In this presentation I discuss some of the ongoing work at MAST and STScI, and speculate on how these changes in the technology landscape of astronomy and astrophysics data management may be relevant to the multi-messenger astronomy community.
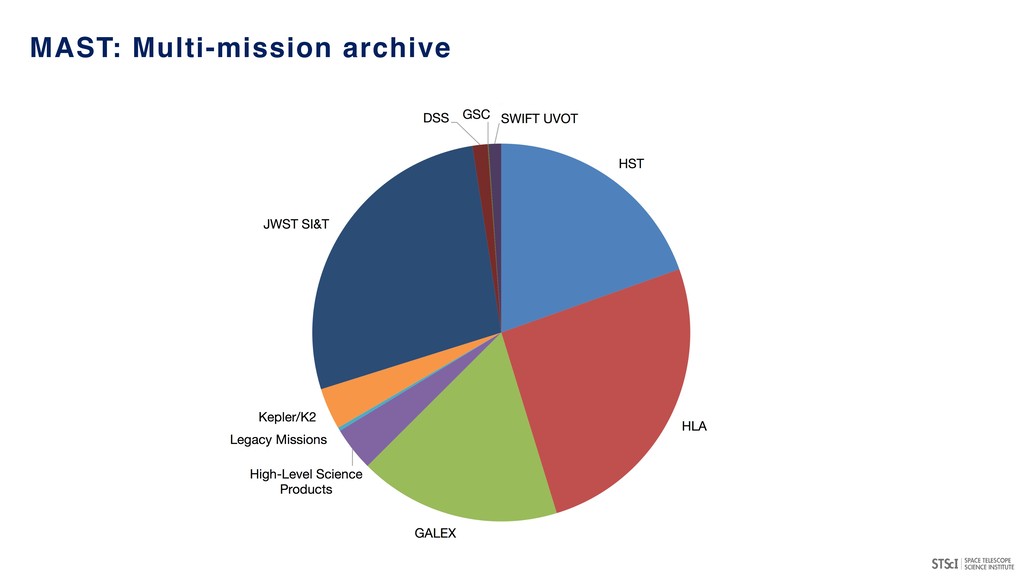
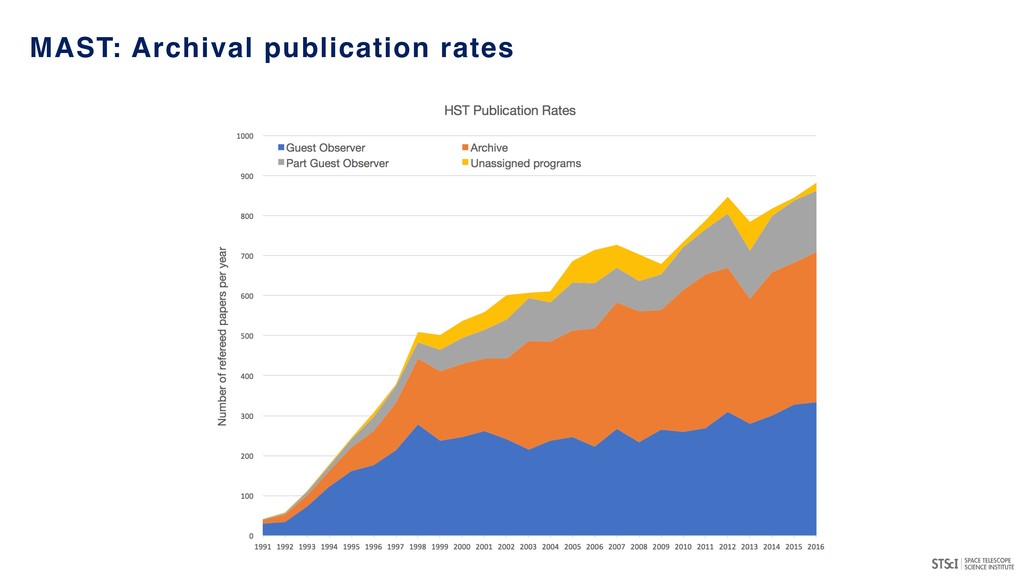
• Responsible for DMS portfolio for all missions (HST, JWST, Kepler/K2, TESS, WFIRST, etc.) • Exploring new technologies, services and infrastructure for data management • Developing community expertise in combining data science and astronomy STScI: Data Science Mission Office https://archive.stsci.edu/reports/BigDataSDTReport_Final.pdf
2. 3. Science platforms as environments for archival data analysis and transient follow-up. Event-driven ‘serverless’ architectures for data processing. Community-contribution at all levels of the data management infrastructure.
