Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Crash Only Software
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Antoine Grondin
April 28, 2016
Programming
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Crash Only Software
Antoine Grondin
April 28, 2016
Other Decks in Programming
See All in Programming
1B+ /day規模のログを管理する技術
broadleaf
0
110
過去最大のMCPアップデート! 2026-07-28 RC版の謎に迫る
licux
6
390
Strategic Design in the Frontend: Moduliths & Micro Frontends @DDDEurope
manfredsteyer
PRO
0
130
Spec Driven Development | AI Summit Lisbon
danielsogl
PRO
0
210
フロントエンドとバックエンドで「1文字」を揃えよう
youkidearitai
PRO
0
740
Semantic Version 単位で戦略を柔軟に変えて、パッケージアップデートを自動化する
daitasu
1
300
Hunting Vulnerabilities in Symfony with LLMs
vinceamstoutz
0
560
代数的データ型って何が嬉しいの? #frontend_phpcon_do
kajitack
8
3.8k
技術記事、AIに書かせるか、自分で書くか? 〜それでも私が自分の手で書く理由〜 / #QiitaConference
jnchito
2
1.5k
作って学ぶ、 JSX (TSX) ランタイムの基本
syumai
7
1.7k
そのテスト、説明できますか?~LWテスト戦略FW~のご紹介
nakahara
0
160
Make SRE Operations Easier with Azure SRE Agent
kkamegawa
0
7.8k
Featured
See All Featured
The Pragmatic Product Professional
lauravandoore
37
7.3k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
2.9k
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
