Presented by Chris Tilt at RICON East 2013.
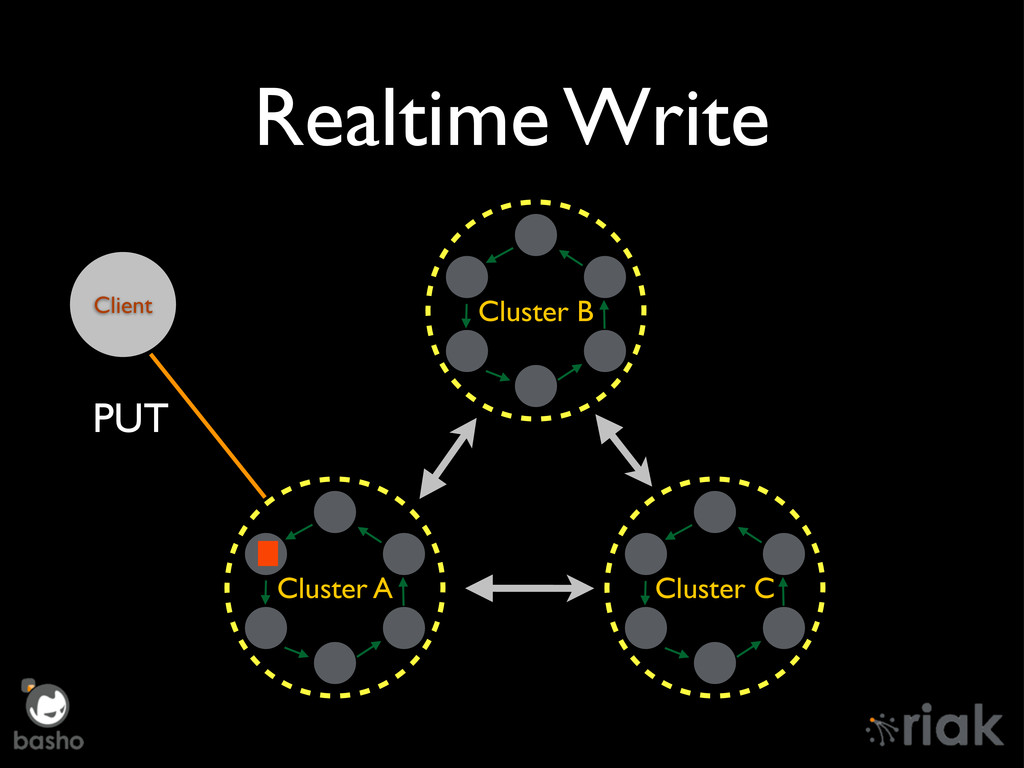
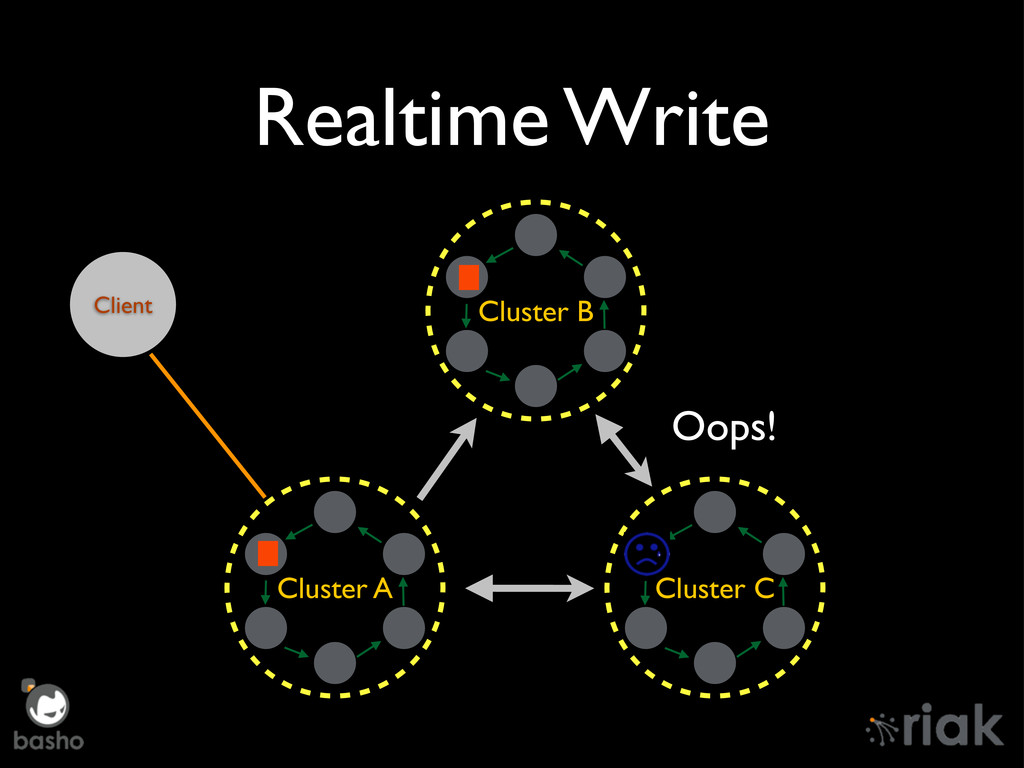
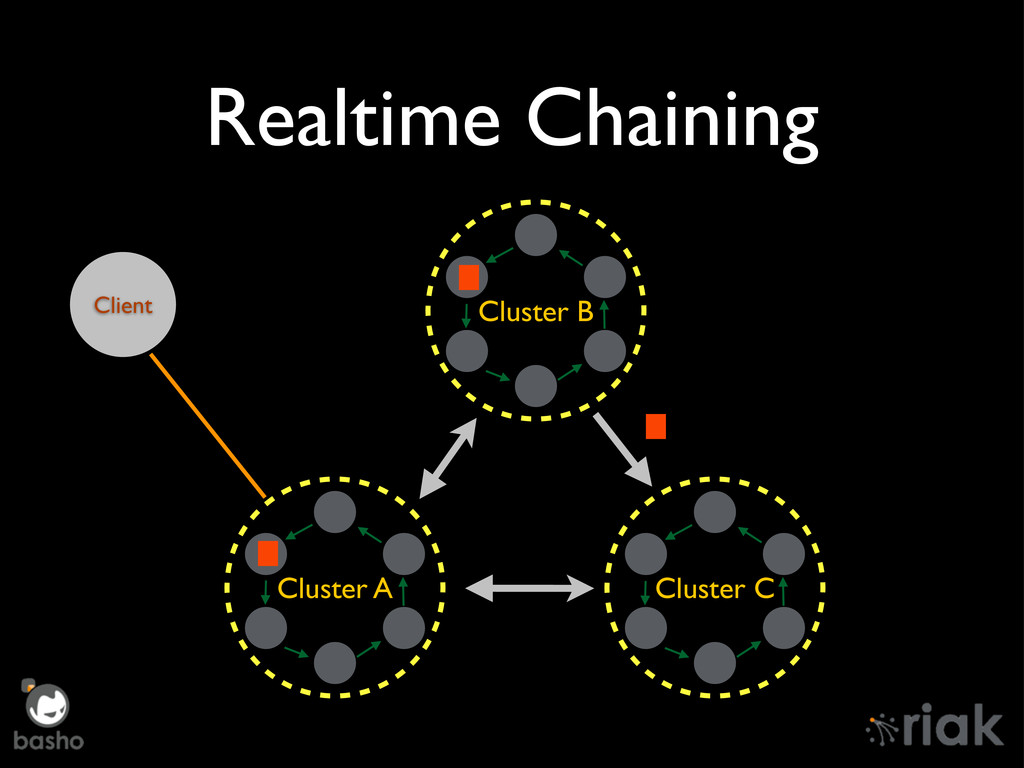
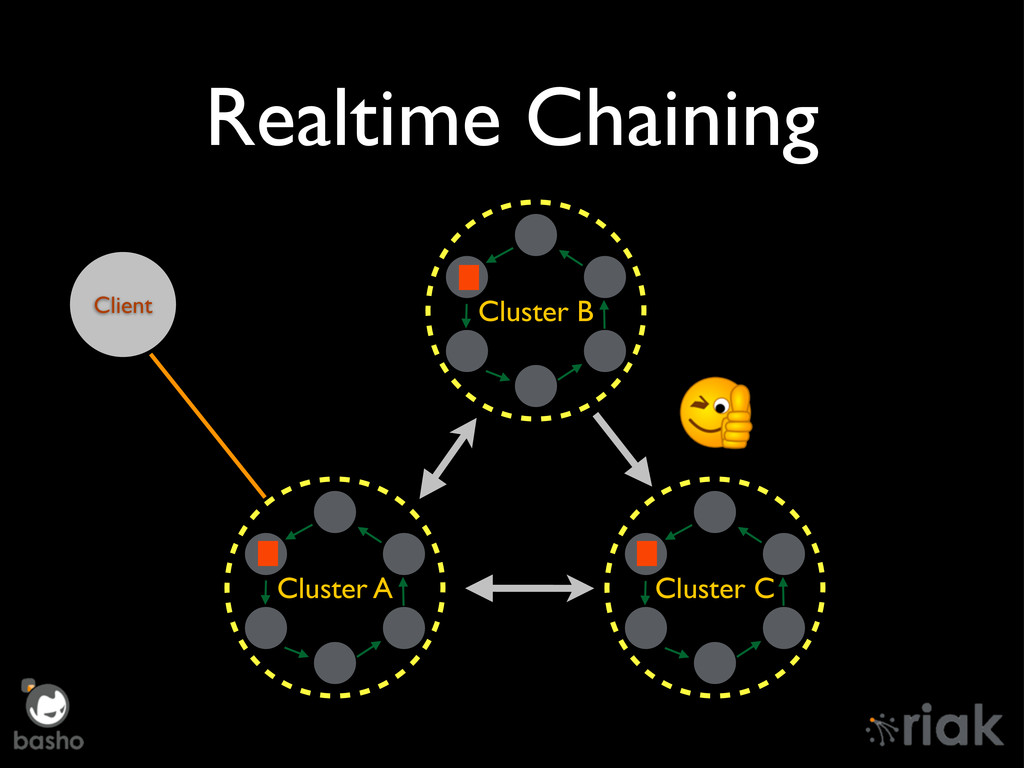
Riak Enterprise has undergone an overhaul since it's 1.2 days, mostly around Mult-DataCenter replication. We'll talk about the "Brave New World" of replication in depth, how it manages concurrent TCP/IP connections, Realtime Sync, and the technology preview of Active Anti-Entropy Fullsync. Finally, we'll peek over the horizon at new features such as chaining of Realtime sync messages across multiple clusters.