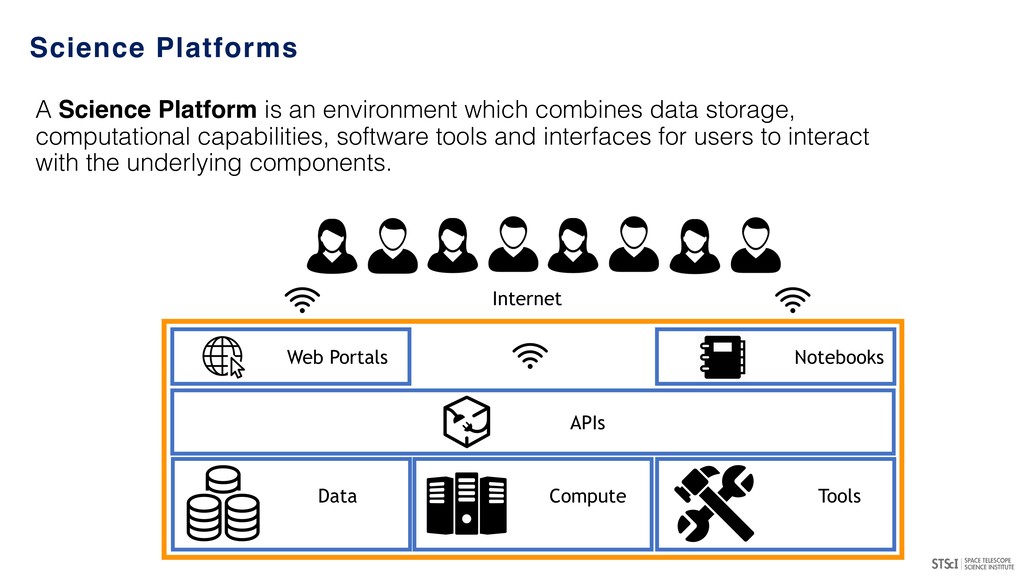
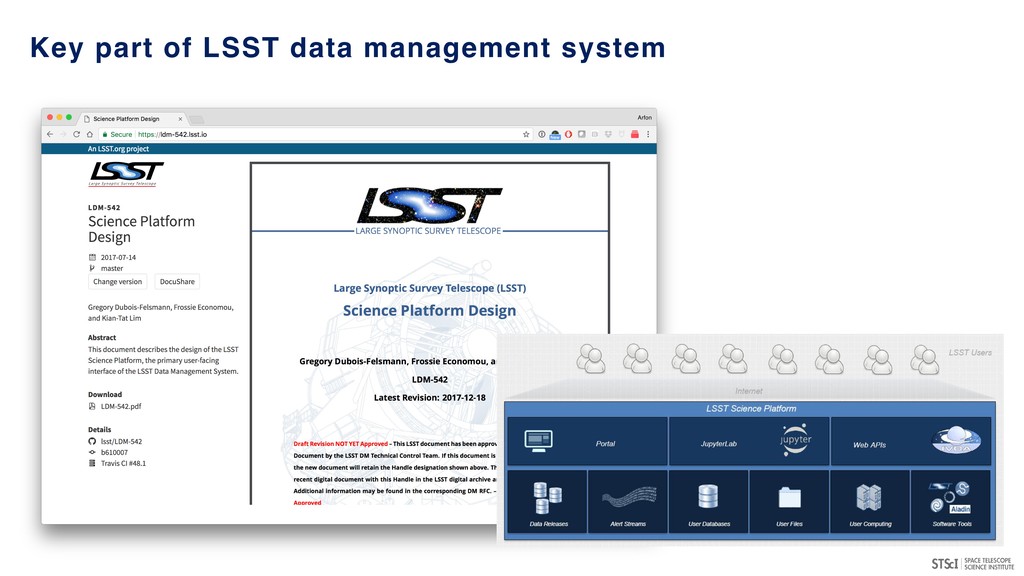
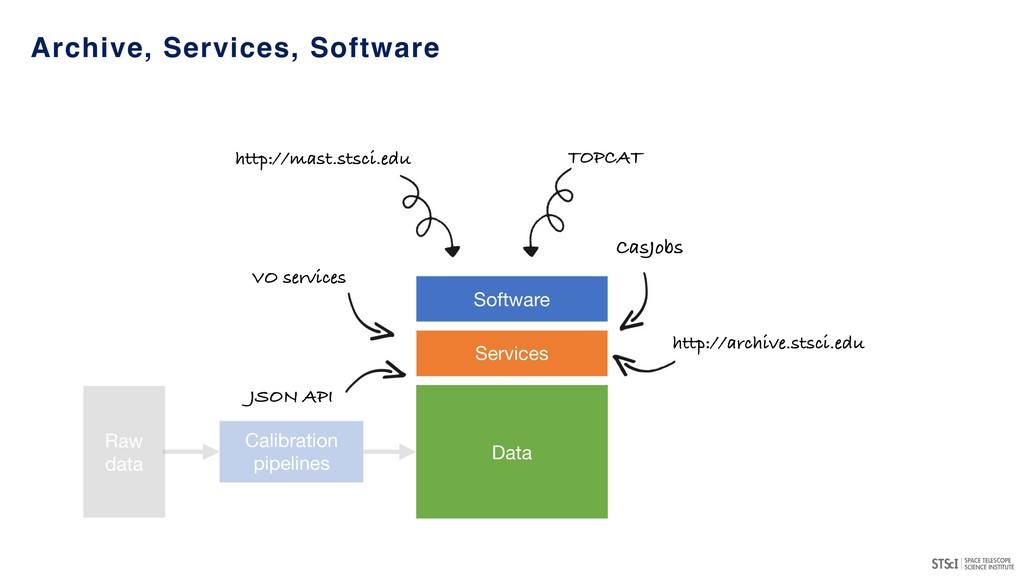
A Science Platform is an environment which combines data storage, computational capabilities, software tools and interfaces for users to interact with the underlying components.
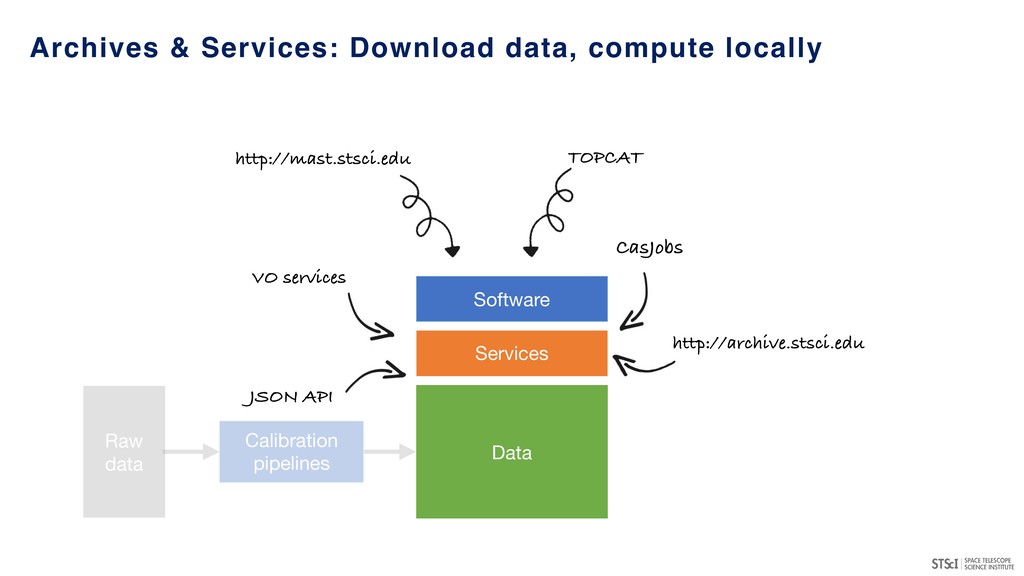
