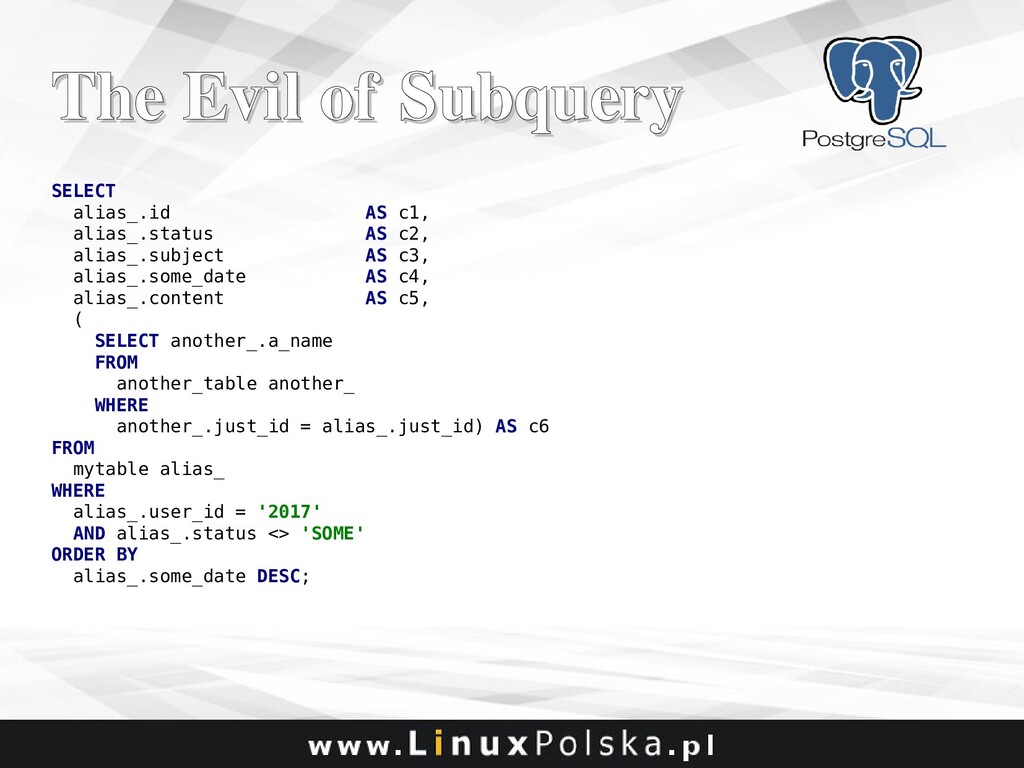
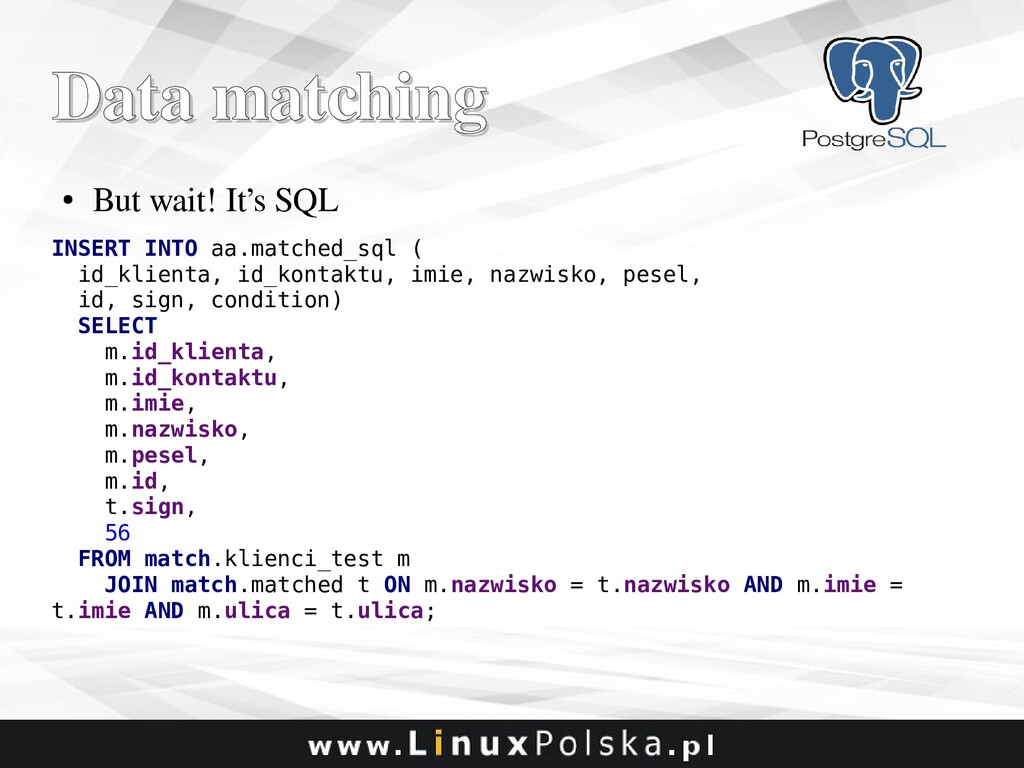
Bad SQL is one of the most common performance issues. The use of ORM frameworks and treating a database as a data store only leads to slow queries which slow down the whole system. I’ll discuss some basic techniques every developer should be aware of, along with some examples from production systems of query tuning using different approaches from modifications of joins and subqueries to adjusting the planer cost settings and other parameters that affect the way a query is executed. Besides, I’ll present some techniques to benchmark a query performance in a reliable and automated manner.