About Chris
Chris has 25 years in the high technology industry as a software developer, CTO, designer, and startup co-founder. He discovered Erlang indirectly through development of telecommunications test equipment at Tektronix, which launched a new passion in functional programming. During the Dot Com days, he co-founded a startup using OCaml as the core language for graph theoretic analysis of web sites. A fear of compilers led to an intense study and eventual job as the lead on a Java-to-native assembly language compiler for a Massively Parallel Processor Array at Ambric, also written in OCaml. Thinking about how to scale software concurrently lead right back to Erlang and Basho, where he works on the Enterprise project team. Chris develops iPhone and Android applications as a hobby. He and his son, Geordie, co-designed a concurrent programming language called 'G' which compiles to C, and a LEGO-sized underwater ROV - both targeted for Arduino. When not programming, he enjoys rocket stoves, cob structures, remodeling, Minecraft, and Kendo.
![Enterprise Reloaded Replication in Record Time Chris Tilt ([email protected]) Basho](https://files.speakerdeck.com/presentations/b3611520a5590130e1123ed34b672d53/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
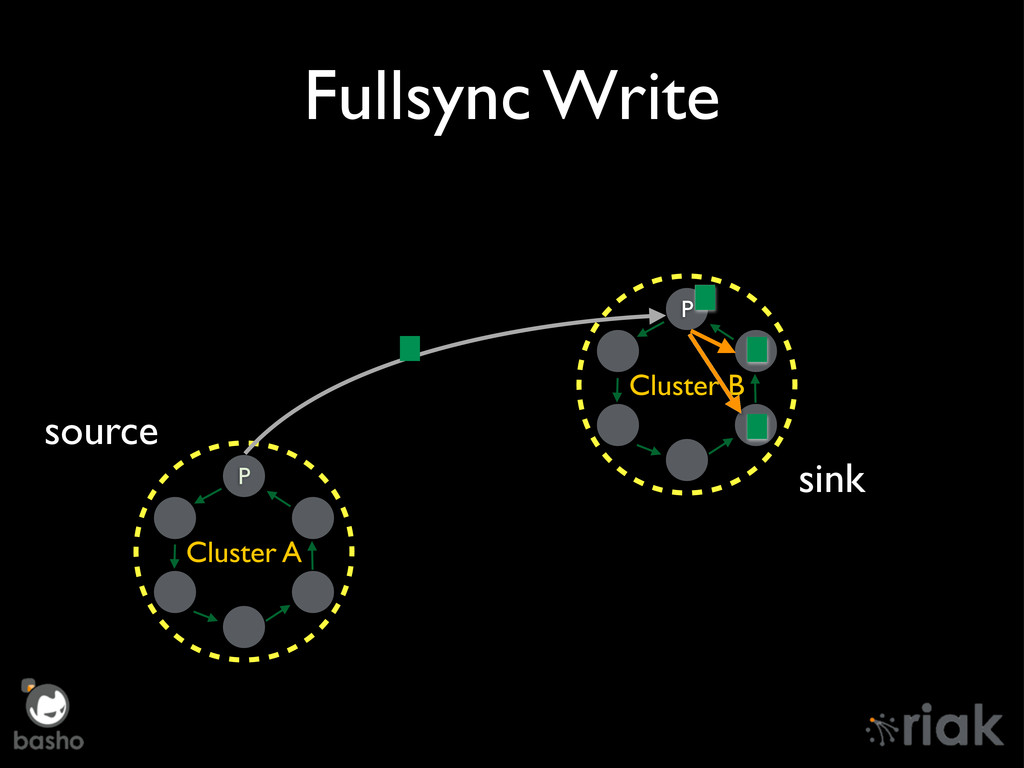{kind=link}
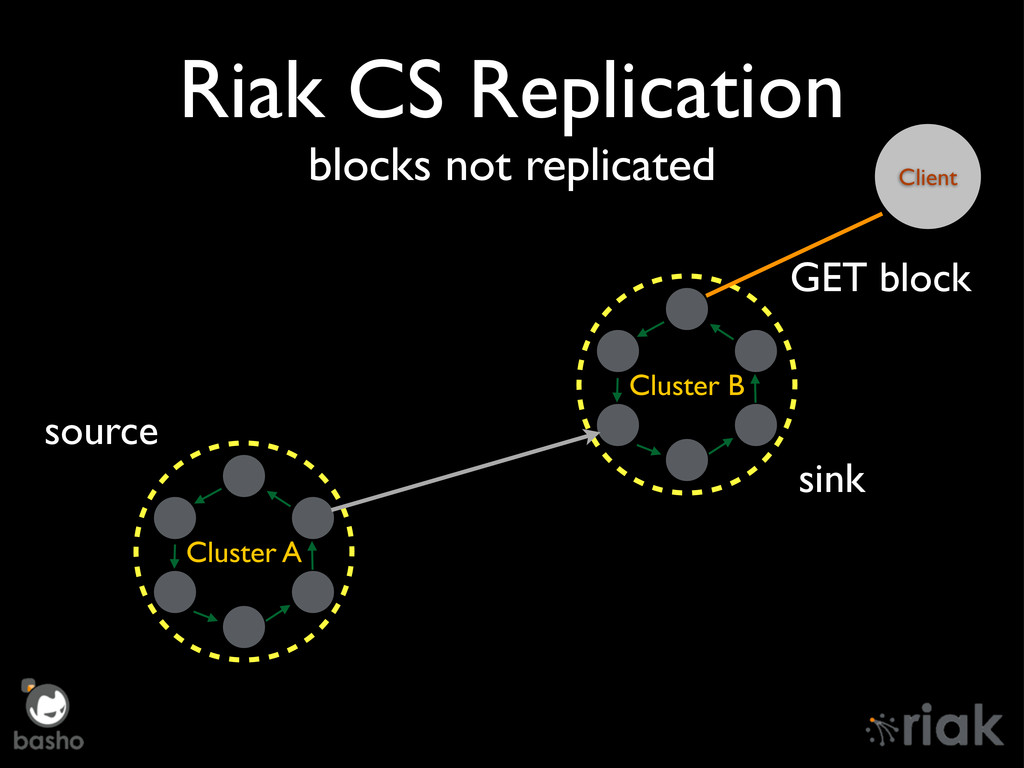{kind=link}
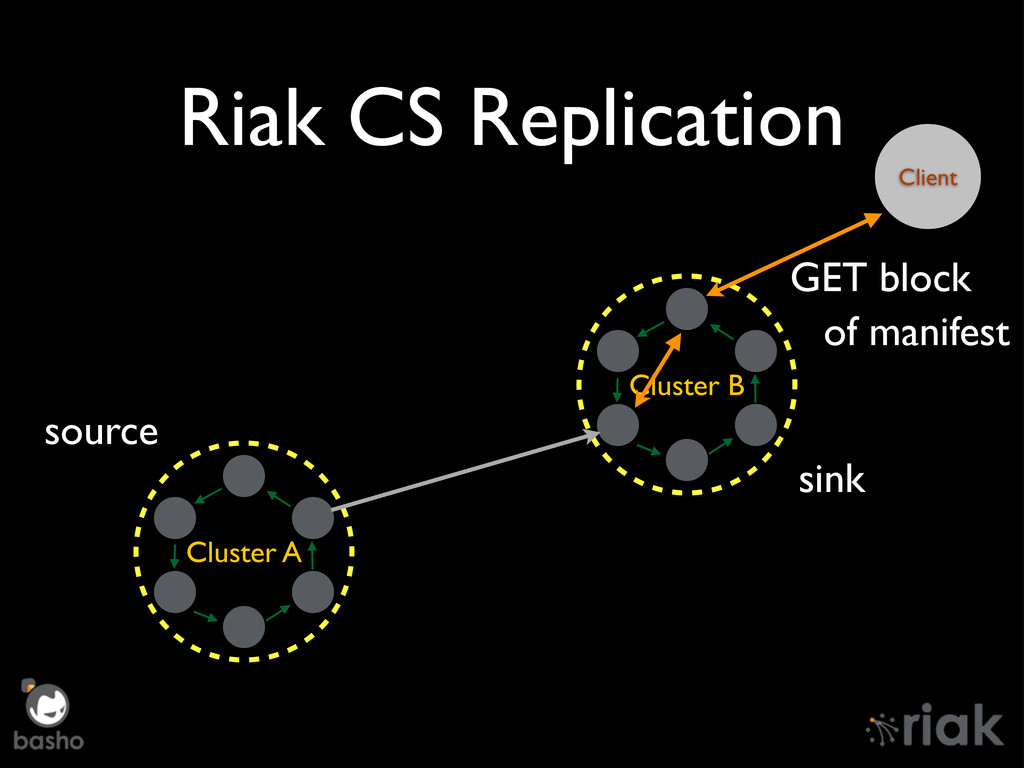{kind=link}
{kind=link}