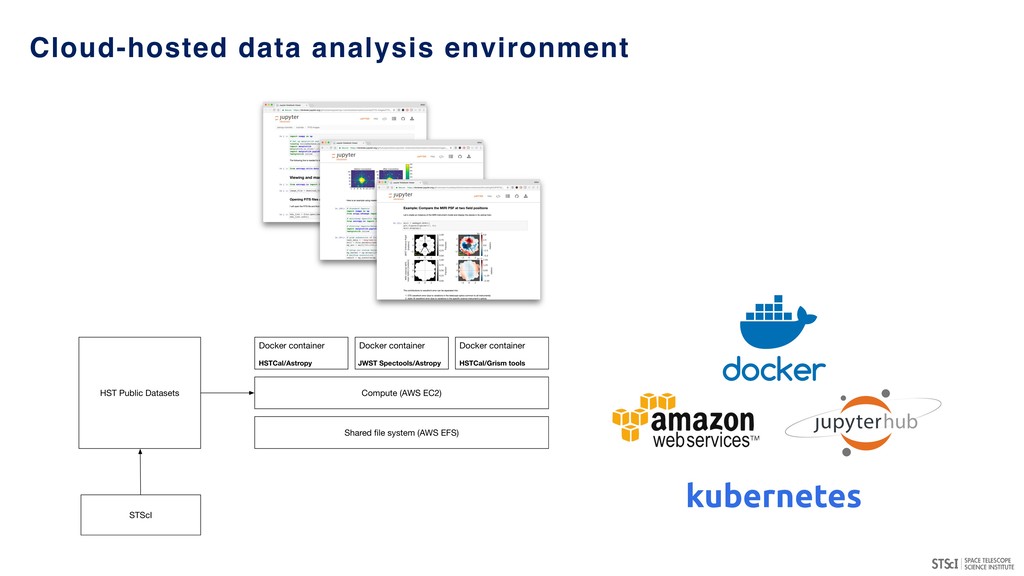
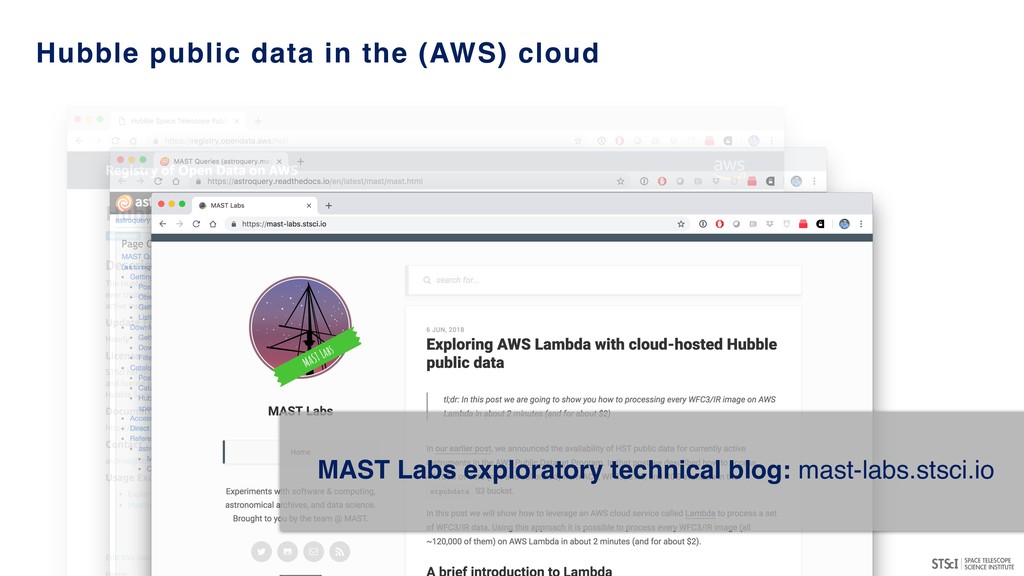
many major projects & archives (MAST, IPAC, LSST, ESAC, CADC, NOAO…) - in a semi-coordinated fashion. • Provide access to large, high-value datasets and the ability to compute against them (server-side analytics). • Potentially provide access to substantial scalable compute resources including GPUs. • Leverages existing programmatic interfaces to astronomical archives (e.g. VO services and other APIs). • Convergence of technologies/conventions (notebook-driven analyses) for repeatable, reliable data exploration and analysis. • Potential environment for transient event analyses and broker development.
