Wondering about the best development practices that will let you sleep at night while your Kafka related applications ship millions or billions of messages each day?!
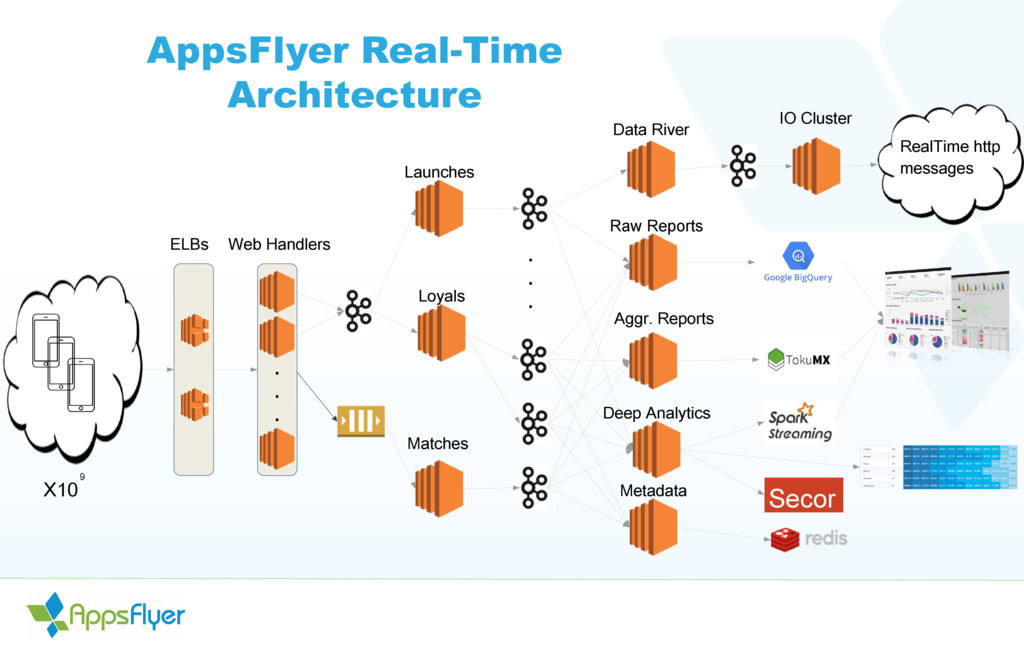
AppsFlyer R&D Team has a full 2 years experience of using Apache Kafka as the main messaging backbone of its mobile attribution service, shipping over 10 billion messages in Kafka every single day, maintaining tens of different services consuming and producing from 2 Kafka clusters holding 40+ topics.
