data looked like at a given point of time ◦ what data was used to make a decision (reports) ◦ what happened first (total order of operations) • when things happened, correlation (monitoring)
services in production ◦ objects with relations spanning across services ◦ multiple workers on many machines ◦ Ruby (MRI/JRuby), Python; more coming • Amazon EC2 ◦ VMs (Xen) ◦ 7 instance families, different underlying hardware ◦ Ubuntu Linux (12.04.* LTS)
...using independent data stores? How far ahead should we look at the data stream to be sure we’ve seen all changes that happened “now”? Perhaps timestamped changes can be reconciled using additional information about the logic behind them.
to within tens of milliseconds over the public Internet, and can achieve better than one millisecond accuracy in local area networks under ideal conditions. Asymmetric routes and network congestion can cause errors of 100 ms or more.” -- Wikipedia
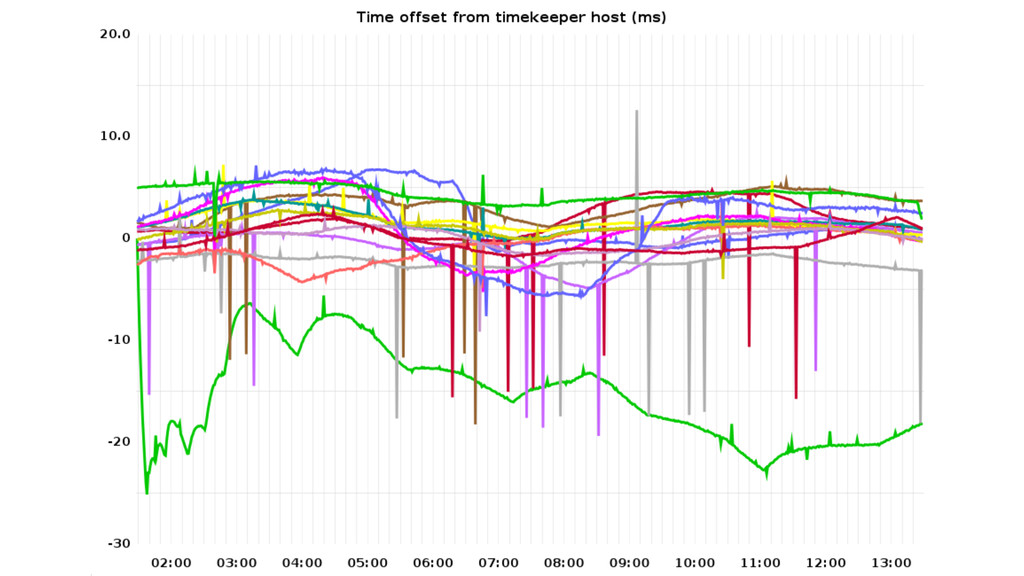
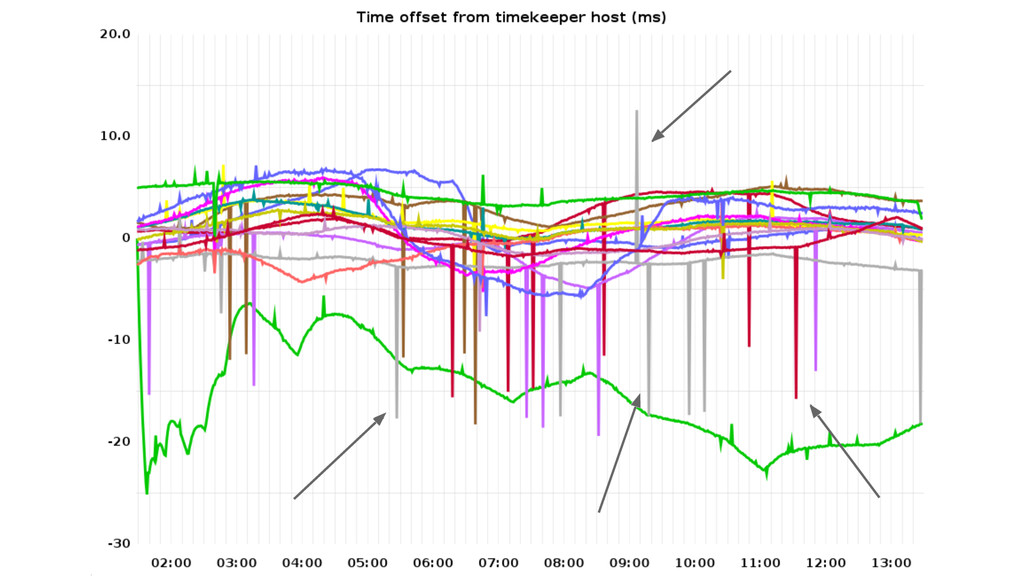
on an EC2 micro instance with 5 days uptime.” “After shutting down and starting again, it was back to normal, so there seems to be some kind of drift.” “Clocks on virtual servers are especially prone to a whole class of these problems. 12 seconds a day is pretty bad until you come across virtual boxes with clocks that run at 180–200% speed!”
