Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
インフラ殴り込み入門_vol1
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
y.ashida
July 18, 2020
Programming
0
170
インフラ殴り込み入門_vol1
y.ashida
July 18, 2020
Tweet
Share
Other Decks in Programming
See All in Programming
API Platformを活用したPHPによる本格的なWeb API開発 / api-platform-book-intro
ttskch
1
130
守る「だけ」の優しいEMを抜けて、 事業とチームを両方見る視点を身につけた話
maroon8021
3
780
AI Assistants for Your Angular Solutions
manfredsteyer
PRO
0
130
Angular-Apps smarter machen mit Gen AI: Lokal und offlinefähig - Hands-on Workshop!
christianliebel
PRO
0
110
Railsの気持ちを考えながらコントローラとビューを整頓する/tidying-rails-controllers-and-views-as-rails-think
moro
5
390
コーディングルールの鮮度を保ちたい / keep-fresh-go-internal-conventions
handlename
0
200
ベクトル検索のフィルタを用いた機械学習モデルとの統合 / python-meetup-fukuoka-06-vector-attr
monochromegane
2
390
CDIの誤解しがちな仕様とその対処TIPS
futokiyo
0
200
「やめとこ」がなくなった — 1月にZennを始めて22本書いた AI共創開発のリアル
atani14
0
370
maplibre-gl-layers - 地図に移動体たくさん表示したい
kekyo
PRO
0
250
AIコーディングの理想と現実 2026 | AI Coding: Expectations vs. Reality 2026
tomohisa
0
1.2k
What Spring Developers Should Know About Jakarta EE
ivargrimstad
0
210
Featured
See All Featured
Amusing Abliteration
ianozsvald
0
130
Typedesign – Prime Four
hannesfritz
42
3k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
231
22k
Un-Boring Meetings
codingconduct
0
220
A Tale of Four Properties
chriscoyier
163
24k
Test your architecture with Archunit
thirion
1
2.2k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.7k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
210
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
390
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
150
Transcript
インフラ 殴り込み入門 講師: 株式会社たたかうWEB 芦田祐希
講義の流れ 自己紹介 講義の目的 インフラ構築の全体像 インフラ構築の要件定義とは
