[APC勉強会8a1 #42 登壇資料]
長谷川 脩(ハセガワ オサム)
<概要>
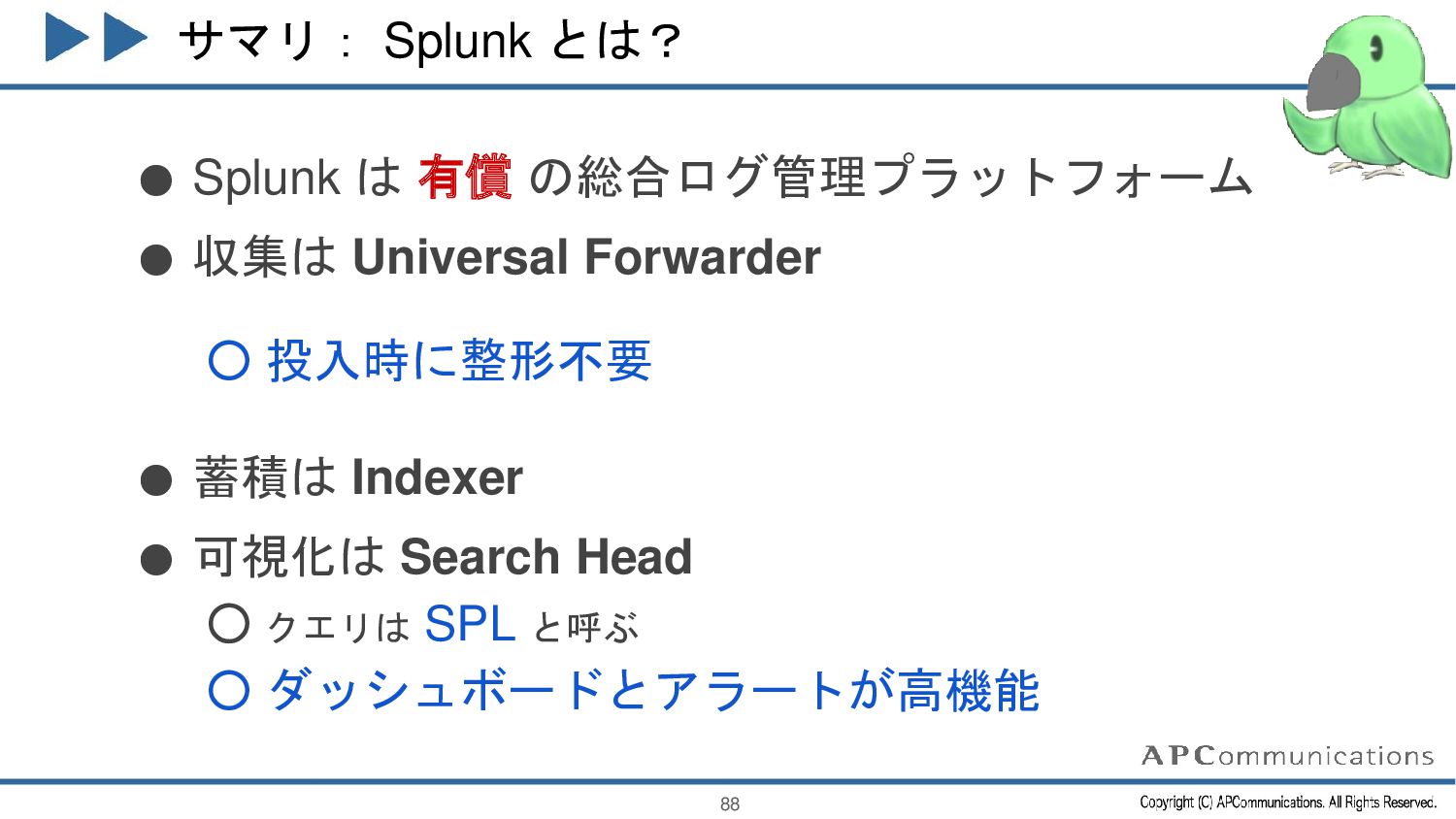
高額なツールであるSplunk。
導入してみたい、してみたはいいけれど......
何を実現すればいいのか分からない!
チームに普及できない!
他のツールとの違いが分からない!
など、課題がたくさんでてきますよね。
本セッションでは、登壇者が業務で直面した課題と、それをどのように解決して、どのような活用をしているのかについてお伝えできればと思います。
<動画>
https://youtu.be/LifaDb7L2S0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