Riak is a distributed, scalable, boring database. If you're looking for open source storage to support the growth of a new or existing system, there aren't many others out there that offer the durability and fault-tolerance guarantees that Riak does. That said, nothing is fool proof, every technology has tradeoffs and things will always fail.
In this talk, Basho Engineer Sean Cribbs takes a high-level look at what it takes to scale Riak in production. The keen administrator will tweak operating systems, hone networks and keep and eye out for things like TCP Incast. Sean dives into these and more, with a focus on what it takes to run Riak at scale.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RELIEF It took 20 minutes to transfer the vnode (riak@gin)7>819:34:00.5748[info]8Starting8handoff8of8partition8riak_kv_vnode8](https://files.speakerdeck.com/presentations/5065e22ce64bdf0002011215/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
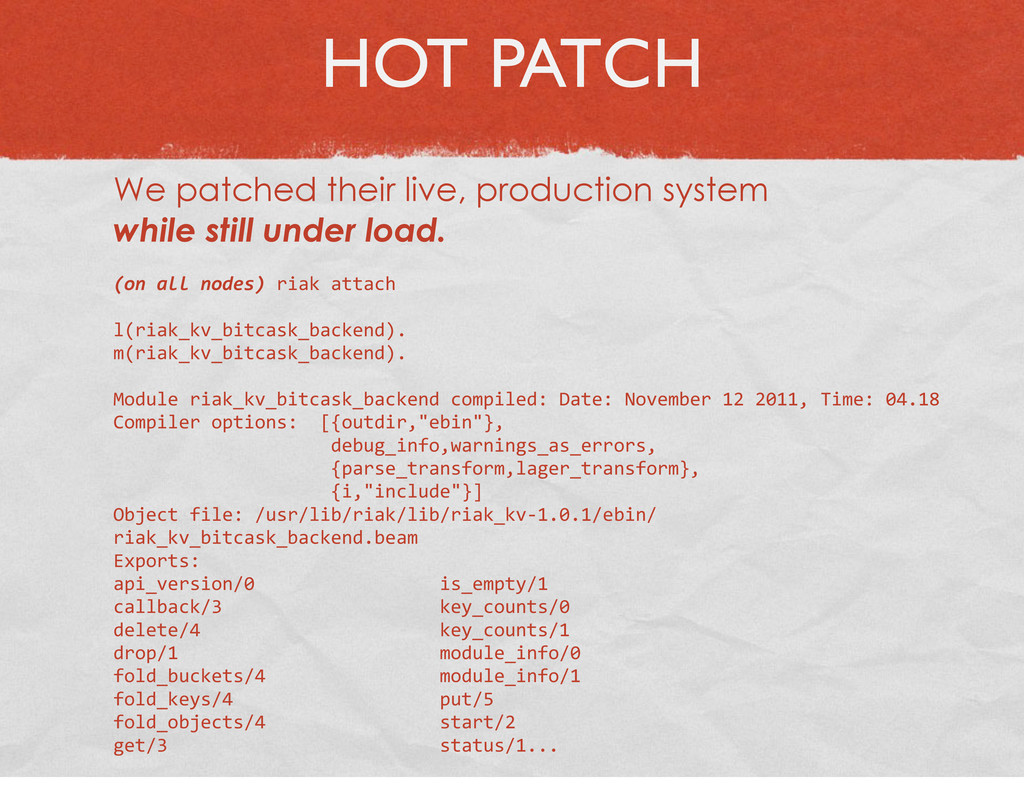{kind=link}
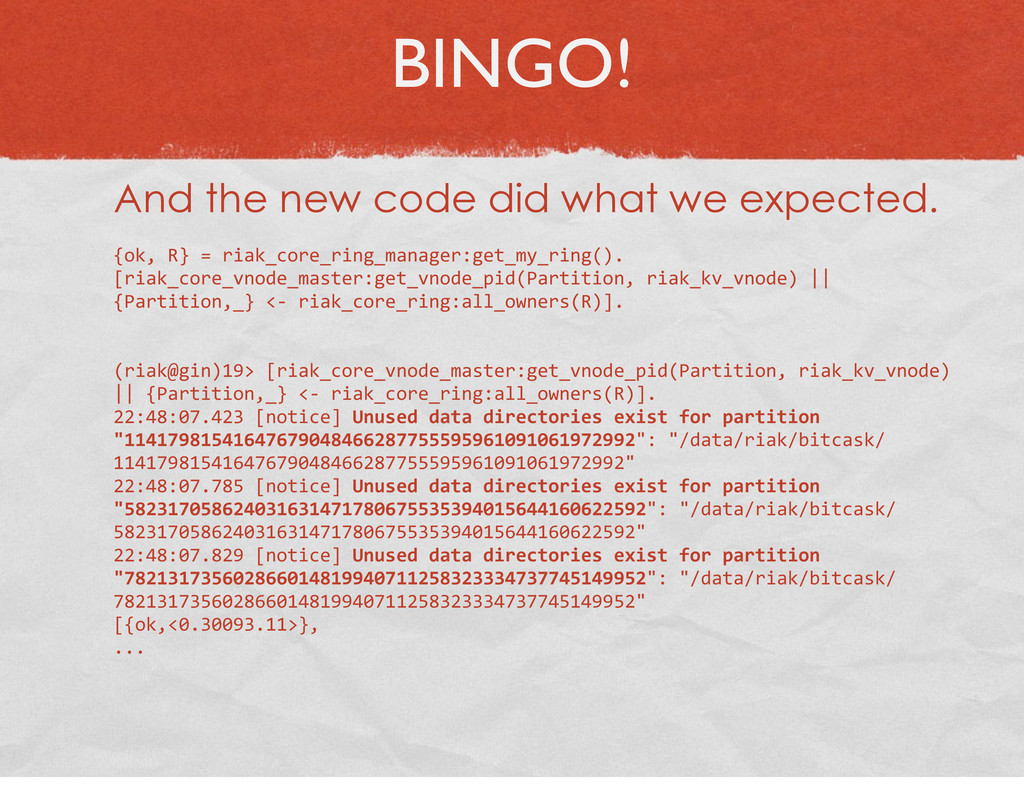{kind=link}
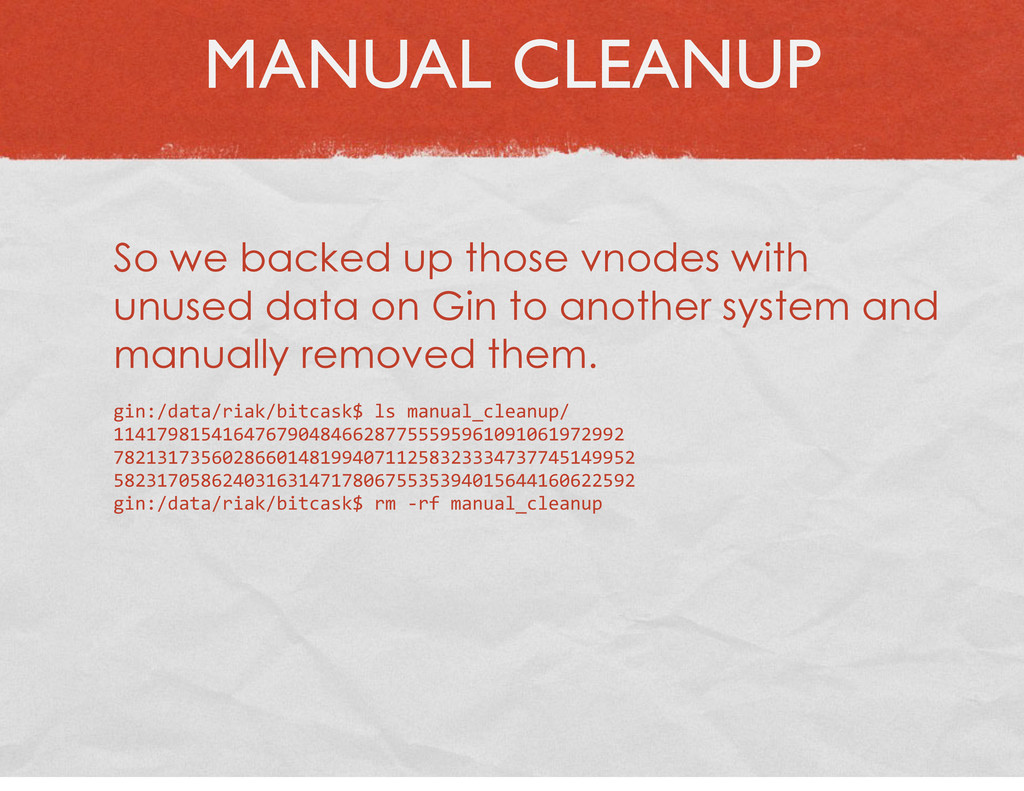{kind=link}
{kind=link}
{kind=link}