各項目の要件定義と設計 実際のプロジェクトでは、、 書籍「インフラ設計のセオリー(※) 」の内容に沿って、 要点を絞ってインフラ構築の基礎を解説。 (※) 著:JIEC基盤エンジニアリング事業部インフラ設計研究チーム
講師について 芦田 祐希 株式会社たたかうWEB代表 (代表しかいない) •経歴 29歳まで職場を転々、フリーター。人生崖っぷちの危機感からプログラミングを勉強。 30歳は会社員SEとして経験を積んだが、あまりの給料の安さにフリーランスへ転身。
2018年33歳の時に勢いだけで株式会社たたかうWEBを創立。 現在は受託開発をしつつ人材・教育の分野に力を入れている。 •やってる仕事 システム受託開発(ディレクター・実装) 自身の得意分野はWEBアプリ(Django) SES事業(トラブルで振り出しに) プログラミングスクール(構築中)
講義の目的 アプリケーションプログラマがインフラの基礎を学ぶ。 開発の経験を積むにつれてインフラ対応の必要性 環境構築(WEBサーバー・APサーバー・データベース) パブリッククラウド(AWS) コンテナ技術(Docker) インフラまでカバーするプログラマの需要は高い。(単価が高い。)
インフラとは インフラストラクチャー(Infrastructure) 何らかのサービスを提供するために必要な土台・仕組み。 •インフラ(生活): 生活をするために必要な水道・ガス・道路・交通機関 •インフラ(システム) ECサイトを運営するために必要な ハードウェア・ネットワーク・OS・ ミドルウェア(WEBサーバー・データベース)
インフラ構築全体像 フォーターフォールを想定。 要件定義 設計 実装 試験
運用・保守 インフラ構築もアプリ開発と同じフロー。
要件定義 要件定義とは「顧客の要求を要件に落とし込む」こと。 要求 → ぼやっとした顧客の要望。 「障害時に備えたい。」 要件 → 機能・非機能含めた実現すべきシステム定義 「システムダウン時は3時間以内に復旧。」
「日次でDBデータをバックアップ。」 ・上流なので要件バグがあると手戻りコストが甚大。 ・責任はあくまでユーザー側にある。
設計 要件定義を元に設計。 インフラSEの設計範囲は ・アーキテクチャ設計 ・システム構成設計(ハード・ミドル・ソフトウェア・ネットワークやDB) ・運用設計
製造・試験 •製造 設計書を元に構築手順書を作成し、環境を構築。 OSやミドルウェア・ソフトウェアのインストール セッティング •試験 ・単体試験:サーバ単体でのOSやミドルウェアの機能試験 ・結合試験:サーバ間OS・ミドルウェア間の試験 例)アプリケーションサーバーとDBサーバー連携など ・システムテスト:業務を前提とした試験
例)ピーク時のスループットや障害発生時のプロセス確認など
機能要件・非機能要件 インフラの要件定義とは、顧客要求から非機能要件を定義すること。 機能要件 → 業務上の要件 → 開発チーム担当 「店舗からの売上データ(CSV)を管理画面で集計する。」 「決済代行会社と連携してWEBサイトに決済システムを導入する。」 ※業務を動かすための機能の定義。
非機能要件 → システム上の要件 → インフラチーム担当 「障害発生時は、3時間以内にバックアップデータからシステムを復旧する。」 「将来、ユーザーの増加に備えて性能拡張が可能な構成とする。」 ※業務の安定稼働を目的としたシステム性能の定義。
非機能要件定義の問題点 ・ユーザーにとって専門性が高く、要件を定義できない。 → 化粧品のWEB販売事業者がサーバースペックを指定してくるか? ・プロジェクトの初期段階でユーザーが関心を持ちにくい。 → ベンダも提案しづらい。 ・非機能要件は曖昧な定義になりがち。 → 「障害が発生したら、可能な限り早急に対応。」
早急に対応・・・ってどれくらい? 曖昧な定義の結果、、、 ユーザー: 障害発生時は3時間ぐらい復旧すると思ってた。 ベンダ: 早急に対応というのは1日以内ぐらいだと思ってた。 →多大な手戻りコスト