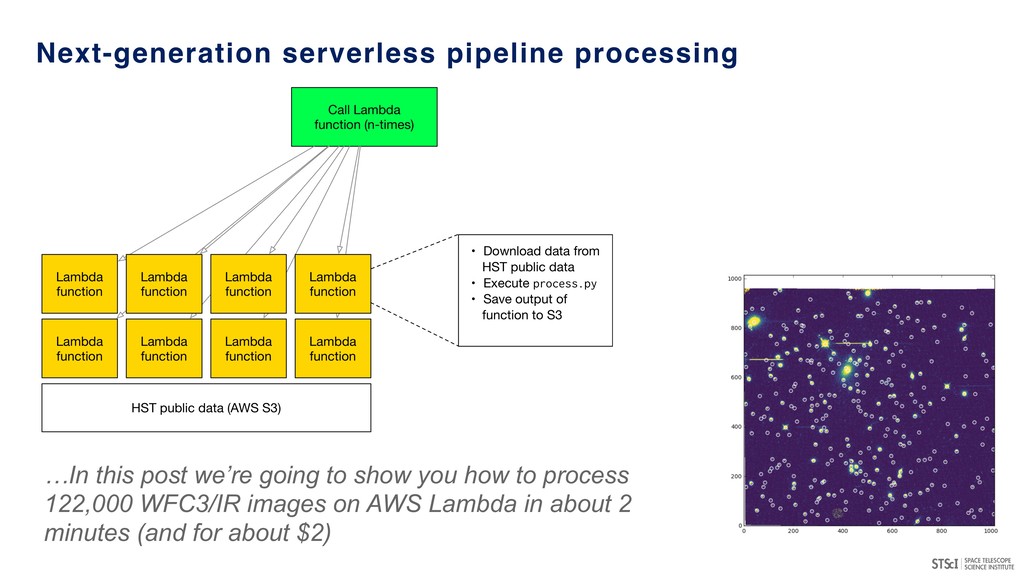
(e.g. in Python, C++, Julia, Haskell, Fortran…) • Upload the function to a cloud computing platform (AWS Lambda, Google Cloud Functions, Azure Functions, Apache Whisk) • Define resources required for cloud function to execute (CPU/RAM) • Trigger function based on event rules (e.g. event posted to API or appearing in event stream) • SCIENCE!
