of the night, automation is the likely outcome. If operations is frequently called, the usual reaction is to grow the operations team.” On designing and deploying internet-scale services - James Hamilton - LISA ’07 dev+ops culture @indix
configuration management c. deployment (incl. releases and testing at various environments) d. on-call roster and weekly rotation for all the systems they inherit and build.
tolerant” b. AWS cost c. processes like Ops-Review for each system before hitting production d. common infrastructure like configuration management, logging, metric collection, alerting etc. That’s 3 folks responsible for the work across 50+ developers in ops. dev+ops culture @indix
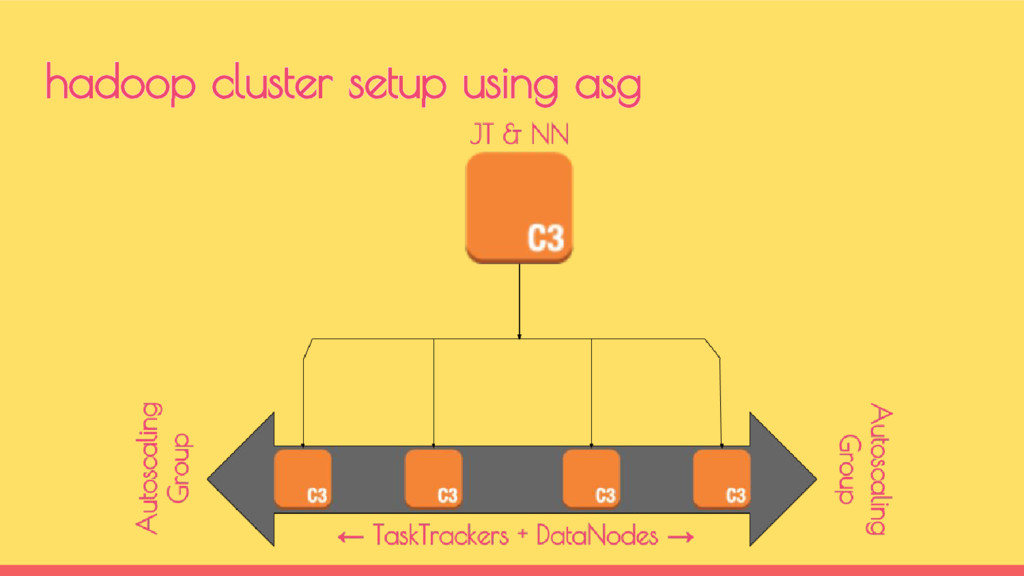
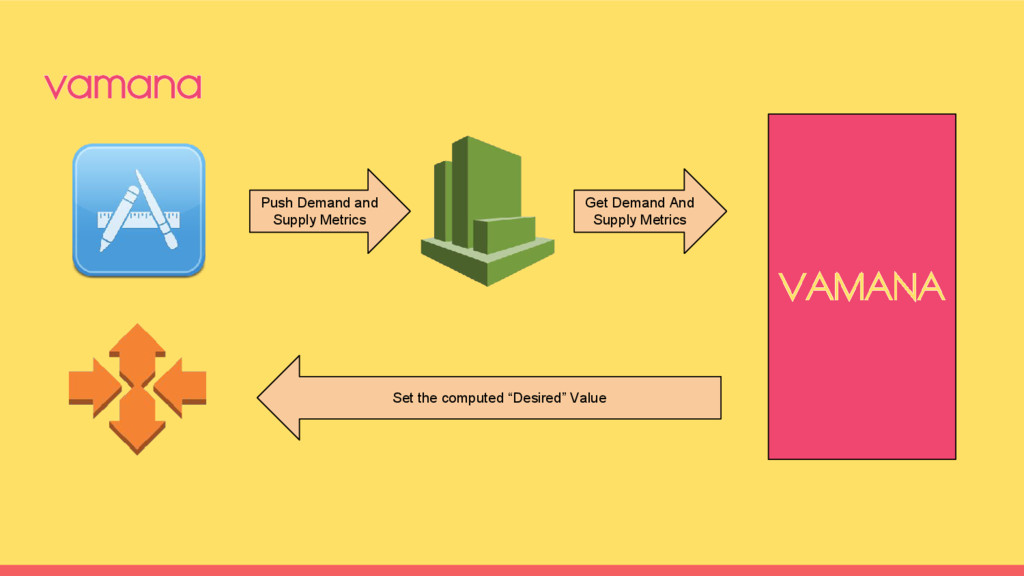
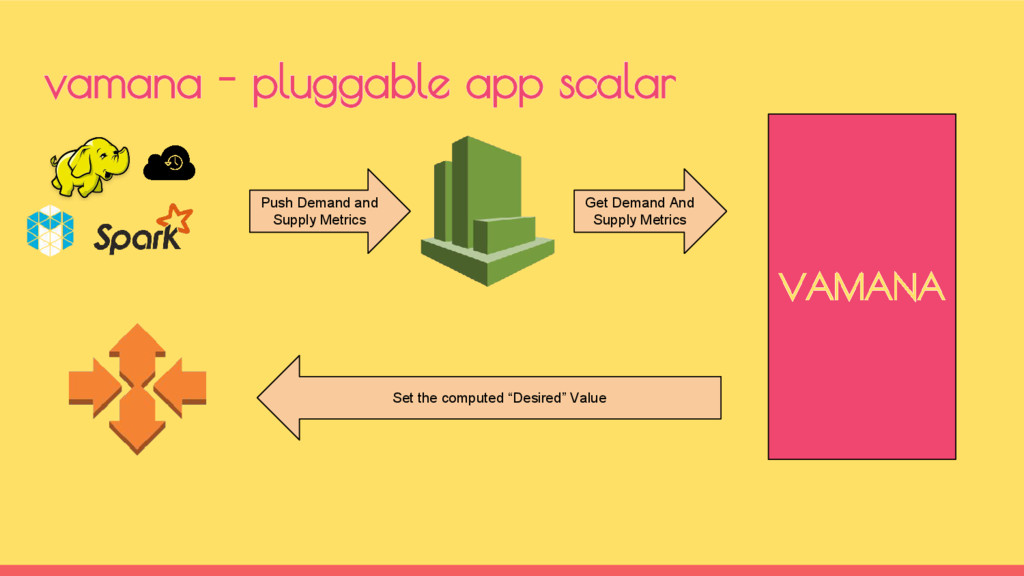
teams coming together to solve some of common problems of both. Dev Problem - Automatic scaling for apps to meet certain SLA Ops Problem - Keeping the cost under control when systems scale dev+ops culture @indix
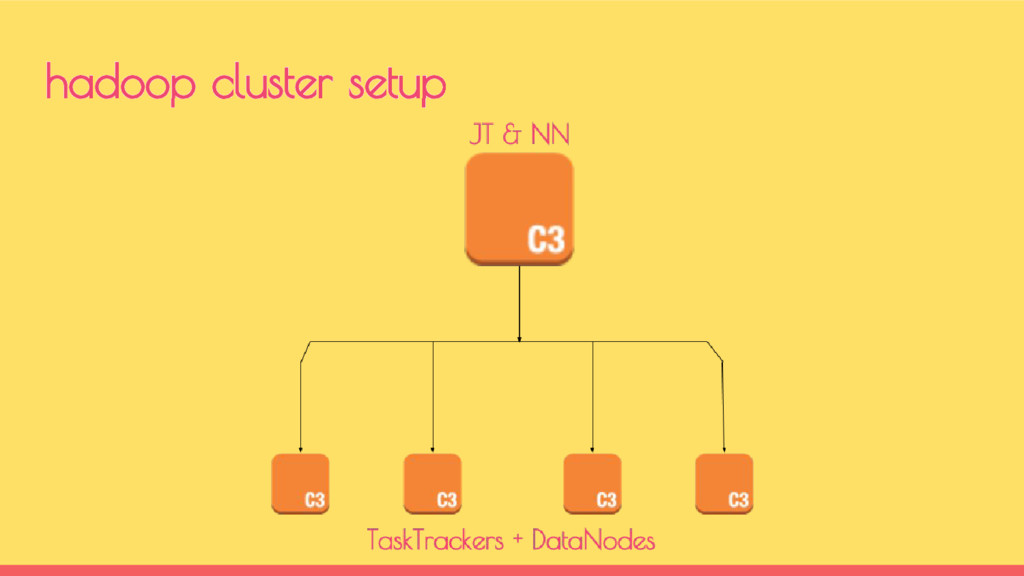
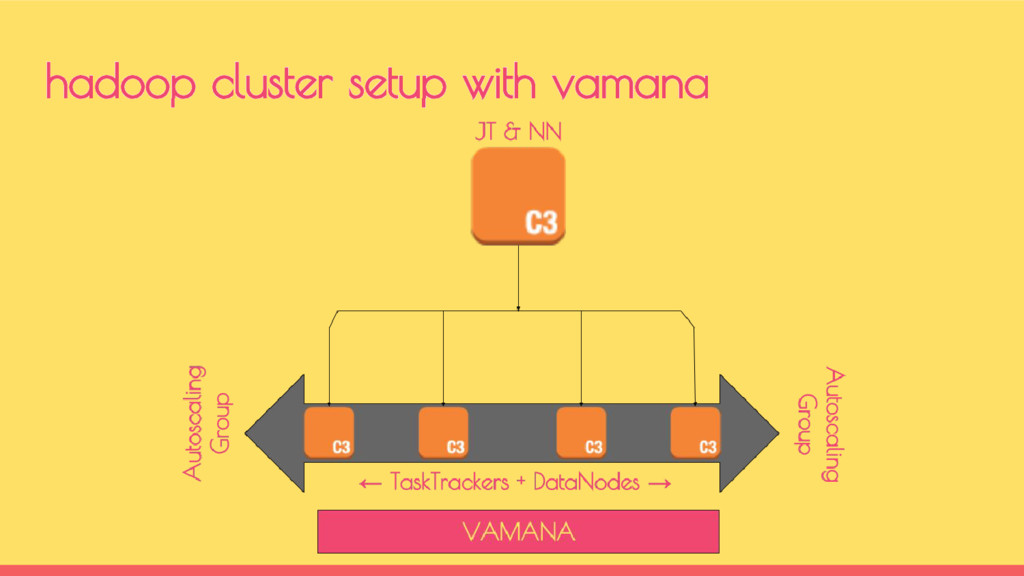
clusters Each of them have their own usage pattern A Staging cluster has only workloads for 3-4 hours a day Production cluster has workloads 24x7 - running 100s of jobs hadoop @indix
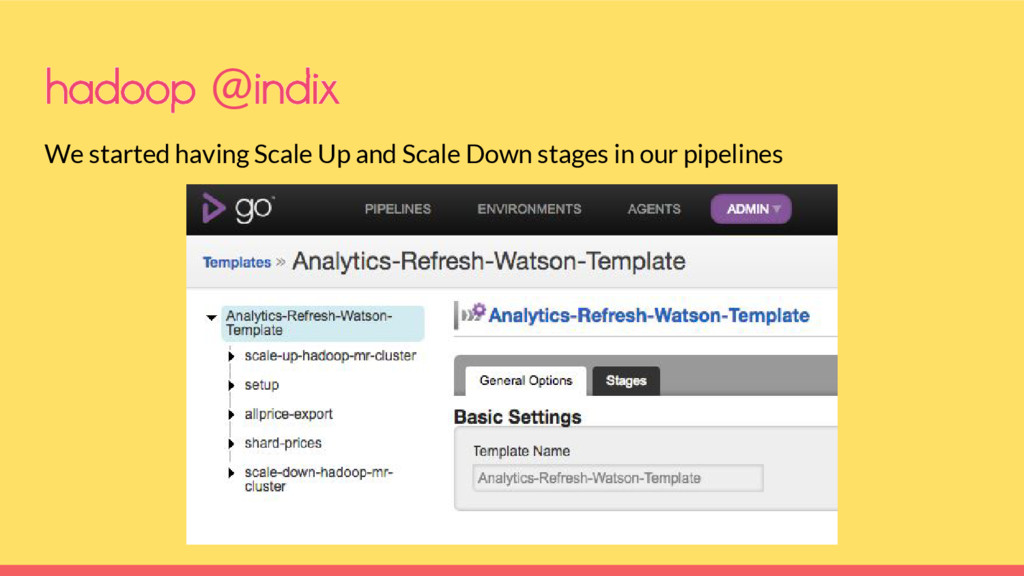