課題解決:非機能要求グレード 非機能要求グレードとは、 IPAと複数の大手企業で定義された非機能要件定義のためのツール このツールを元に、ユーザとベンダで要件定義の認識をすり合わせる。
非機能要件の分類 インフラ要件は6つのカテゴリーに分類できる。 • 可用性 システムの信頼性・安定性。どれだけ安定して稼働するか。「現在」に対する備え。 • 性能・拡張性 システムの処理性能。将来スペックの拡張がしやすいか。「将来」に対する備え。 • 運用・保守性
システムの安定稼働を目的とした運用。どのレベルで保守を行うか。 • 移行性 現行システムを開発システムに移行する際の要件。 (本講では割愛) • セキュリティ システムの安全対策などの要件。 • 環境・エコロジー システム環境の耐震、温度、騒音。地球に優しいシステムかどうか。(本講では割愛)
可用性 可用性とは・・・ システムの信頼性、障害の発生しにくさ。 障害が発生してもどれだけサービスを停止せずに済むか、影響を最小限にできるか。 可用性 4つの中項目要件 ・継続性 サービスの稼働率についての要件。 ・耐障害性 障害が発生してもサービスを停止させないようにするための要件
・耐災害性 災害が発生してもサービスを停止させないようにするための要件 ・回復性 障害が発生したときのどれだけスピーディに復旧させるかの要件
継続性 継続性・・・ サービスがどれだけ中断せず継続して稼働するか。 →稼働率を定義する。 稼働率 = (サービスが実際に利用できた時間) ➗ (サービスを提供すべき時間) 例)
・年間に5分のサービス停止のみ許容する場合 稼働率 = (8760 - 0.08) / 8760 x 100 = 99.999% ・平日8時間のサービス稼働、月間1時間のサービス停止を許容する場合 稼働率 = (1920 - 12) / 1920 x 100 = 99.4% 稼働率要求を満たすような冗長化の設計。 クラウドサービスの場合、稼働率要求を満たすようなサービスを選定。(SLA参考)
耐障害性 耐障害性・・・ 障害に対する耐性要求。 設定した稼働率に応じて、 ・どの程度冗長化するか。 ・データをどこまでバックアップするか。 → コスト・予算との兼ね合いで折り合いを付ける。
耐災害性 耐災害性・・・ 災害が発生したときのシステムの継続性。 ・事業継続計画や災害復旧計画などのマニュアルの作成 ・遠隔地サーバに全く同じシステムを構築 ・遠隔地へデータのバックアップ →コスト大 東日本大震災より、耐災害性を重視する風潮。
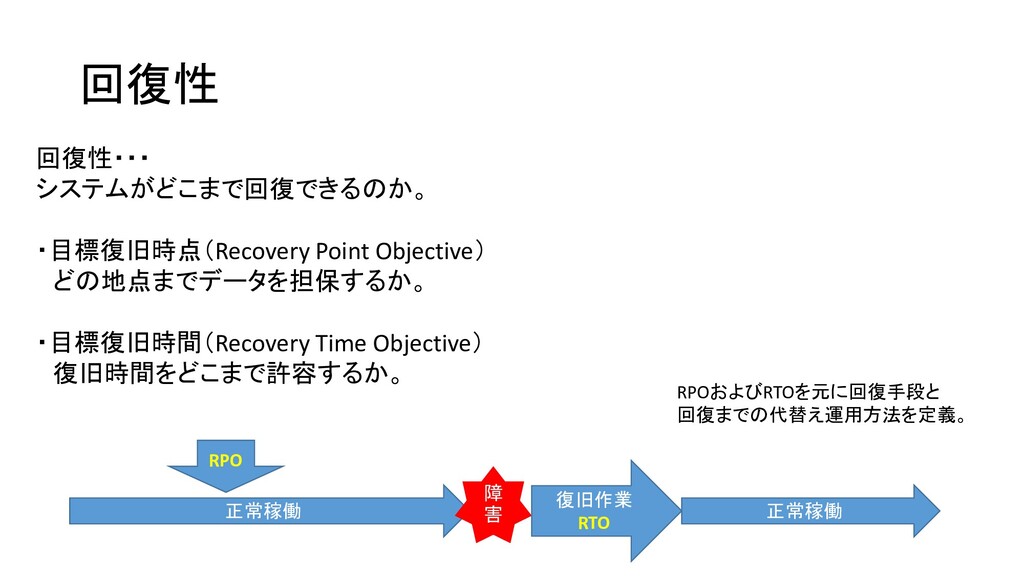
回復性 回復性・・・ システムがどこまで回復できるのか。 ・目標復旧時点(Recovery Point Objective) どの地点までデータを担保するか。 ・目標復旧時間(Recovery Time Objective)
復旧時間をどこまで許容するか。 正常稼働 障 害 復旧作業 RTO 正常稼働 RPO RPOおよびRTOを元に回復手段と 回復までの代替え運用方法を定義。
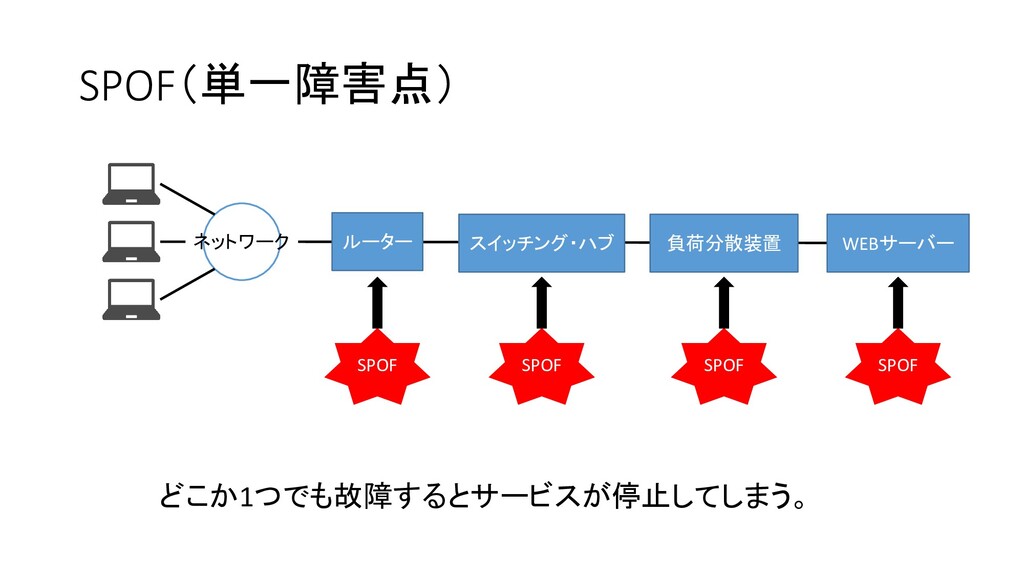
可用性設計のセオリー 耐障害設計を行う。 基本的考え方 SPOFの排除! SPOFとは・・・ 単一障害点(Single Point Of Failure)のこと。 そこで障害が起こるとサービスが止まってしまうネックポイントのこと。
SPOF(単一障害点) ネットワーク ルーター スイッチング・ハブ 負荷分散装置 WEBサーバー SPOF SPOF SPOF SPOF
どこか1つでも故障するとサービスが停止してしまう。
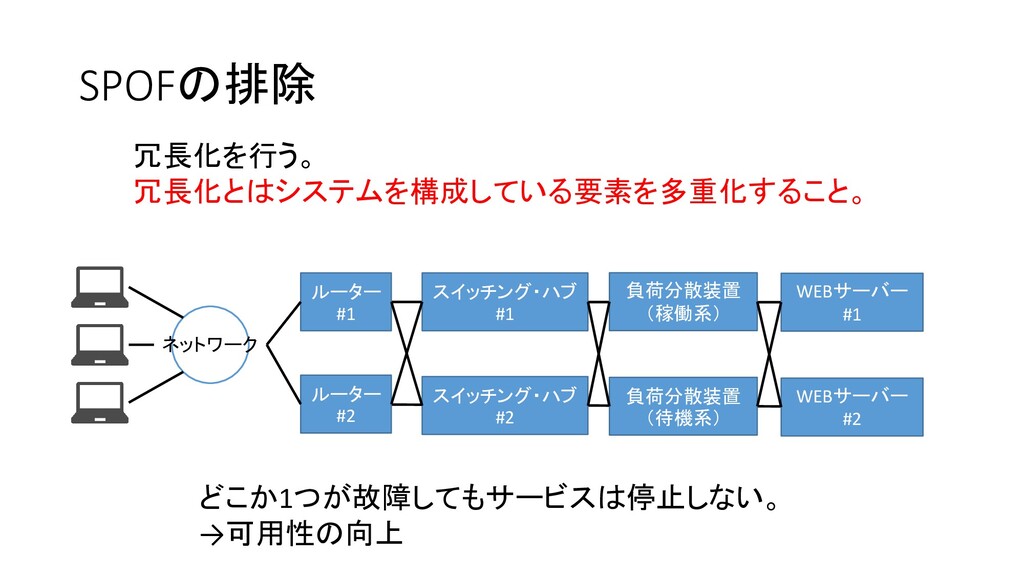
SPOFの排除 ネットワーク ルーター #1 スイッチング・ハブ #1 負荷分散装置 (稼働系) WEBサーバー #1