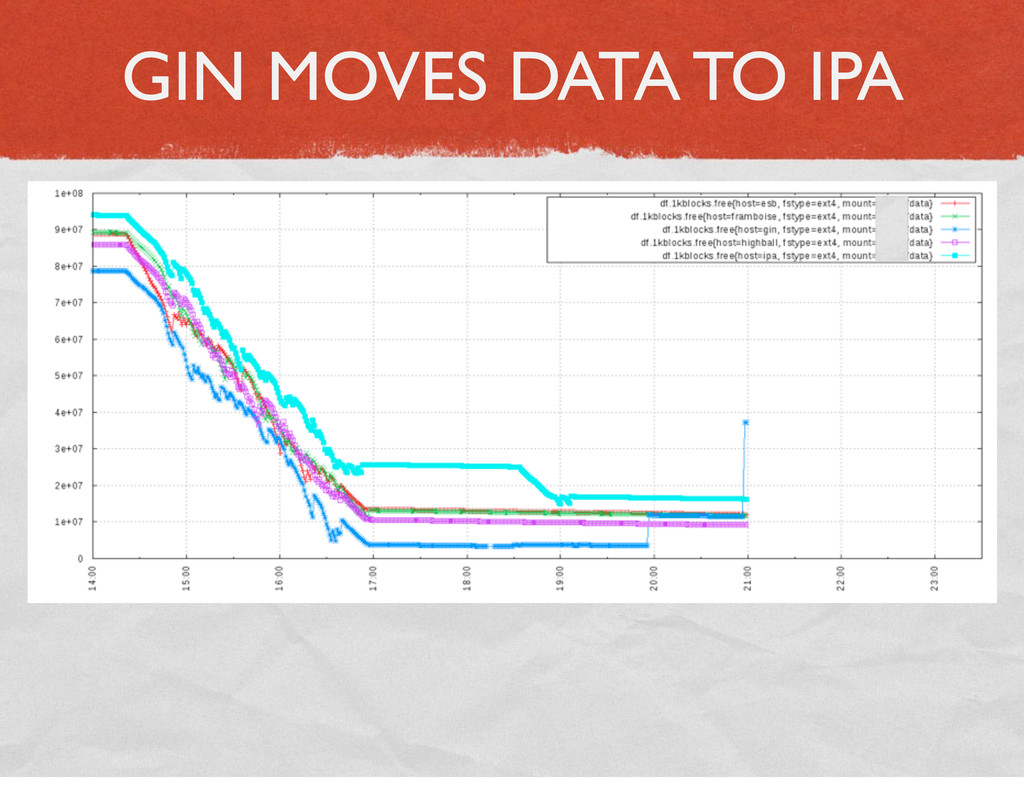{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LET’S CHECK DAT RAID 10.28.60.20888prodH04888raidH0Hb 10.28.60.21088prodH05888raidH0Hb [...] 10.28.60.22688prodH13888RAID5HB 10.28.60.22888prodH14888RAID0HB 10.28.60.23088prodH15888RAID0HB](https://files.speakerdeck.com/presentations/5065e22ce64bdf0002011215/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
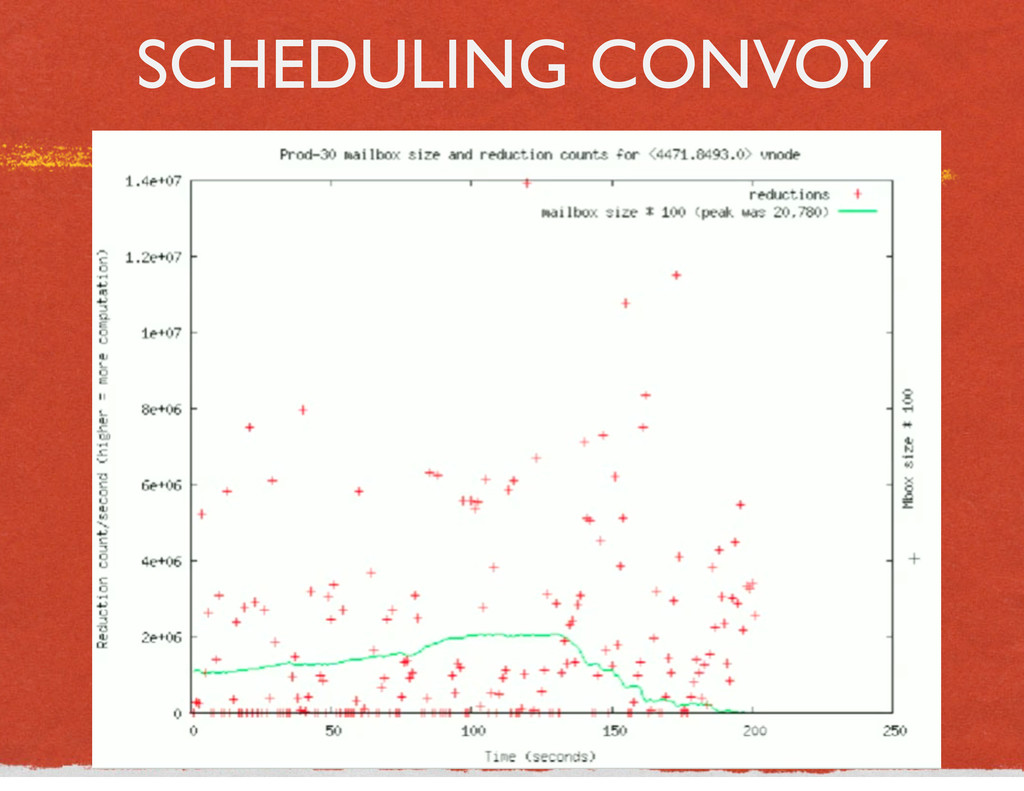{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU! [email protected] @seancribbs](https://files.speakerdeck.com/presentations/5065e22ce64bdf0002011215/slide_64.jpg){kind=link}