[事前アンケート結果共有] Splunkを使ったことはありますか? みなさん、 Splunk を使ったこと、ありますか? 7 1. 業務で使ったことがある 2. 個人で触ったことはある](https://files.speakerdeck.com/presentations/46811f69dcb24b688607f6a39d0265e4/slide_6.jpg){kind=link}
![[事前アンケート結果共有] Splunkを使ったことはありますか? 8 Splunk 未経験の方が半数 なので、 苦労談、活用事例の前に、 まずは「Splunk とは何か」 について説明いたします](https://files.speakerdeck.com/presentations/46811f69dcb24b688607f6a39d0265e4/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
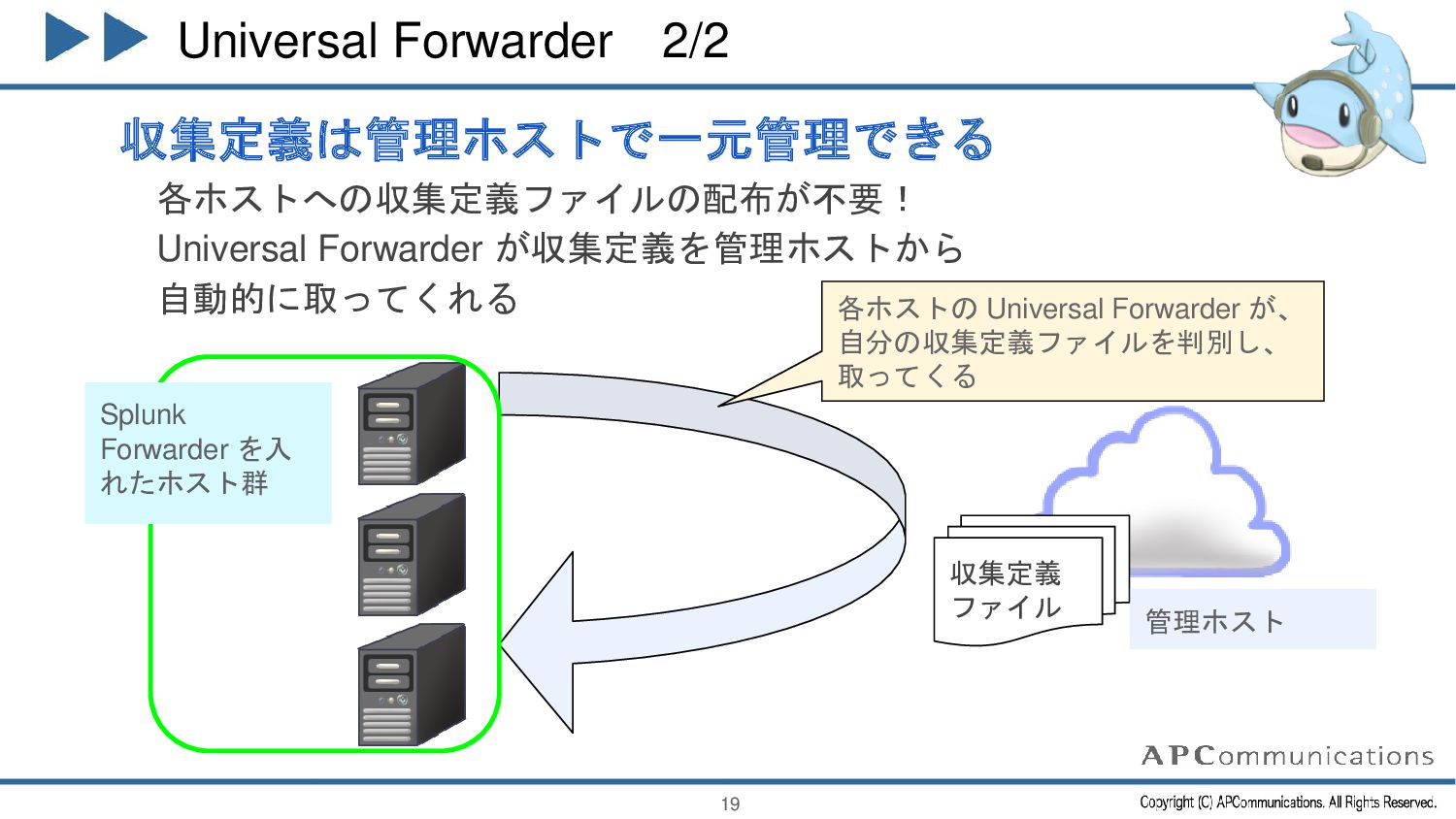{kind=link}
{kind=link}
{kind=link}
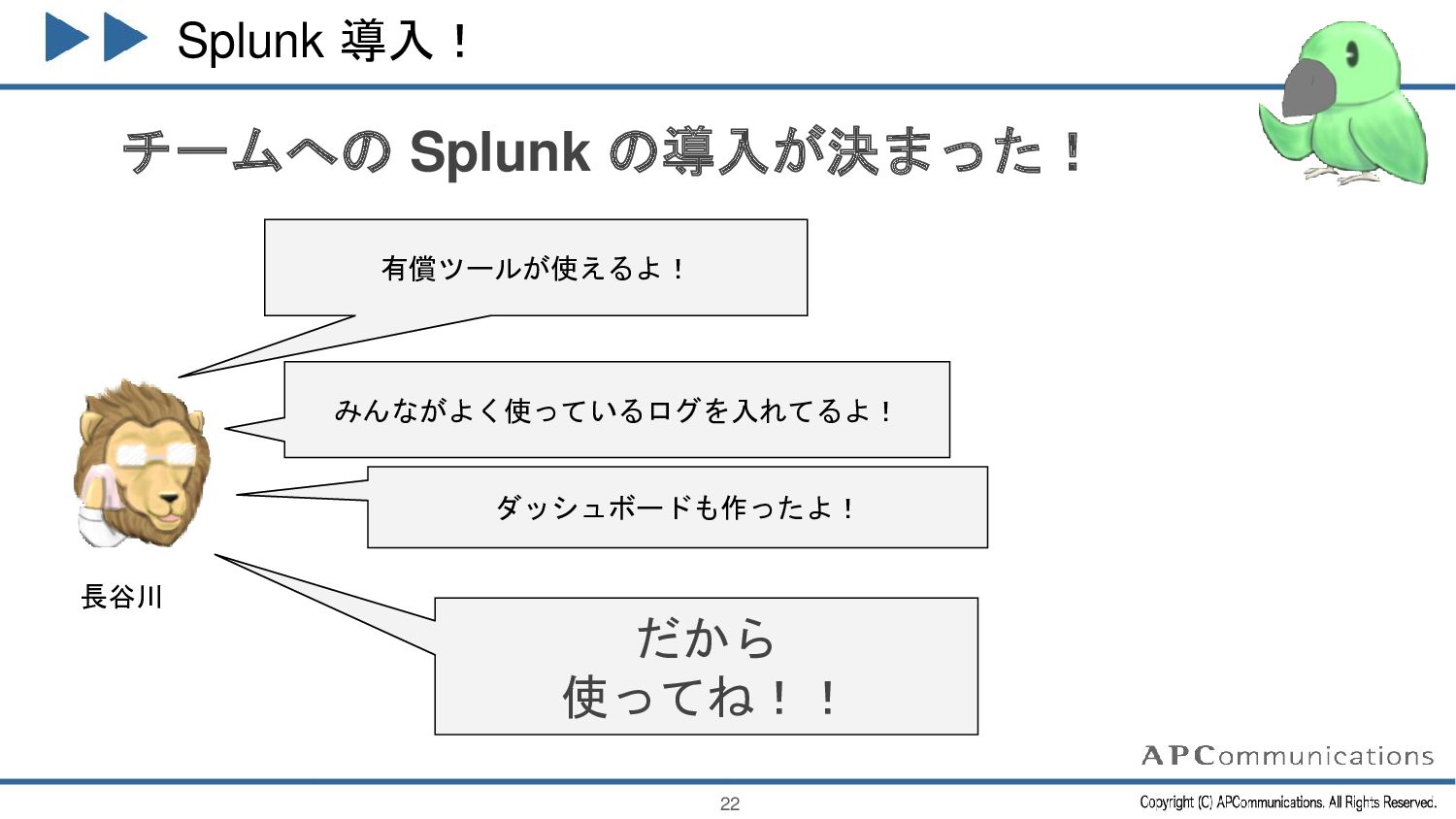{kind=link}
{kind=link}
{kind=link}
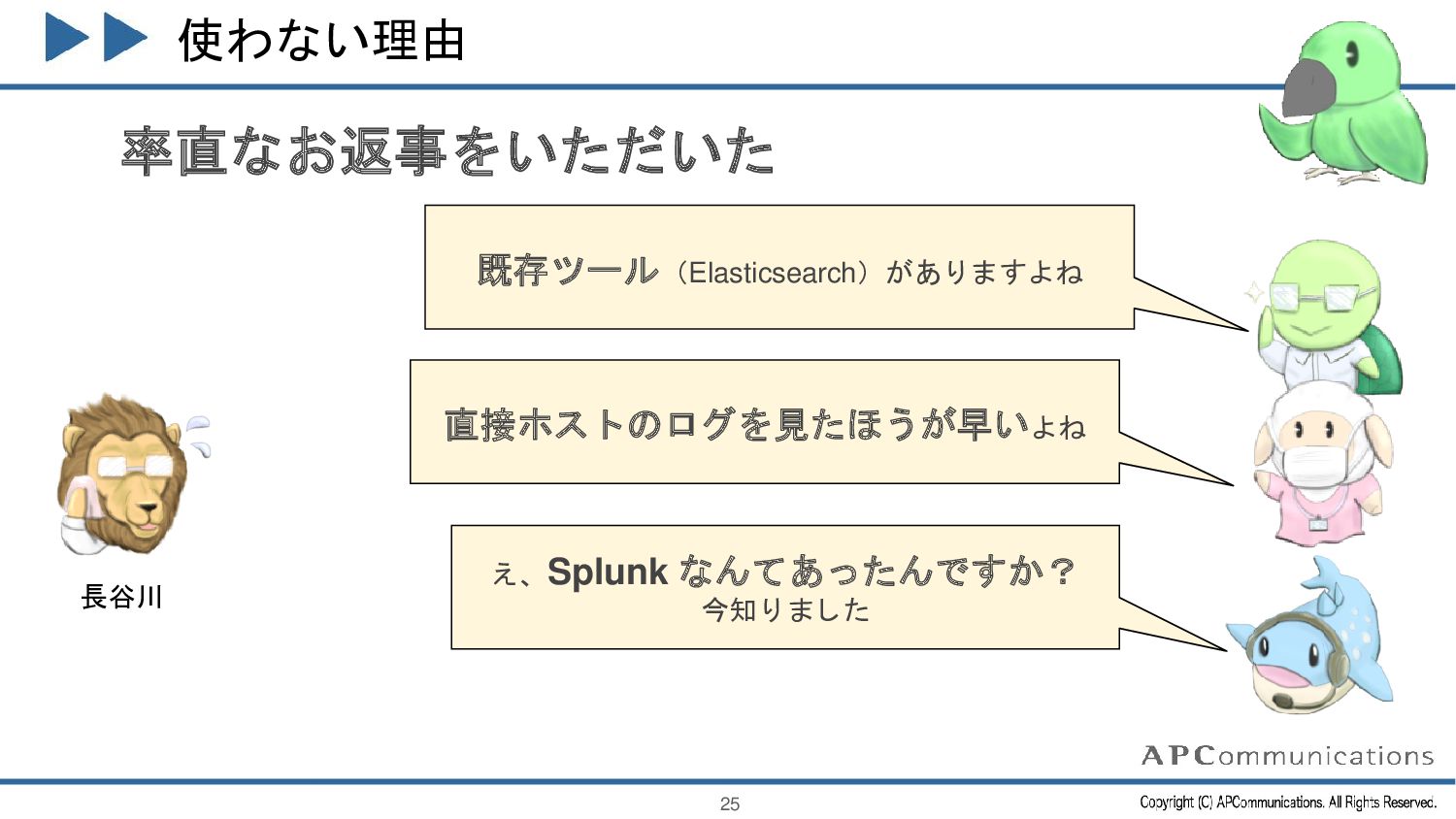{kind=link}
{kind=link}