ルーター #2 スイッチング・ハブ #2 負荷分散装置 (待機系) WEBサーバー #2 どこか1つが故障してもサービスは停止しない。 →可用性の向上 冗長化を行う。 冗長化とはシステムを構成している要素を多重化すること。
冗長化の例 ・サーバー内ハードウェアの冗長化 電源ユニット・ネットワークアダプタ・ストレージ(RAID構成) ・サーバーの冗長化 ・並列クラスタ ・HAクラスタ
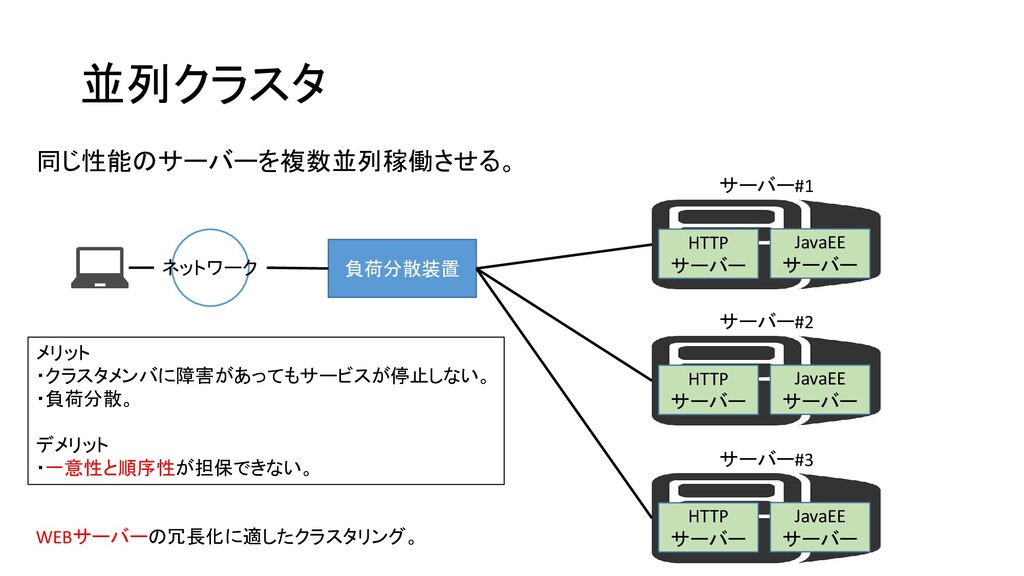
クラスタリング クラスタリングとは・・・ サーバーの冗長化を行うこと。 並列クラスタ: 複数のサーバー(クラスタメンバ)を並列稼働(同時稼働)する。 HAクラスタ: 稼働系サーバーと待機系サーバーで構成する。
並列クラスタ 同じ性能のサーバーを複数並列稼働させる。 ネットワーク 負荷分散装置 HTTP サーバー JavaEE サーバー サーバー#1 HTTP
サーバー JavaEE サーバー サーバー#2 HTTP サーバー JavaEE サーバー サーバー#3 メリット ・クラスタメンバに障害があってもサービスが停止しない。 ・負荷分散。 デメリット ・一意性と順序性が担保できない。 WEBサーバーの冗長化に適したクラスタリング。
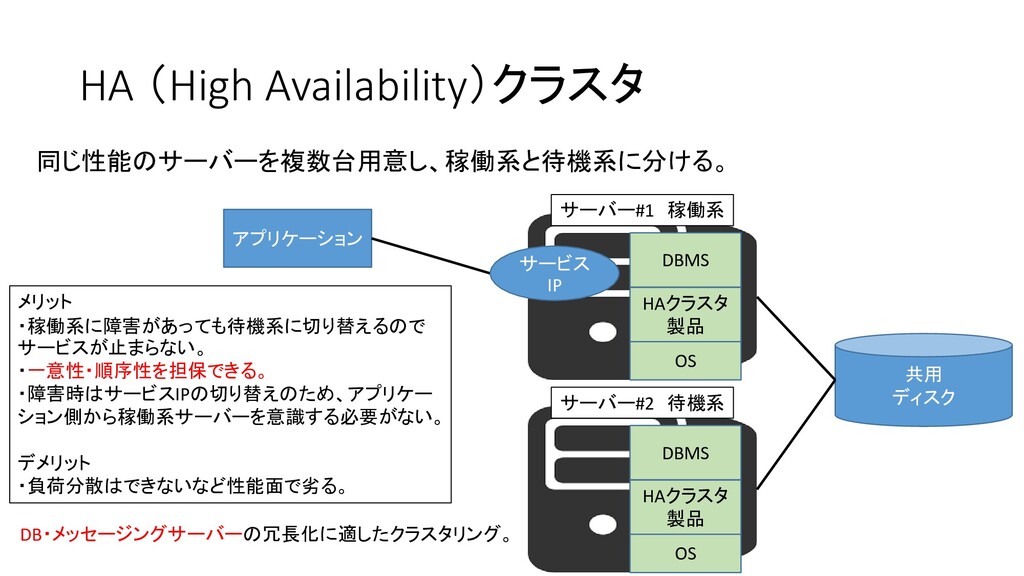
HA (High Availability)クラスタ 同じ性能のサーバーを複数台用意し、稼働系と待機系に分ける。 アプリケーション メリット ・稼働系に障害があっても待機系に切り替えるので サービスが止まらない。 ・一意性・順序性を担保できる。 ・障害時はサービスIPの切り替えのため、アプリケー
ション側から稼働系サーバーを意識する必要がない。 デメリット ・負荷分散はできないなど性能面で劣る。 DB・メッセージングサーバーの冗長化に適したクラスタリング。 サーバー#1 稼働系 OS HAクラスタ 製品 DBMS サービス IP サーバー#2 待機系 OS HAクラスタ 製品 DBMS 共用 ディスク
可用性 まとめ •要件定義 稼働率 冗長化 バックアップ •設計 単一障害点(SPOF)を潰す。 冗長化 ハードウェア:
電源ユニット・ネットワークアダプタ・ストレージ(RAID) サーバー: 並列クラスタ: WEBサーバー HAクラスタ: DBサーバー・メッセージングサーバー
性能・拡張性 性能:システムのパフォーマンス。 拡張性:将来的にシステムを増強できるかどうか。 可用性 → 現在進行系の今に対する備え(耐障害性、継続性) 性能・拡張性 → 将来的なシステム負荷増加など未来に対する備え(どれだけ柔軟に性能増強できる か)
性能・拡張性 性能・拡張性 4つの中項目要件 ・業務処理量 ユーザー利用数と実際の業務で発生するデータ処理量(通常時・ピーク時)を定義。 ・性能目標値 業務処理量を元に目標レスポンステイムやスループットを定義。 ・リソース拡張性 業務処理量の増加予測を元に将来的スペック増強に対する備えを定義。 ・性能品質保証
本書では割愛。
業務処理量 性能検討する上で必須の情報。以下のような情報を予測し、定義。 ・同時接続ユーザー数 ある一定のタイミングの時間帯に集中アクセスしてくる利用者数。 例)ユーザー数のうち1%を想定し、10名。 ※ピーク時も定義すること。 ・データ量 マスターデータ、トランザクションデータ、ログデータなどのデータ量 例)1日の新規起票数はユーザー数の10%程度と想定。 →
100レコード前後のInsertか。 ・オンラインリクエスト数 単位時間あたりリクエスト数 ・バッチ処理件数 単位時間あたりバッチ処理件数
性能目標値 業務処理量を元に目標レスポンスタイムやスループットを定義。 例) ・Aバッチ処理時間は1時間以内とする。 ・B処理のレスポンスタイムは5秒以内とする。
リソース拡張性 業務処理量の増加予測を元に将来的スペック増強に対する備えを定義。 例) 3年後にはシステム利用ユーザー数が2倍になることを見据え、 拡張性の高いCPU・メモリ・ストレージ製品を選定する。
