A cache can be easily understood as a saved answer to a question. Caching can speed up an application if a computationally complex question is asked frequently. Instead of the computing the answer over and over, we can use the previously cached answer.
Caching is an important component while scaling applications which are to be used by many users. It solves various problems related to cost and latency. Usually it takes more time to retrieve data from DB rather than cache. Using a cache to avoid recomputing data or accessing a slow database provides us with a great performance boost.
I will describe in depth the different methods of Caching, their pros and cons. This talk will help developers focus on their code before scaling their applications. It will provide immense performance improvements with this simple concept.
Outcomes: The novice audience will be able to understand basic Caching Mechanisms. They will be able to utilize their knowledge which will serve pivotal while scaling applications
{kind=link}
{kind=link}
{kind=link}
{kind=link}
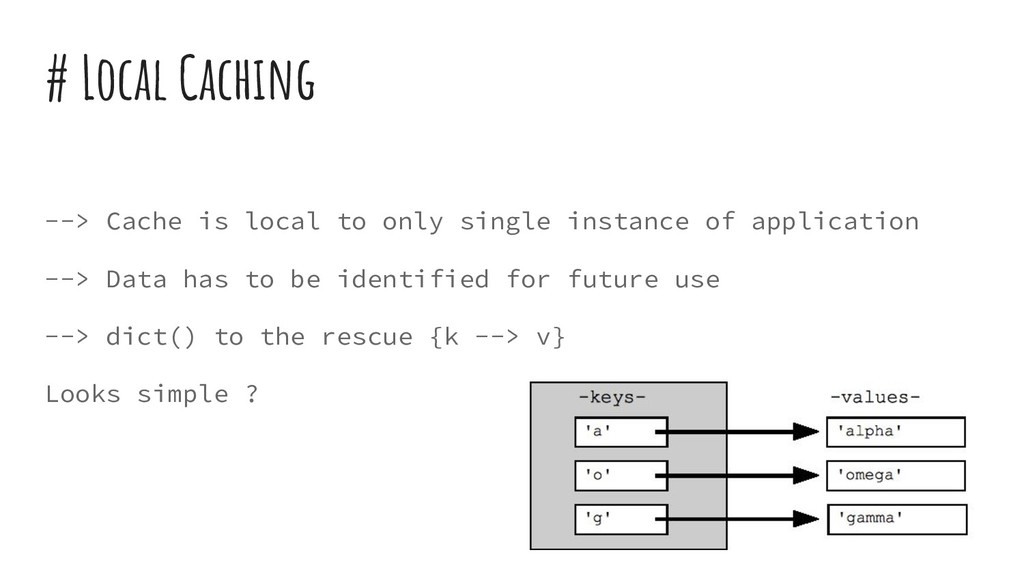{kind=link}
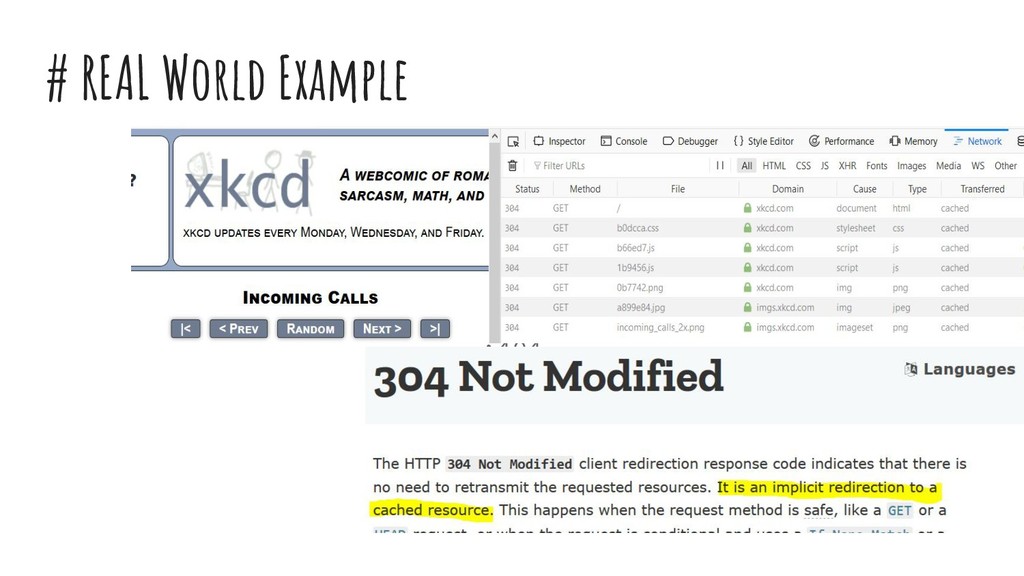{kind=link}
{kind=link}
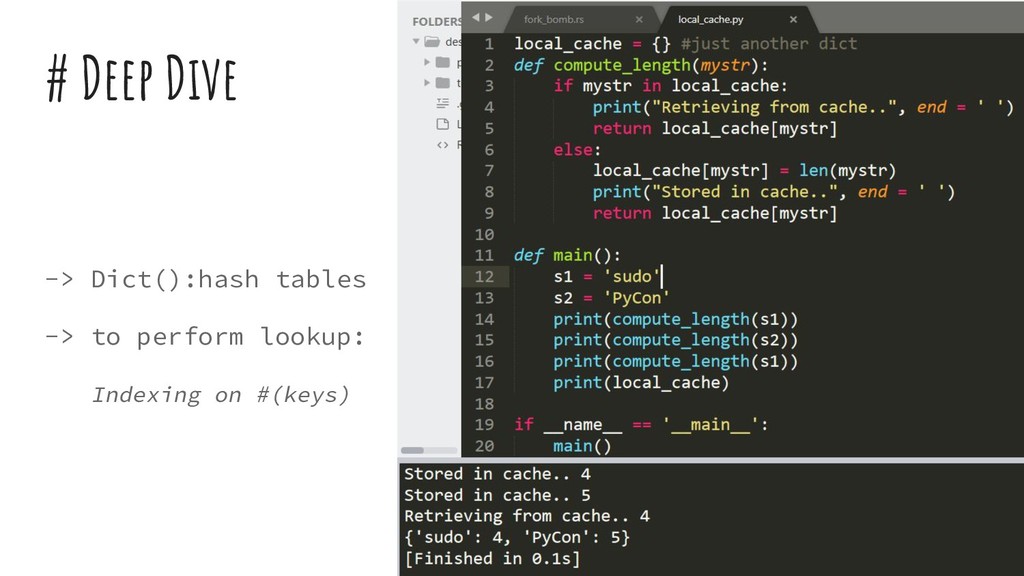{kind=link}
{kind=link}
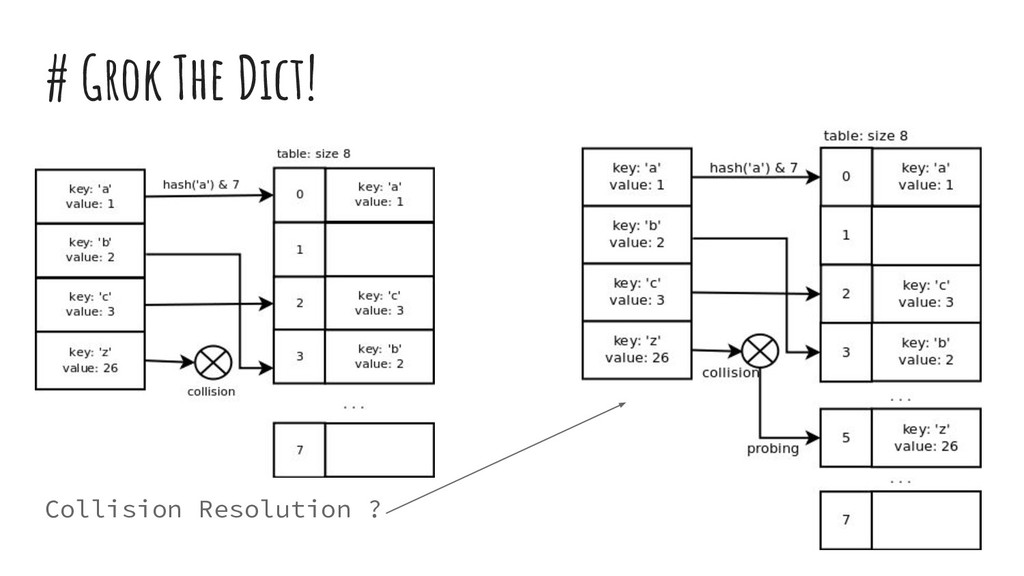{kind=link}
{kind=link}
{kind=link}
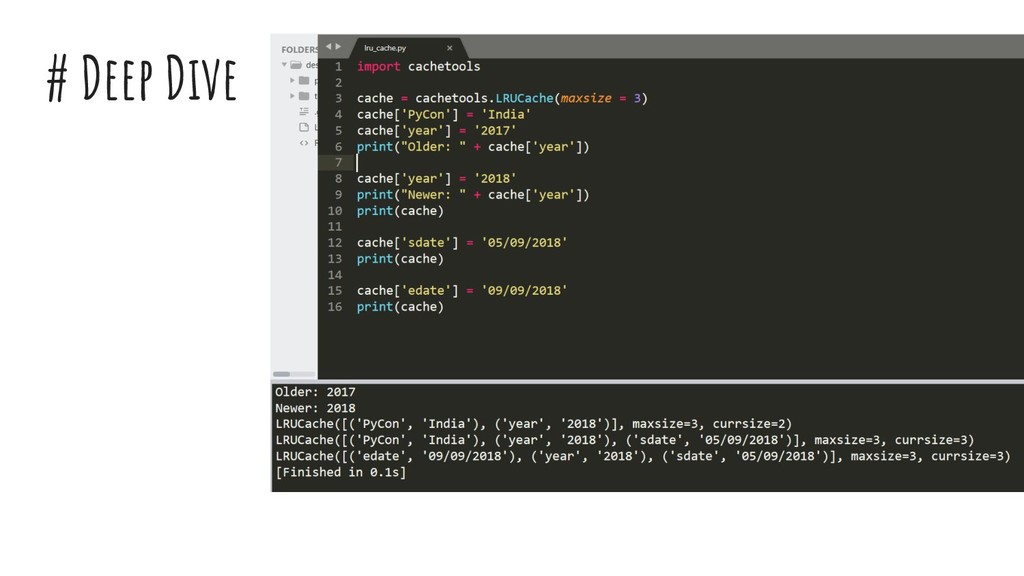{kind=link}
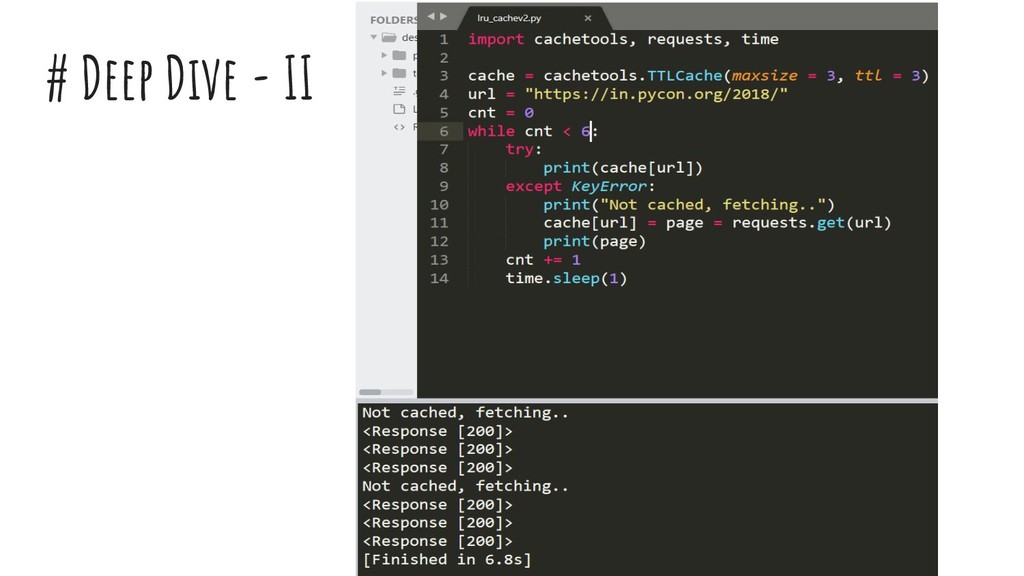{kind=link}
