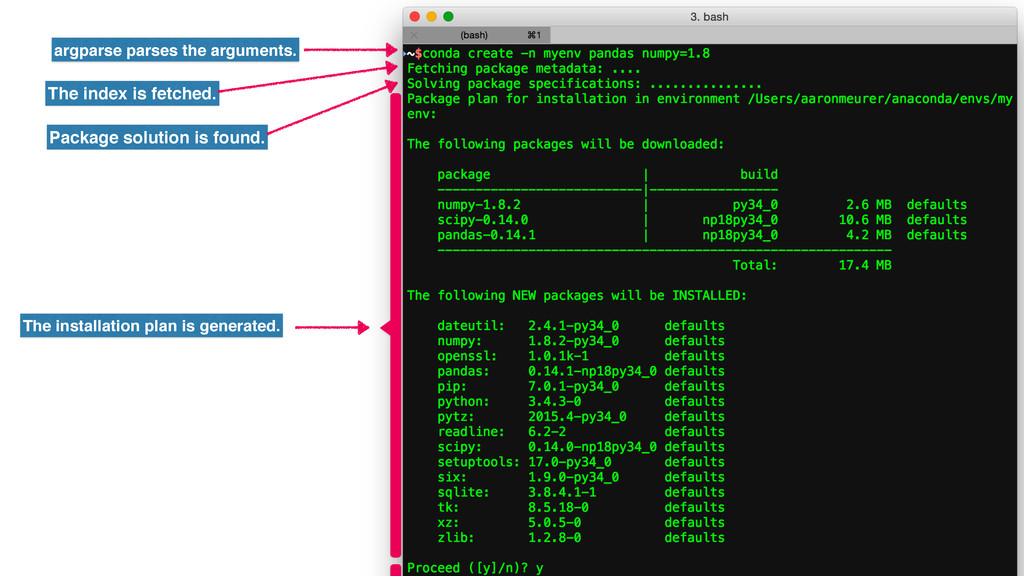
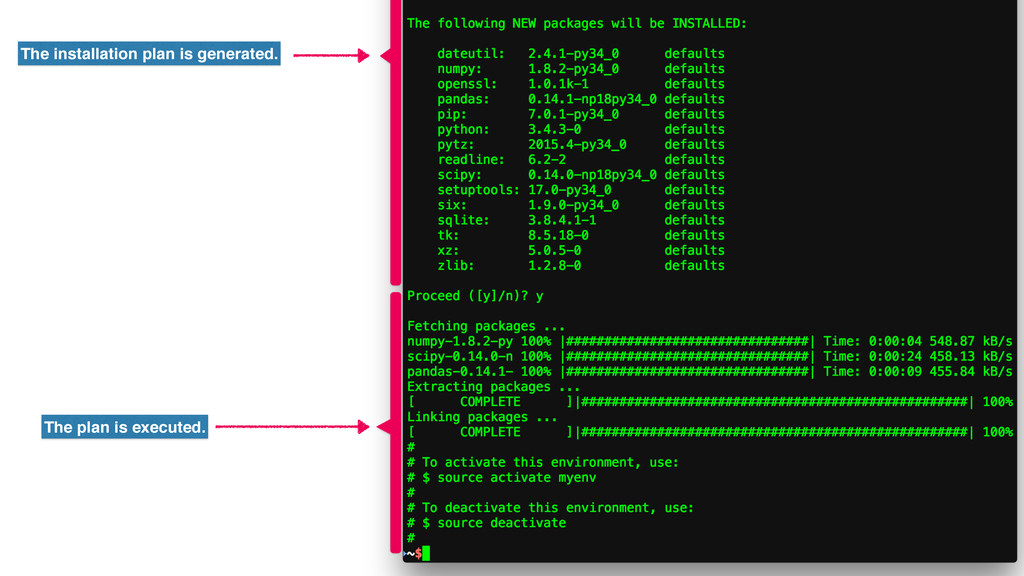
my example. [('PREFIX', '/Users/aaronmeurer/anaconda/envs/myenv'), ('PRINT', 'Fetching packages ...'), ('FETCH', 'numpy-1.8.2-py34_0'), ('FETCH', 'wheel-0.26.0-py34_0'), ('FETCH', 'scipy-0.14.0-np18py34_0'), ('FETCH', 'pandas-0.14.1-np18py34_0'), ('PRINT', 'Extracting packages ...'), ('PROGRESS', '4'), ('EXTRACT', 'numpy-1.8.2-py34_0'), ('EXTRACT', 'wheel-0.26.0-py34_0'), ('EXTRACT', 'scipy-0.14.0-np18py34_0'), ('EXTRACT', 'pandas-0.14.1-np18py34_0'), ('PRINT', 'Linking packages ...'), ('PROGRESS', '17'), ('LINK', 'ncurses-5.9-1 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'openssl-1.0.1k-1 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'sqlite-3.8.4.1-1 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'tk-8.5.18-0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'xz-5.0.5-0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'zlib-1.2.8-1 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'readline-6.2.5-1 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'python-3.4.3-0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'numpy-1.8.2-py34_0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'pytz-2015.6-py34_0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'setuptools-18.1-py34_0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'six-1.9.0-py34_0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'wheel-0.26.0-py34_0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'dateutil-2.4.1-py34_0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'pip-7.1.2-py34_0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'scipy-0.14.0-np18py34_0 /Users/aaronmeurer/anaconda/pkgs 1'), ('LINK', 'pandas-0.14.1-np18py34_0 /Users/aaronmeurer/anaconda/pkgs 1'), ('SYMLINK_CONDA', '/Users/aaronmeurer/anaconda')]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}