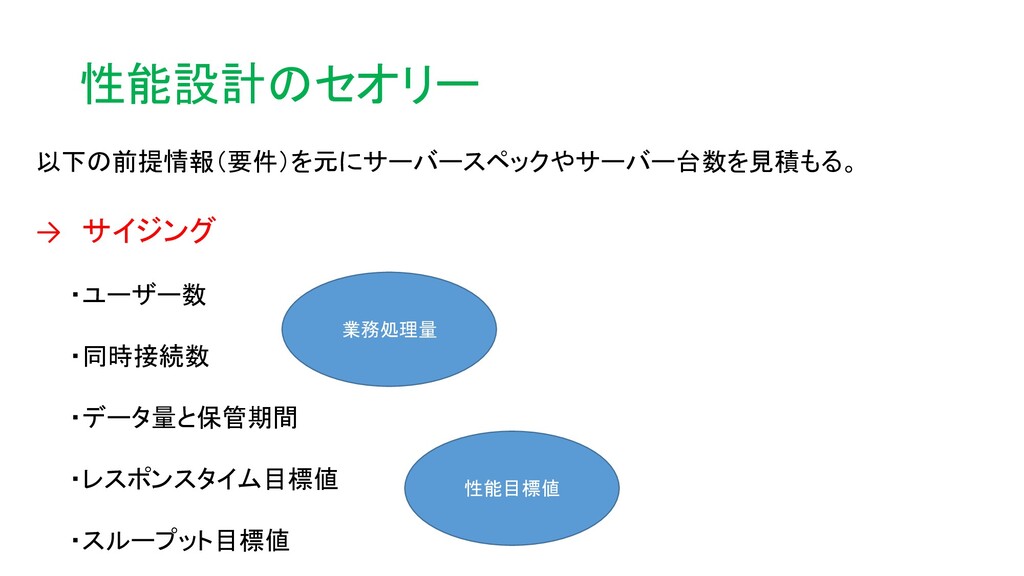
性能設計のセオリー 以下の前提情報(要件)を元にサーバースペックやサーバー台数を見積もる。 → サイジング ・ユーザー数 ・同時接続数 ・データ量と保管期間 ・レスポンスタイム目標値 ・スループット目標値 業務処理量
性能目標値
サイジングの注意点 必要なリソースはアプリケーションを動かしてみないとわからないため、高精度の見積もり はできない。 そのため、 1、安全率をかけておく 見積もりスペックに安全率(1.2~1.5)をかけた値を設定する。 2、テストフェーズで調整
CPU・メモリの選定 ・利用する製品の推奨スペックの確認。 ・CPUメーカーのベンチマーク値を確認。 ・必要なCPUコア数 シングルコアで充分なバッチ処理など。 仮想化ソフトを利用する場合はデュアル以上など。 ・既存システムのCPU使用率、メモリ使用率の確認
ヒープ領域の設定 ヒープ領域とは・・・ アプリケーションが利用することのできるメモリ領域(容量)。 メモリ不足によるプロセスダウンはサービス停止に繋がりかねない。 しかしアプリケーションを動かすまで実際必要なヒープ領域は分からない。 →概算で見積もっておき、テストフェーズで調整。テストを重点的に! ヒープサイズを大きくしておけば?? ガベージコレクション(APサーバー)はヒープサイズに応じて処理時間が増大する。
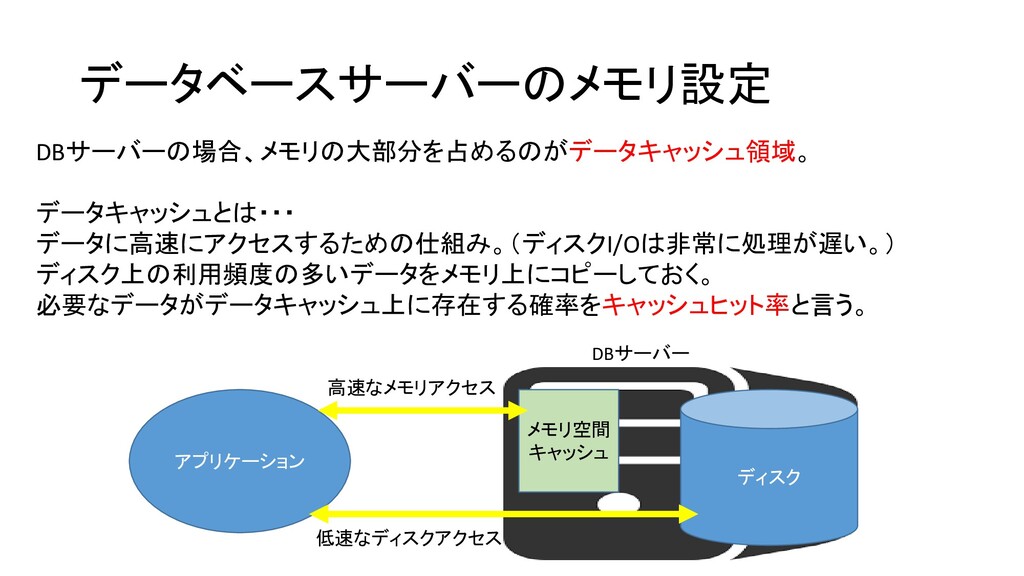
データベースサーバーのメモリ設定 DBサーバーの場合、メモリの大部分を占めるのがデータキャッシュ領域。 データキャッシュとは・・・ データに高速にアクセスするための仕組み。(ディスクI/Oは非常に処理が遅い。) ディスク上の利用頻度の多いデータをメモリ上にコピーしておく。 必要なデータがデータキャッシュ上に存在する確率をキャッシュヒット率と言う。 アプリケーション メモリ空間 キャッシュ DBサーバー
ディスク 高速なメモリアクセス 低速なディスクアクセス
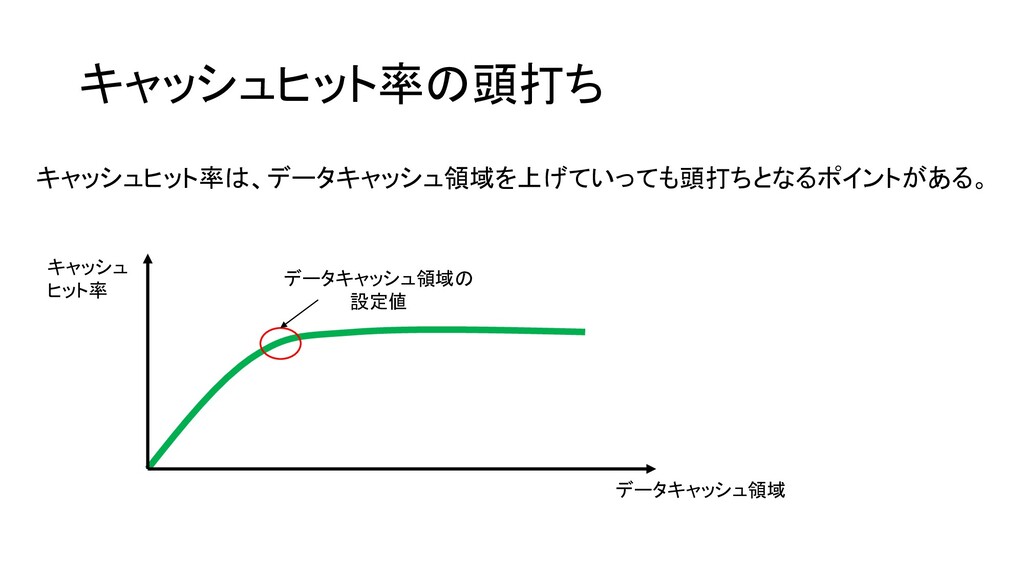
キャッシュヒット率の頭打ち キャッシュヒット率は、データキャッシュ領域を上げていっても頭打ちとなるポイントがある。 キャッシュ ヒット率 データキャッシュ領域 データキャッシュ領域の 設定値
拡張性設計のセオリー 拡張性を確保する。 ↓ スケールアップ・スケールアウトできるようにしておく。 スケールアップとは・・・ スペックを増強すること。 例)メモリ:8GB → 16GB ストレージ:HDD256GB
→ 512GB スケールアウトとは・・・ サーバーを増やすこと = 冗長化 例)WEBサーバー1台 → WEBサーバー2台
拡張性の確保 サーバーやハードウェア製品によってはメモリやストレージの増設に対応していないもの があるので選定時に注意すること。(オンプレミスの場合) 仮想サーバーであれば基本拡張可能。 しかし、場合によってはシステムを停止する必要あり。
スケールアップかスケールアウトか ・クラスタリングとの適性 並列クラスタ: スケールアウト・スケールアップどちらでも拡張可能 HAクラスタ: スケールアップでのみ拡張可能 ・コスト面 スケールアウトで物理サーバーを増やす場合はスケールアウトに比べ圧倒的にコスト大。 ただし、仮想化技術の進歩でスケールアウトのコストも大幅に低下している。 ・問題の内容
例えばディスクI/Oがボトルネックとなる場合、 スケールアップでの改善は見込めないため必然的にスケールアウトで対応する。
拡張例:レスポンスの悪化 システム運用開始後、しばらくしてレスポンスが悪くなってきたケース。 •調査ポイント ・業務処理量の観点 → ユーザー数の急激な増加はないか? ・性能の観点 → ヒープサイズ使用率が限界ではないか? →
データキャッシュヒット率は高い数値で安定しているか? → ディスクI/Oが問題になってないか? ・ネットワークの観点 → 転送速度に問題ないか?
