Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
EthreumのPoWアルゴリズム Ethash
Search
shigeyuki azuchi
September 28, 2020
Technology
38
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
EthreumのPoWアルゴリズム Ethash
GBECの解説動画の資料です。
https://goblockchain.network/2020/09/ethash/
shigeyuki azuchi
September 28, 2020
More Decks by shigeyuki azuchi
See All by shigeyuki azuchi
FORS
azuchi
0
13
クラスターmempool
azuchi
0
32
W-OTS+
azuchi
0
36
Shorのアルゴリズム
azuchi
0
59
DahLIAS: Discrete Logarithm-Based Interactive Aggregate Signatures
azuchi
0
43
Fiat-Shamir変換と注意点
azuchi
0
230
AssumeUTXOを利用したブロックチェーンの同期
azuchi
0
55
BIP-374 離散対数の等価性証明
azuchi
0
74
BIP-353 DNS Payment Instructions
azuchi
0
91
Other Decks in Technology
See All in Technology
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.4k
Type-safe IaC for Dart
coborinai
0
180
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
310
AI x 開発生産性を取り巻く予算戦略と投資対効果
i35_267
7
2.8k
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
700
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
450
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
730
Network Firewallやっていき!
news_it_enj
0
260
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
1k
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
940
OPENLOGI Company Profile for engineer
hr01
1
74k
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
300
Featured
See All Featured
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
How STYLIGHT went responsive
nonsquared
100
6.2k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Technical Leadership for Architectural Decision Making
baasie
3
440
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
We Are The Robots
honzajavorek
0
280
The Curse of the Amulet
leimatthew05
2
13k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Transcript
EthereumのPoWアルゴリズム Ethash
1 Ethashとは? Ethereumで採用されているASIC耐性を持たせるよう設計されたProof of Workアルゴリズム https://eth.wiki/en/concepts/ethash/ethash • マイニングに大量のメモリの展開を必要とさせることでASIC耐性を持たせる
(2020年9月時点で約3.8GB) • ProgPoWの導入が見送られたことから現在でもEthereumのPoWアルゴリズム • EthashをサポートするASICは既に発売されている。 Bitcoinのように極端な効率の向上ではなく、GPUマイニングに比べて現状数倍 • 将来的には別のアルゴリズムに移行?
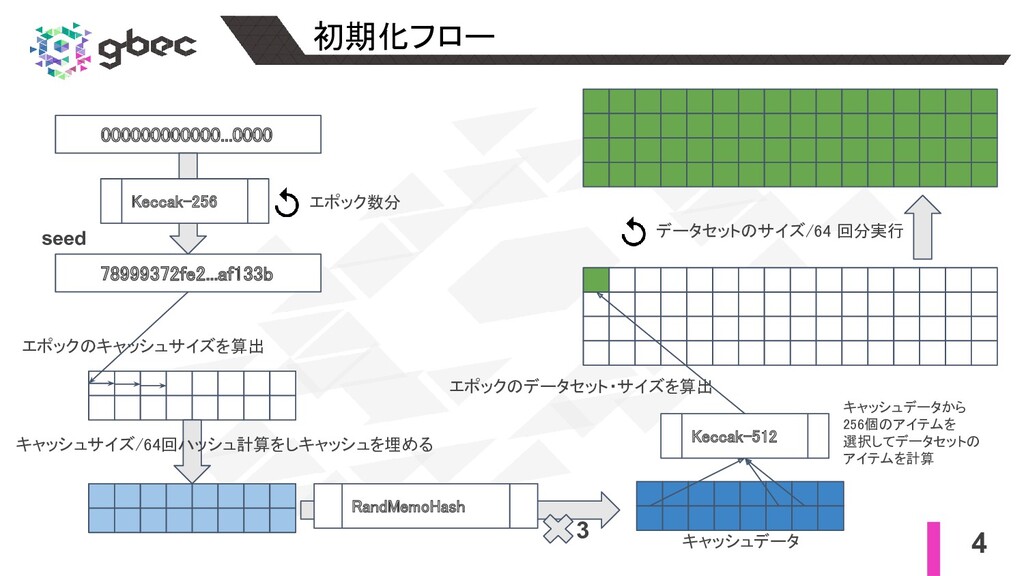
2 初期化 30,000ブロック = 1 エポック毎にマイニングに使用するデータを初期化する 1. seedハッシュを計算する。
”00” * 32のデータをエポック数分 Keccak-256ハッシュを計算することで得られる。 (前のエポックのseed値のKeccak-256ハッシュが次のエポックの seed値) 2. seed値から擬似ランダムなキャッシュを生成する。 a. キャッシュサイズを計算する(キャッシュサイズはエポック毎にほぼ線形に成長する)。 (正確には線形増加する数値を下回る1番近い素数値を採用) i. 初期エポックのキャッシュサイズは 16,776,896 = 約16MB。 ii. 2020年9月17日の10,876,614ブロック時点のキャッシュサイズは約 61MB。 b. seed値をキャッシュサイズ / 64 回、Keccak-256ハッシュ値を計算し、計算した64バイトの各ハッシュ 値を配列に追加していく。←これでキャッシュサイズ分のデータができる。 c. bの配列を初期キャッシュとして、 RandMemoHashアルゴリズムを実行する。 実行結果に対してさら RandMemoHashアルゴリズムを計3回実行する。 ※RandMemoHashは、事前定義されたメモリサイズに対してメモリ量が僅かでも少ないと関数の評価が 指数関数的に遅くなる、もしくは実行不可能になるStrict Memory Hard Functionの一種。 cの出力値がキャッシュデータ。