480
Become a Pro
speakerdeck
PRO
31
6k
The SEO identity crisis: Don't let AI make you average
varn
0
500
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
780
Designing for Performance
lara
611
70k
Building an army of robots
kneath
306
46k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
950
Transcript
Happiness through Crash-Only Software @AntoineGrondin
Who am I
None
None
None
None
None
None
None
crash-only
crash-only Catchy term that describes a way of coding and
organizing your infrastructure.
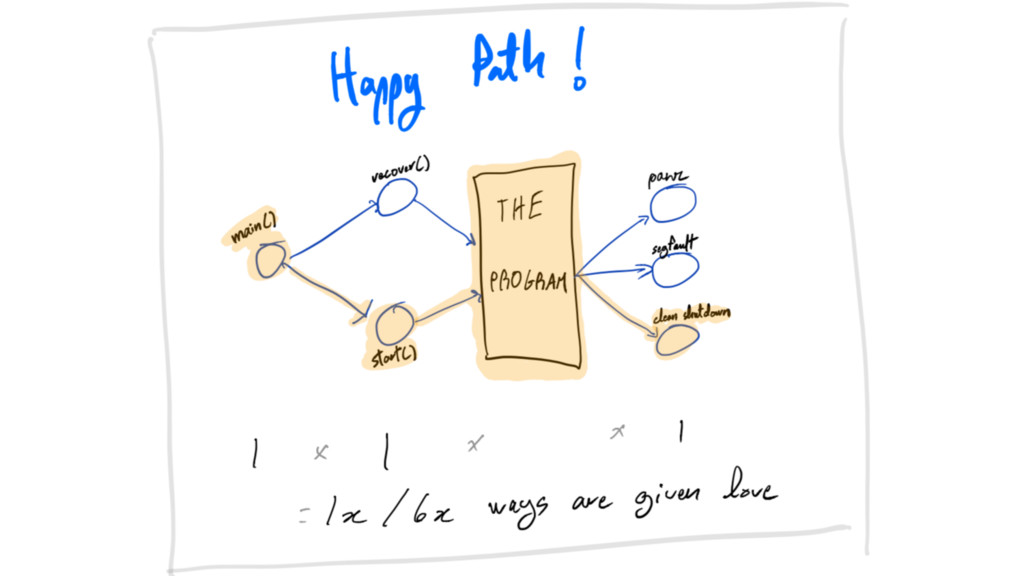
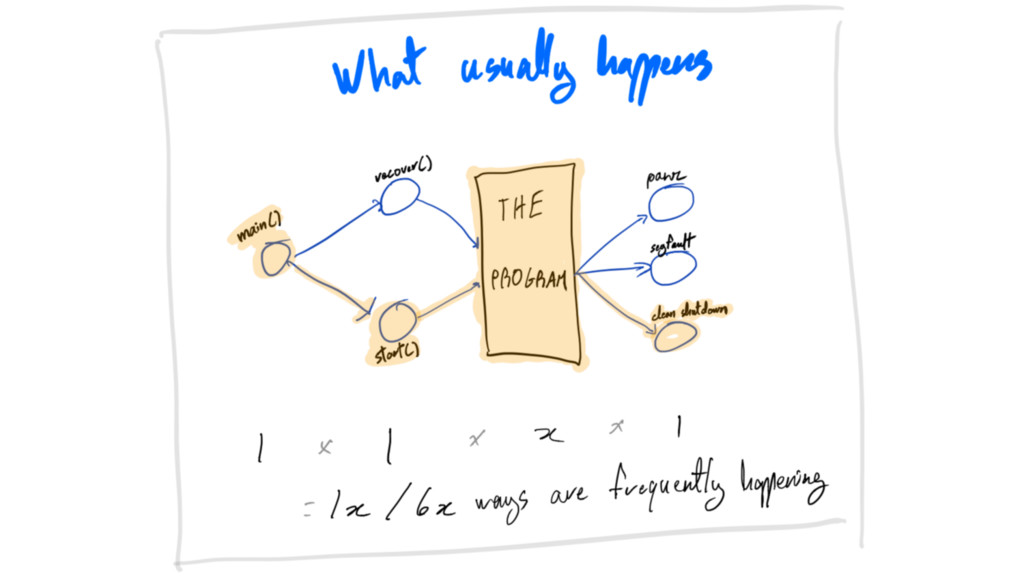
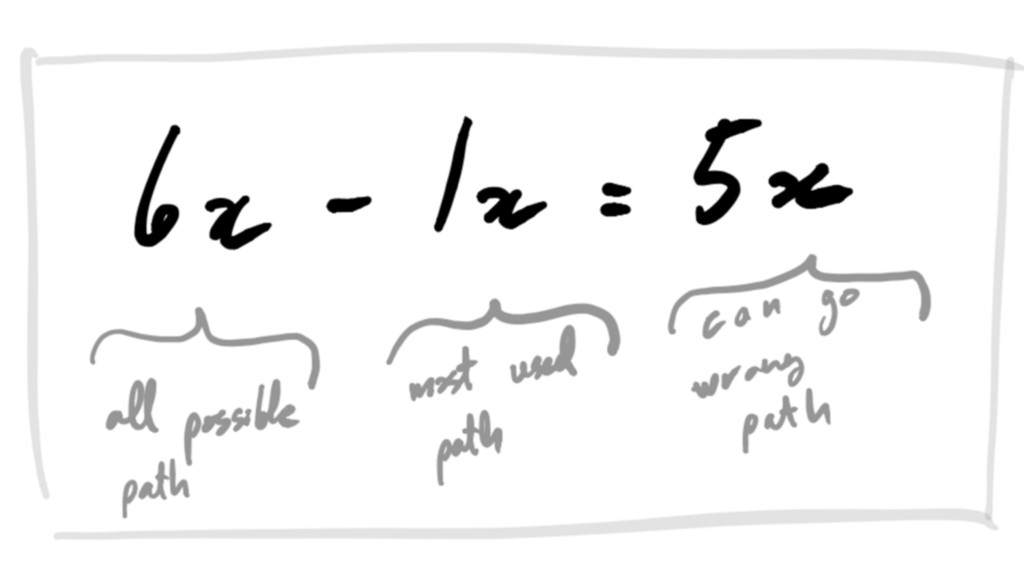
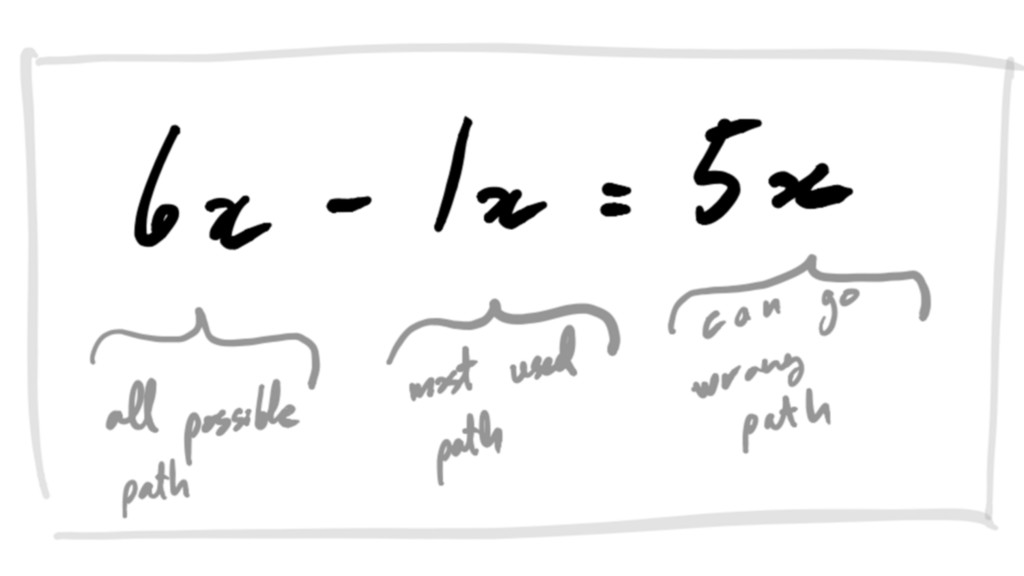
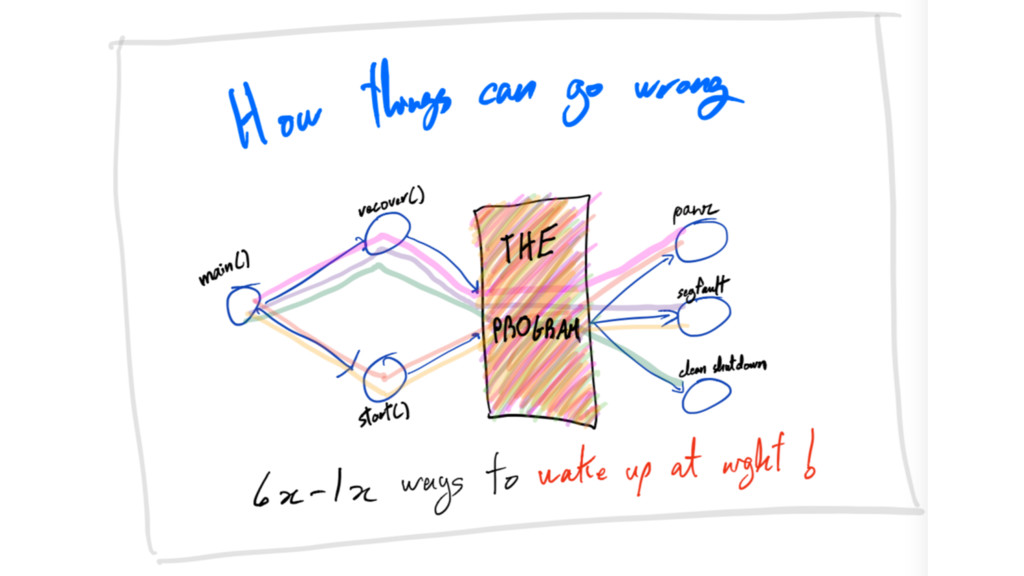
crash-only sounds like a crazy idea
crash-only it’s not =]
crash-only Failure doesn’t throw system into chaos.
crash-only Equilibrium toward progress and consistency.
litmus test
litmus test kill -9 every 10s
kill -9 Is progress still happening?
kill -9 Will you need to urgently wake up?
kill -9 Can you say “wtv, it’ll fix itself”
kill -9 Will you keep all important data?
kill -9 Will your system remain consistent?
litmus test Answered no to any of the previous?