拡張例:レスポンスの悪化 ・CPU・メモリがボトルネックの場合 まずはスケールアップで対応。 上限値でも解決しない場合はスケールアウト。 ・ヒープサイズに問題がある場合 ヒープサイズ拡張。 ただし、 OSの使用メモリ + ヒープサイズ
< 物理メモリ となること。 逆転するとOSのページング(スワップアウトの1種)が生じ、処理速度低下。 ・データキャッシュ率が低下している場合 データキャッシュ領域の拡張。ただし、上記のように限界値に注意。 ・ネットワーク転送速度の問題の場合 帯域の拡張検討。
拡張例:レスポンスの悪化 ・ディスクI/Oボトルネックの場合 ディスクI/Oはスケールアップでは改善が難しい性質。 →スケールアウトで対応。 ただし、データベースのディスクI/Oボトルネックの場合は DBサーバーはスケールアウトによる冗長化は不向き(一意性が担保できない)なので、 SQL改修・実行計画の改善で対応する。 ただし、参照系のみのクエリであれば冗長化可能。
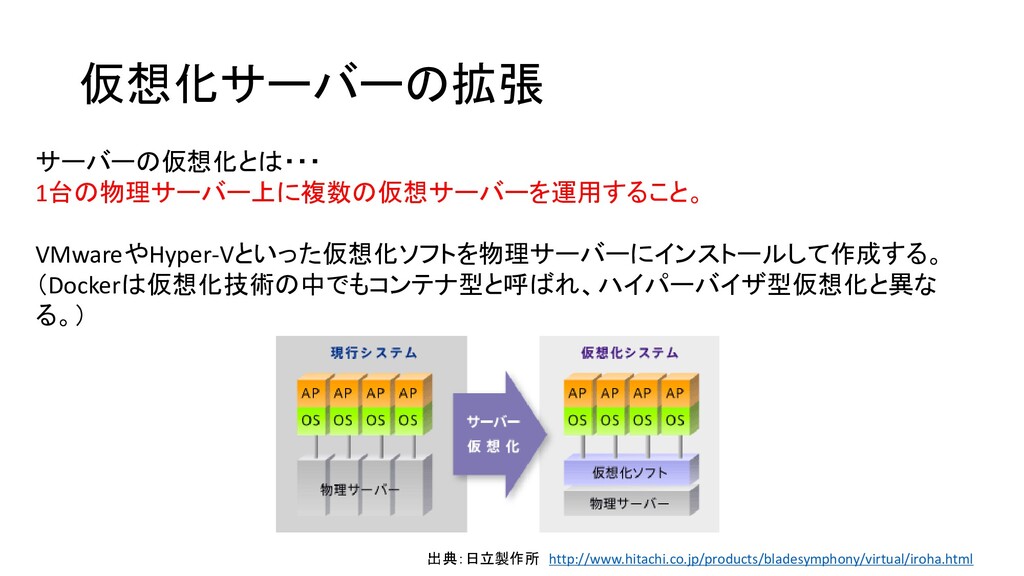
仮想化サーバーの拡張 サーバーの仮想化とは・・・ 1台の物理サーバー上に複数の仮想サーバーを運用すること。 VMwareやHyper-Vといった仮想化ソフトを物理サーバーにインストールして作成する。 (Dockerは仮想化技術の中でもコンテナ型と呼ばれ、ハイパーバイザ型仮想化と異な る。) 出典:日立製作所 http://www.hitachi.co.jp/products/bladesymphony/virtual/iroha.html
仮想化のメリット・デメリット メリット: ・物理サーバーが少ないためコスト減・管理が簡素。 ・リソースを有効活用できる。 仮想サーバーの場合、余っているリソースを他の仮想サーバーに割り当てられる。 ・古いOS・ソフトの延命ができる。 物理サーバーのOSは更新しつつ、仮想環境上のサーバーは古いバージョンを維持し続 けられる。 デメリット: ・物理サーバーを含めた耐障害設計が複雑になる。
仮想化サーバーの拡張性 設計は前述の考え方と変わらない。 拡張方法が異なる。 サーバー定義ファイルを修正、複製し、再起動するだけでスケールアウト・スケールアップ が可能。 従来に比べ拡張が圧倒的に簡単。
性能・拡張性 まとめ •要件定義 ・業務処理量 同時接続数・データ量・リクエスト数など ・性能目標値 レスポンスタイム・スループット •設計 業務処理量、性能目標値からCPU等のサイジング(性能設計) ヒープ領域・データキャッシュ領域(性能設計)
スケールアップ・スケールアウト(拡張設計)
運用・保守性 運用とは・・・ 日々システムを動かしていくこと。 監視・バックアップなど 保守とは・・・ システムに変更を加えていくこと。 DBチューニング・機器リプレース・バグ改修など
運用・保守性 運用・保守性 6つの中項目要件 ・通常運用 ・保守運用 ・障害時運用 ・運用環境 ・サポート環境 ・その他の運用管理方針
通常運用 通常時のシステム運用方法を定義。 定義項目は以下。 ・通常運用時間 システムの利用可能な時間は? → ユーザー目線・管理者目線 ・監視運用 障害発生の早期発見のため必要。 どうやって監視する?
