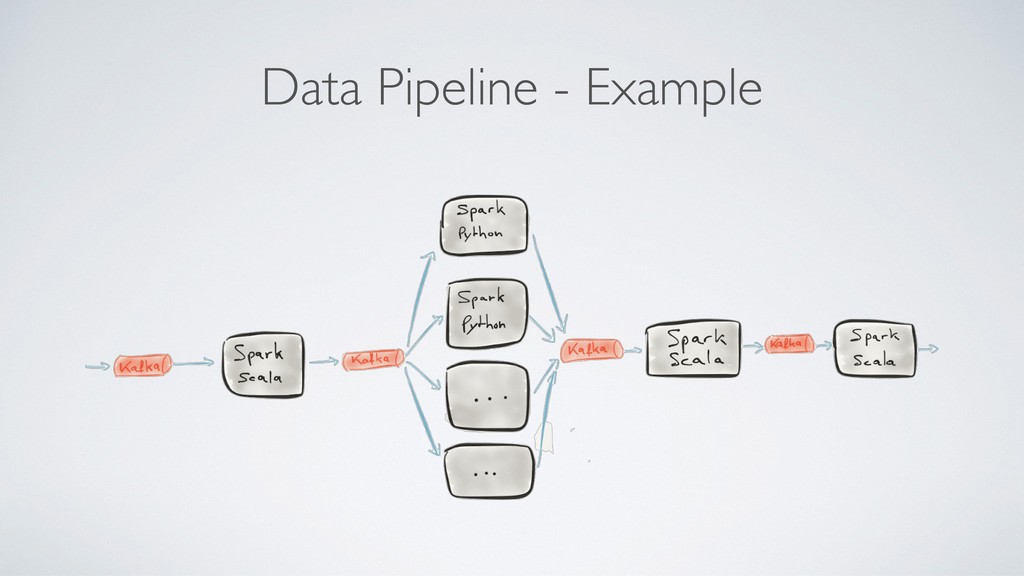
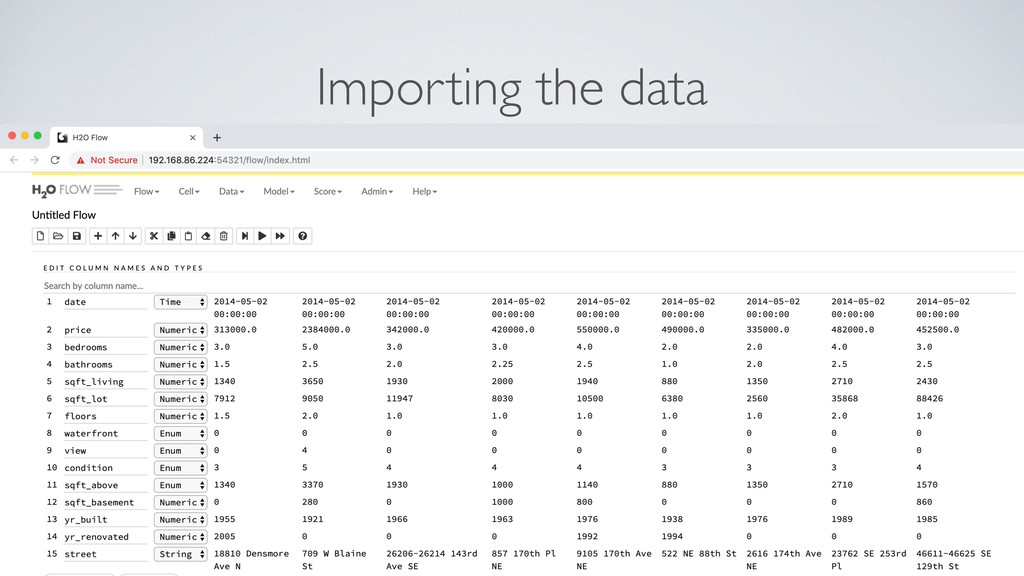
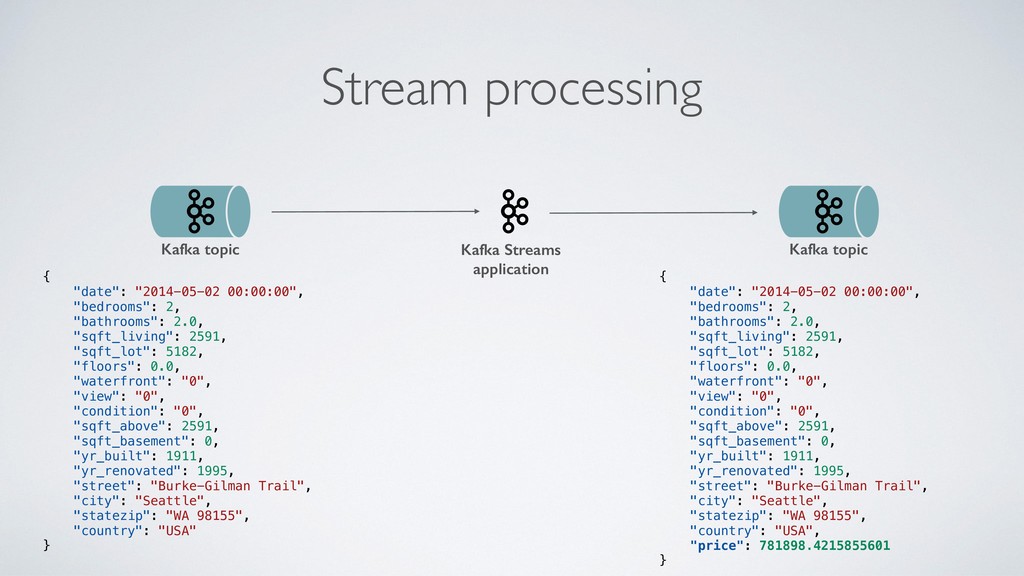
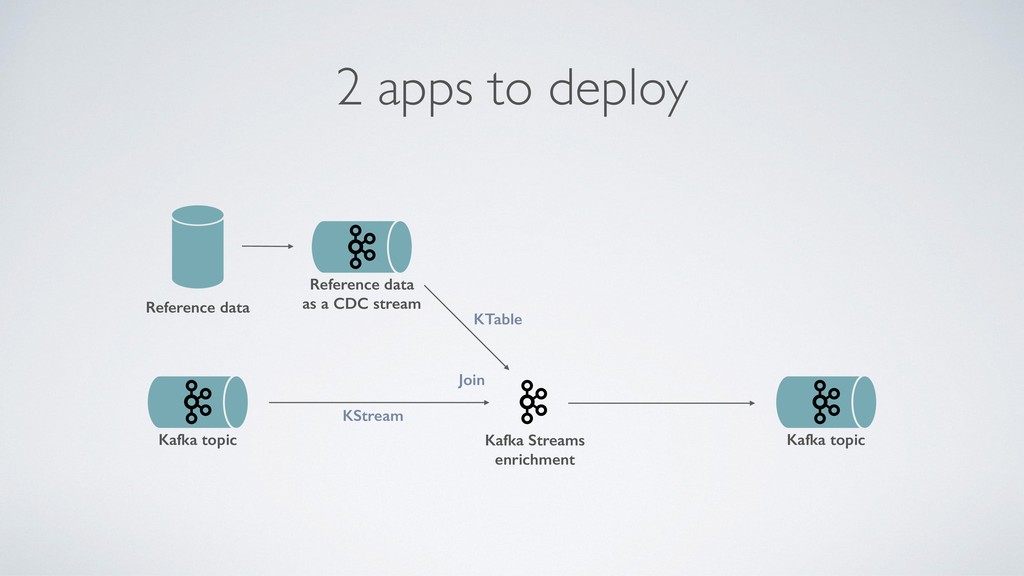
"sqft_lot": 5182, "floors": 0.0, "waterfront": "0", "view": "0", "condition": "0", "sqft_above": 2591, "sqft_basement": 0, "yr_built": 1911, "yr_renovated": 1995, "street": "Burke-Gilman Trail", "city": "Seattle", "statezip": "WA 98155", "country": "USA" } Stream processing { "date": "2014-05-02 00:00:00", "bedrooms": 2, "bathrooms": 2.0, "sqft_living": 2591, "sqft_lot": 5182, "floors": 0.0, "waterfront": "0", "view": "0", "condition": "0", "sqft_above": 2591, "sqft_basement": 0, "yr_built": 1911, "yr_renovated": 1995, "street": "Burke-Gilman Trail", "city": "Seattle", "statezip": "WA 98155", "country": "USA", "price": 781898.4215855601 } Kafka Streams application Kafka topic Kafka topic
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}