3 初期化 3. キャッシュデータからデータセットを生成する。 a. まずデータセットのサイズを計算する。 データセットのサイズもキャッシュと同様エポック毎に線形増加する。
i. 初期ブロックのデータセットサイズは、約 1GB。 ii. 2020年9月17日の10,876,614ブロック時点のデータセットのサイズは約 3.8GB。 b. データセットのサイズ / 64回 、キャッシュデータから疑似ランダムに256個選択したデータを組み合わ せてKeccak-512ハッシュを計算しデータセットのアイテムを生成する。 def calc_dataset_item(cache, i): n = len(cache) r = HASH_BYTES // WORD_BYTES # initialize the mix mix = copy.copy(cache[i % n]) mix[0] ^= i mix = sha3_512(mix) for j in range(DATASET_PARENTS): cache_index = fnv(i ^ j, mix[j % r]) mix = map(fnv, mix, cache[cache_index % n]) return sha3_512(mix) def calc_dataset(full_size, cache): return [calc_dataset_item(cache, i) for i in range(full_size // HASH_BYTES)] キャッシュデータを元にbの計算を実行するこで、 マイニングに必要な巨大なデータセットを生成する。
4 初期化フロー 000000000000...0000 78999372fe2...af133b seed Keccak-256 エポック数分 エポックのキャッシュサイズを算出
キャッシュサイズ/64回ハッシュ計算をしキャッシュを埋める RandMemoHash 3 キャッシュデータ エポックのデータセット・サイズを算出 Keccak-512 キャッシュデータから 256個のアイテムを 選択してデータセットの アイテムを計算 データセットのサイズ/64 回分実行
Block Header 5 マイニング Ethashを利用したマイニングでは、生成したデータセットを使って↓の計算をする <Hashimoto Full>
Parent Hash Uncle Hash Coinbase State Root Tx Root Receipts Root logsBloom Difficulty Number Gas LImit Gas Used Timestamp Extra MixDigest Nonce 1. MixDigestとNonceを除いたデータのKeccak-256ハッシュを計算する。 2. 1のハッシュとNonceを結合してKeccak-512ハッシュを計算する= Seed Hash 3. Mix(128バイト)を初期化する。 Mixが128バイトになるまでSeedHashを結合する。 4. データセットから順次データ読み出し、Mixと結合しFNVハッシュ値を計算し、 Mixを更新する。これを64回繰り返す。 各ラウンドで常にRAMからfull pageをフェッチする必要がある。 5. Mixを32バイトに圧縮する。←MixDigest 6. Seed HashとMixDigestを結合してKeccak-256ハッシュ値を計算する。 7. 計算した6のハッシュ値がDifficultyから計算したターゲット値を下回っていた場合、 Proof of Workは成功と判断され、使用したNonceと計算したMixDigestを ブロックヘッダーにセットする。
Block Header 6 Proof of Workの検証 EthashのPoWを検証するには2通りの方法がある
Parent Hash Uncle Hash Coinbase State Root Tx Root Receipts Root logsBloom Difficulty Number Gas LImit Gas Used Timestamp Extra MixDigest Nonce • Full Client向け マイニング時と同様、各エポックで必要なデータセットをメモリ上に展開して、 ブロックヘッダーのNonceを使ってマイニング時と同じ計算Hashimoto Fullを実行する。 高速なPoWの検証が可能。※ これを実行しているのはGethではFull Syncの場合のみ。 • Light Client向け スマートフォンなどの軽量デバイスで大量のメモリを使用したPoWの検証は難しい。 Light Clientでは各エポックで必要なキャッシュのみをメモリ上に展開し、 Hashimoto Fullで必要になるデータセットからのデータの読み出しをメモリからではなく、 都度データセットのアイテムを計算する。<Hashimoto Lite> このため、Light Clientの方がPoWの検証スピードは遅い。ただし必要なメモリ量は低。 ※ GethではLightモード以外に、デフォルトのFast Syncでもこの方法を採用。
7 まとめ • EthashはASIC耐性を持たせるために設計されたProof of Workのアルゴリズム • エポック毎に決定論的にキャッシュ、データセットを生成 • キャッシュ、データセットのサイズはエポック毎に線形増加する
• 高速にマイニングするためにデータセットをメモリ上に展開しておく必要がある • データセットがメモリ上に展開されていると検証も高速 • Light Clientはキャッシュのみをメモリ上に展開し、PoWの検証で必要な データセットのアイテムを都度計算するため、PoWの検証は遅い • PoWアルゴリズムを設計する上でのトレードオフは重要なポイント
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}