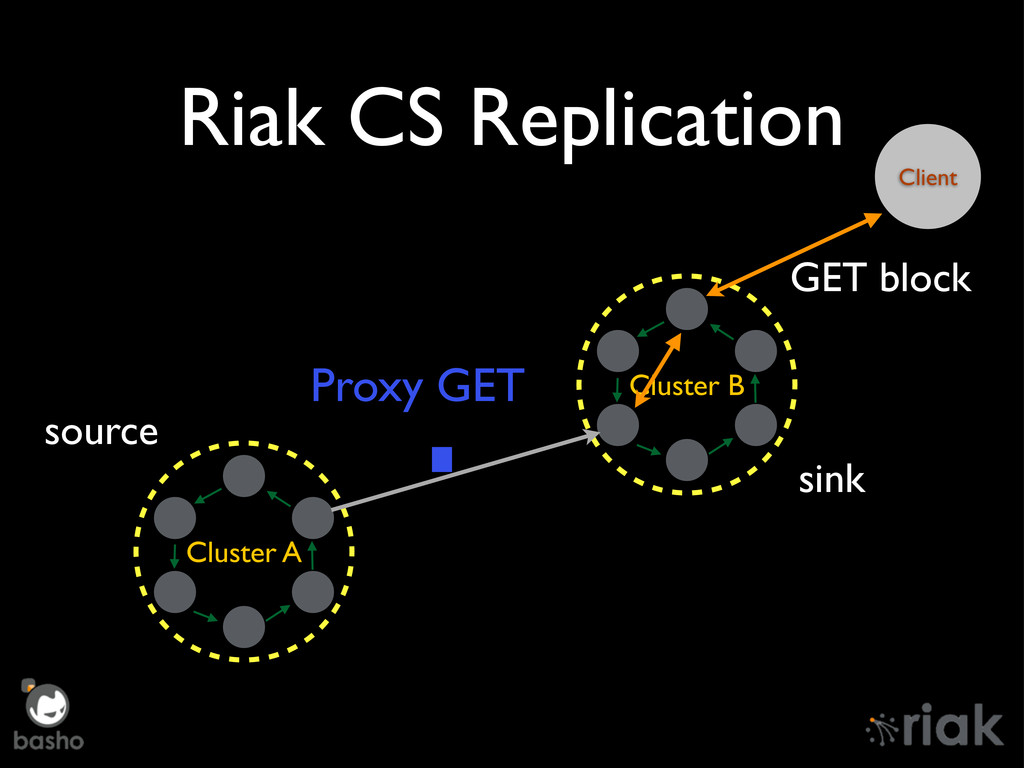{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
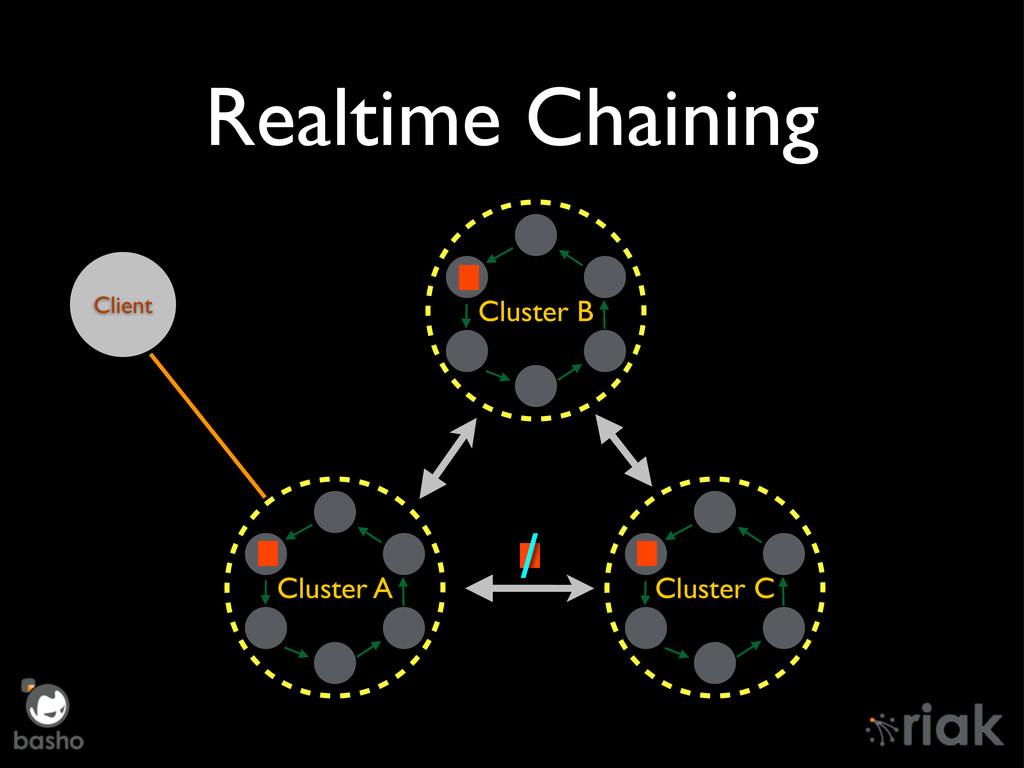{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
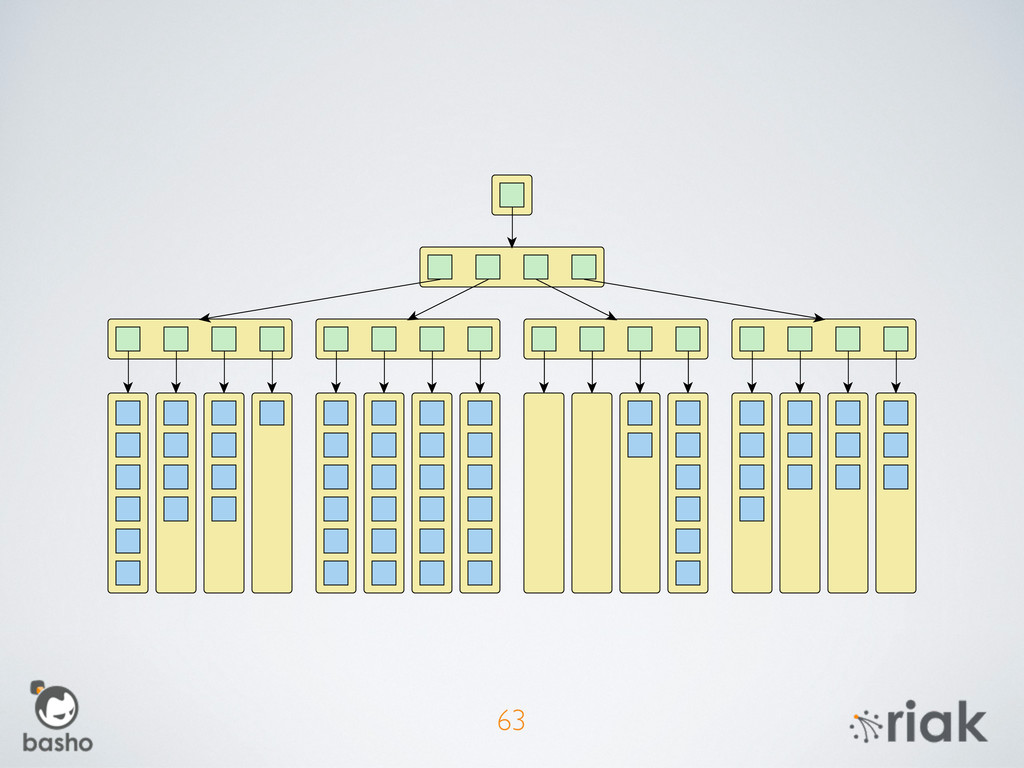{kind=link}
{kind=link}
{kind=link}
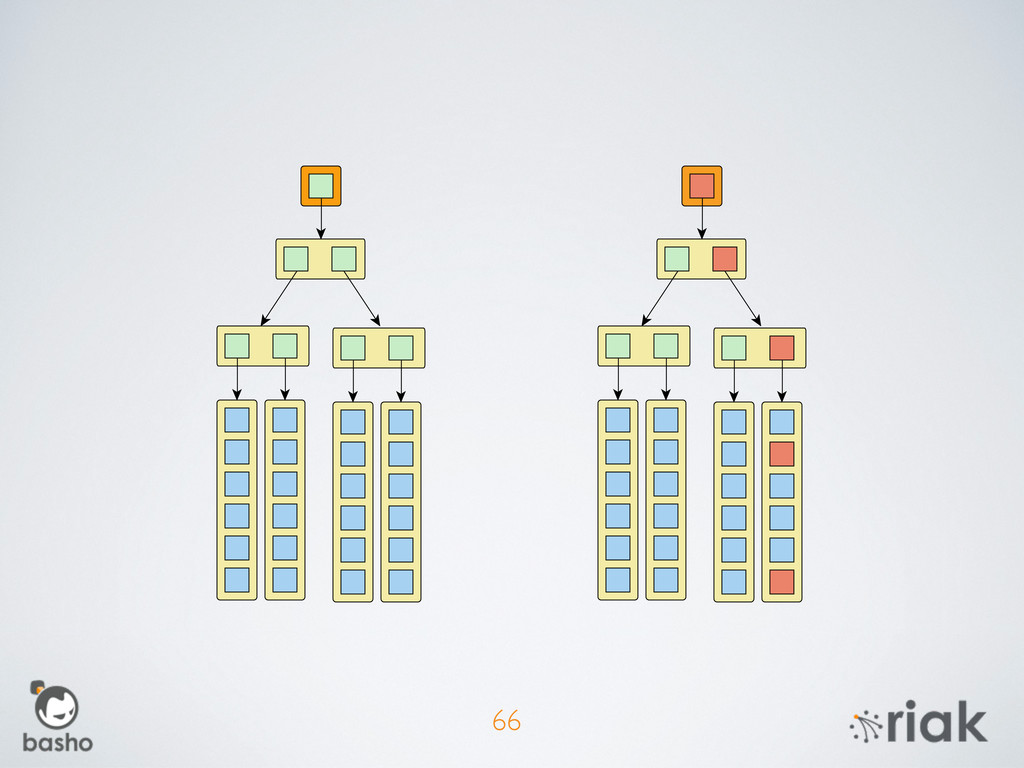{kind=link}
{kind=link}
