In today's competitive e-commerce landscape, effective search ranking systems are no longer a luxury, but a necessity. At Mercari, Japan’s largest C2C e-commerce marketplace, AI search ranking is the flagship feature in our commitment to continuously integrate AI into search, driving significant engagement and GMV uplift in our pursuit to provide the best search experience for our millions of users.
In this talk, we'll delve into key components of Mercari's search ranking system, specifically:
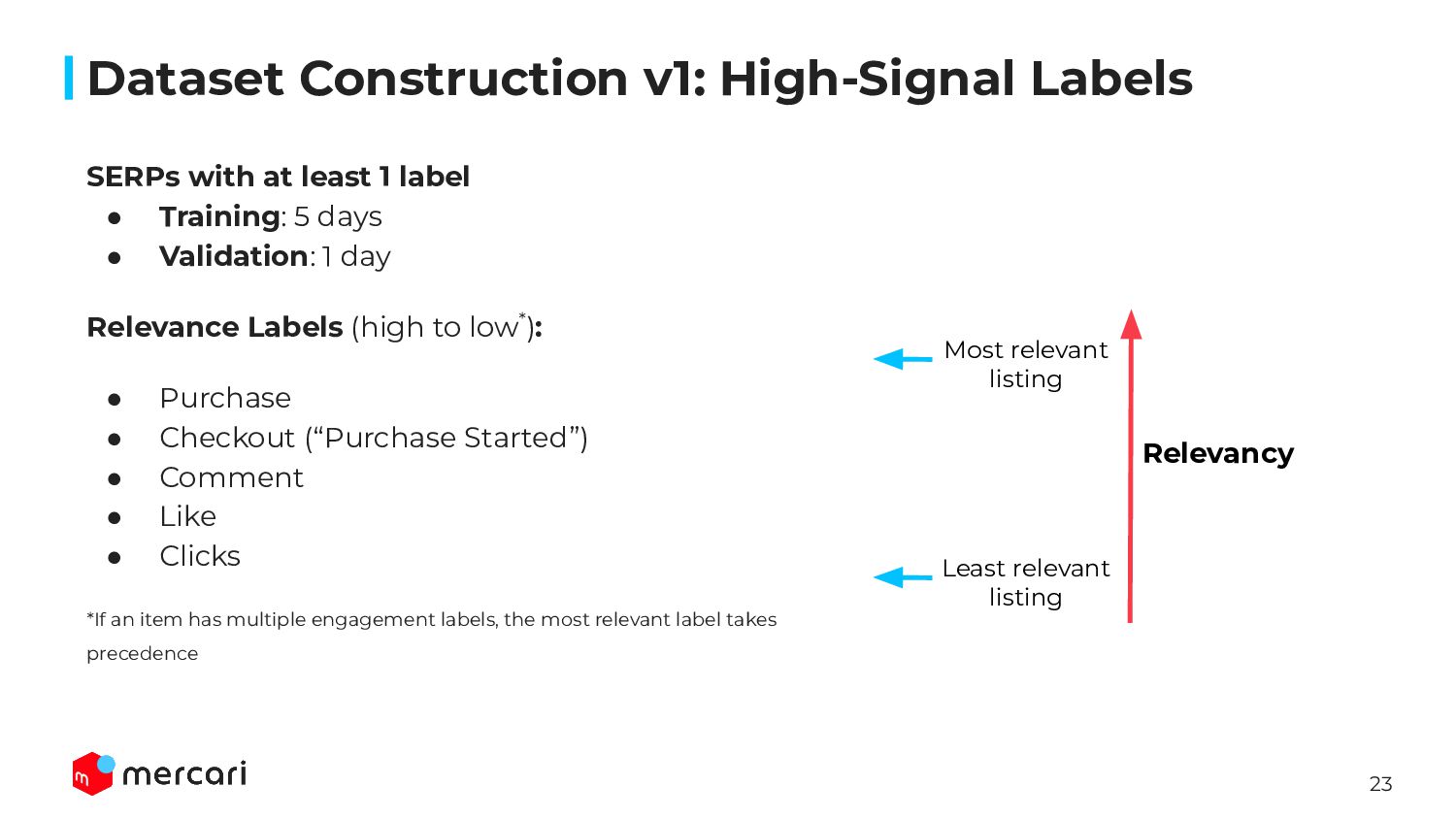
Dataset Construction: Demonstrating how we build a rich and diverse dataset incorporating user behavior, item attributes, and marketplace dynamics. We will show how we deal with implicit feedback specific to two-sided marketplaces with unique items.