None
None
None
None
None
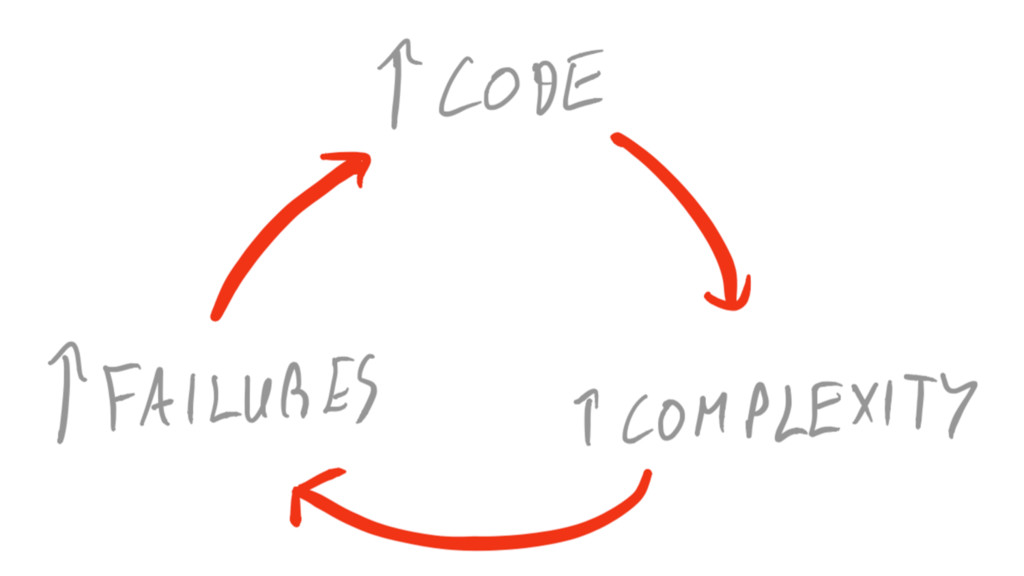
preventing failure is a lost battle
it’s a lost battle Can only push failure into more
and more corners.
it’s a lost battle Failure minimization code adds complexity.
it’s a lost battle Added complexity induces more failures.
it’s a lost battle Attempts to fight failures result in
more failures.
None
None
only way to win is to choose not to fight
choose not to fight Failures will happen no matter what
you do.
choose not to fight Be pessimistic, assume it will happen
all the time.
choose not to fight How to design a pessimistic system
while minimizing complexity?
None
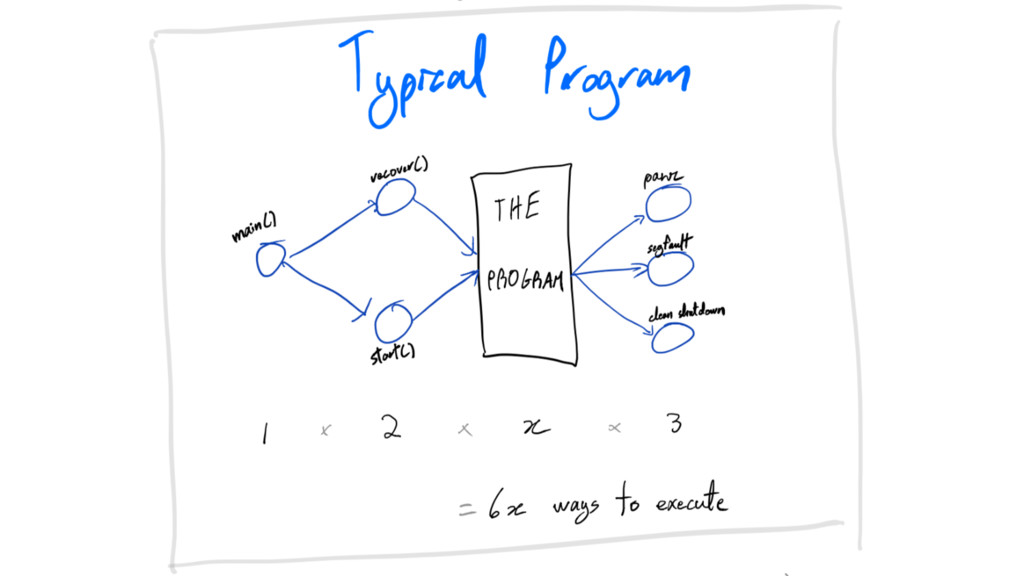
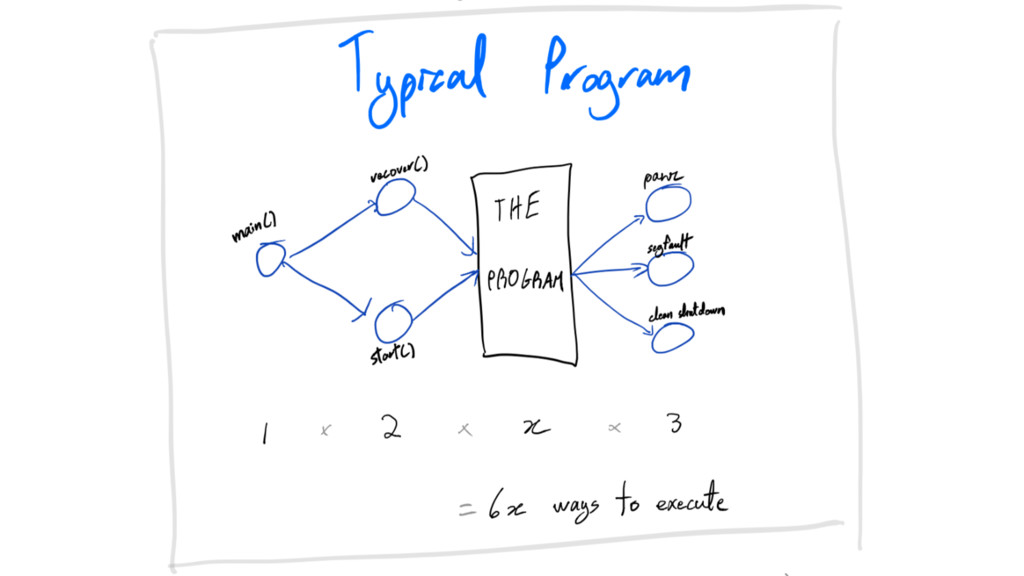
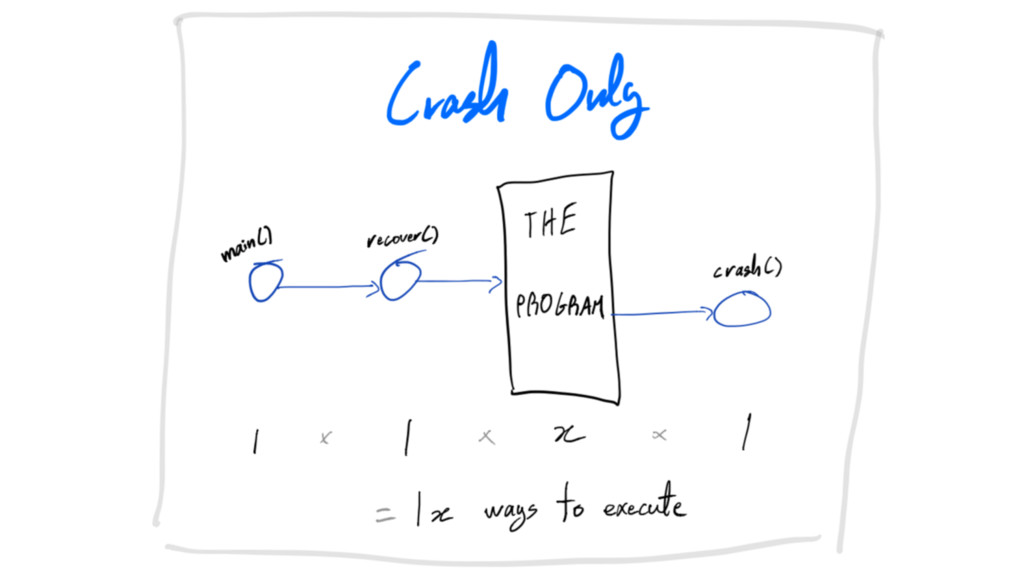
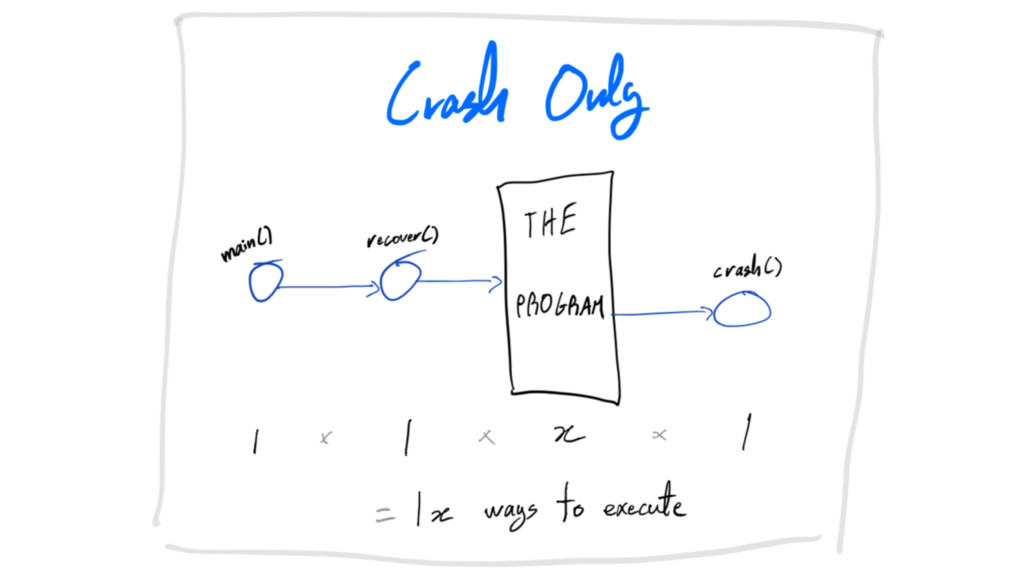
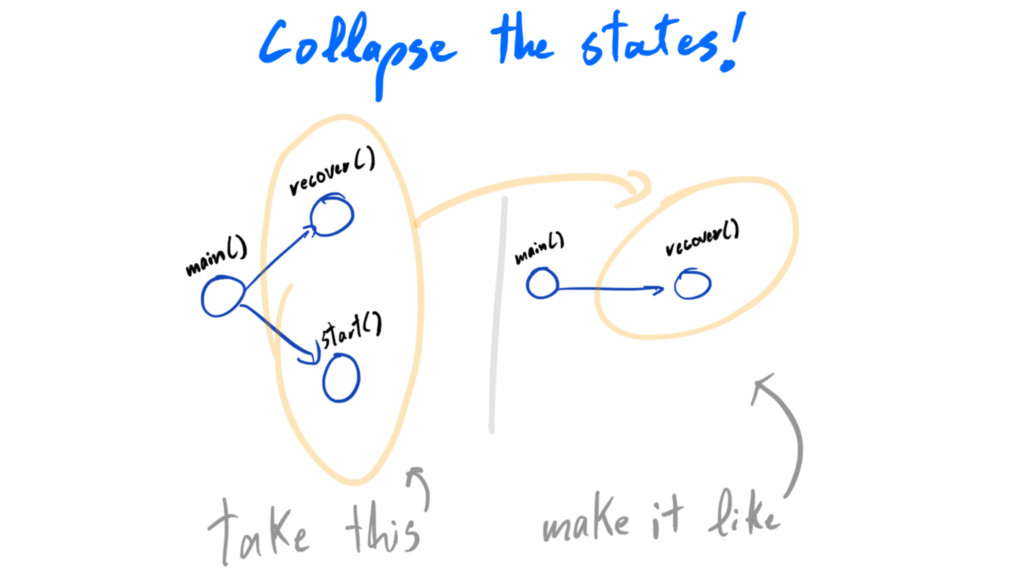
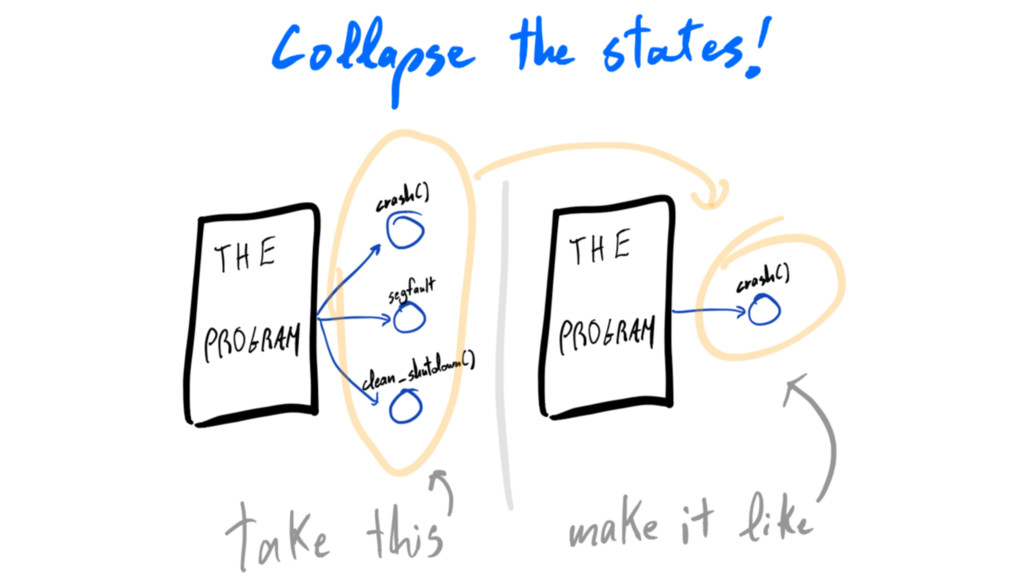
write less code
crash-only
crash-only: write less code collapse code paths
None
None
None
None
None
None
None
write less code
None
None
None
None
write less code do not gracefully shut things down
write less code do not gracefully shut things down false
illusion of safety
write less code do not gracefully shut things down counterproductive
write less code do not gracefully shut things down adds
