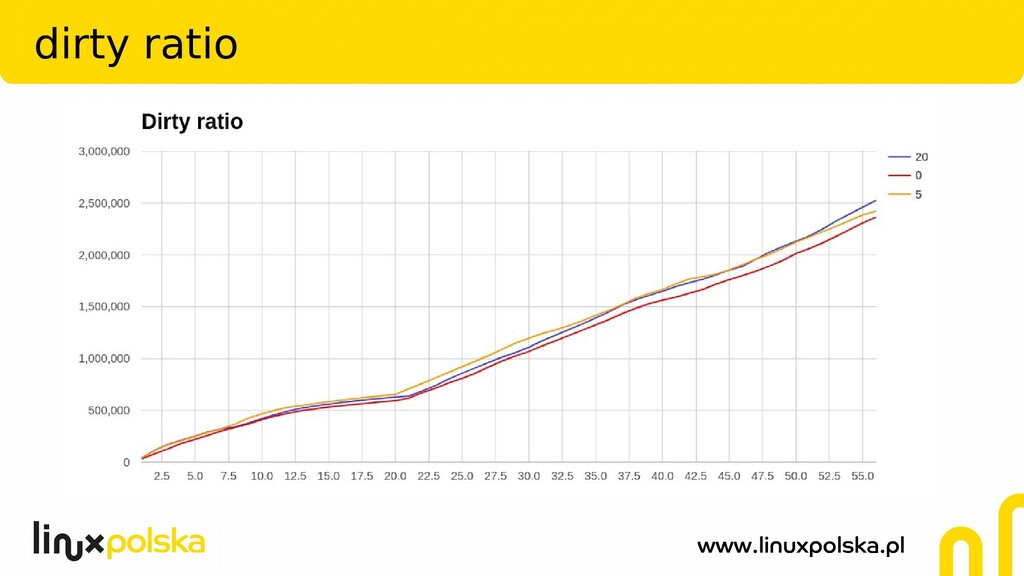
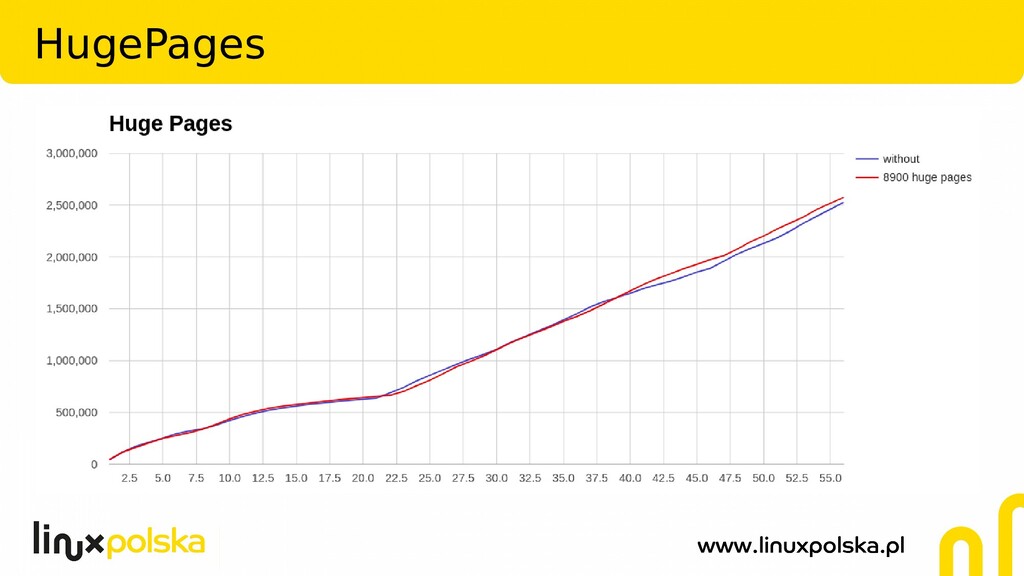
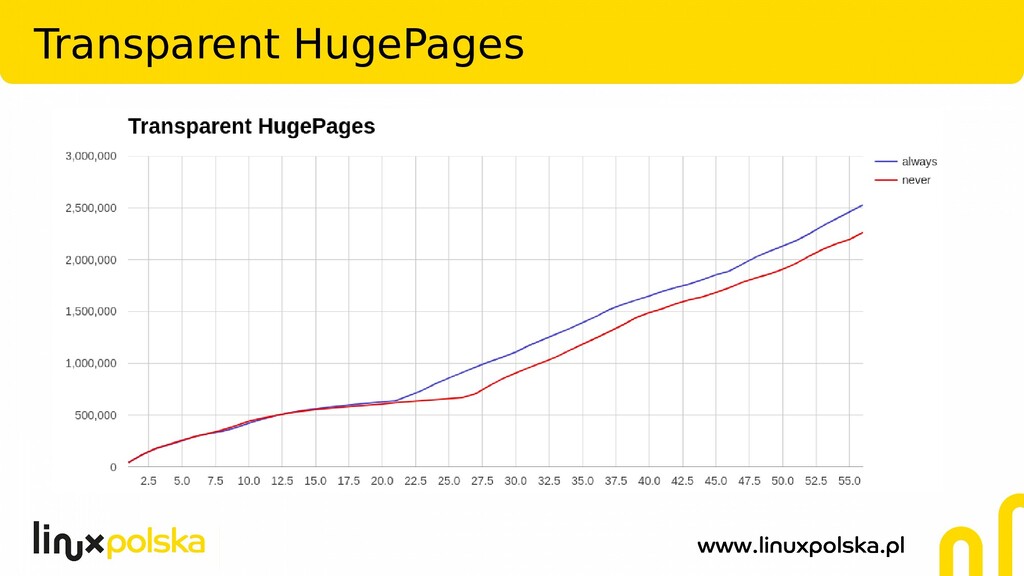
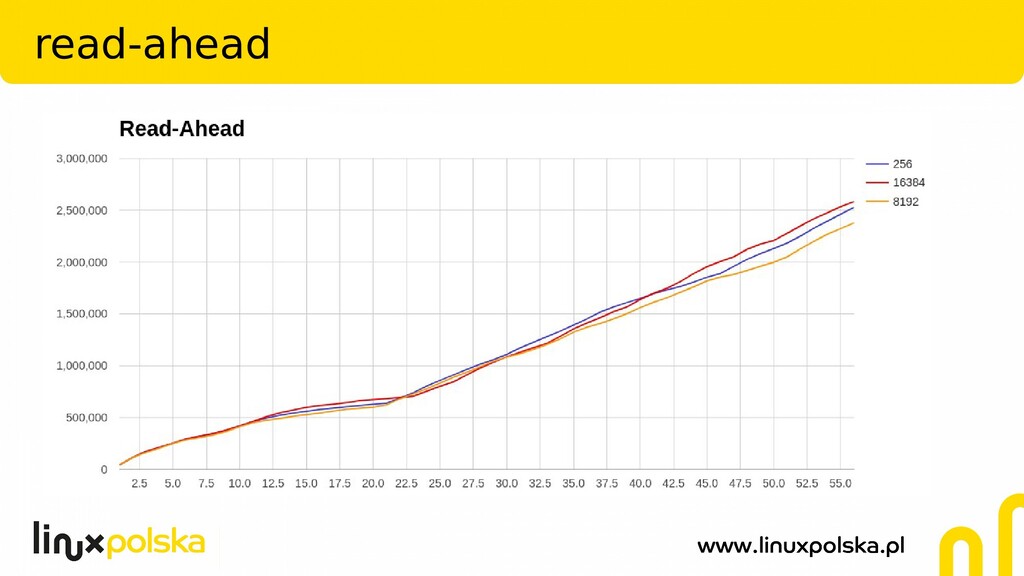
The file systems offer a lot of tunables. PostgreSQL relies heavily on the operating system and file systems is running on. But what's the exact impact of those parameters on a real production