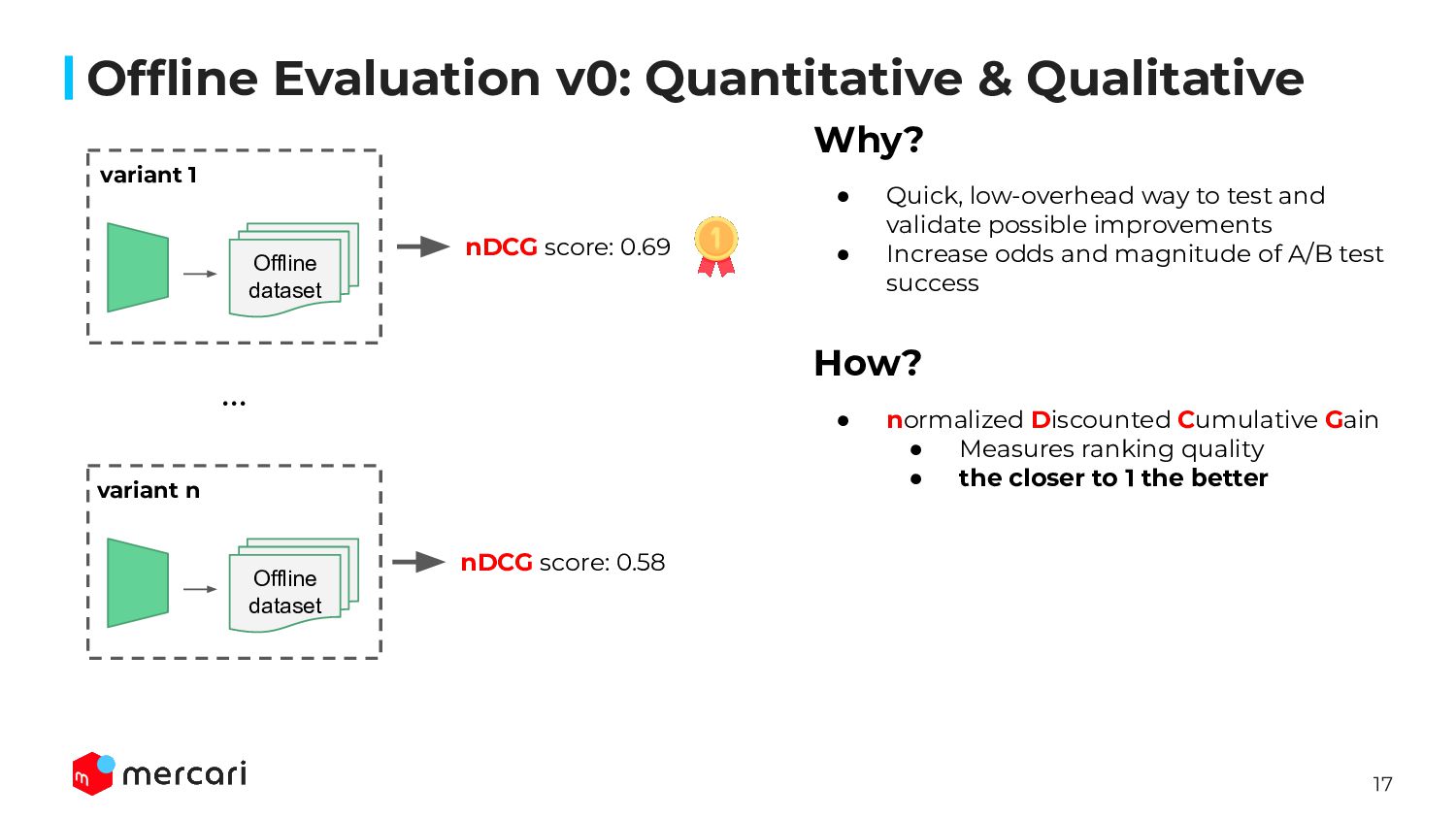