{kind=link}
{kind=link}
{kind=link}
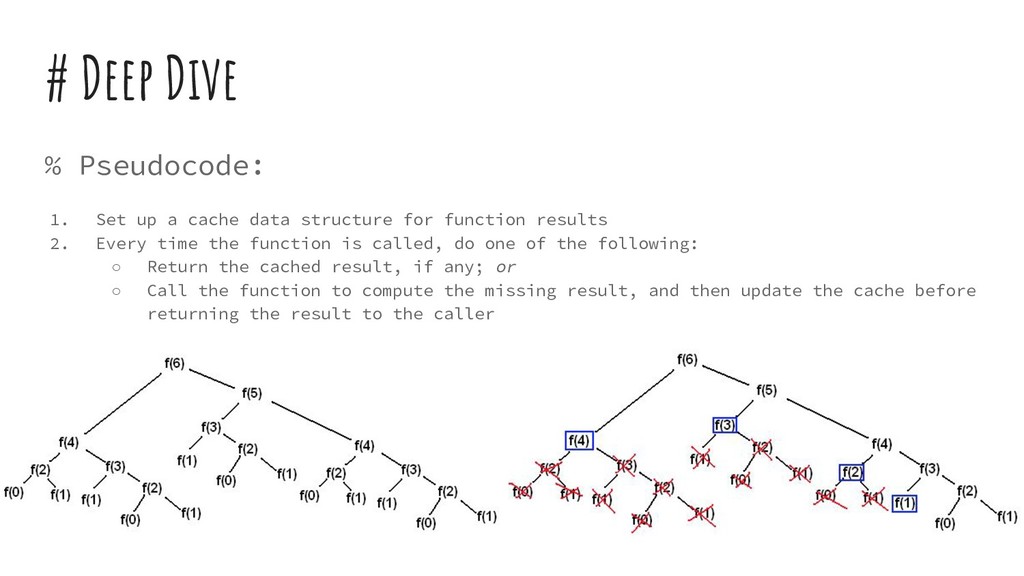{kind=link}
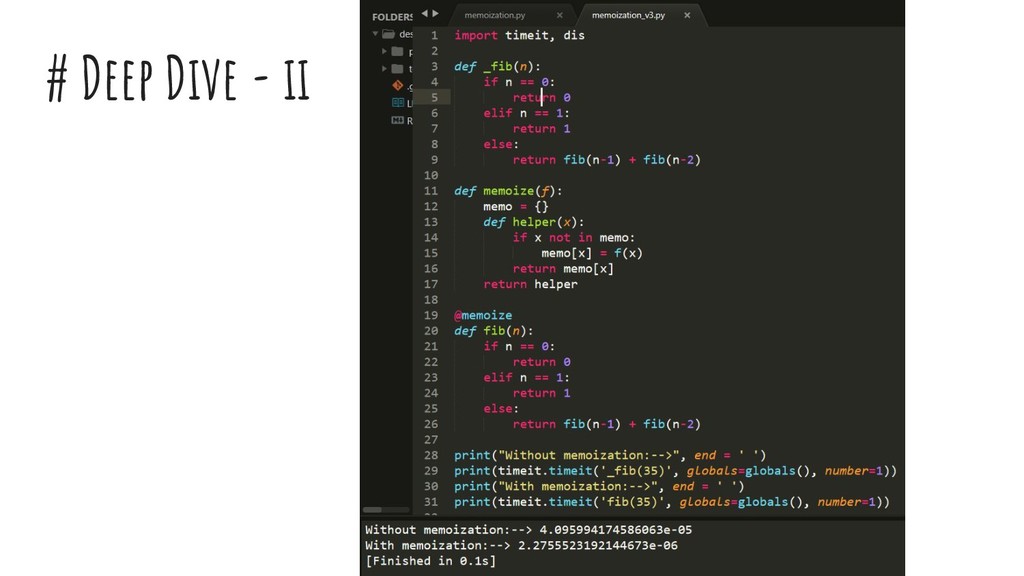{kind=link}
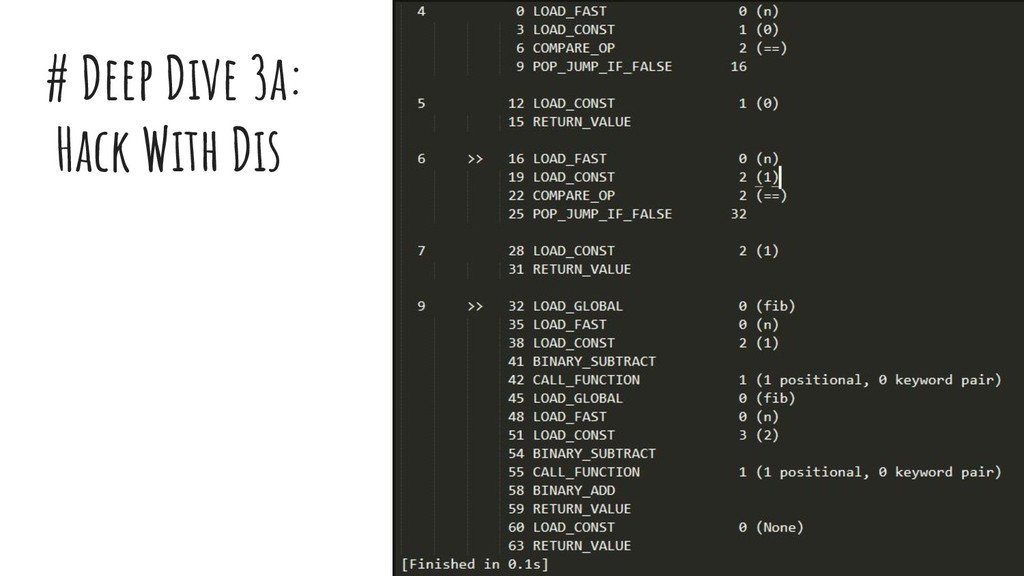{kind=link}
{kind=link}
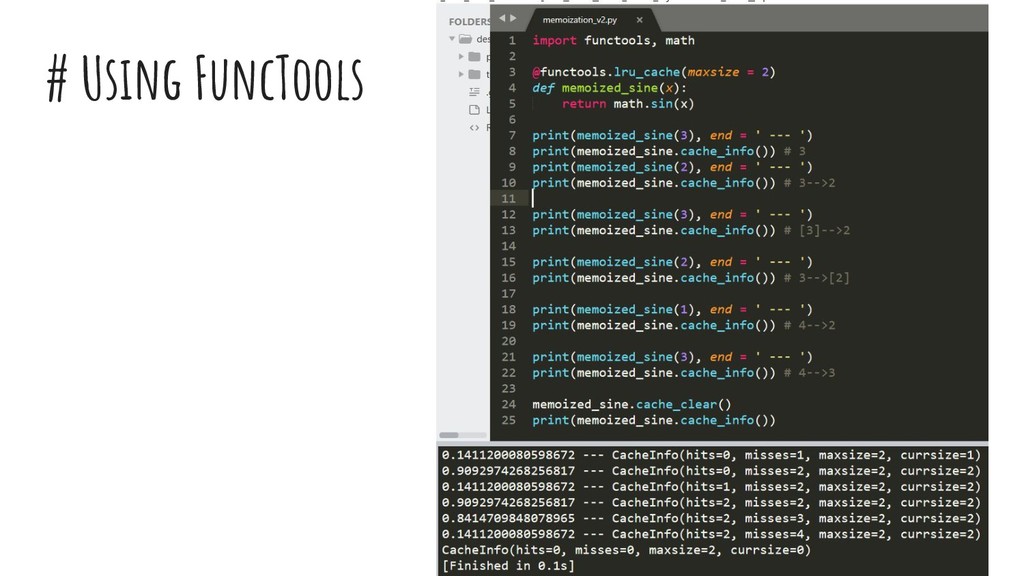{kind=link}
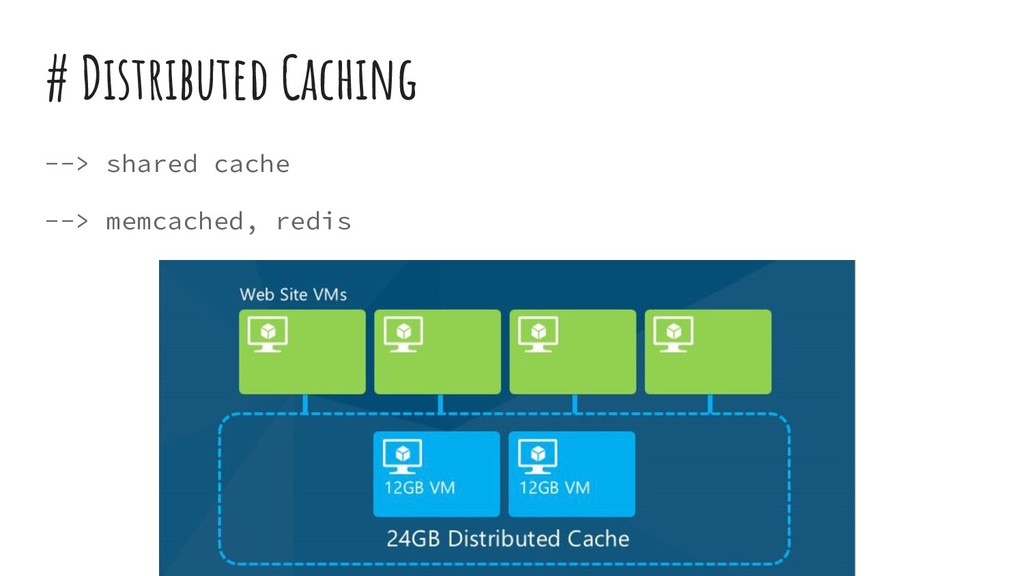{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}