As web developers, our job is to build nice, fast, and reliable websites, web apps, or web services. But our role isn't limited to this. We have to build these products not only for our ideal users but for a range of people as wide as possible. Today's browsers help us in achieving this goal providing APIs created with this scope in mind. One of these APIs is the Web Speech API that provides speech input and text-to-speech output features in a web browser.
In this talk you'll learn what the Web Speech API is and how it can drastically improve the way users, especially those with disabilities, perform tasks in your web pages.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
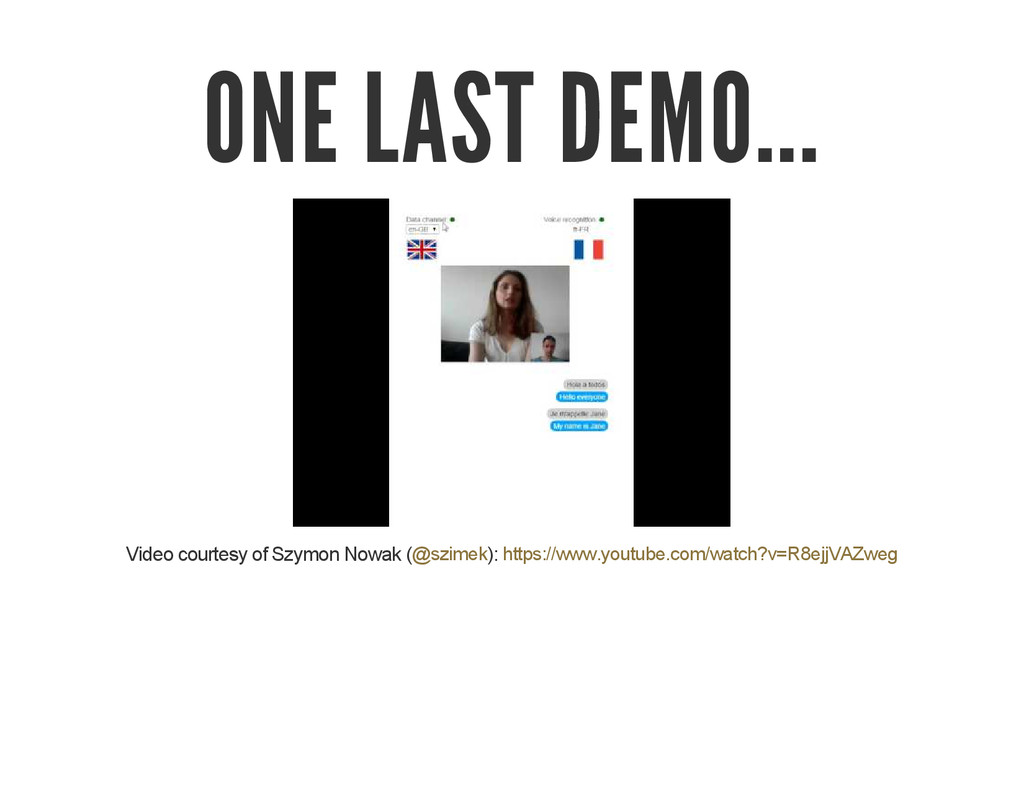{kind=link}
{kind=link}
{kind=link}
![CONTACTS Website: Email: Twitter: www.audero.it [email protected] @AurelioDeRosa](https://files.speakerdeck.com/presentations/3338a46a7dce4993b174a5f62573c9d6/slide_58.jpg){kind=link}