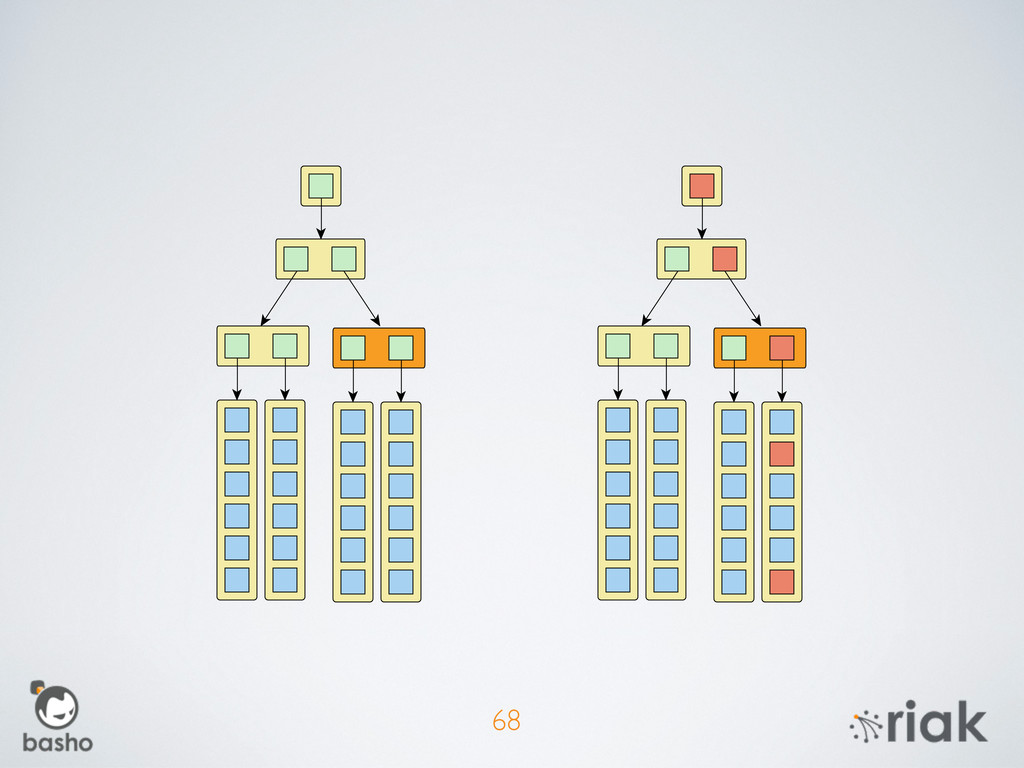{kind=link}
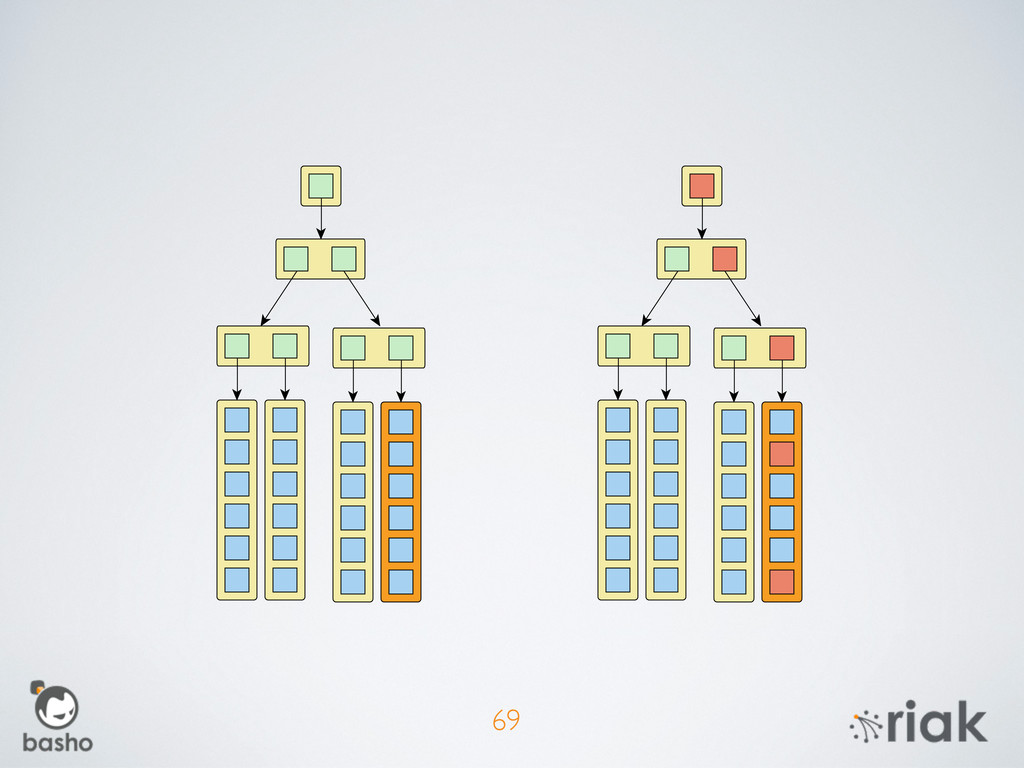{kind=link}
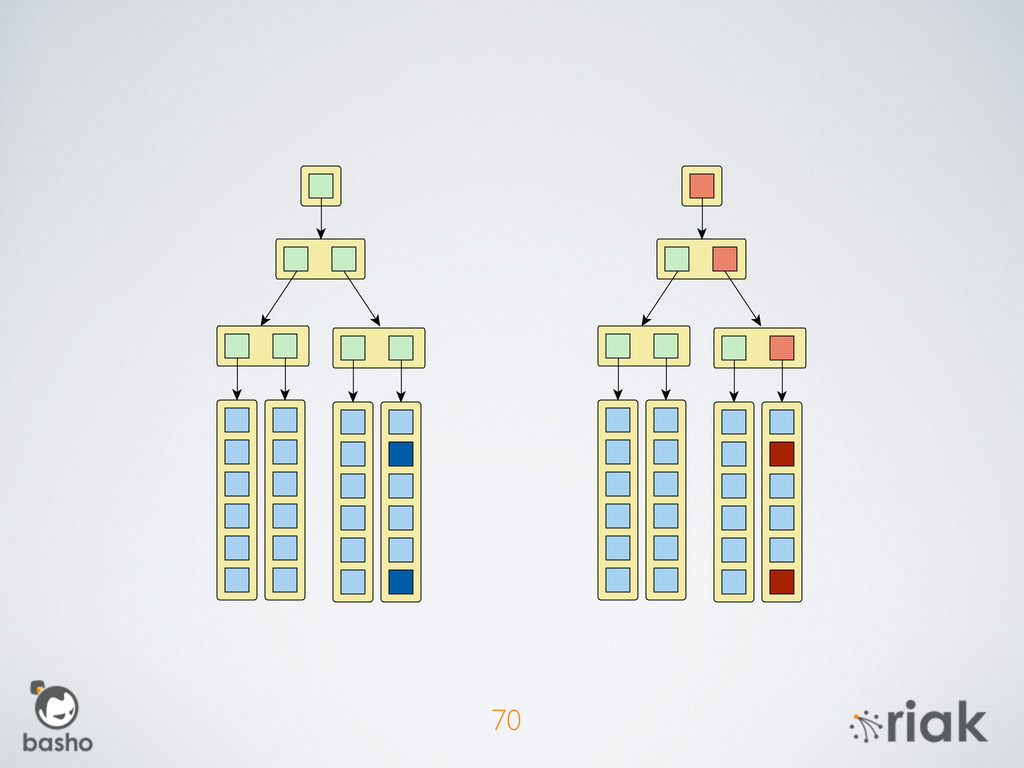{kind=link}
{kind=link}
{kind=link}
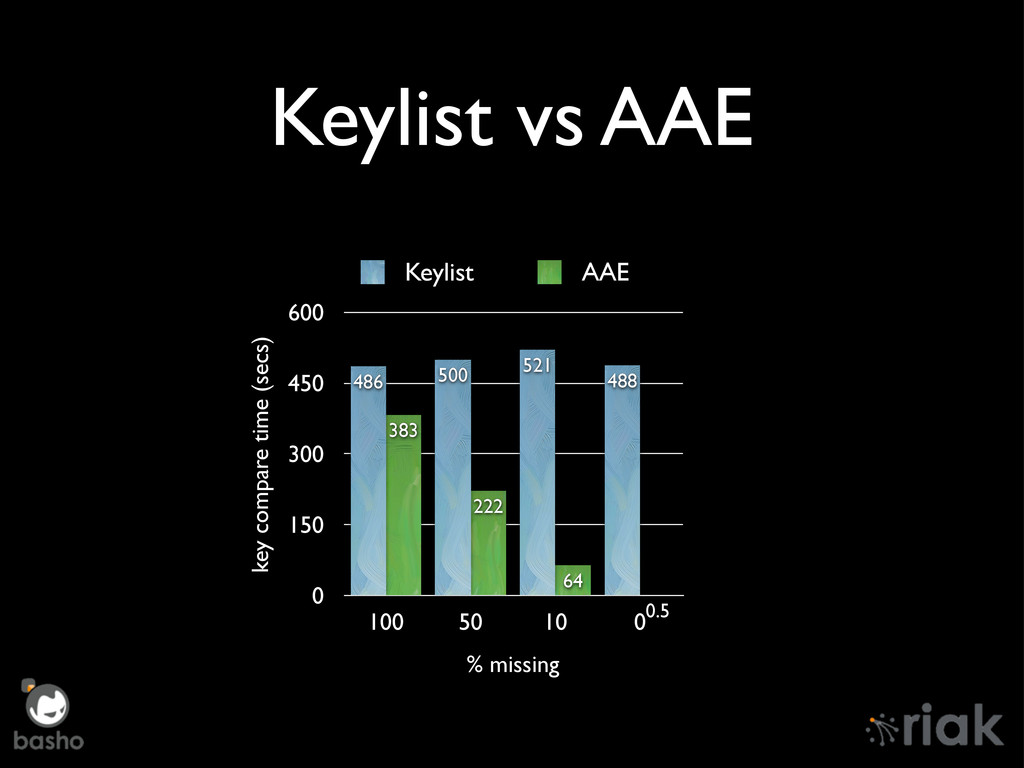{kind=link}
{kind=link}
{kind=link}
![Thanks! [email protected]](https://files.speakerdeck.com/presentations/b3611520a5590130e1123ed34b672d53/slide_75.jpg){kind=link}