on an EC2 micro instance with 5 days uptime.” “After shutting down and starting again, it was back to normal, so there seems to be some kind of drift.” “Clocks on virtual servers are especially prone to a whole class of these problems. 12 seconds a day is pretty bad until you come across virtual boxes with clocks that run at 180–200% speed!” (ಠ_ಠ)
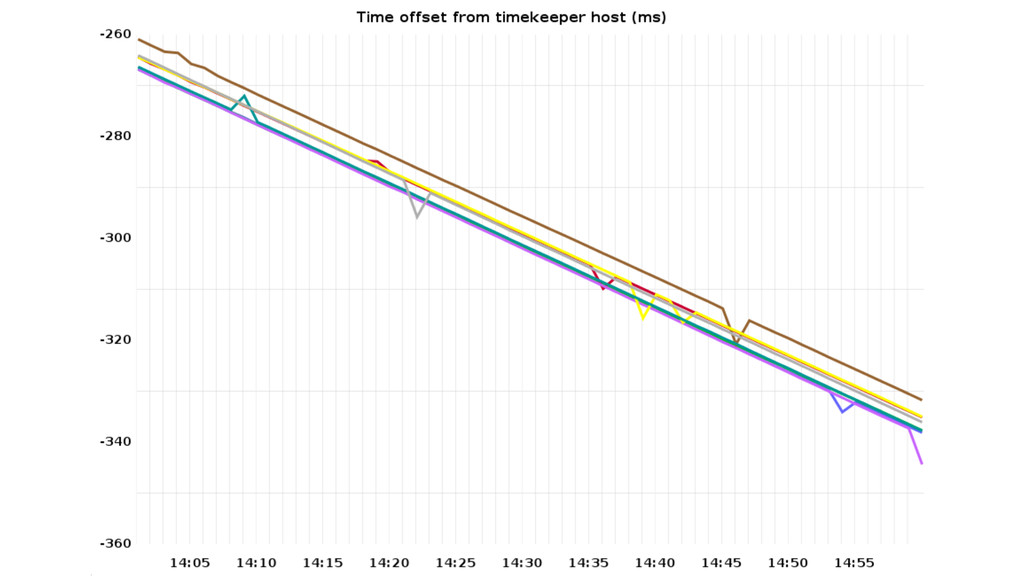
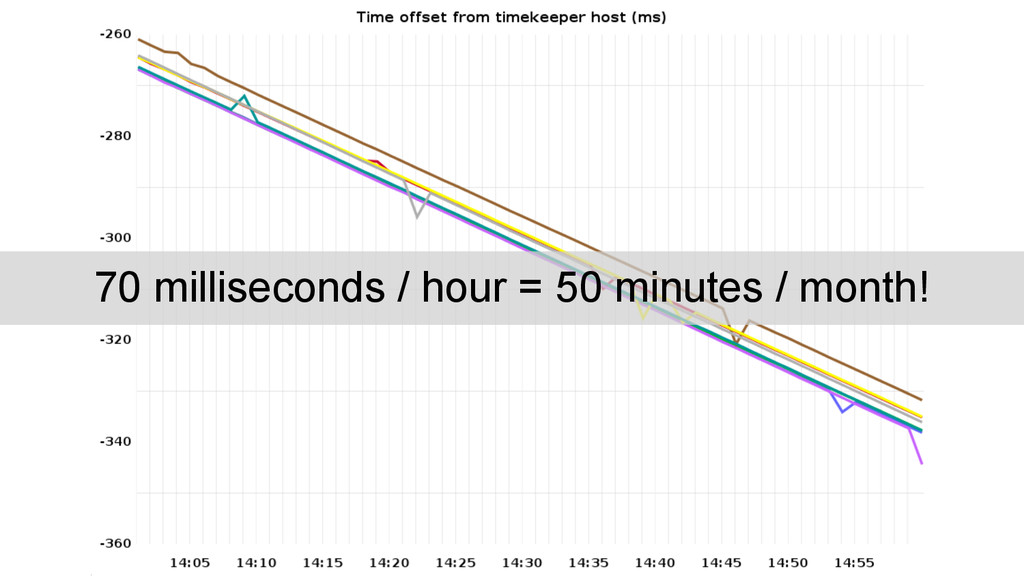
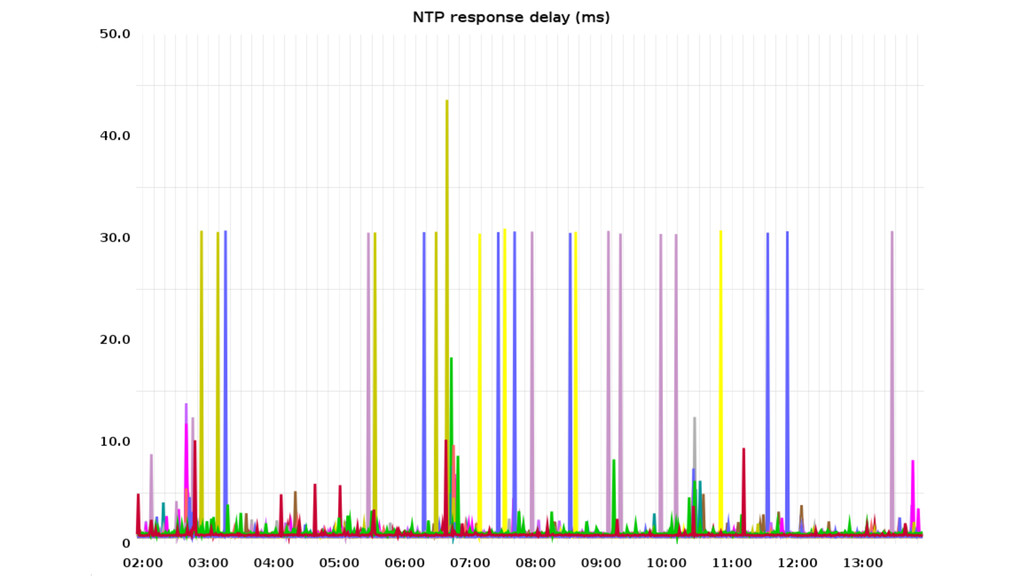
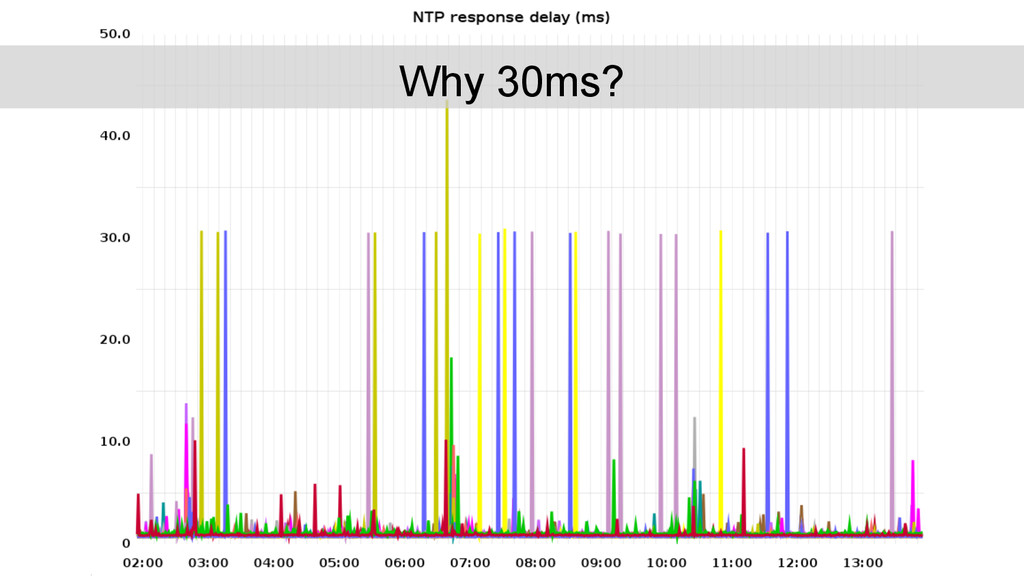
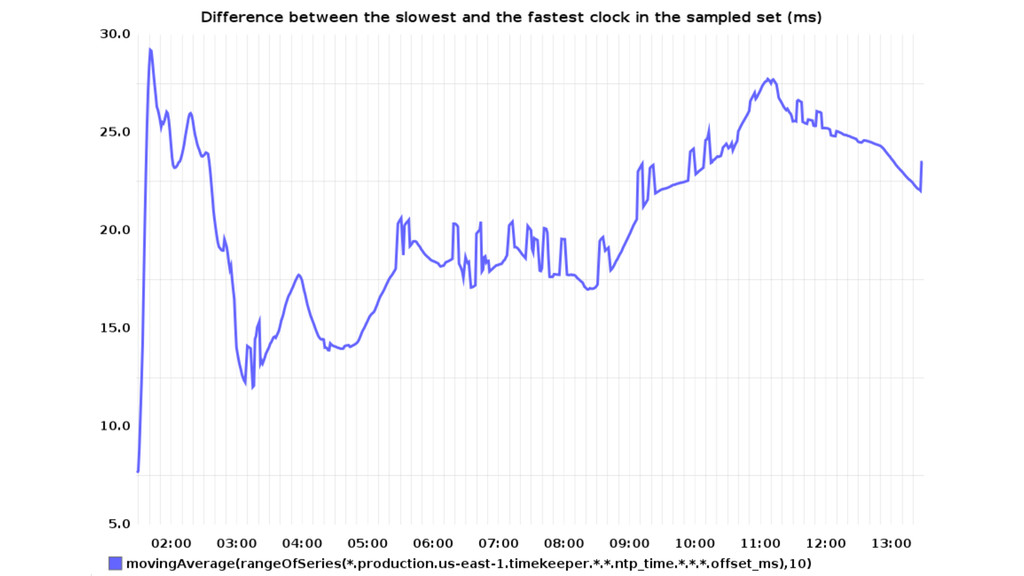
vs. a single monitoring “timekeeper”. Out-of-the-box NTP configuration using {0,1,2}.amazon. pool.ntp.org yields sets of 3 different time servers for each NTP daemon. Usually one stratum 1 source in the mix (GPS, CDMA, ...).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Questions? Let’s talk afterwards! [email protected]](https://files.speakerdeck.com/presentations/7358c51ffbec4cdf9511396864277450/slide_16.jpg){kind=link}