![[事前アンケートより] Splunk で困っていることは? 27](https://files.speakerdeck.com/presentations/46811f69dcb24b688607f6a39d0265e4/slide_26.jpg){kind=link}
![[事前アンケートより] Splunk で困っていることは? 28 「使い道」に困っている方が計40% これからお話しする失敗談と成功談は、 Splunk での経験談になりますが、 他のログ管理プラットフォームでも 同様の課題が出てくると思います](https://files.speakerdeck.com/presentations/46811f69dcb24b688607f6a39d0265e4/slide_27.jpg){kind=link}
{kind=link}
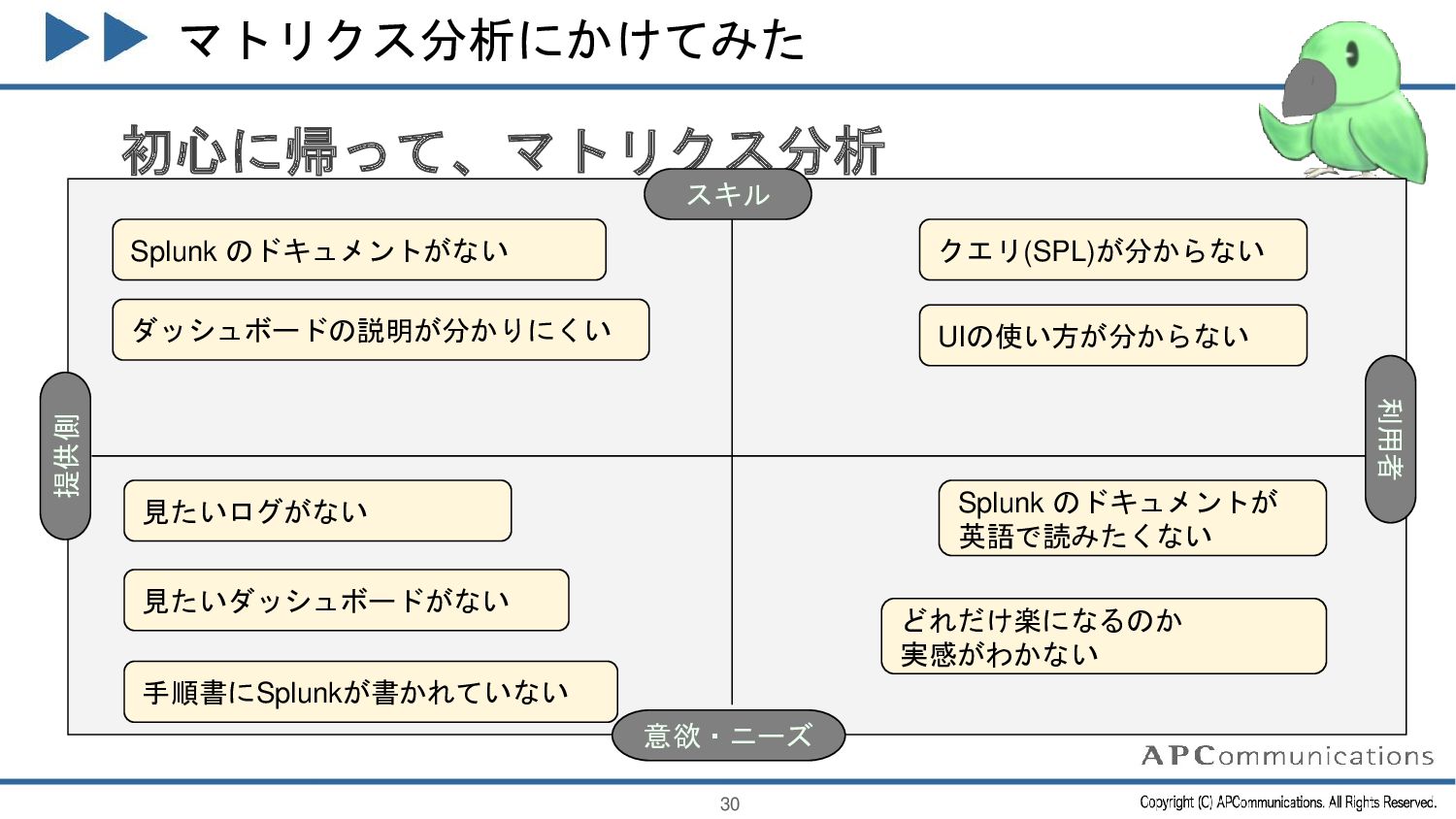{kind=link}
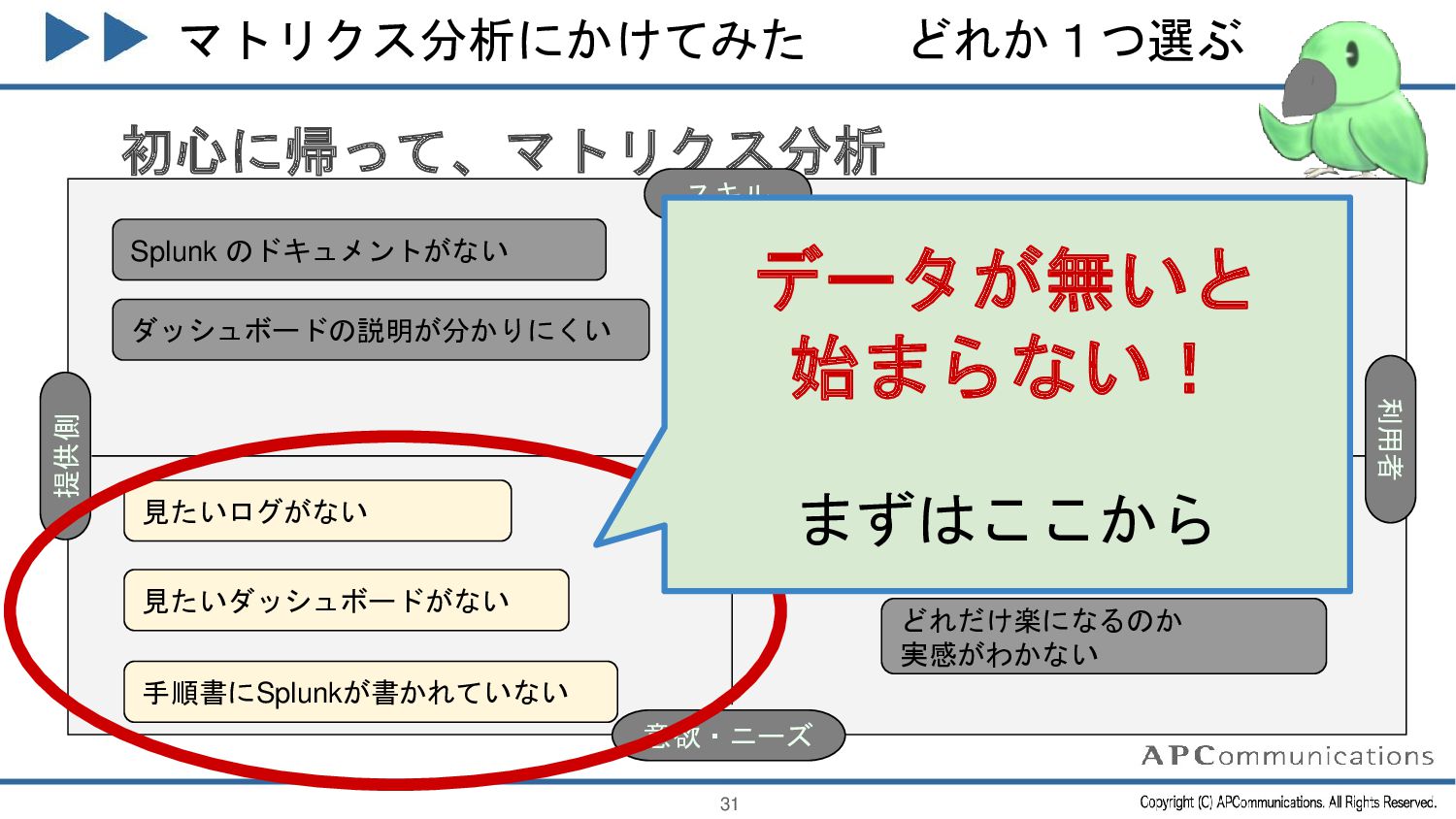{kind=link}
{kind=link}
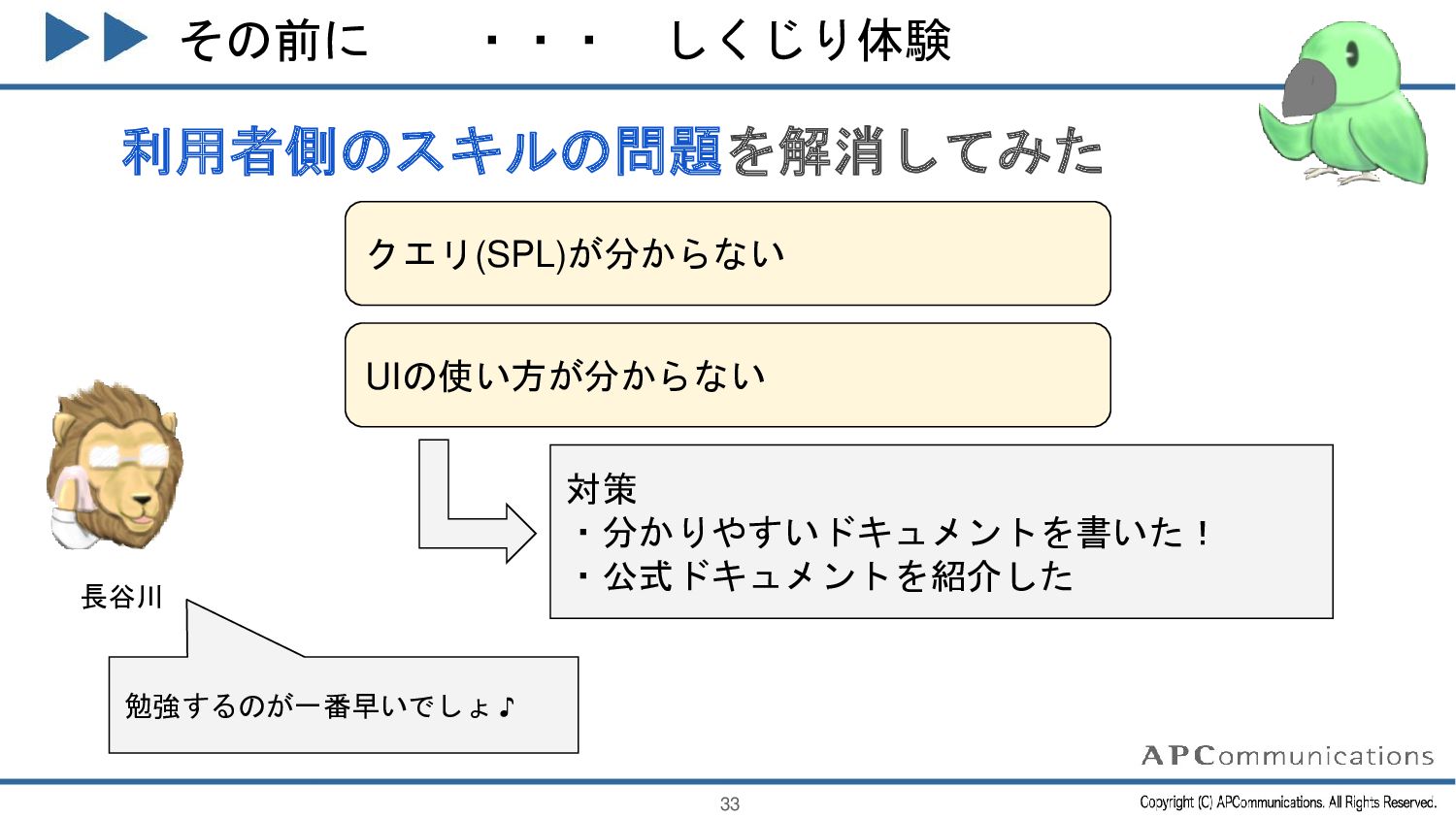{kind=link}
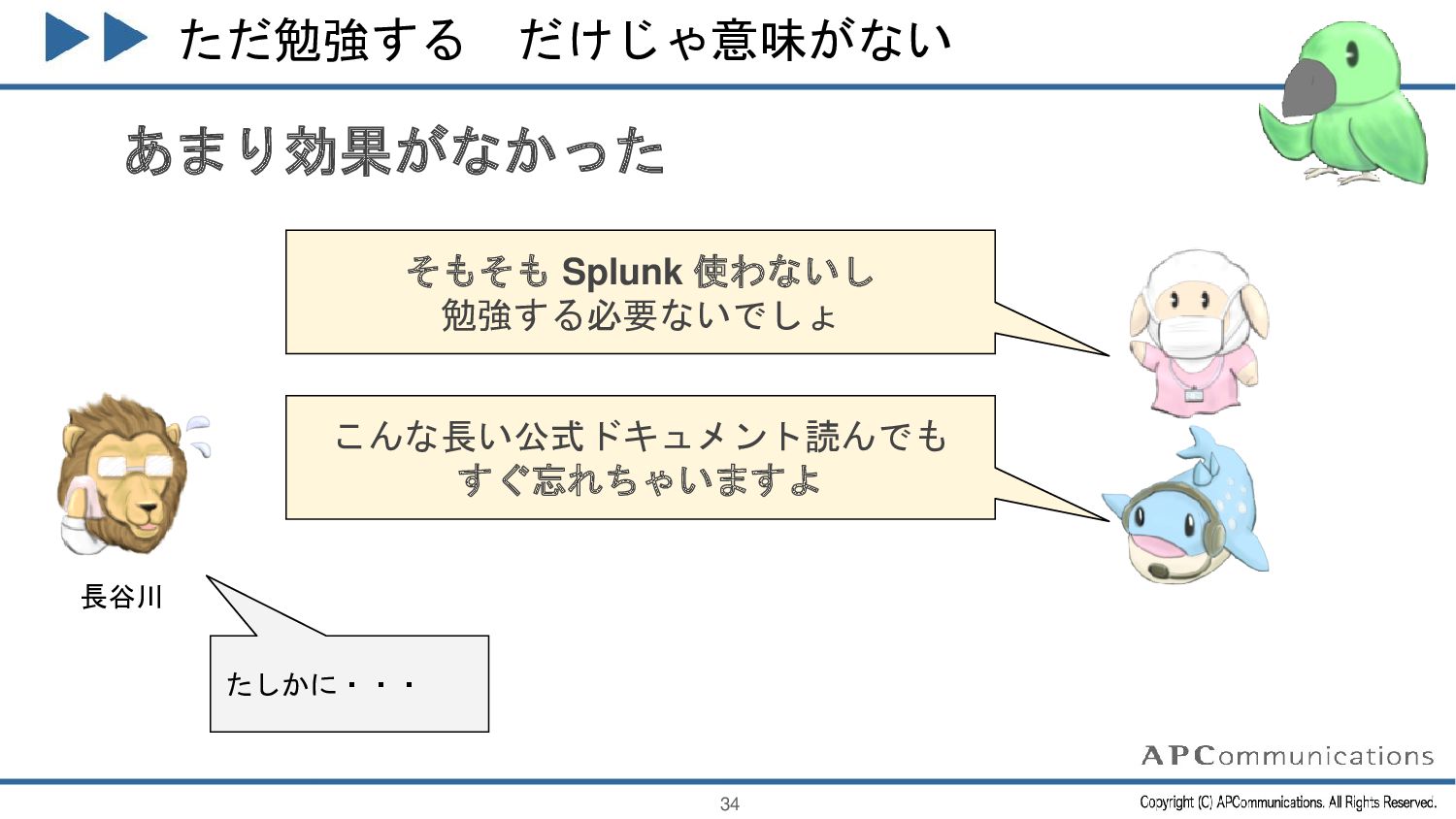{kind=link}
{kind=link}
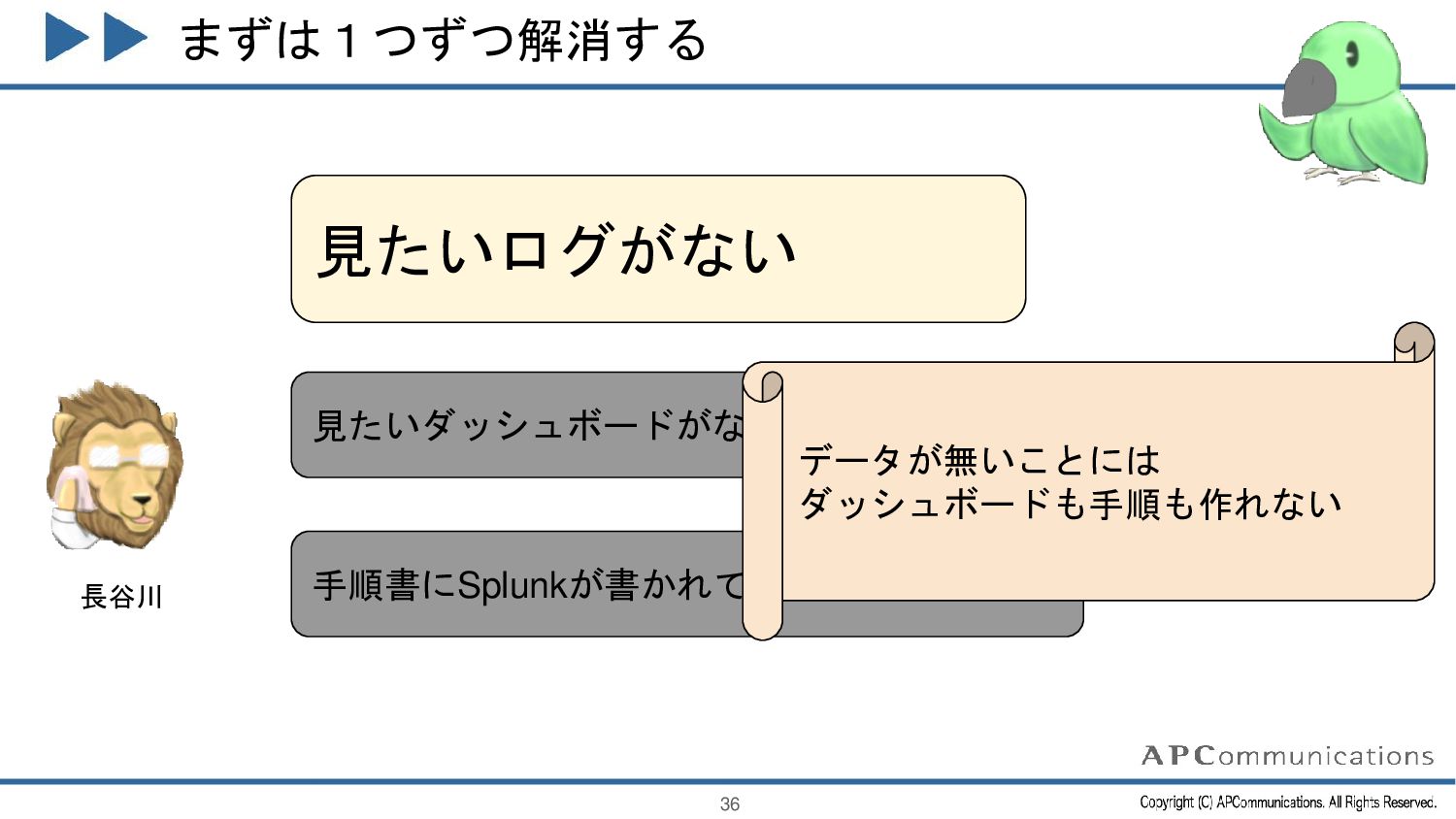{kind=link}
{kind=link}