& astronomers to focus on ‘business logic’ of their analysis rather than thinking about infrastructure. • Can be triggered from multiple settings (e.g. automated background tasks or inline analysis steps) • Event-driven & responsive - can be very cost effective. • Potentially interesting for more data & compute intensive archive functionalities. • SCALE: Makes massively parallel computations easy*… * Easy to shoot yourself in the foot too
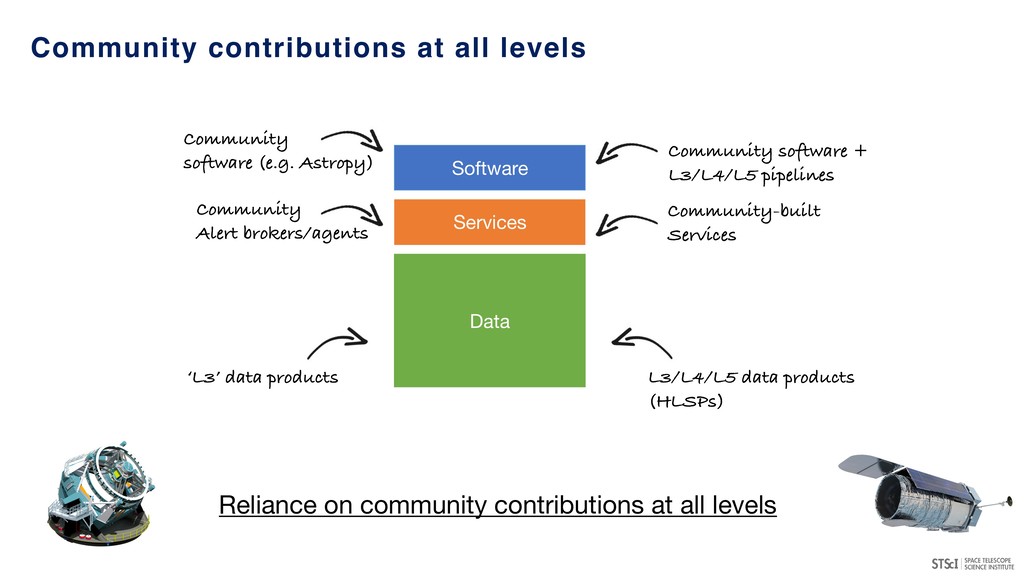
brokers/agents Community-built Services ‘L3’ data products Community software (e.g. Astropy) Community software + L3/L4/L5 pipelines L3/L4/L5 data products (HLSPs) Reliance on community contributions at all levels
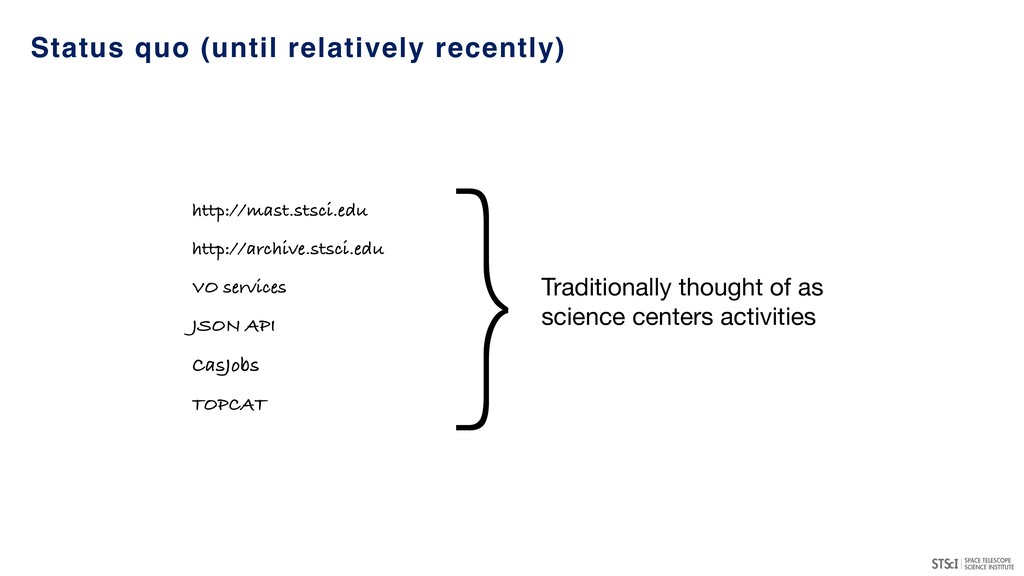
now the ‘new normal’ in many sectors (especially data science) • What might the different roles be for projects/facilities, science teams, individuals? • Communities often form around shared challenges, shared data products • Easier to recognize innovations created by others when working with similar data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! [email protected] https://mast-labs.stsci.io](https://files.speakerdeck.com/presentations/32035f88859d4e2a99a99f65f5fe1977/slide_33.jpg){kind=link}