database? In my presentation I'll show the test results done for one of our customer's using many terabytes Zabbix system with PostgreSQL as a backend. The following tunables (among others) were checked:
file system block size
write barriers
journaling modes
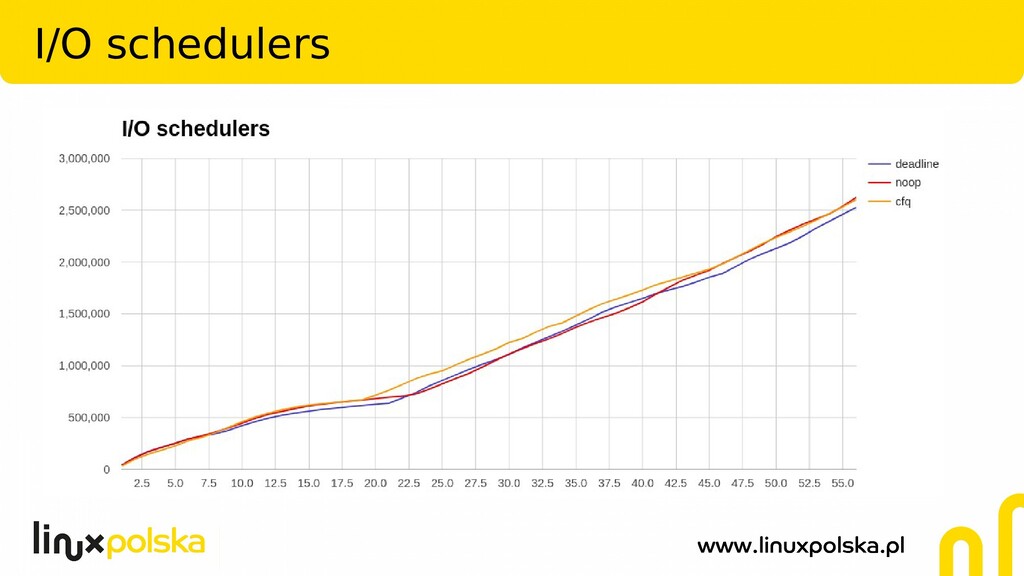
IO Schedulers
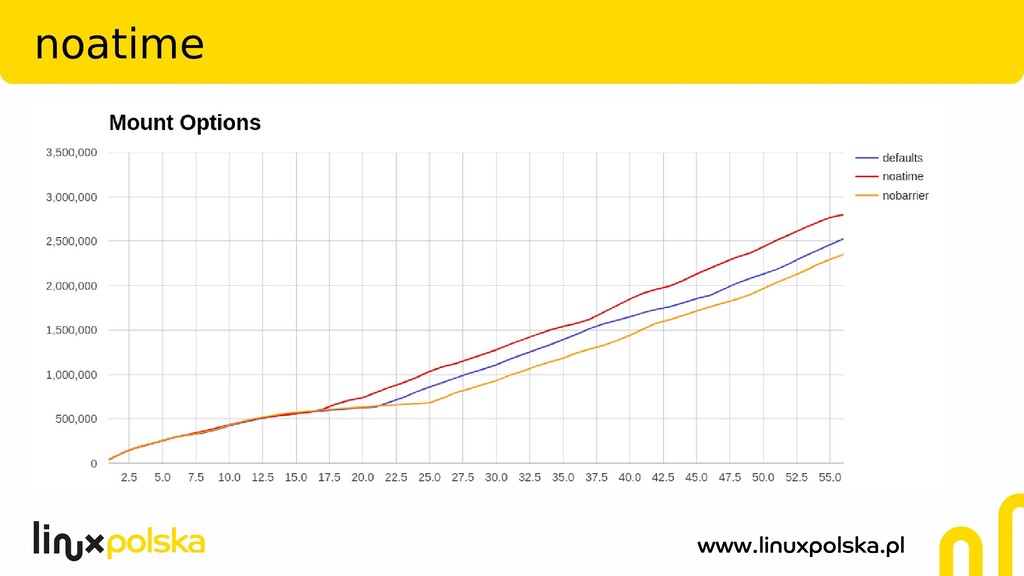