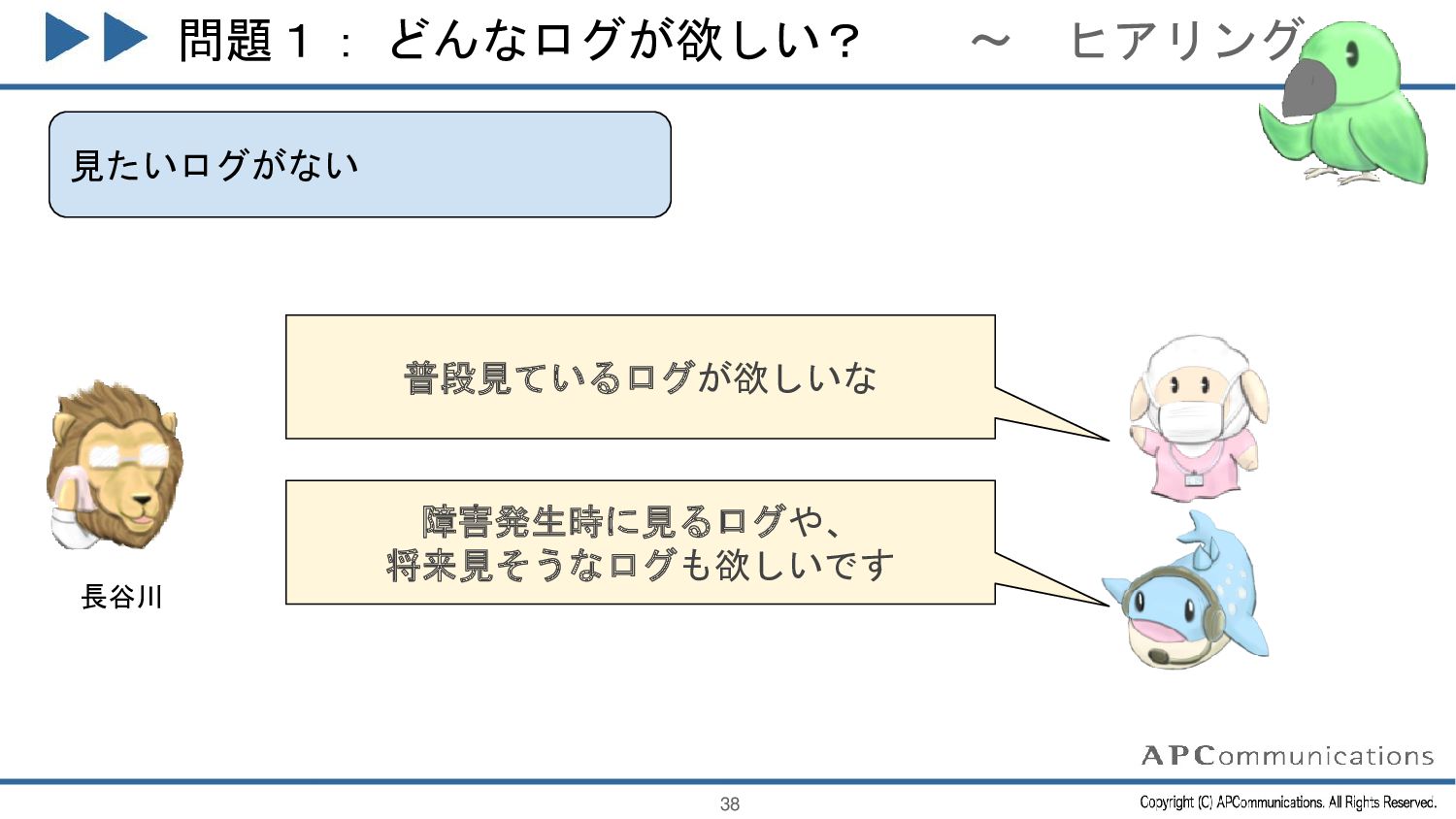{kind=link}
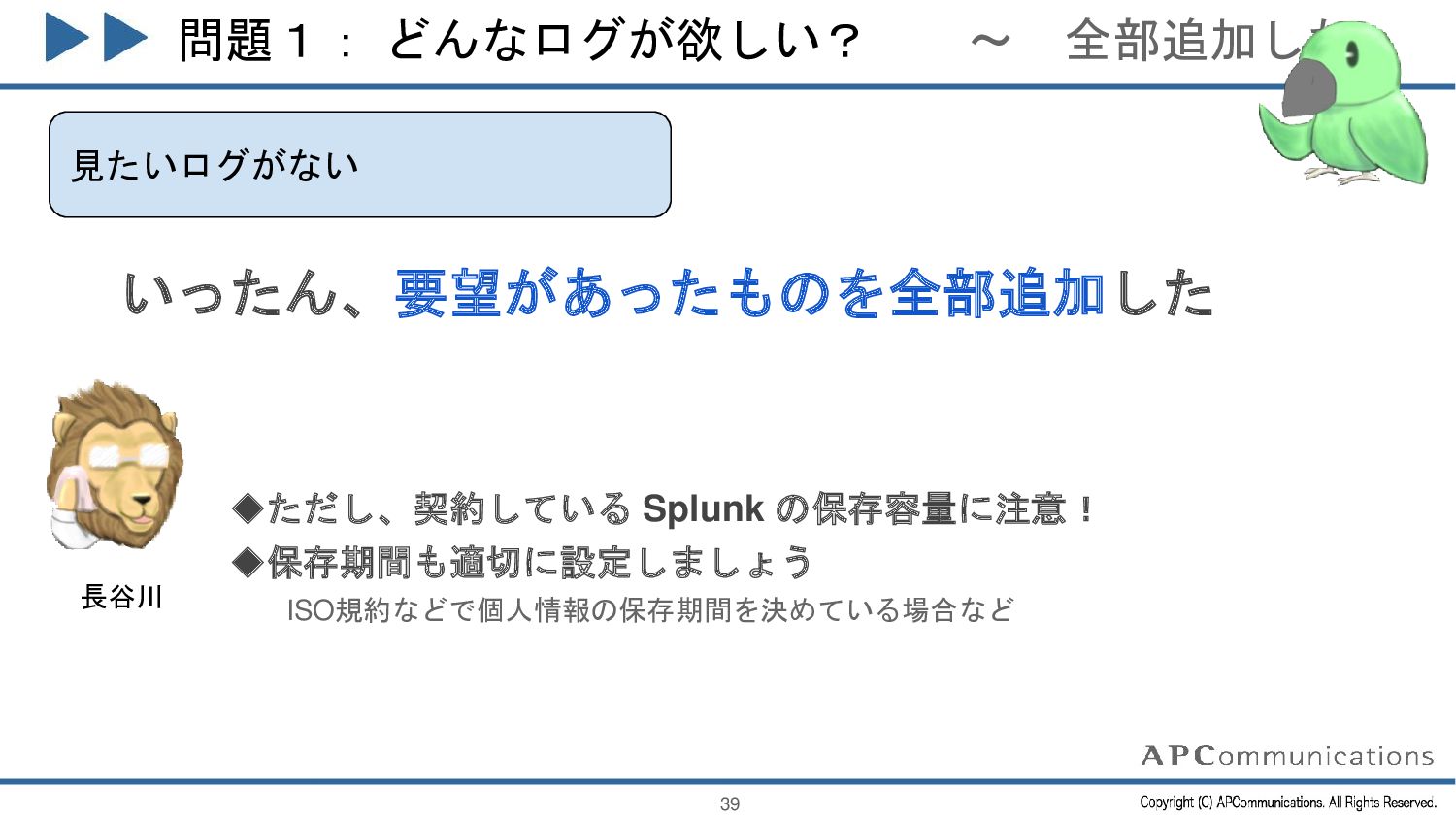{kind=link}
{kind=link}
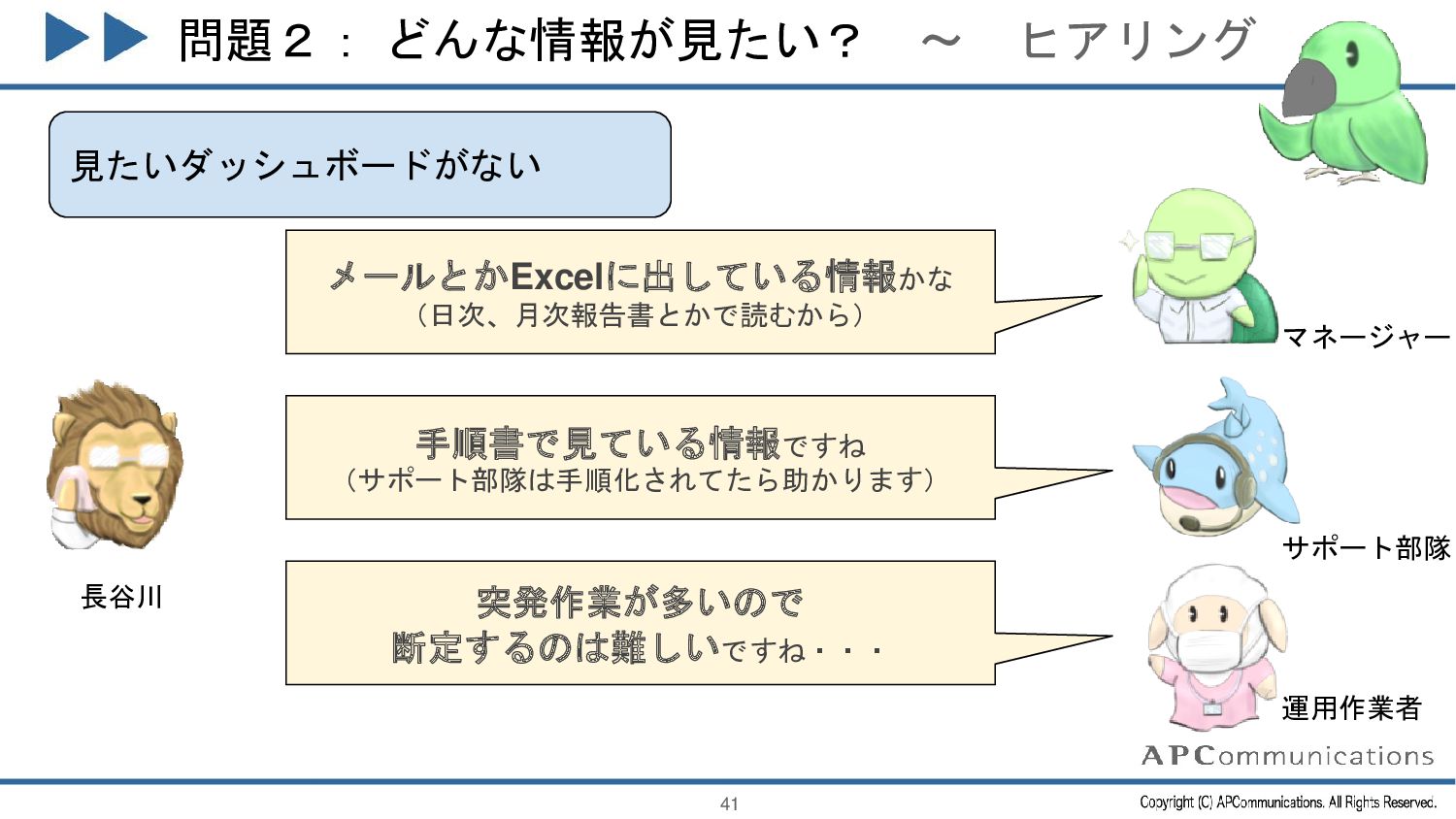{kind=link}
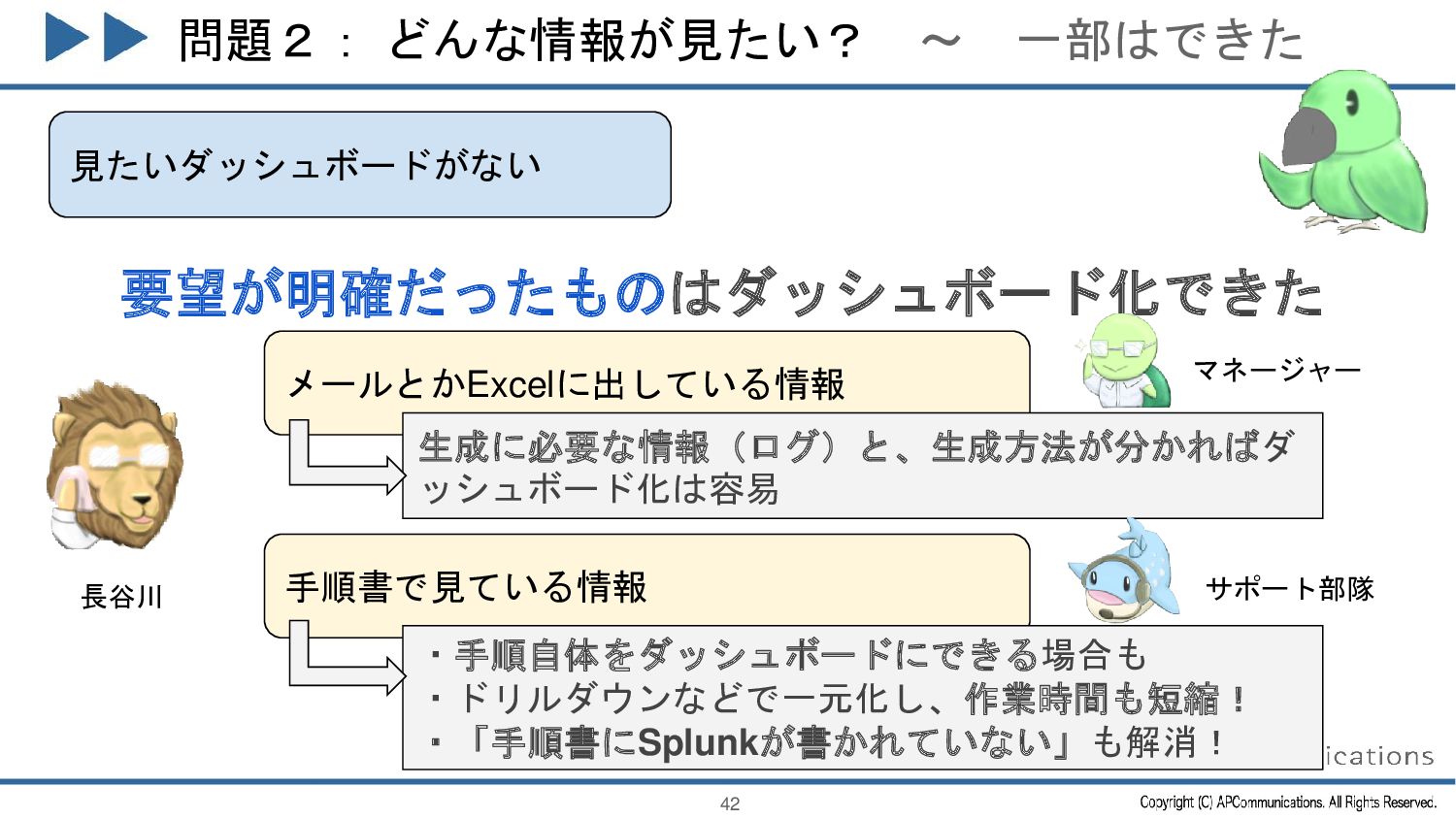{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
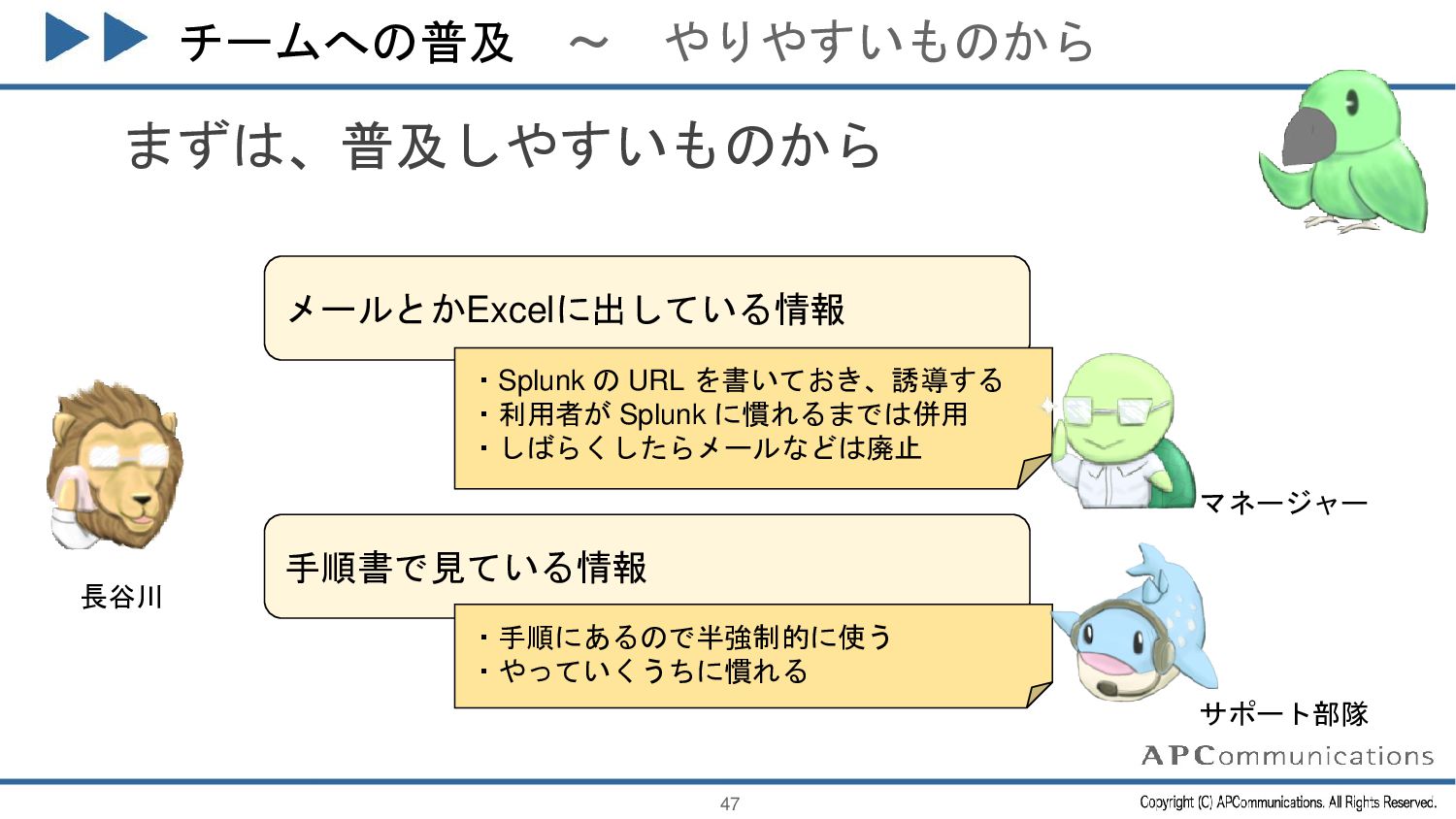{kind=link}
{kind=link}
{kind=link}
