advanced, independent development studio in Europe, and the biggest producer of mobile games in Poland, ◦ over 160 projects for smartphones and mobile devices with two best known brands: Real Boxing & GodFire, now prepare for Real Boxing 2… coming soon. • Artur Boniecki ◦ Head of R&D Department at Vivid Games S.A., previously was working 14 years for Alcatel-Lucent, ◦ involved in a project related to processing of large quantities of data identifying devices, traits and behavior of gamers and analysis of collected data.
billions of events generated in mobile applications used by millions of users, • a system to process the gathered data and present results: ◦ metrics like DAU, MAU, RET, ARPU, LTV etc., ◦ aggregation per 1hr, 1d, 1w, 1m etc., ◦ segmentation per sex, age, country, device etc., ◦ targetting, ◦ funnels, ◦ a/b tests, ◦ data mining algorithms.
& cost limitations: ◦ very short time, need effects asap, no time for deep research and months of prototyping, ◦ must be a system which does not require niche technology expertise, ◦ no time for building own reliability architecture, ◦ don’t want to spend much for maintenance/administration, ◦ DevOps model is important.
but of course also data stream processor in scope, for research purposes let’s take a look at data store... ◦ HBASE ▪ free and can handle massive amount of data, but no friendly data retrieval API (this is not sql :) ), setting up HA / multi node is very complex, ◦ CASSANDRA ▪ free and can handle huge data sets, has SQL-like language (good) but still need to set up HA / multi node is very complex and columnar schema designing is hard, ◦ COUCHBASE ▪ free, nosql db, very fast, trends are optimistic, but not sure if used in real world for such purposes as we have, yes… some analytics companies are using that, need to get experts or invest in research, self-study a lot
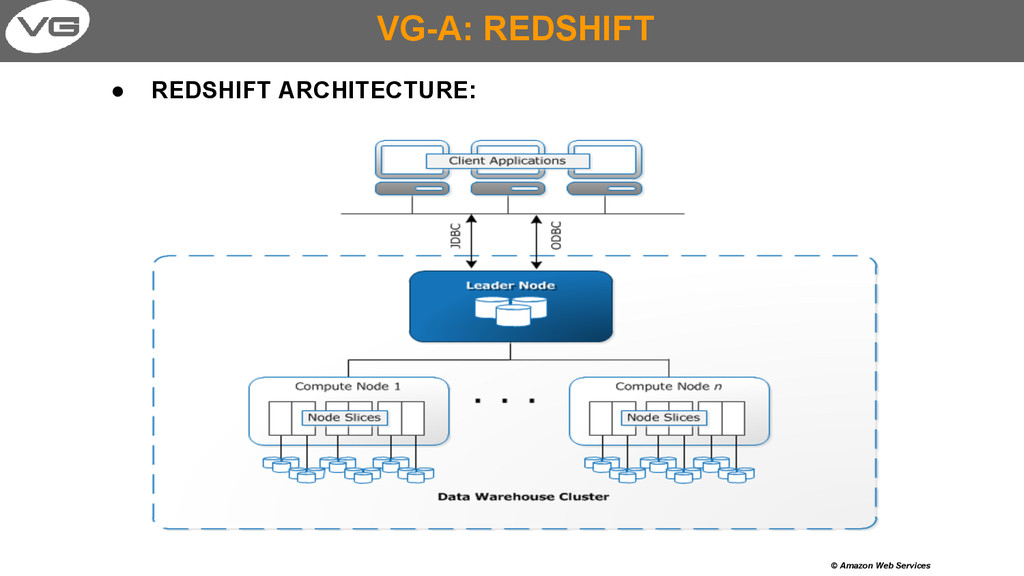
massive amount of data, ◦ columnar storage technology to improve I/O efficiently ▪ parallelizing queries across multiple nodes, ◦ fully managed service with PayG pricing model: ▪ storage size and type, node type, ◦ scalable - more store or io? add node and go with that, ◦ relational model on top – easy to pick up for developers who are familiar with other RDBMS (VERY NICE!!!), ◦ columnar model is not exposed (we don’t need it), ◦ easy backup and restore + data safety – data is replicated across nodes.
per cluster /based on node type - can be changed via support contact, ◦ tables in cluster - max 9990 / per cluster!!!, ◦ max databases - 60 / per cluster, ◦ schemas max 256 / per database, ◦ max concurrent connections to redshift - 500, ◦ max aws accounts per cluster - 20, ◦ maximum size of a single row loaded by using the COPY command is 4 MB, ◦ naming (cluster, db, param_grp, user, sec_grp, subnet_grp, snapshot) - must be lowercase only, unique on account level + other limits - see doc.
use COPY mechanism instead (agregate and batch- load it), ◦ when using COPY don’t store data file on S3 (takes time to upload), just put link/manifest (lightweight) on S3 to your records on EC2, ◦ don’t forget about effective hashing dist key and sort key ◦ S3 & RS should be in the same region to improve performance, ◦ use column compression feature to reduce storage space and reduce of data read to improve performance, ◦ remember you can scale out but you CAN NOT elastically scale in (you must do admin procedures to go down).
AWS… why to grow eg. Kafka and maintain it ;), ◦ fully managed service with PayG pricing model: ▪ stream x nof shards x HTTP request count, ◦ scalable - bigger traffic -> add shards and go, lower traffic -> downgrade shards and go, ◦ keeps requests queued up to 24 hours.
- 10 (need contact amazon to increase), ◦ input data cached max 24h (this is nice feature !!!), ◦ max size of datablob (payload before base64 encoding) is 50kb / aggregate data when possible, ◦ write per shard - max 1000 writes / s; 1MB / s, ◦ read per shard - max 5 reads / s; 2MB / s.
several minutes max (up to 10min wait for ACTIVE), ◦ the data sequence is not a guaranteed, unless you set - SequenceNumberForOrdering, ◦ distribute traffic evenly across the shards - use random partition keys, make sure traffic from one client goes always to the same shard, ◦ there is about 3sec latency from the time that a record is added to the stream to the time that it is available from GetRecords(), ◦ resharding - split & merge, always remember to read from parent shard(s) first. There may be duplicates in child shard. When merging, the “killed” shard is still available to read queued msgs (24h), but not active.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU [email protected]](https://files.speakerdeck.com/presentations/31a27e59ebdb4c3d8385fc45b3fce6c2/slide_17.jpg){kind=link}