complexity -> adds failure modes
beyond a single component
crash-only architecture made of crash-only components respect a contract
#1 servers try to process requests or crash
#2 clients send requests until success or TTL
#3 most components are stateless
#4 non-volatile state pushed outside of applications
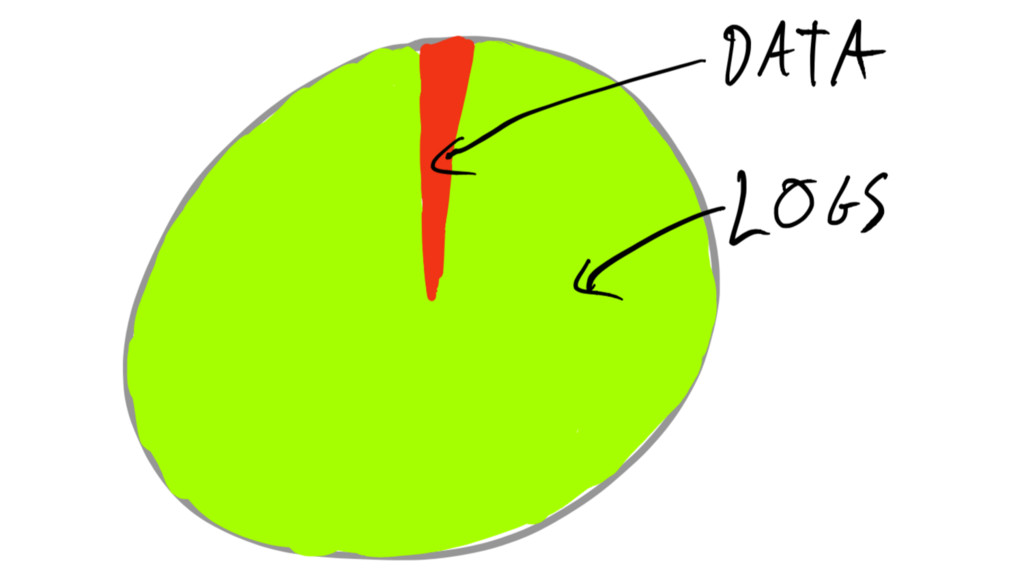
distinguish between types of data #5
pick proper type of datastore based on volatility #6
communicate in a specific manner #7
communications
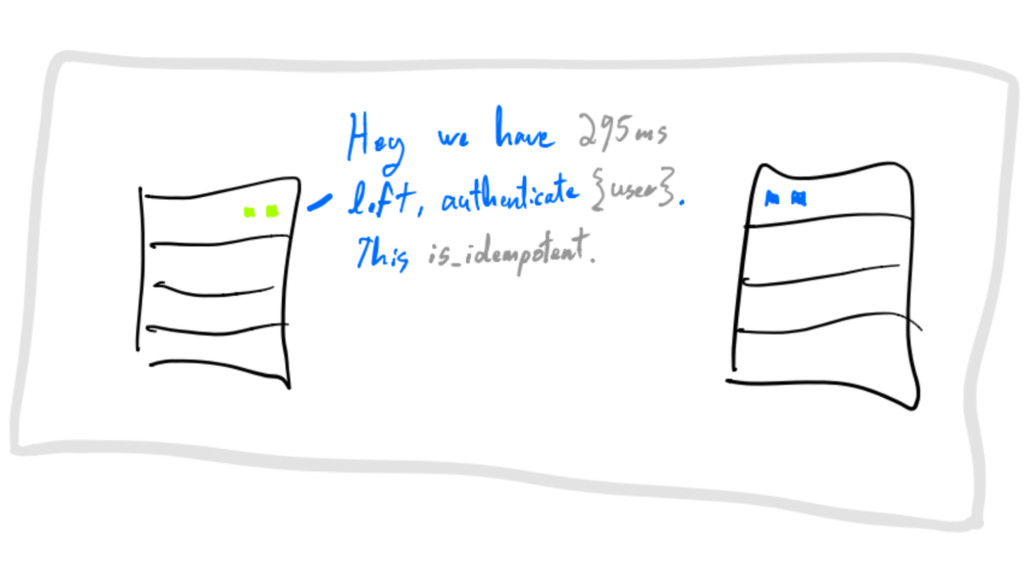
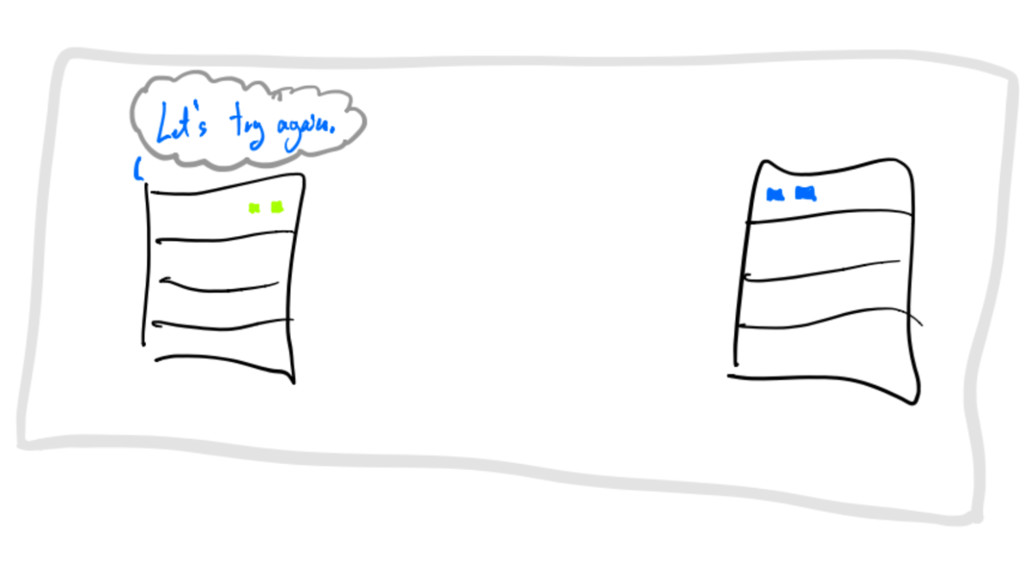
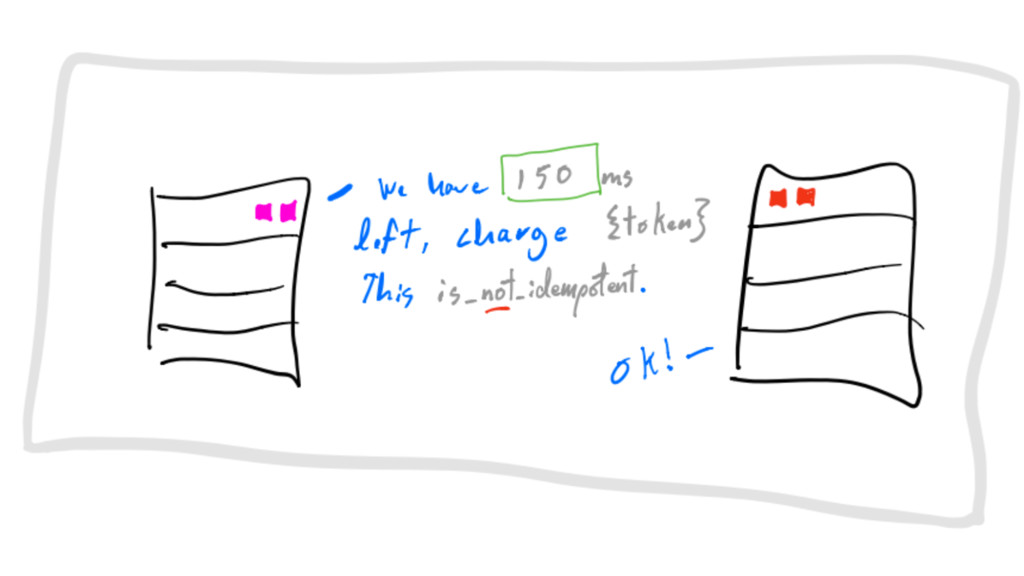
requests must be self-describing communications
requests must be self-describing time to live (TTL) communications
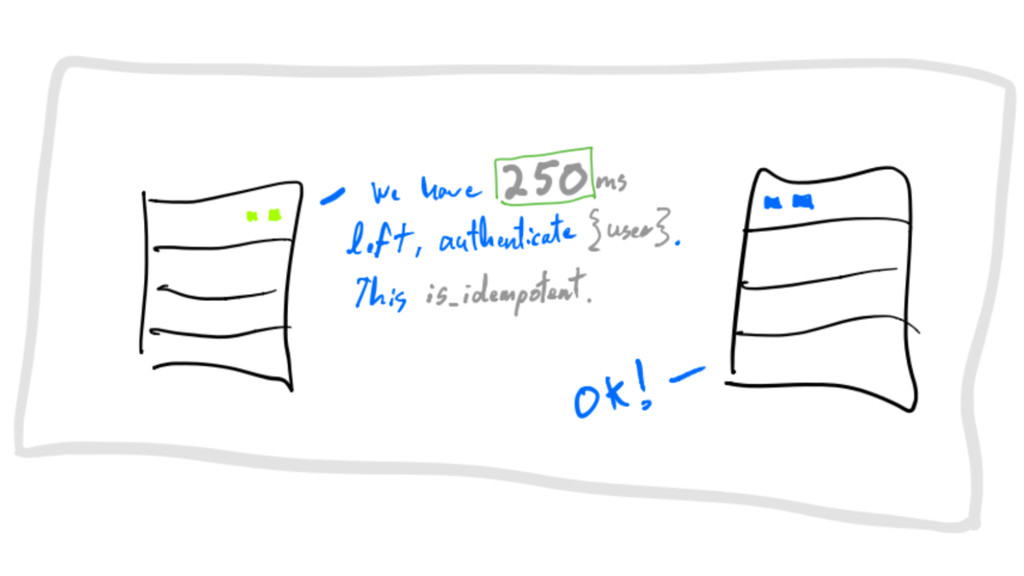
requests must be self-describing is_idempotent flag communications
None
on failure: retry_after gives a chance to crash-only component to
restart communications
exponential randomized backoffs communications
every resource acquisition is leased communications
communications
None
None
None
None
None
None
None
None
None
None
None
None
communication sidebar: exactly-once delivery
when you send exactly 1 message to exactly 1 server
exactly-once delivery