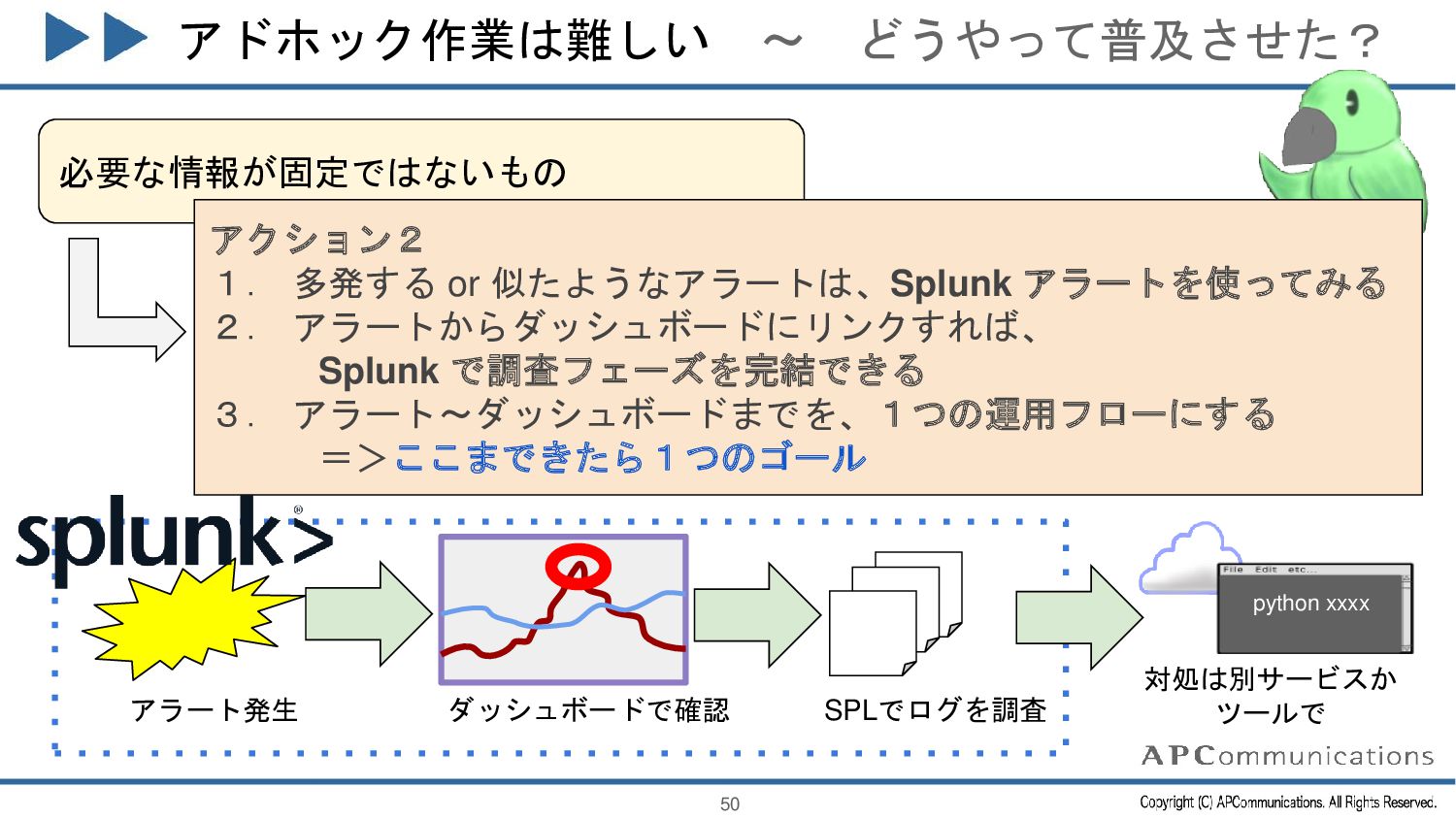{kind=link}
{kind=link}
{kind=link}
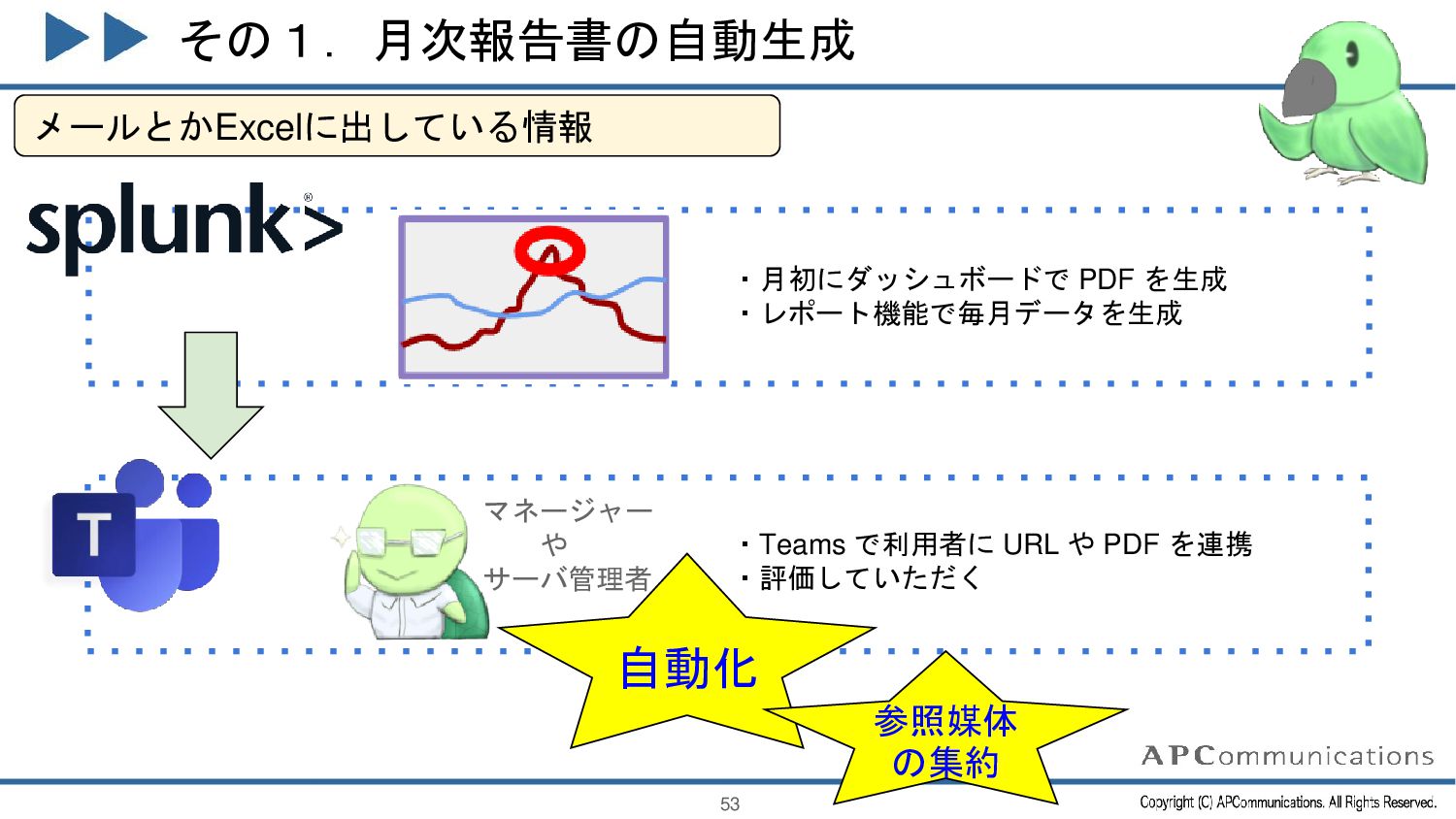{kind=link}
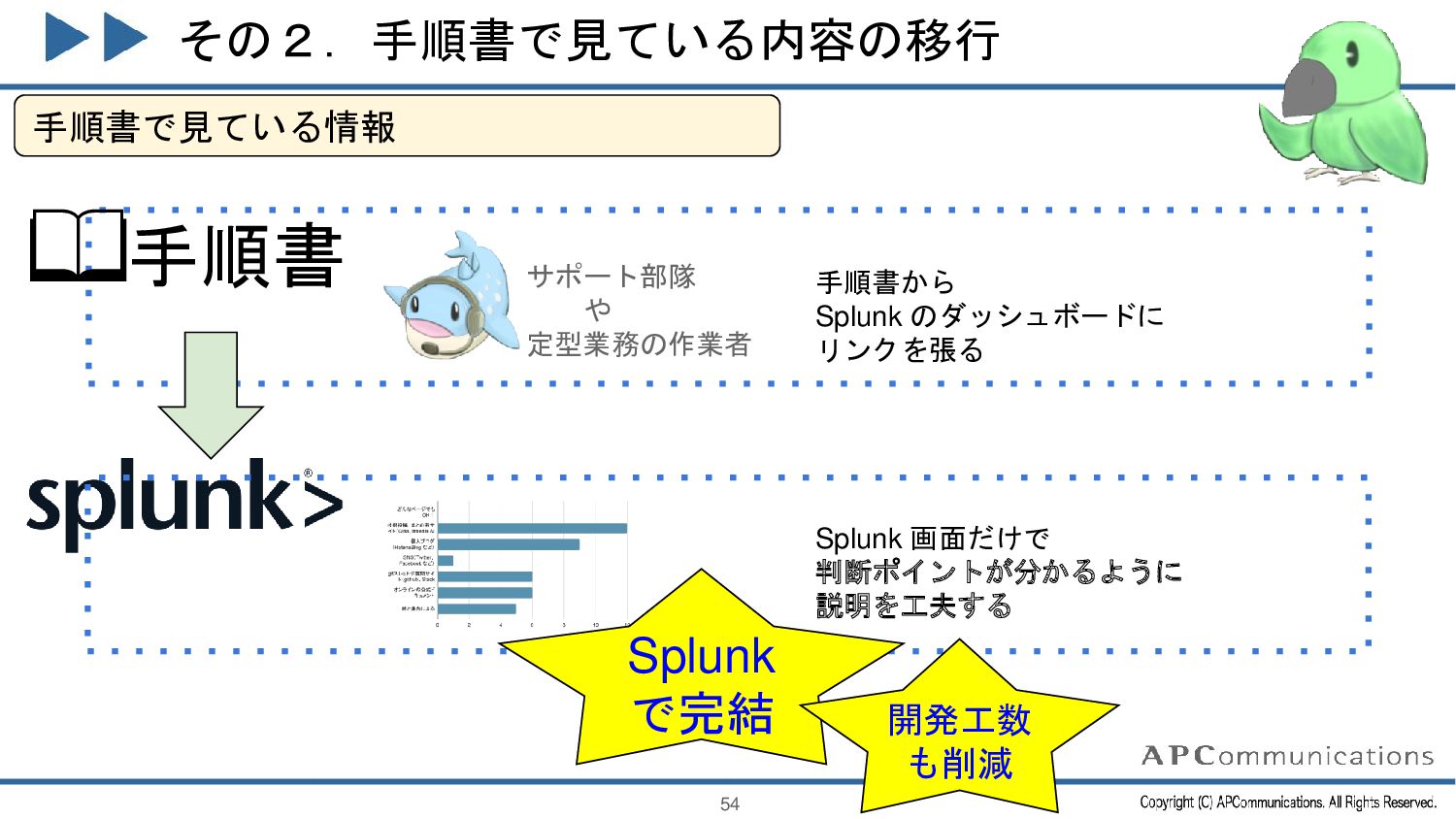{kind=link}
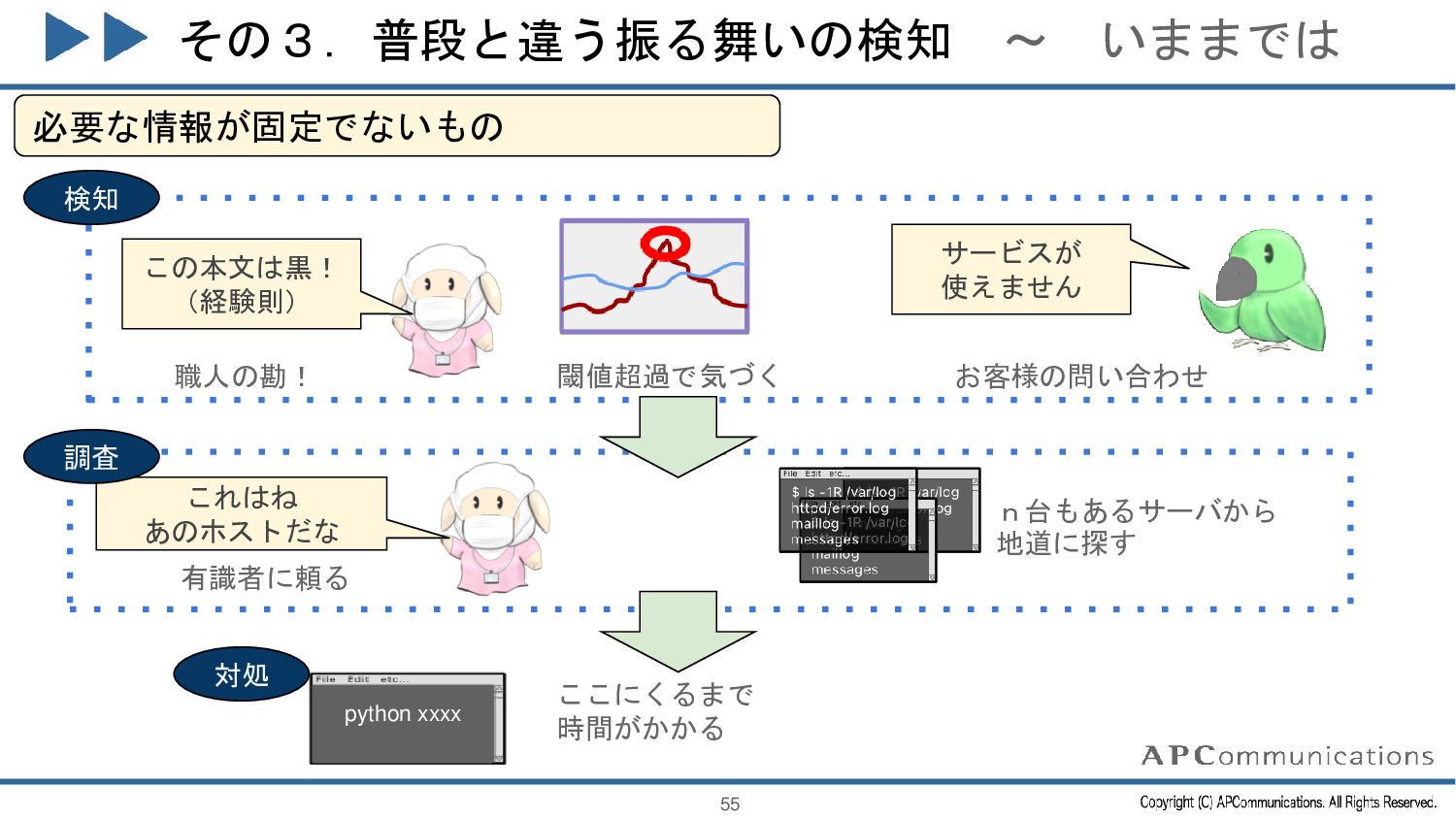{kind=link}
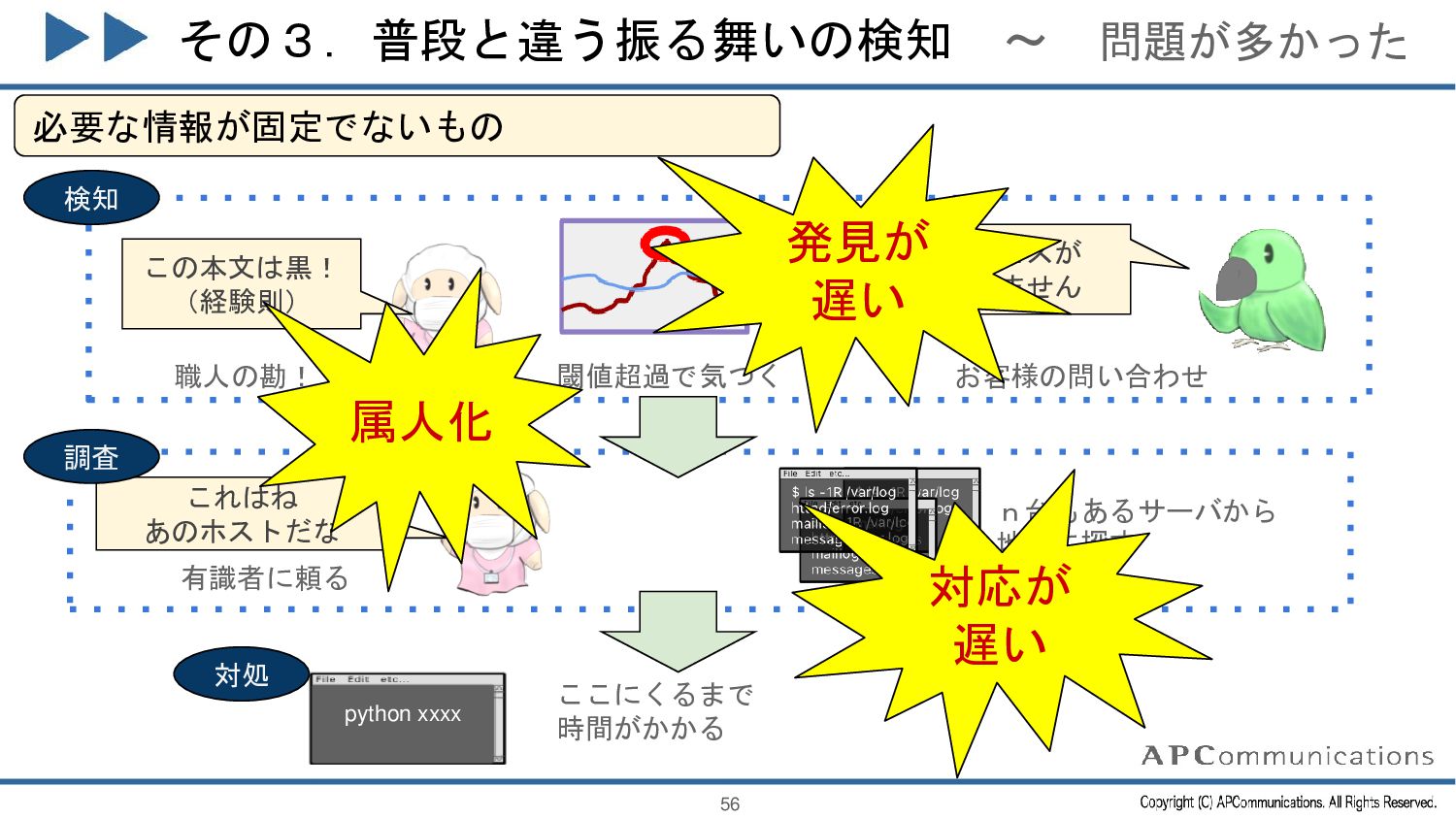{kind=link}
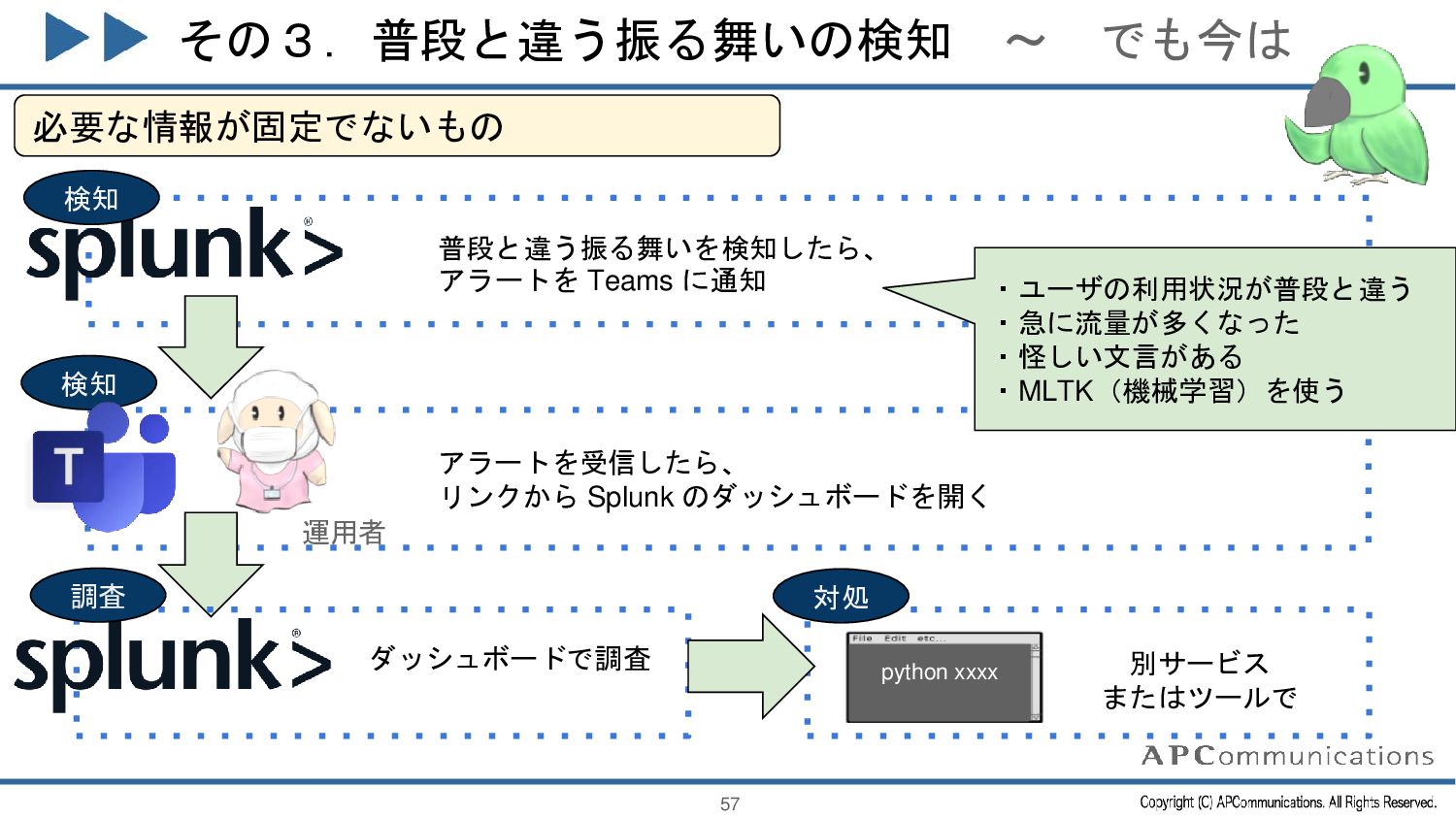{kind=link}