completion and the cluster will not scale down Every new pipeline created had to have a scale up and scale down stage More than 1 pipeline started sharing the cluster hadoop @indix
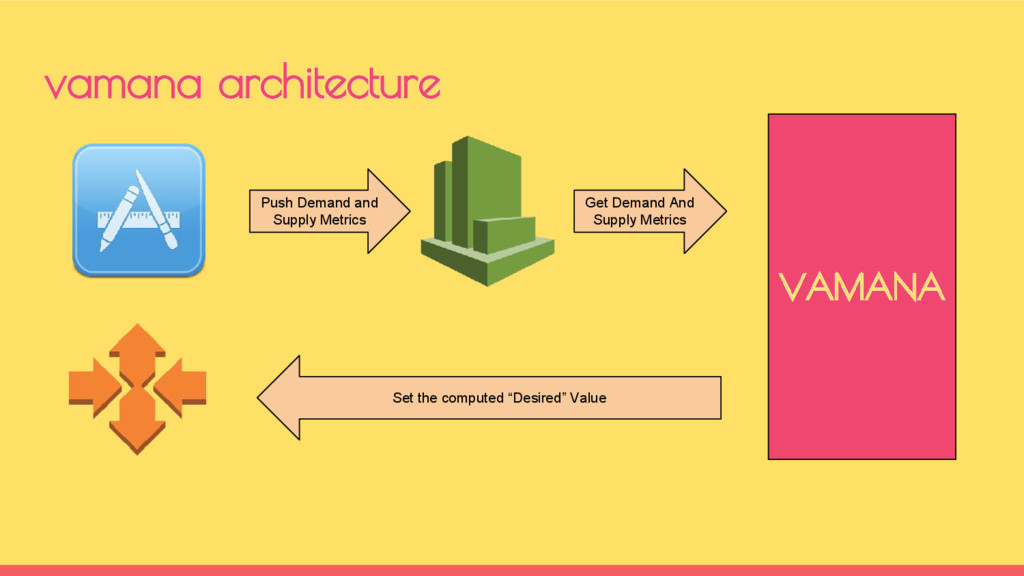
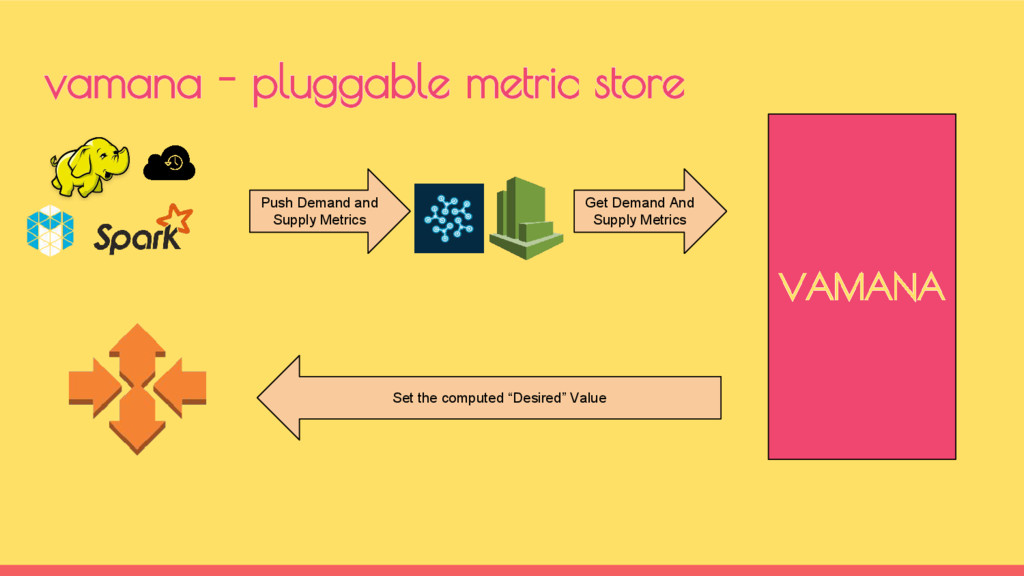
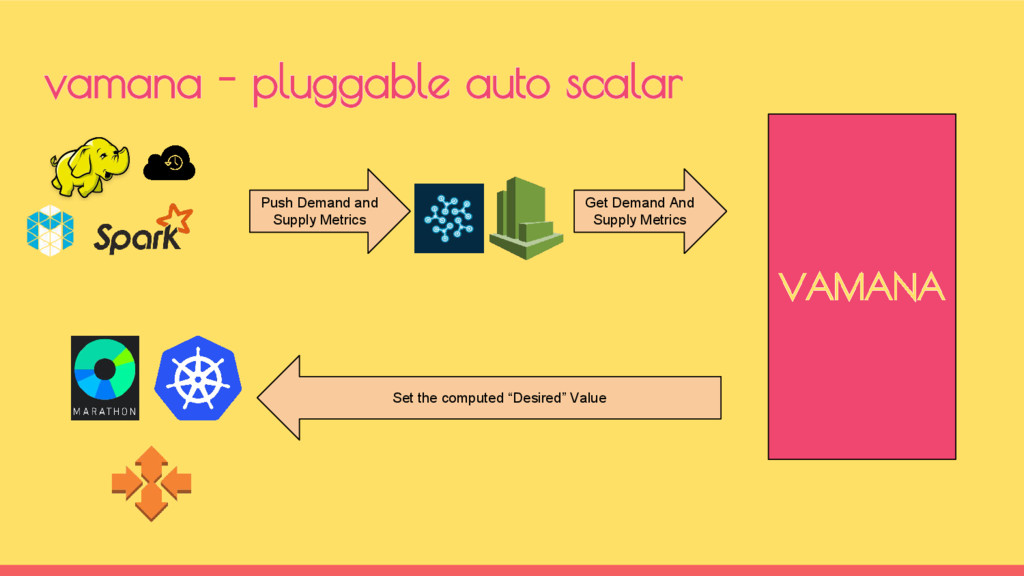
◦ map_supply ◦ reduce_supply • Demand metrics are collected as cumulative sum of map & reduce tasks of all Running jobs ◦ map_demand ◦ reduce_demand demand vs supply metrics for hadoop
Until we saw our AWS bill was gradually increasing - esp. under “Data Transfer” Because HDFS write pipeline is not very AWS-Cross-AZ-Data-Transfer-Cost aware
Until we saw our AWS bill was gradually increasing - esp. under “Data Transfer” Because HDFS write pipeline is not very AWS-Cross-AZ-Data-Transfer-Cost aware problem 3 - data transfer cost