Presented on PGCONF.EU 2017 in Warsaw
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
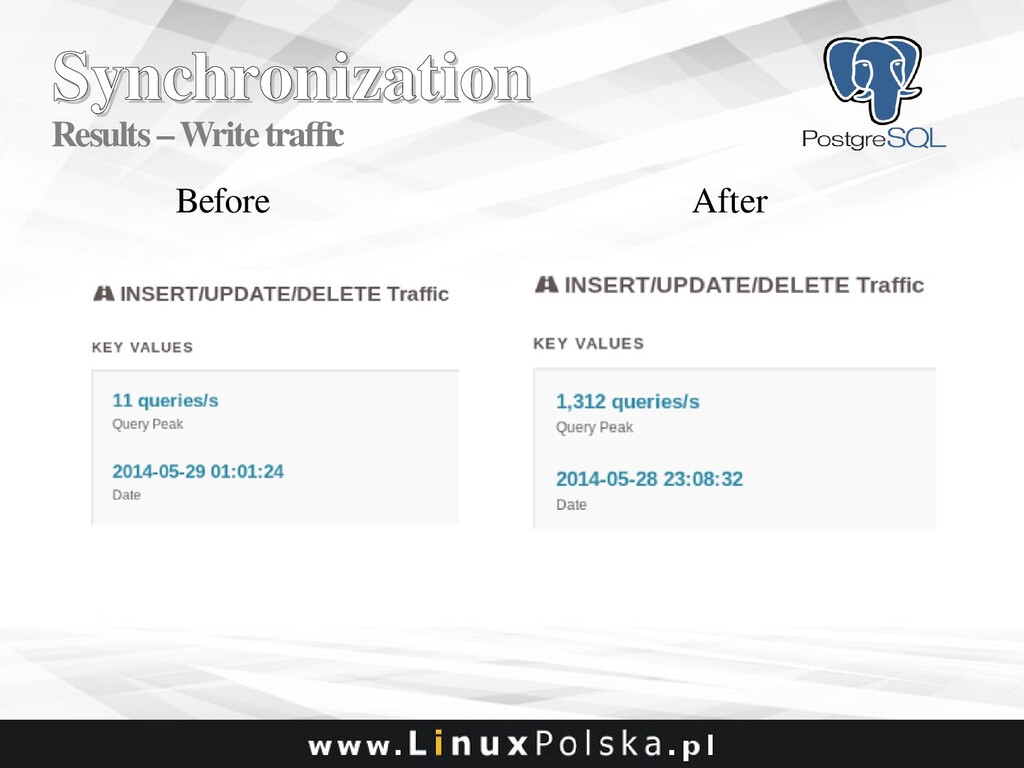
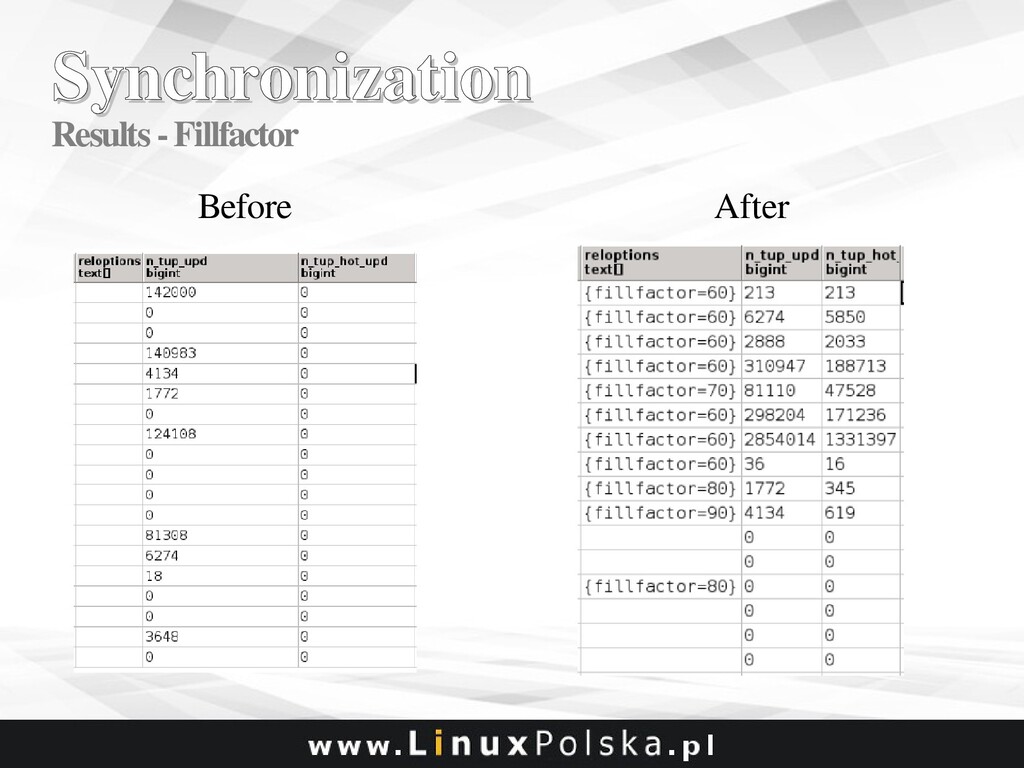
![Synchronization Synchronization Starting Point Around 20 get_xml_[type] functions with FOR](https://files.speakerdeck.com/presentations/a97b38dd7247420cb17ed6c7ac1deabe/slide_39.jpg){kind=link}
![Synchronization Synchronization Starting Point Around 20 xml_[type] tables like: CREATE](https://files.speakerdeck.com/presentations/a97b38dd7247420cb17ed6c7ac1deabe/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}