access time
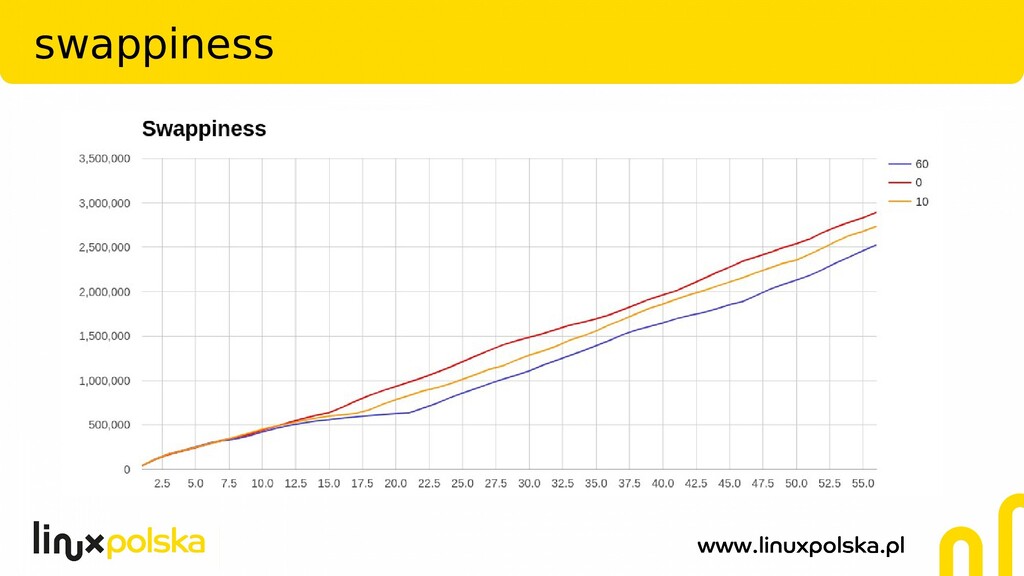
read-ahead
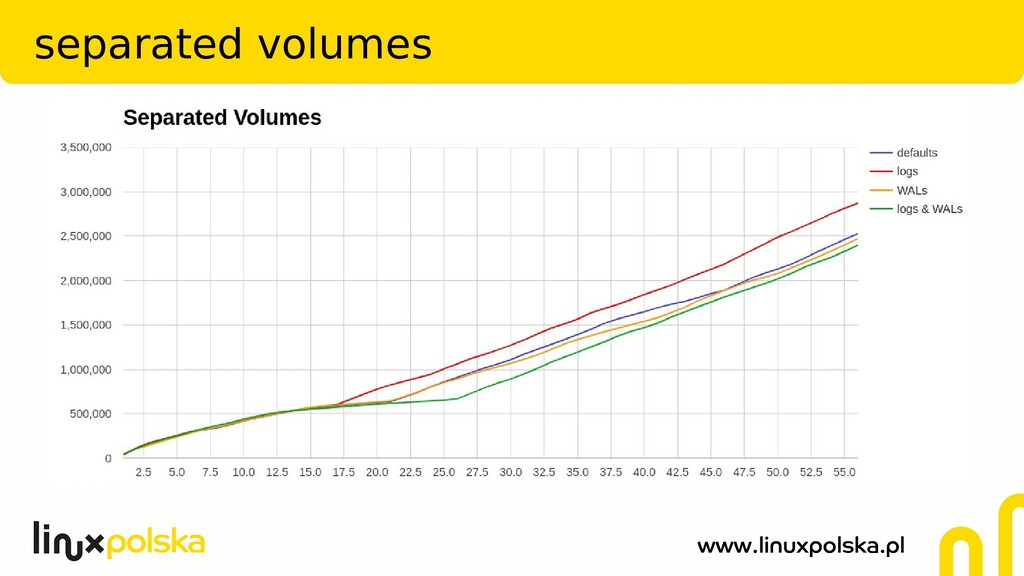
disk layouts
Two of the most widely used file systems: ext4 and xfs were investigated. Tests were conducted on 4 socket, 128GB RAM HP ProLiant DL580 G7 server, using pgreplay against Zabbix PostgreSQL 10 database.
Presented in Lisbon on PGCONF.EU 2018
https://www.postgresql.eu/events/pgconfeu2018/schedule/session/2125-file-system-and-virtual-memory-tuning-for-a-zabbix-database/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Alicja Kucharczyk Thank You! Senior Solution Architect [email protected] +48 888](https://files.speakerdeck.com/presentations/5712b979f6384a7bac8ebed50943c589/slide_56.jpg){kind=link}