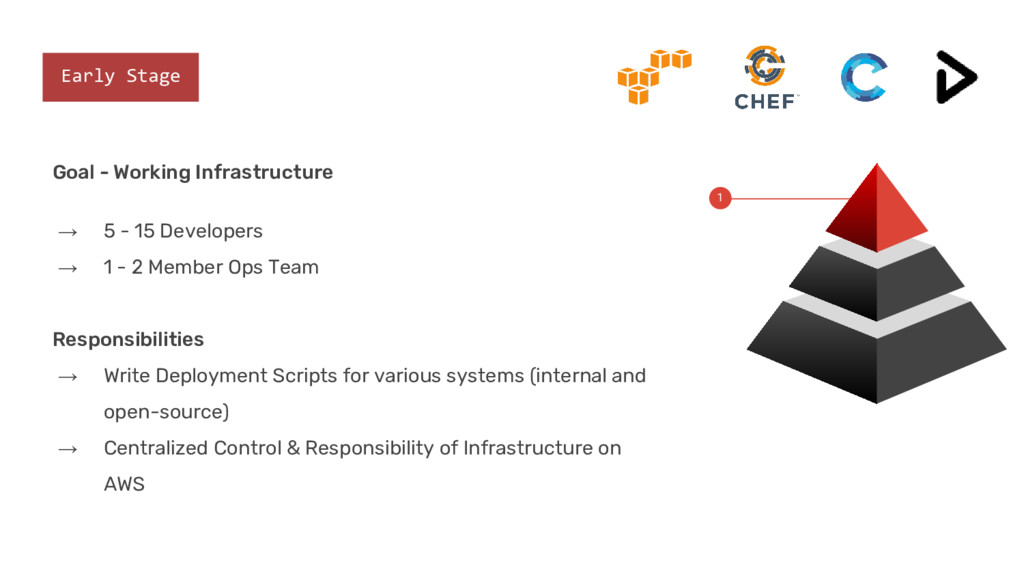
Developers → 1 - 2 Member Ops Team Responsibilities → Write Deployment Scripts for various systems (internal and open-source) → Centralized Control & Responsibility of Infrastructure on AWS 1
of new things on fast-growing Big-Data landscape but ops couldn’t handle all these requests ◦ Ops started working with Devs so they can take these experiments on their own ◦ Devs had a lot of say about the operational setup, scripts, etc.
- 30 Engineers → 2 - 3 Ops Engineers Responsibilities → Educate developers on their infrastructure → Work on the overall process (or framework) for operations 2
the middle of the night, automation is the likely outcome. If operations is frequently called, the usual reaction is to grow the operations team.” From: On designing and deploying internet-scale services ~ James Hamilton - LISA ’07 2
contribute for operations - oss.indix.com → (+) Individual teams took over their infra & on-call resulting in faster & better systems → (-) With decentralised operations, cost control is very hard, but super important → (-) Backup is important if we have to provide CRUD access to everybody
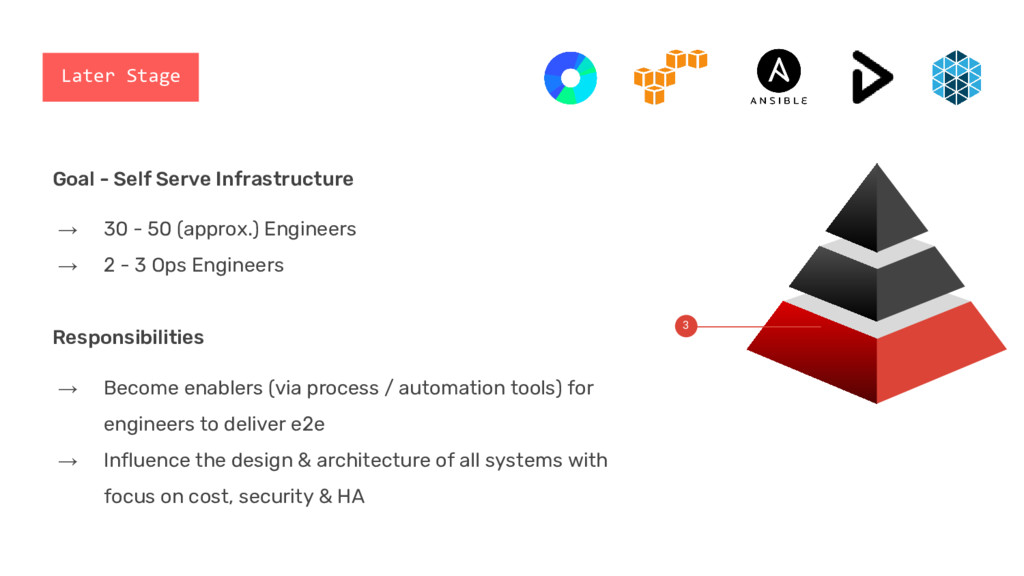
- 50 (approx.) Engineers → 2 - 3 Ops Engineers Responsibilities → Become enablers (via process / automation tools) for engineers to deliver e2e → Influence the design & architecture of all systems with focus on cost, security & HA
provide a unified view of all underlying resources → (+) Operations is a first-class skill for Devs and “Development” is for Ops → (+) Operability Review before the first prod push helped reduce lots of surprises → (-) De-centralised infra access lead to lot of fragmentation in the deployment stack
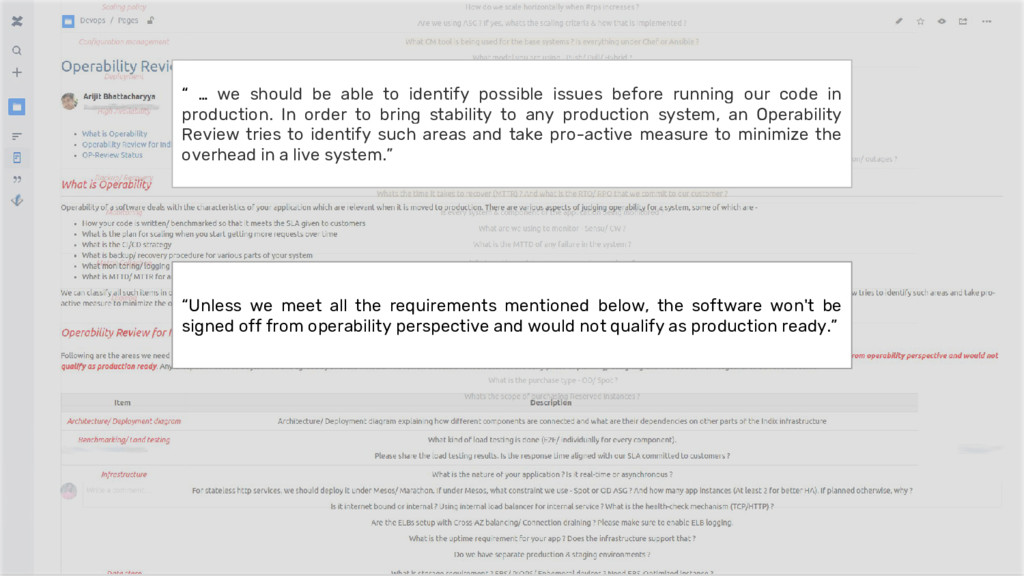
won't be signed off from operability perspective and would not qualify as production ready.” “ … we should be able to identify possible issues before running our code in production. In order to bring stability to any production system, an Operability Review tries to identify such areas and take pro-active measure to minimize the overhead in a live system.”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}