/ YARN) running 24x7 You need to save cost by running Spot instances Handle surge pricing for spot by switching AZs Ability to fallback to On Demand if needed to meet certain SLA Switch back to Spot once the surge ends learnings so far
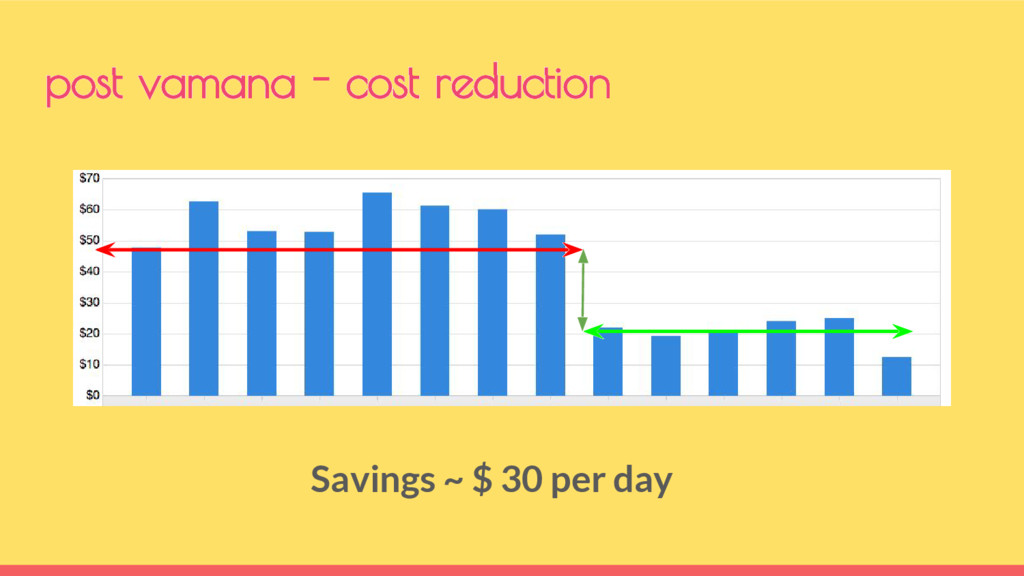
now Along with Vamana, enabled us to achieve • ~40% reduction in monthly AWS bill • ~50% of AWS Infrastructure is on Spot • 100% of Hadoop MR workloads are on Spot
using shiny tools Think Autoscale as first class functional feature across all systems Use Spot on AWS - Save costs - but be cognizant of when, where and hows take aways Questions? github.com/indix/matsya || github.com/indix/vamana
instances Spot Prices are highly volatile But, highly cost effective if used right Spot’s “Demand vs Supply” is local to it’s Spot Market aws spot primer
the following dimensions • # of Instance Types, Availability Zones and Regions The number of spot markets is a cartesian product of all the above numbers. Example - Requirement for 36 CPUs per instance • Instance Types - [d2.8xlarge, c4.8xlarge] • AZs - [us-east-1a, us-east-1b, us-east-1c, …] • Region - [us-east, us-west, …] - 10 regions • Total in US-EAST (alone) => 2 * 5 = 10 spot markets aws spot markets
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}