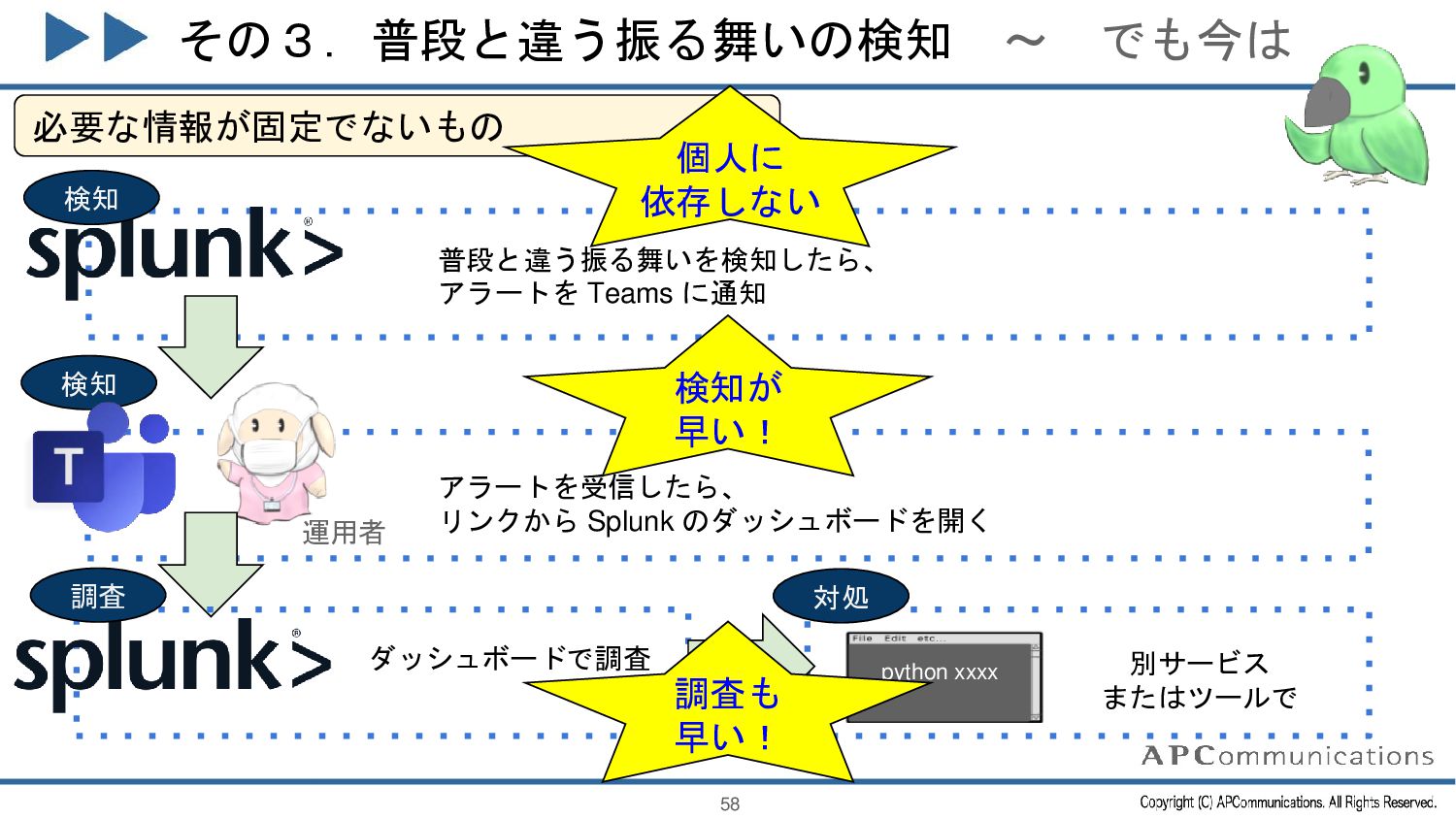{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
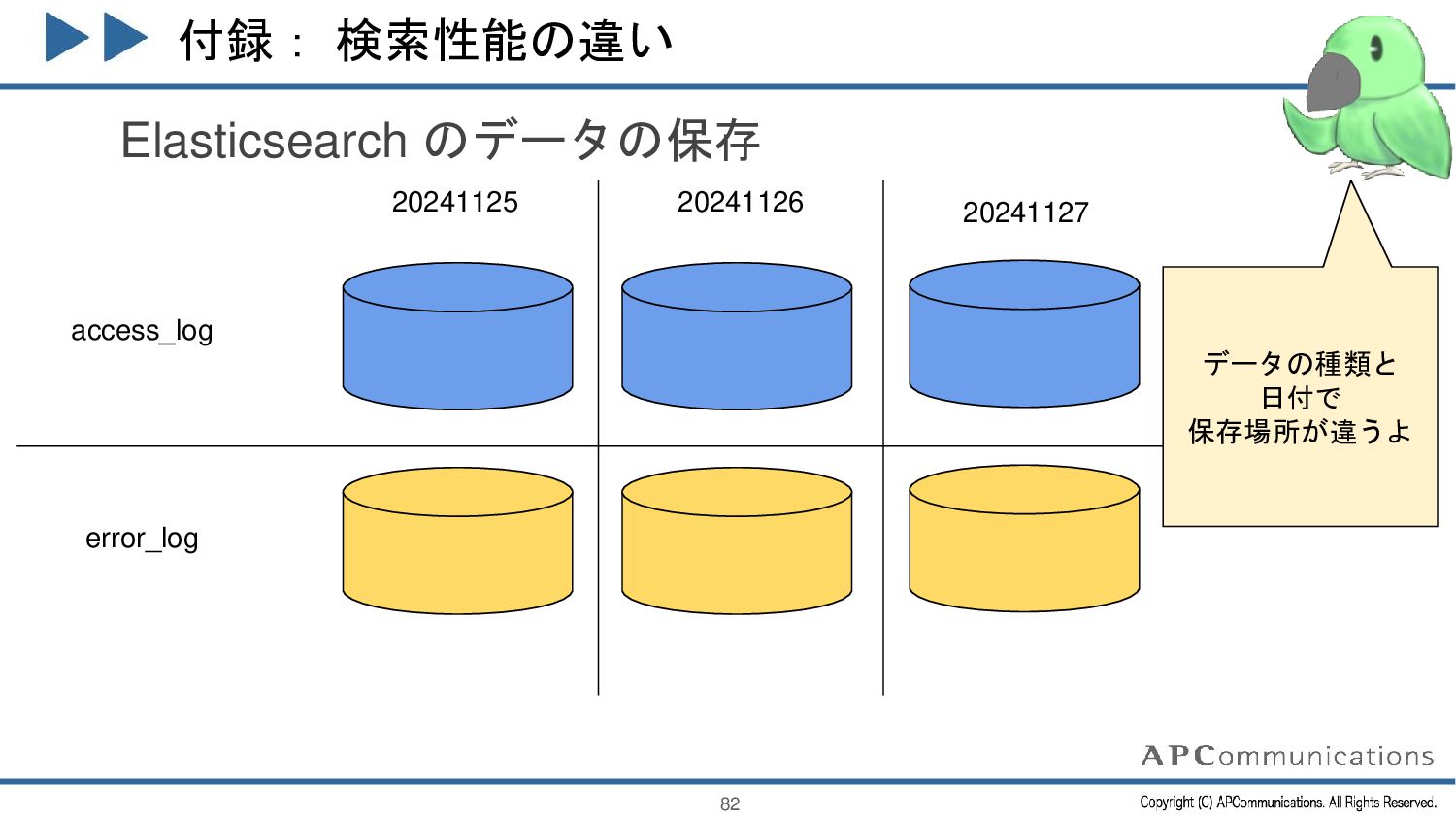{kind=link}
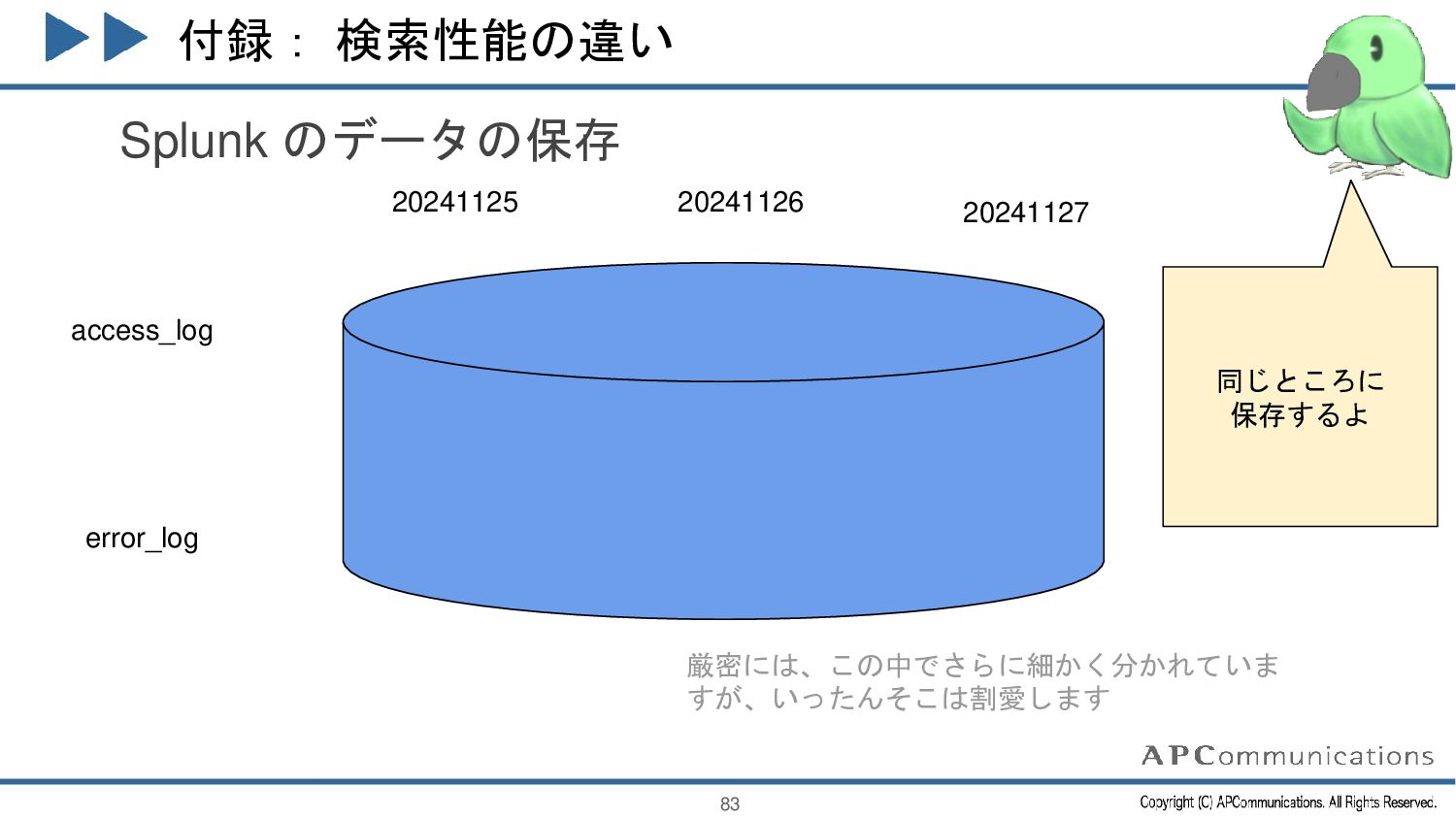{kind=link}
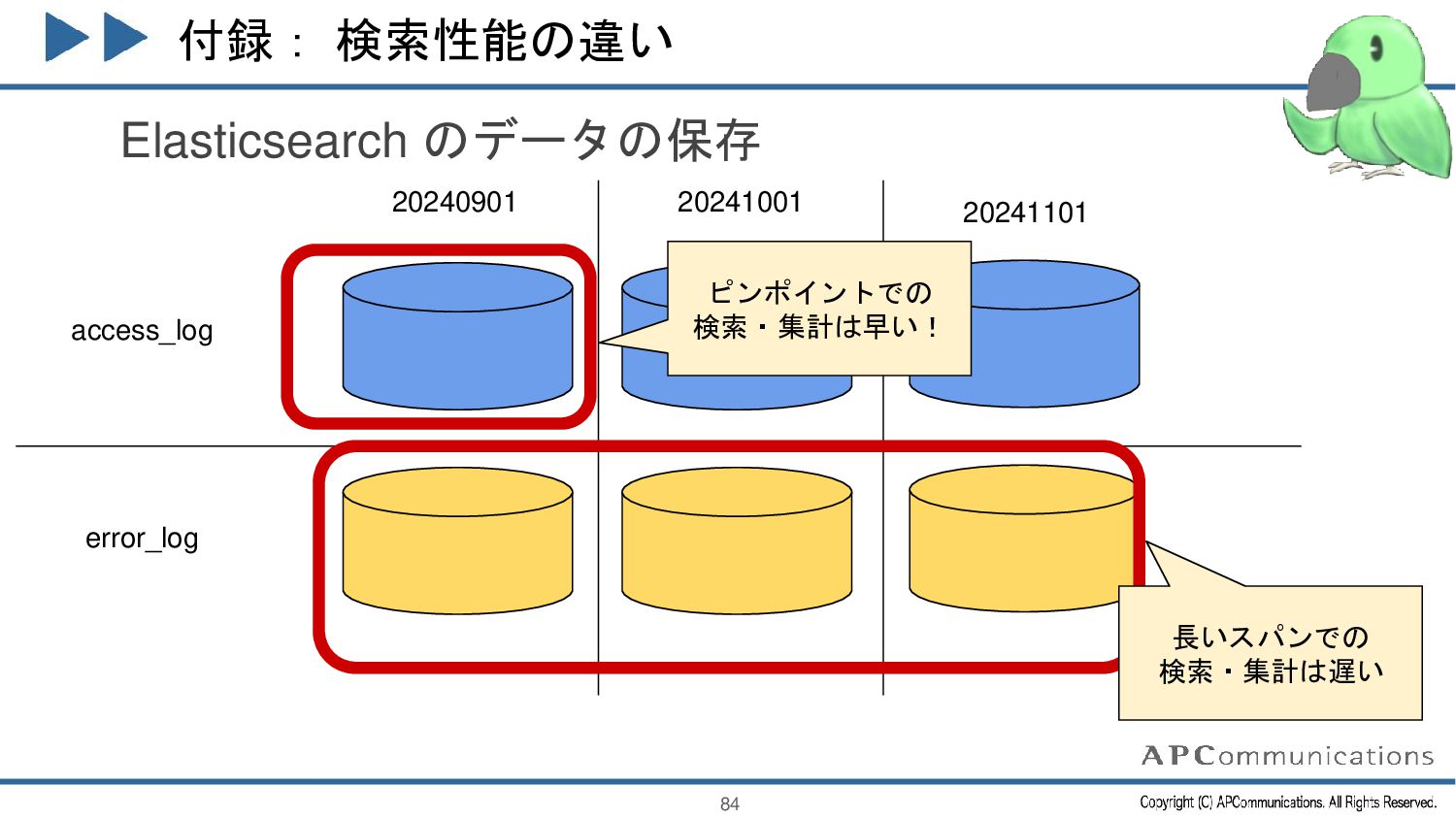{kind=link}
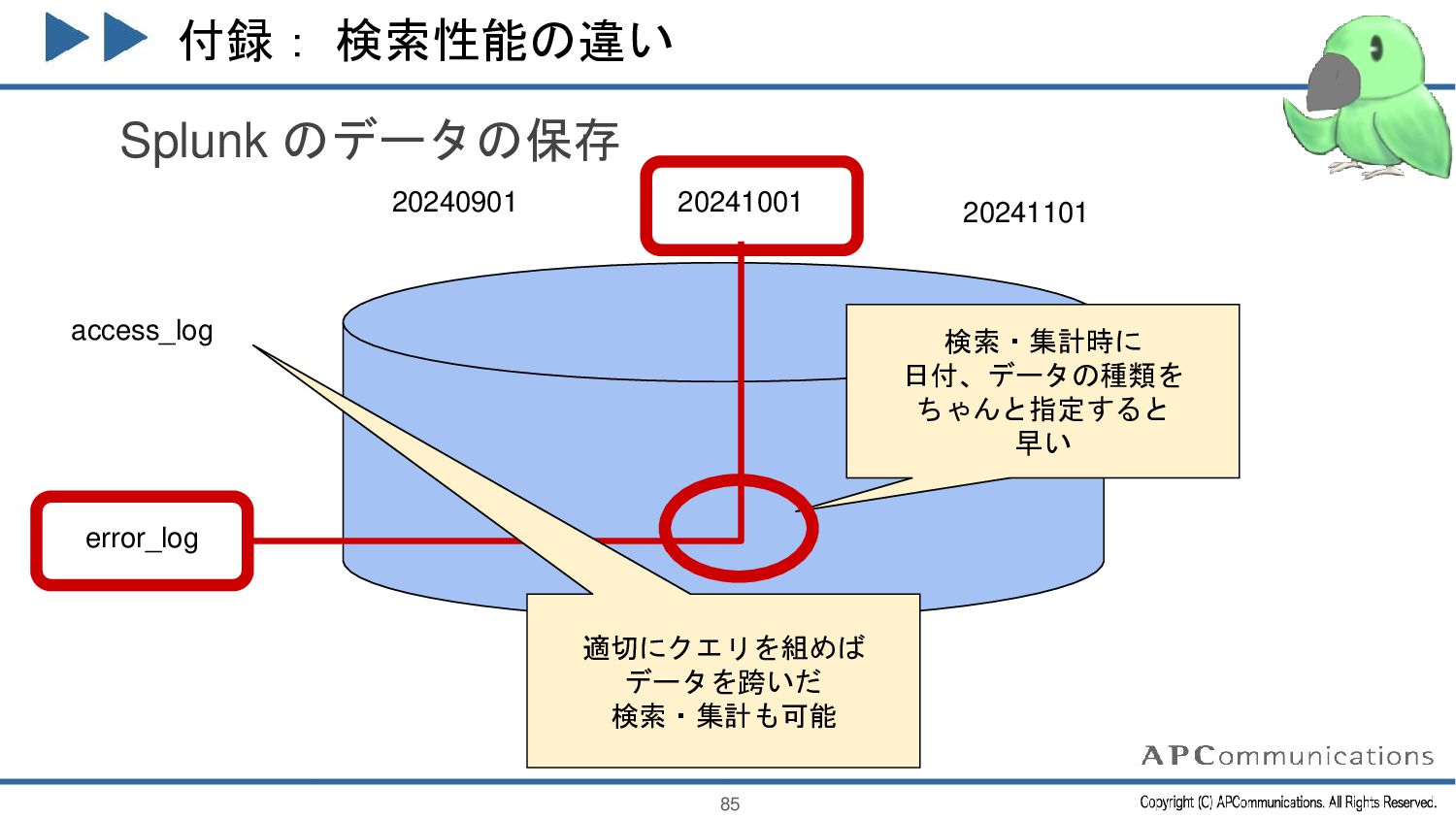{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}