→ どのログをどのレベルで監視する? ・バックアップ運用 バックアップの頻度と世代
保守運用 システムに変更を加えるときの運用方法を定義。 定義項目は以下。 ・パッチ適用方針 すべて当てる?部分的?当てない? アプリへの影響リスク ・パッチ適用タイミング 即時?定期保守時?障害発生時のみ? など。。
障害発生時運用 障害発生時の運用方法を定義。 障害の起こらないシステムは存在しない。 定義項目は以下。 ・復旧作業 復旧作業と復旧作業中の代替え運用を定義。 ・システム異常検知時の対応 24365対応?何人待機? 体制の定義 →
コストとの兼ね合い
運用・保守性設計のセオリー まず最初に「ユーザー向けシステム運用時間」を設定する。 →他の項目に与える影響が大きいため。 例えば、 ・バックアップの取得は通常は運用時間外。 運用停止時間によってバックアップ取得にかけられる時間が制限される。 ・エラー検知時、運用時間内であれば即時対応が必要。 運用時間外であれば翌日の対応でも問題ないことも。 運用時間・バックアップ・監視 について設計する。
システム運用時間設定時の注意 ・運用時間の異なる特別な日は存在するのか? 例)日曜日だけは運用時間を短縮する、など。 ・特別日の定義は年度ごとに差異が無い定義が望ましい。 第一日曜日 → どの年度でも特定できる。 ゴールデンウィーク → 年度によって特定が難しい。→実装が困難。
・運用時間外のリクエストはどう処理する? 一般的にはSorryページを表示。 指定時間になったら表示ページを切り替える実装が必要。
システム停止時間 システム停止時間はシステムがダウンしている時間。 サービス停止時間・システム運用時間外とは異なる。 システム停止時間中に実行すること。 ・セキュリティパッチ適用 ・ハードウェアの保守 ・データメンテナンス など、システムを停止しないと実行できない作業。
システム停止の検討事項 ・計画停止 ユーザーへの事前告知は必要か? システム運用時間外の計画停止であれば告知不要。 ただし、メンテナンス中ページは必要。 ・停止する時間帯に本来行うはずだった処理の洗い出し バッチ処理 → 代替手段の検討 外部連携
→ データ連携時間を変更してもらうなど。
バックアップ 問題発生時の保険。極めて重要。 ・どのデータを ・どの頻度で ・どの世代まで ・どれぐらいの間 バックアップするか。 手厚くするほどコストが増大。 頻度を強化 →
サーバーの処理コスト&データ量増大 世代・保管期間を強化 → データ量増大 ※正常時ログと障害時ログを比較したりするので、 ログは最低1ヶ月、できれば3ヶ月は保持したい。
バックアップの世代 要件定義時に世代の設定をしておくこと。 例) 日次のバックアップ取得で、3世代 → 3日前までのデータに戻せる。
システム監視 監視の目的: システムが正しく稼働しているかを継続的に確認する。 「故障しない機械は存在しない」 →監視の必要性。 インフラとして監視する項目: ・プロセス監視 ・メッセージ監視 ・リソース監視 ・ハードウェア監視
・ジョブ監視 監視は一般的にZabbixなどの監視ソフトを導入して行う。独自実装はコスト大。
プロセス監視 WEBサービスであれば最低でも ・WEBサーバー(httpプロセス) ・アプリケーションサーバー(Javaプロセスなど) 他にもインストールしたソフトや独自実装のプロセスなど。
メッセージ監視(ログ監視) ログ内の特定文字列を検知する。 例えば、以下のように検知対象文字列を定義する。 メッセージコード:AAA121 メッセージ:500エラーが発生しました。 この場合、ログ内に「 AAA121 」や「500エラーが発生しました。」という文字列が出現すると、 指定の処理(アラートメール送信など)を自動で行うことができる。 ただ、システム的に問題のないエラーメッセージを拾ってしまったり、
逆にメッセージを絞り込みすぎると対応の必要なエラーを見落としたりと、設定が難しい。 →ある程度の大枠を監視対象としておき、後々不要なメッセージを消していくのが良策。
リソース監視 CPU、メモリ、ストレージ等の使用のされ方を監視する。 一般的には使用率を監視。 ただし、一時的にユーザーが集中した場合、瞬間的に使用率が上昇し、 こういった場合はアラートにしたくない。 →「CPU使用率が•%以上を•回連続して検出した」のように、 慢性的な高使用率に絞り込む。 慢性的な高い使用率はリソースの拡張を検討する必要がある。
ハードウェア監視 ハードウェアの故障は大抵ログに吐かれるのでログのエラーを監視する。 ただし、ハードウェア自体がダウンするとログが出力されないため、 ハードウェア自体の死活監視も必要。
ジョブ監視(バッチ処理監視) ジョブ監視の2つの目的。 ・すべてのバッチ処理が正常に終了しているかどうかを監視。 →たいてい、処理エラーとなると後続のバッチがコケるため。 ・処理の遅延を監視。 →エラーが無くとも、後続バッチの処理開始までに処理が完了しないと後続のバッチが コケるため。 ※エラーの有無に加えてスケジュールも通りかどうかも監視が必要。
システム運用の自動化 運用周りの作業を自動化する。 → コマンド群をシェルスクリプトにまとめるなど。 自動化のメリット: ・人的コストの削減。 ・人的ミスの排除。 自動化のデメリット: ・実装コストがかかる。 自動化対象の一般例:
・ソフトの起動・停止 ・バックアップの取得 ・タスクの実行
バックアップ自動化の注意 処理エラーとなることが大変多い。 以下のように失敗となる要因が多いため。 ・ハードウェアの故障 ・メディアの経年劣化 ・リソース不足 ・アプリケーションの割り込み など。。 バックアップの連続エラー時にシステム障害が発生すると大惨事。 →必ず自動化処理の最後に完了確認を組み込み、
完了メッセージが表示されない場合はアラート送信をするようにする。
運用・保守性 まとめ •要件定義 ・運用時間 ・バックアップ運用 ・監視運用 •設計 まず運用時間の設計 そして ・バックアップ設計
頻度・世代・保管期間 ・監視設計 プロセス・メッセージ・リソース・ハードウェア・ジョブ 運用の自動化
