Presented by Matthew Von-Maszewski at RICON East 2013
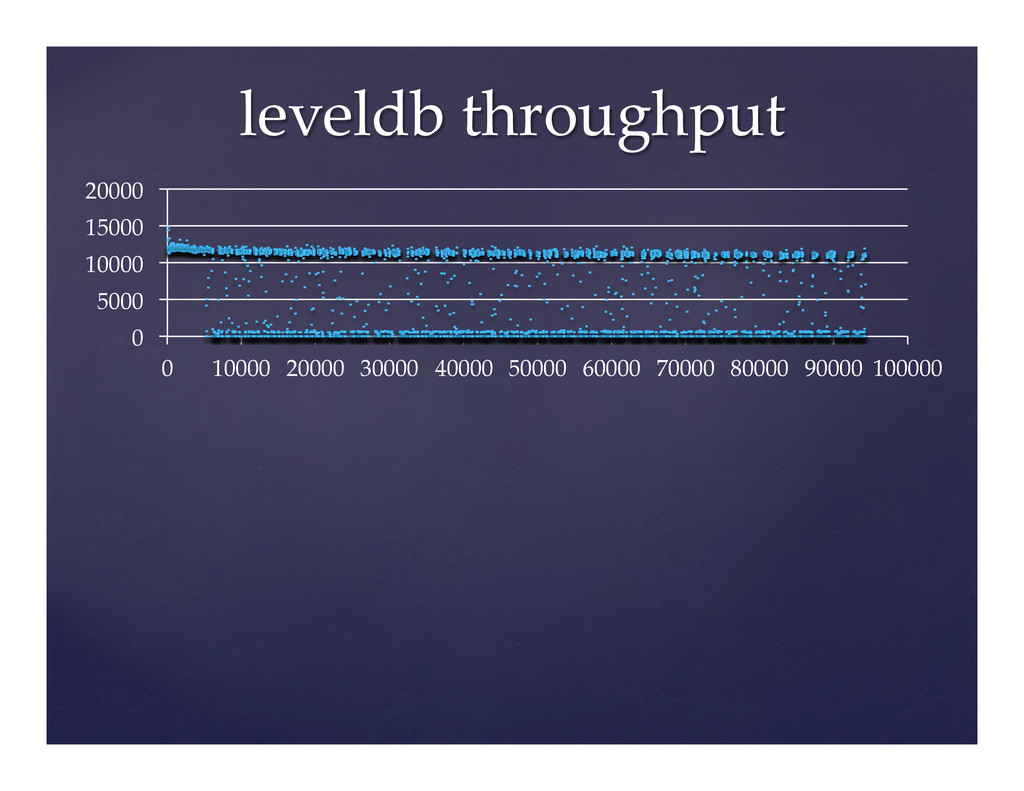
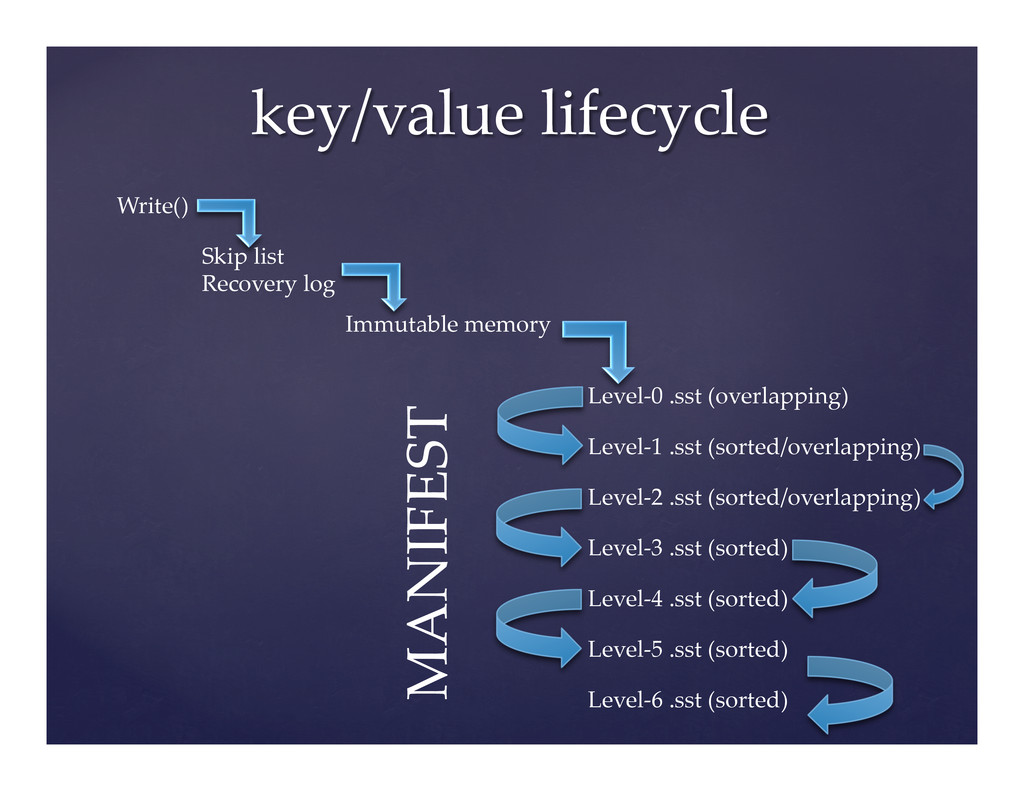
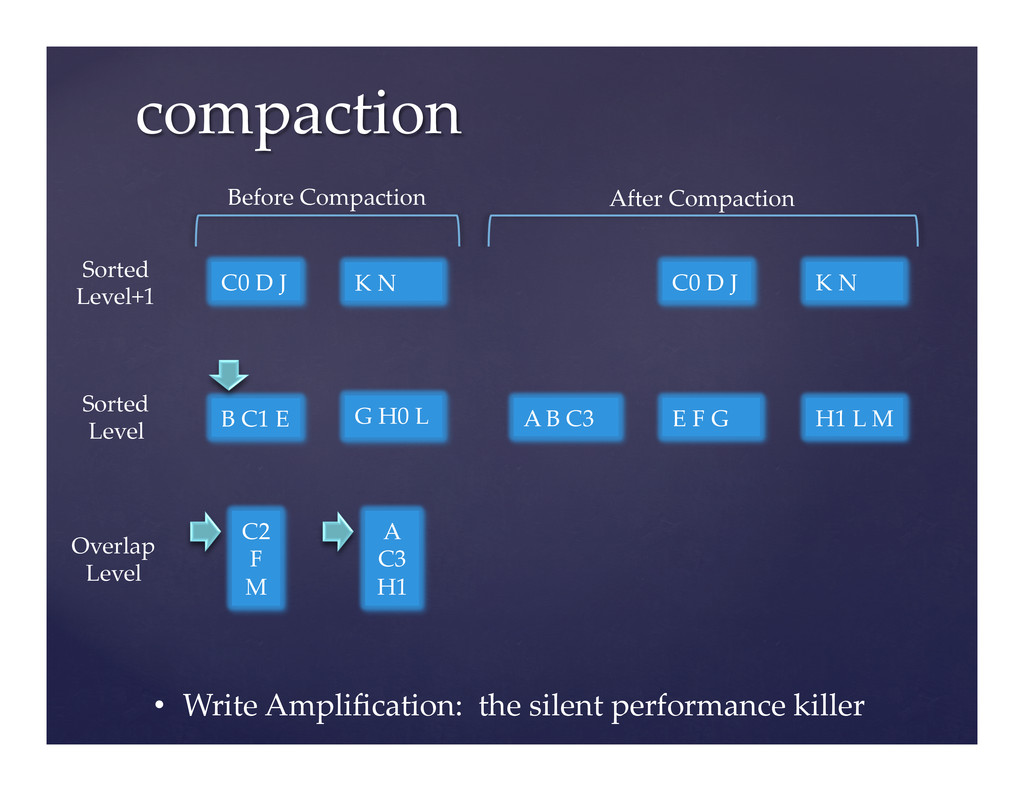
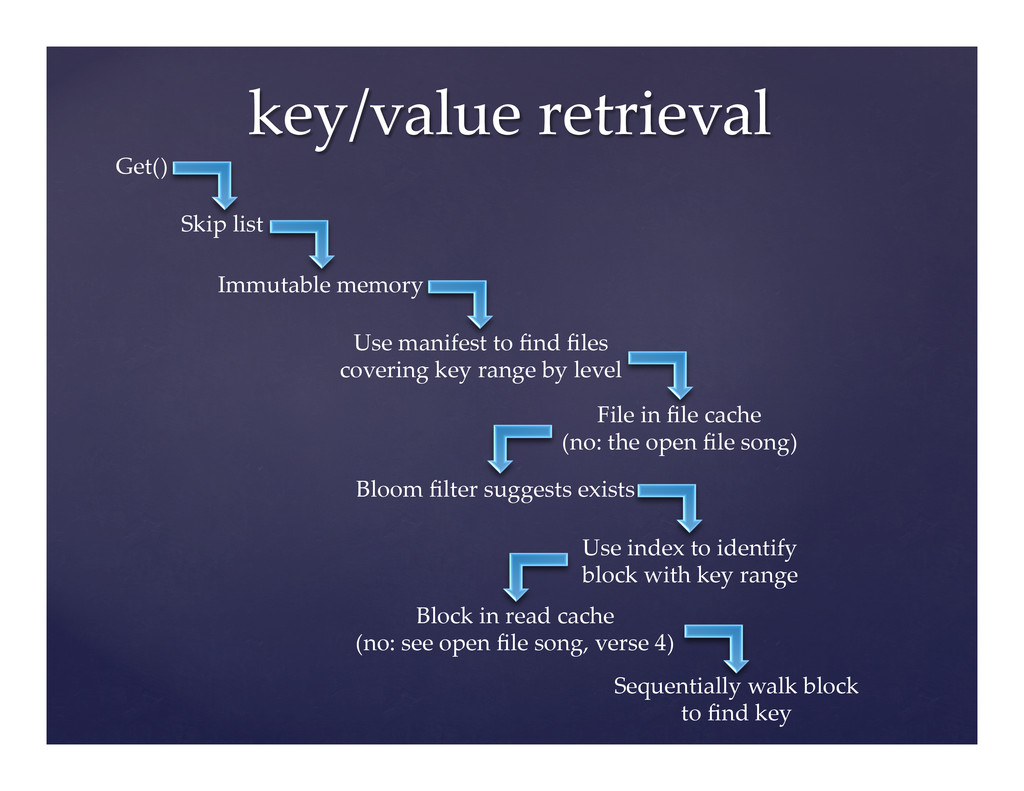
LevelDB is a flexible key-value store written by Google and open sourced in August 2011. LevelDB provides an ordered mapping of binary keys to binary values. Various companies and individuals utilize LevelDB on cell phones and servers alike. The problem, however, is it does not run optimally on either as shipped.
This presentation outlines the basic internal mechanisms of LevelDB and then proceeds to discuss the tuning opportunities in the source code for each mechanism. This talk will draw heavily from our experiences optimizing LevelDB for use in Riak, which is handy for running sufficiently large clusters.
About Matthew
Matthew is a high tech migrant worker. Currently a Software Engineer at Basho Technologies working on the C/C++ aspects of Riak's storage and vm layers. Prior to Basho, Matthew has been a contributing developer at Intuit, Akamai, Nuview, SmarterTravel Media, and for miscellaneous contracts. His delivered projects range from 4 bit micro controller toys, ROM based Quicken, high volume / user specific content delivery, and distributed retail inventory planning/control. Weekends find him either with his family or out participating in marathons or Half-Iron triathlons.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}