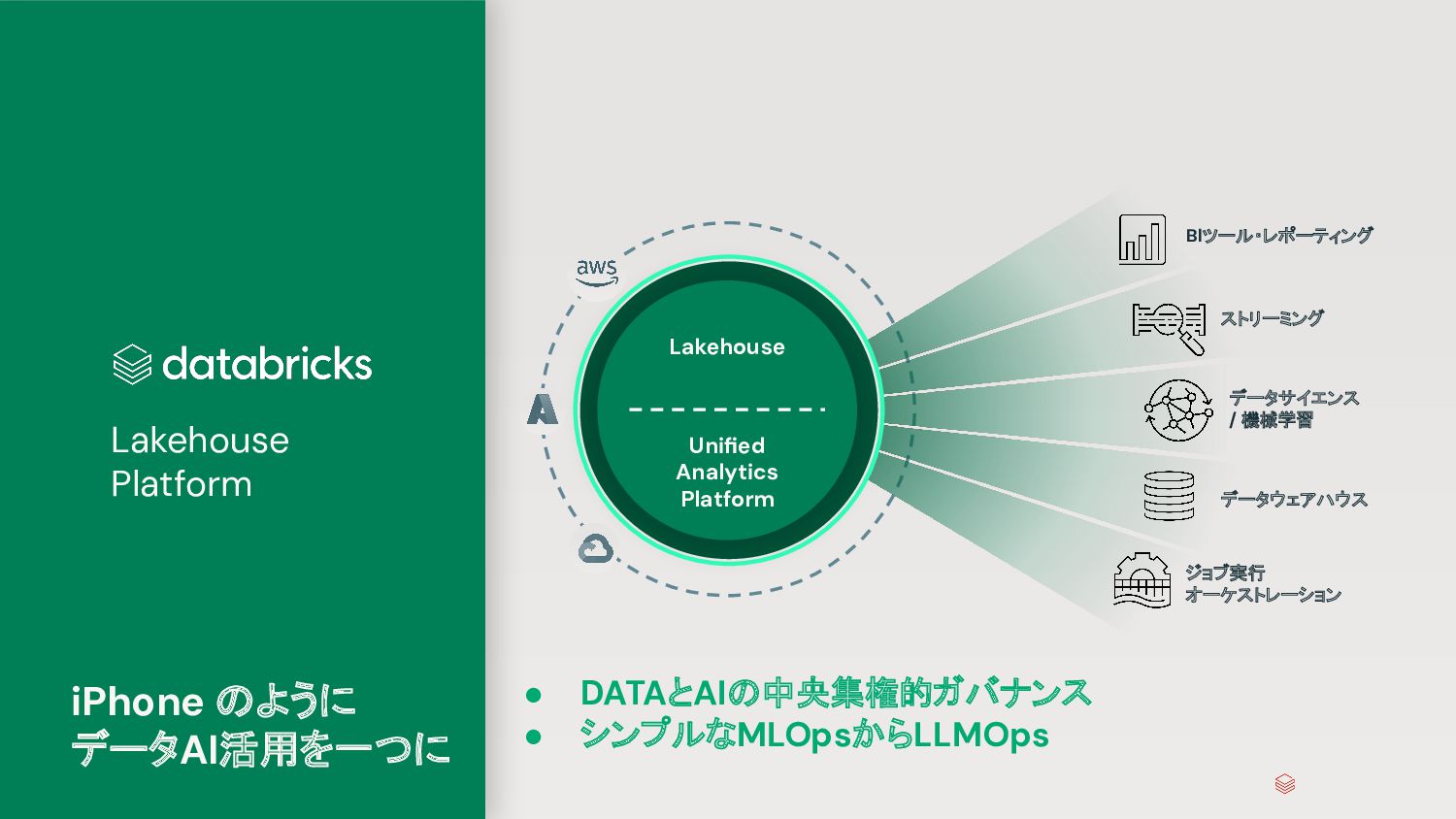{kind=link}
{kind=link}
{kind=link}
{kind=link}