移行性 現行システムから新システムへのデータ移行に関する要求を定義。 本番データを扱うため、ユーザーが決定する項目が多く、インフラSEが設計する部分が少 ない。 ・移行時期 ・移行方式 ・移行対象 →ユーザーが決定する。
セキュリティ設計のセオリー セキュリティ要件: ・識別と認証 ・暗号化 ・通信制御 ・監視・監査 ・セキュリティリスク管理 ・ウィルス・マルウェア対策 セキュリティの脅威: ・情報漏えい
・データの改ざん・破壊 ・業務サービス停止
識別と認証 識別と認証の脅威:なりすまし 識別とは・・・ ある一個人が誰なのか一意に特定すること。 95%の確立でAさんだろうという推測も識別に含まれる。 識別のための情報:メールアドレス、名前 認証とは・・・ 当該人物が本人であるかどうか証明すること。 100%その人だと証明できなくてはならない。 認証のための情報:パスワード、顔認証
識別と認証 4つのなりますまし対策: ・ユーザーID管理 ・パスワード管理 ・認証 ・証明書
ユーザーID管理 ・使用されなくなったID(退職)などは無効化や削除する。 → 残しておくと悪用のリスク。 ・複数回認証失敗で認証拒否 → 例)3回連続でログイン認証失敗の場合、10分間ログイン不可 → ブルートフォースアタックにも有効 ・ユーザーごとに適切な権限設定
→ 例)Aさんには管理者権限があるが、Bさんは参照権限のみ。
パスワード管理 ・パスワードの定期的な変更 ・パスワードポリシー パスワードの複雑性 過去パスワードの使用禁止 など
認証 ・ID/パスワード認証 IPアドレス制限や電子証明書と組み合わせ可能。 ・バイオメトリックス認証 顔認証、指紋認証など 精度が高くない&装置の導入が必要。 ・ワンタイムパスワード 装置の導入が必要。
証明書 WEBサイトのなりすまし:フィッシング詐欺 サーバー証明書: 「そのサーバーは本物の〇社が運営している」という第3者期間が発行した電子証明書。 SSLの仕組みで利用されている。
暗号化 暗号化の脅威:情報漏えい 対策項目: ・PC対策 ・ネットワーク対策 ・サーバ対策 ・人・ルールに関する内部対策
暗号化 PC対策 不正閲覧対策: ・機密データをそもそも端末に保存しない。 ・ファイルの暗号化。 社外持ち出し対策: ・ハードディスク全体を暗号化。(PC紛失・盗難対策) 電子メール対策: ・電子署名と本文の暗号化。
暗号化 ネットワーク対策 VPN(Virtual Pravate Network) 送信内容を暗号化。 専用線より安全性は劣るがコストが低い。 無線LAN 通信内容を暗号化。 無線LANの暗号化方式:WPA2
暗号化 サーバー対策 外部からの攻撃に備える。 ・ファイルのコピーガード。 ・リムーバルディスクへのコピー制限。
暗号化 人・ルールによる内部対策 ・機密情報の管理責任者。持ち出す場合は許可を。 ・電子メールの添付ファイルをパスワードロック。パスワードは別メールで送信。 など
通信制御 通信制御の脅威: ・外部からの不正侵入 ・Dos攻撃 対策: ・ファイアウォール ・WAF
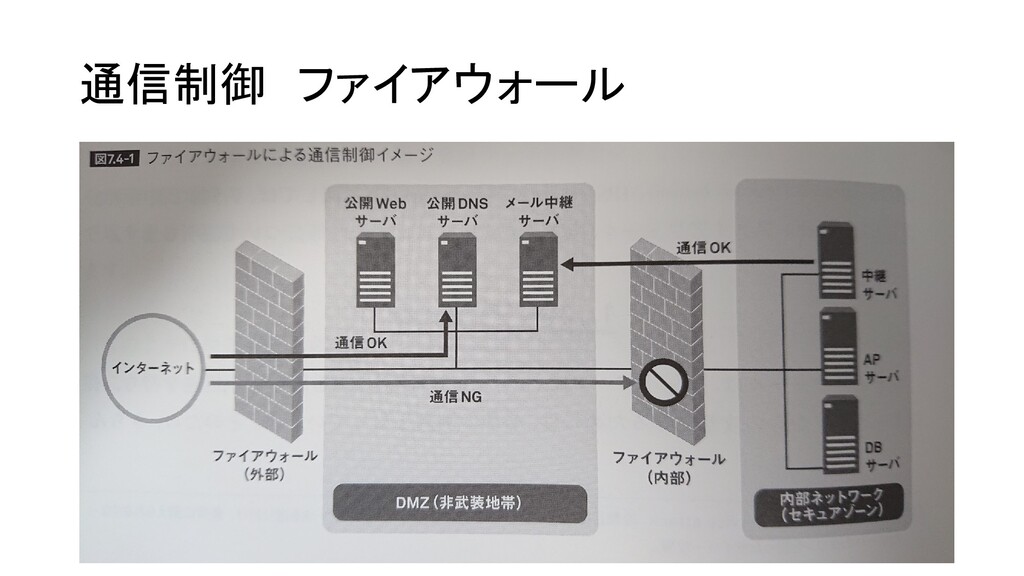
通信制御 ファイアウォール ネットワーク間の通信を制御する。 ファイアウォールを用いて以下の3つのゾーンを構成。 ・セキュアゾーン(機密データ) 外部・DMZからは直接アクセス不可。 ・DMZ(非武装地帯) ファイアウォールによってセキュアゾーンおよび外部ネットワークから隔離された領域。 セキュアゾーンおよび外部ネットワークからアクセス可能。 DMZから接続できるのは外部のみ。
WEBに公開するサーバー、メール中継サーバー、DNSサーバーなどを配置。 ・外部ネットワーク
通信制御 ファイアウォール
通信制御 WAF WAF(Web Application Firewall) WEBアプリケーションに特化した通信制御を行う。 ファイアウォールでは防げない、 以下のようなWEBアプリの脆弱性に対する攻撃を防げる。 ・SQLインジェクション ・クロスサイトスクリプティング
・パラメータ改ざん
監視・監査 監視・監査の脅威: ・不正行為 ・不正アクセス 不正行為は発覚してから対策しても意味を成さないので、 事前に「いつ」「だれが」「なにをした」というログを残す。 対象装置: PC・スマートフォン・サーバー・ミドルウェア・アプリケーション・通信システム 対象ログ: 認証ログ・操作記録・エラーログ・アクセスログ・通信記録
監視・監査 監視・監査の脅威: ・不正行為 ・不正アクセス 不正行為は発覚してから対策しても意味を成さないので、 事前に「いつ」「だれが」「なにをした」というログを残す。 対象装置: PC・スマートフォン・サーバー・ミドルウェア・アプリケーション・通信システム 対象ログ: 認証ログ・操作記録・エラーログ・アクセスログ・通信記録
ウィルス・マルウェア対策 マルウェアとは・・・ 危害を及ぼす悪意あるプログラム。 ウィルス・ワーム・トロイの木馬・・・マルウェアの一種。 ・ウィルス: プログラムを書き換えて自己増殖するマルウェア。 単独では存在できない。 ・ワーム: ウィルスと似ているが、単独で存在できる。 ・トロイの木馬:
コンピュータ内部に侵入し、外部からの命令で端末を自在に操る。
マルウェアの感染経路 電子メール: 添付ファイル。拡張子を偽造。 Excelのマクロに潜伏させたり。 インターネット: マルウェアが仕込まれたWEBサイトにアクセスして強制的にダウンロード・実行。 USBメモリ: マルウェアに感染したUSBをPCに接続することで感染。
マルウェアの感染対策 ・感染経路の把握 ・マルウェア対策ソフトの導入 常に最新版に更新。 ・セキュリティホールをなくす。 OSやミドルウェアを常にアップデート。 ※アプリへの影響は要調査。 ・定期的なマルウェアスキャン ・感染した時の対応を構築
セキュリティ まとめ セキュリティの脅威に備える。 ・情報漏えい ・データの改ざん・破壊 ・業務サービス停止 対策要件: ・識別と認証 ・暗号化 ・通信制御
・監視・監査 ・セキュリティリスク管理 ・ウィルス・マルウェア対策
ご静聴ありがとうございました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}