hint: it’s impossible exactly-once delivery
only 2 alternatives exactly-once delivery
only 2 alternatives: at-least-once delivery at-most-once delivery exactly-once delivery
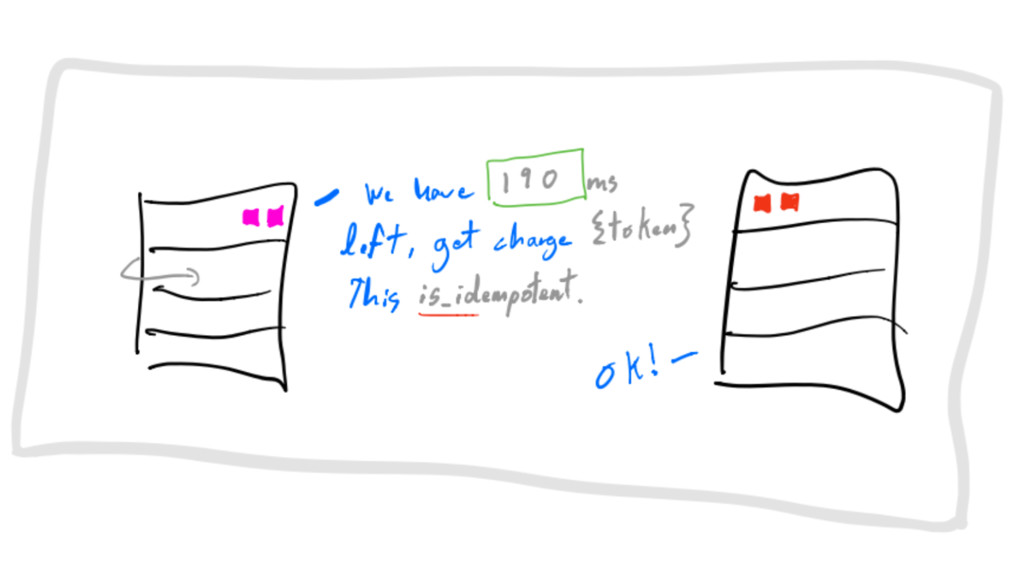
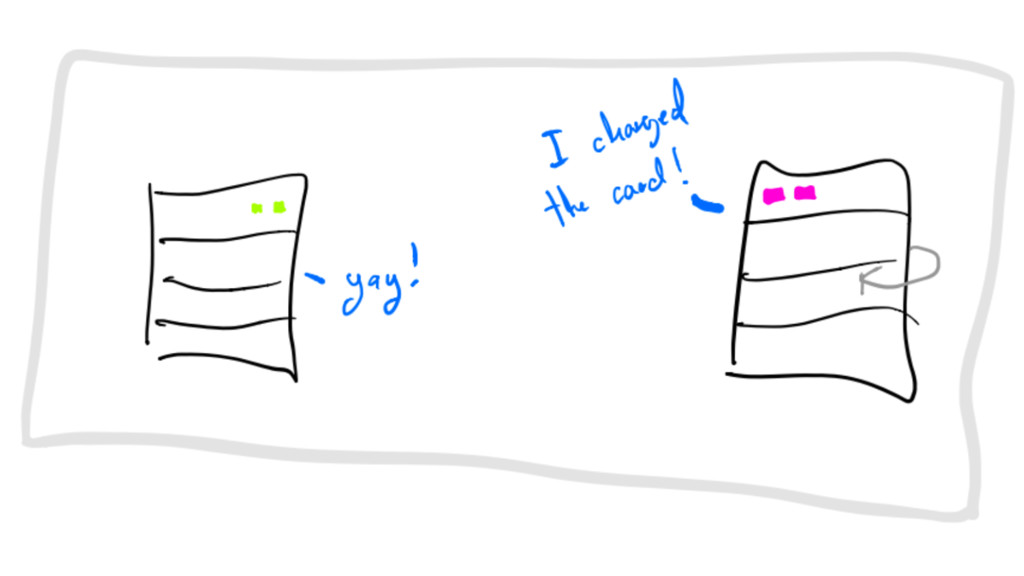
IF message IS idempotent upon failure, retry_after until TTL exactly
at-least-once delivery
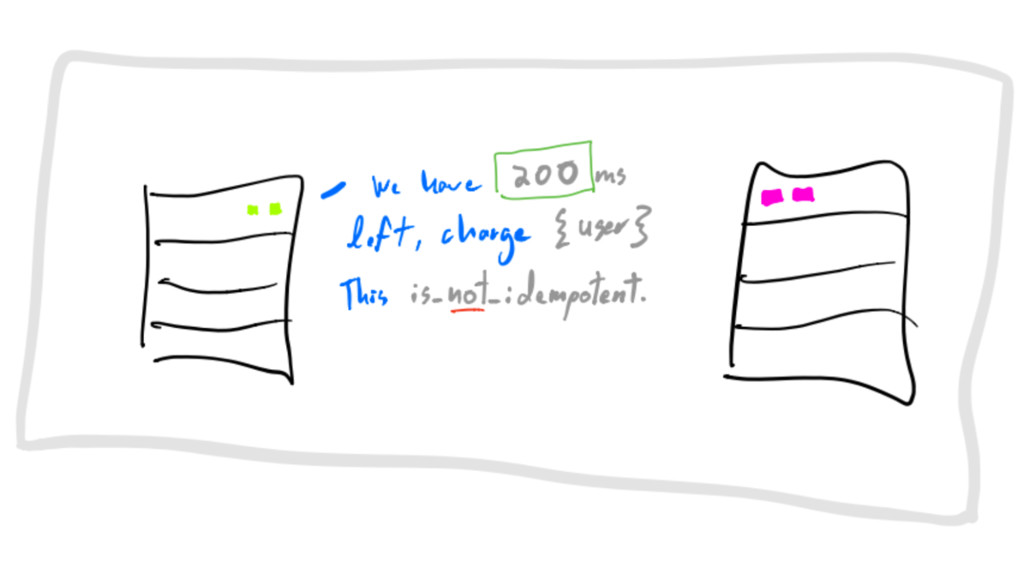
IF message IS NOT idempotent upon failure, rollback exactly at-most-once
delivery
None
None
None
None
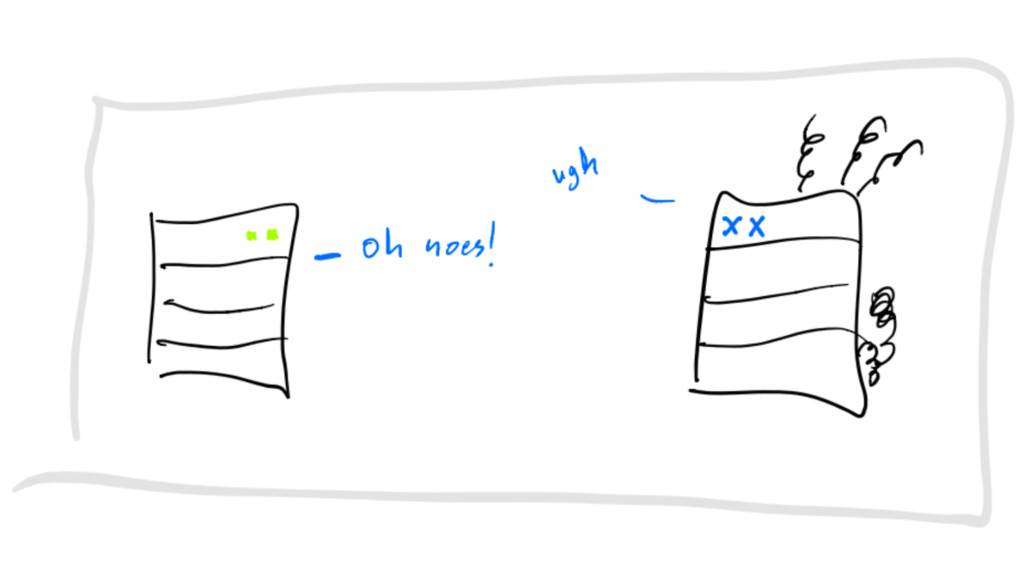
delivery tradeoff I can see… tradeoffs… everywhere…
request have deadline request have is_idempotent flag servers try to
process or crash clients retry until deadline crash-only communication
state
volatile state
non-volatile state
crash-only datastores
RDBMS: postgres crash-only datastores
KV: BerkeleyDB crash-only datastores
append-log based datastores crash-only datastores
real-story
Disk Image Converter at DigitalOcean real-story
requirements real-story
Need to convert millions of images when we change format.
(say qcow to raw) real-story - requirements
Want to migrate ASAP to avoid running legacy code. real-story
- requirements
Don’t want to watch the thing. real-story - requirements
design real-story
Acceptable: at-least-once delivery real-story - design