Kafka is such a critical part of the AppsFlyer system architecture that we wrote a dedicated monitoring service, which monitors our consumers and producers, and is even used to autoscale our services as load varies during the day, we’ll cover this service as part of the meetup. We’ll also cover how we use Kafka for testing new code before deploying to productio
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
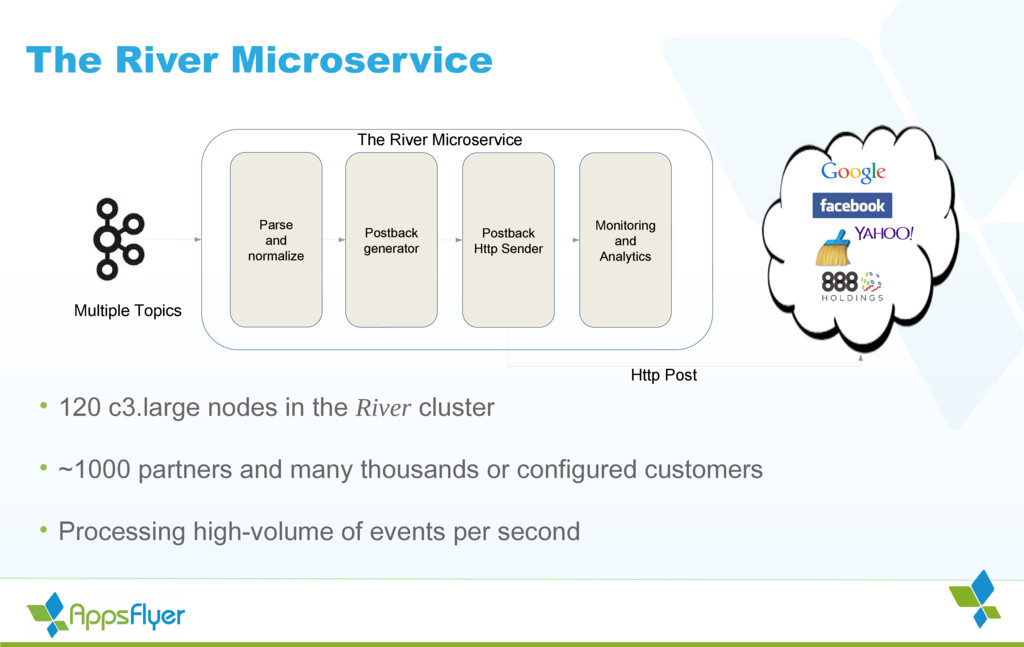{kind=link}
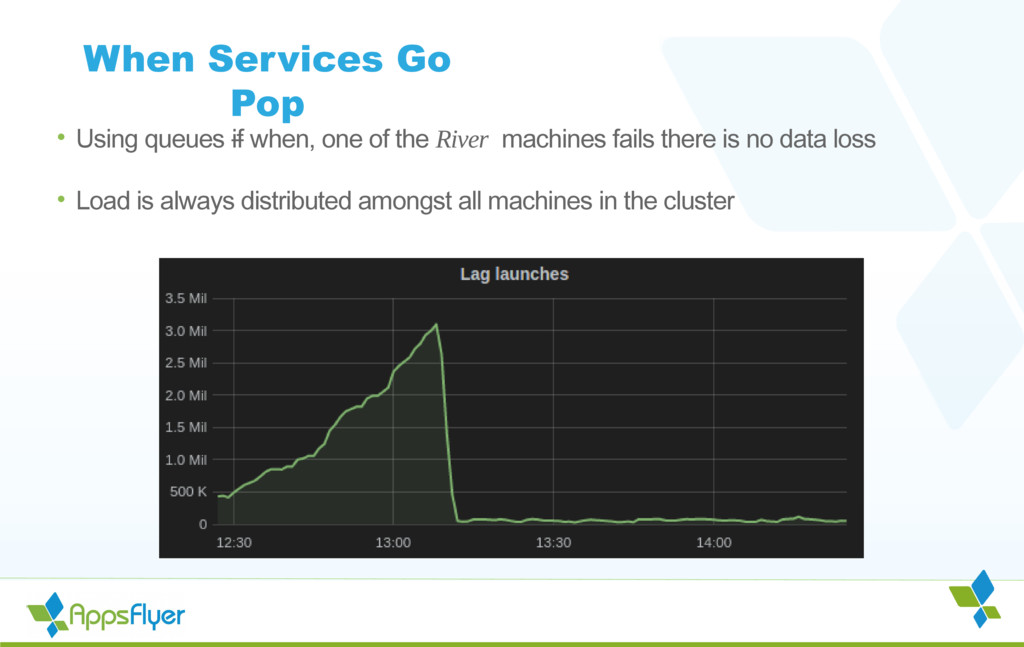{kind=link}
{kind=link}
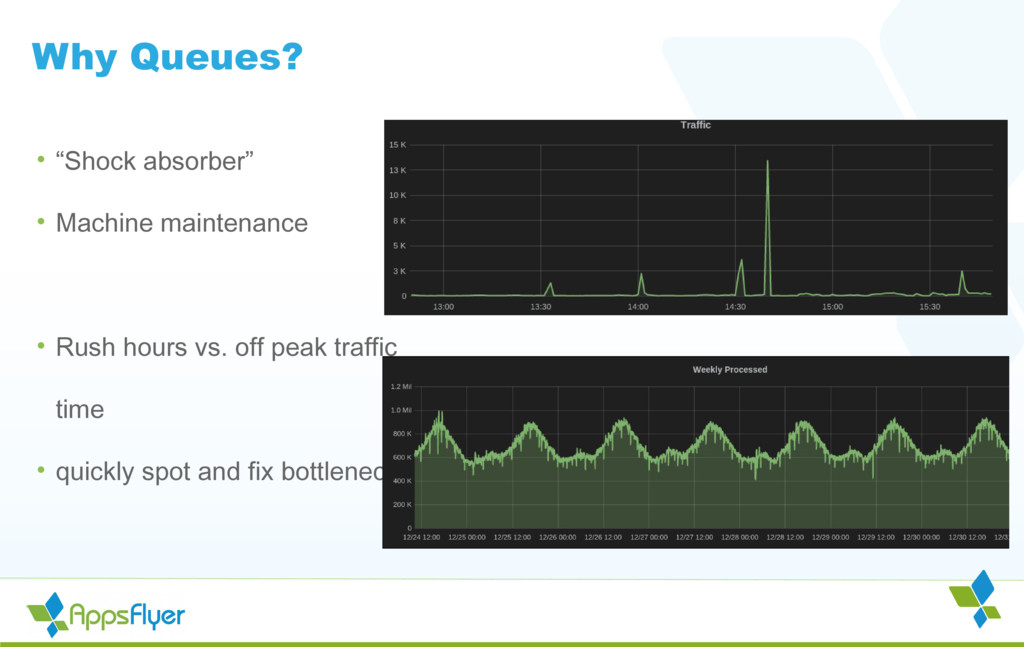{kind=link}
{kind=link}
{kind=link}
{kind=link}
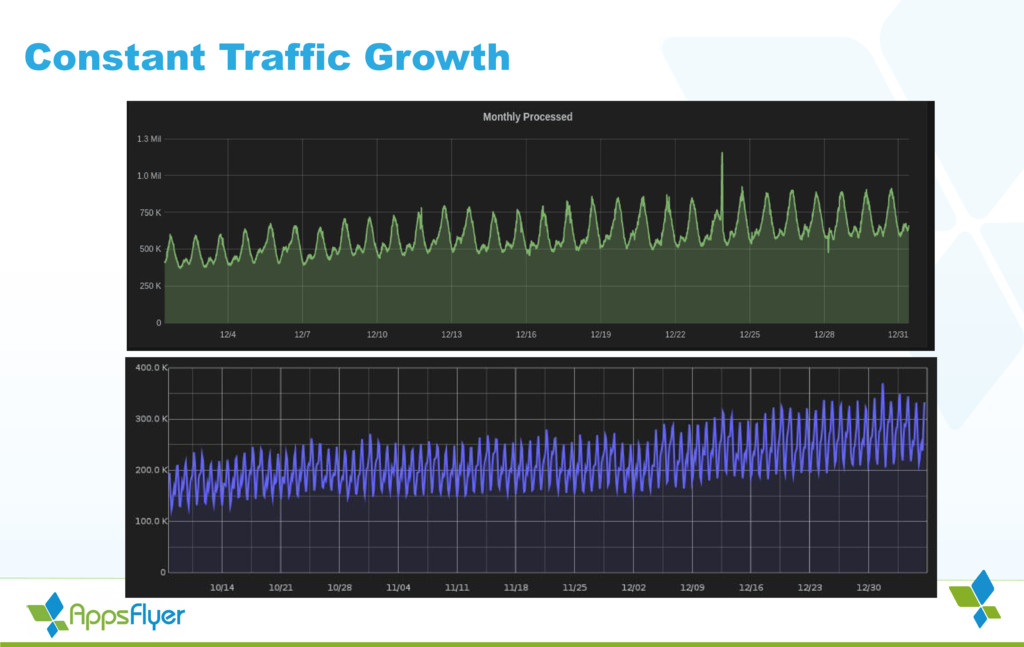{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You. WE ARE HIRING!! Email: [email protected]](https://files.speakerdeck.com/presentations/aceb6d99986241dbafaeedd26155e18f/slide_29.jpg){kind=link}