at-least-once delivery If an image converted >1 time, we don’t
really care. Waste some time, better than losing customer image. real-story - design
non-volatile data: stored in crash-only DB real-story - design
volatile data: stored in Redis (not crash-only) real-story - design
fancy schema real-story - design
all jobs in a queue real-story - design
job leases stored in hash with TTL real-story - design
workers look for jobs without leases real-story - design
Step 1: make a lease Step 2: refresh lease while
working Step 3: delete job+lease once done real-story - design
Step 1: make a lease Step 2: refresh lease while
working Step 3: delete job+lease once done real-story - design
Step 1: make a lease Step 2: refresh lease while
working Step 3: delete job+lease once done real-story - design
if worker dies? real-story - design
if worker dies: its leases expire jobs will get picked
up again real-story - design
if worker dies: its leases expire jobs will get picked
up again real-story - design
if worker fails to delete job once done? real-story -
design
job will be performed again that’s ok real-story - design
if redis crashes? real-story - design
can reconstruct the queue from primary data source real-story -
design
outcome real-story
when issue arose real-story - outcome
get paged by operator real-story - outcome
tell operator to let it go real-story - outcome
tell operator to let it go … the process manager
restarts components real-story - outcome
tell operator to let it go … if issues, system
converges toward progress real-story - outcome
never had to fix anything (touches wood) real-story - outcome
still in use real-story - outcome
and we’re happy real-story - outcome
key points real-story
non-volatile state stored in crash-only DB real-story - key points
volatile state stored in crash-unsafe DB (more like a message
bus) real-story - key points
resources are leased real-story - key points
resources are self-describing real-story - key points
at-least-once vs. at-most-once tradeoff deliberately thought out real-story - key
points
crash-only
is it a panacea? crash-only
no crash-only
other important considerations remain crash-only
caveats
Things That Are Still Important caveats
Things That Are Still Important: Circuit Breakers caveats
Things That Are Still Important: Fallbacks caveats
Things That Are Still Important: Error Recovery caveats
Things That Are Still Important: Degraded Modes caveats
Things That Are Still Important: Cattle vs Pets caveats
Things That Are Still Important: Error Tracking/Reporting caveats
Things That Are Still Important: Debugging Crashed Components caveats
Goes in hand with those strategies caveats
It’s not a Free Lunch caveats
It’s not a Free Lunch (it’s a good step toward
one) caveats
conclusion
Crash-Only software is great! conclusion
Don’t need to wake up! Crash-Only Software Is Great
Stuff just works. Crash-Only Software Is Great
Failures are fun to look at. Crash-Only Software Is Great
It feels good. Crash-Only Software Is Great
Easy to fix when it goes wrong. Crash-Only Software Is
Great
Reduces complexity in code. Crash-Only Software Is Great
Don’t need to wake up! Crash-Only Software Is Great
References Recursive Restartability Candea & Fox, 2001 Crash-Only software Candea
& Fox, 2003 Crash-Only software, More than meets the eye LWN.net, https://lwn.net/Articles/191059/ A Crash Course In Failure NPlus1.org, http://web.archive.org/web/20090430014122/http://nplus1.org/articles/a-crash- course-in-failure/
La Fin comments, ideas: tweet me @AntoineGrondin
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![crash-only it’s not =]](https://files.speakerdeck.com/presentations/3414548df9664f49b1e66743afd00144/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}