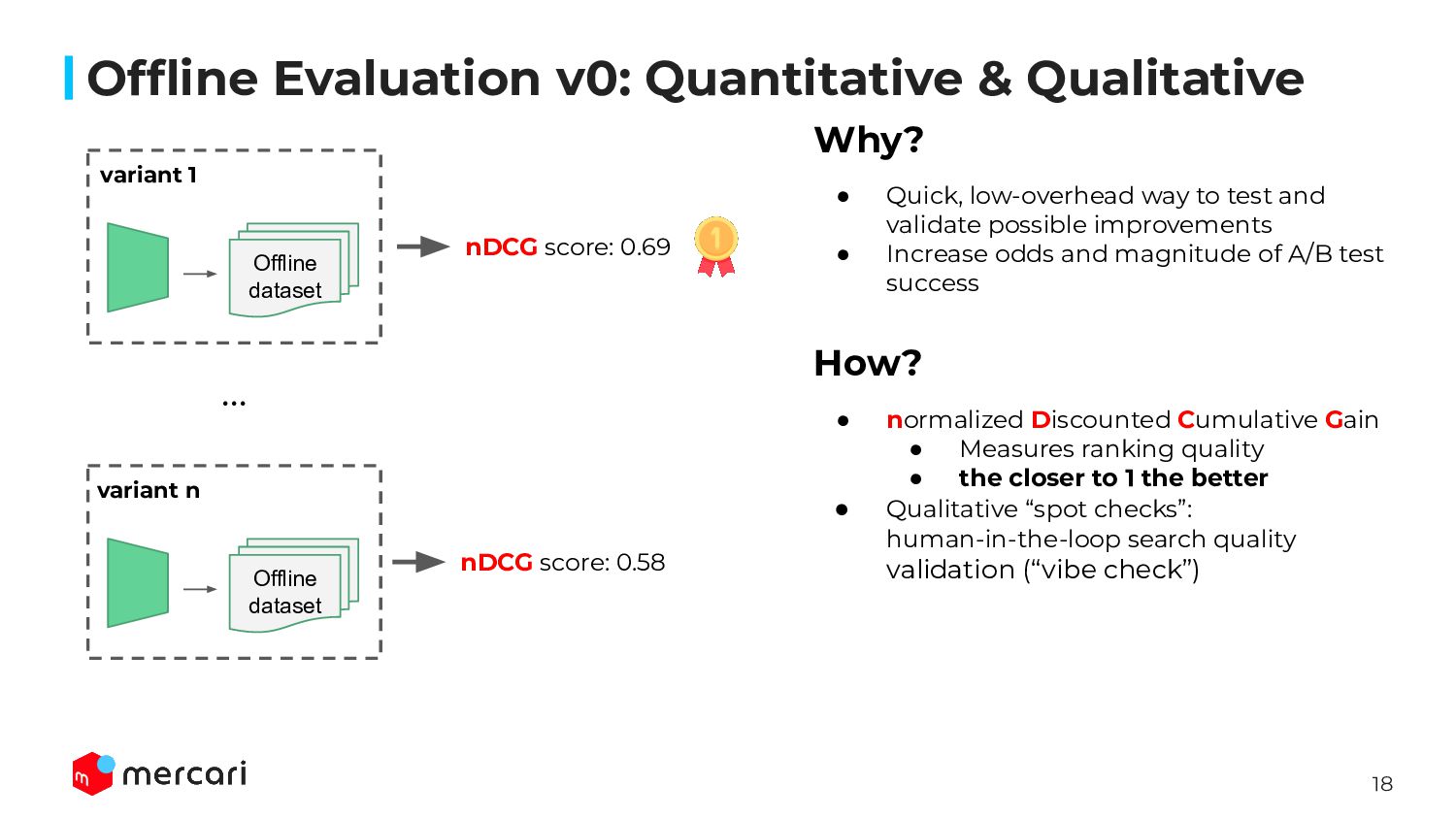
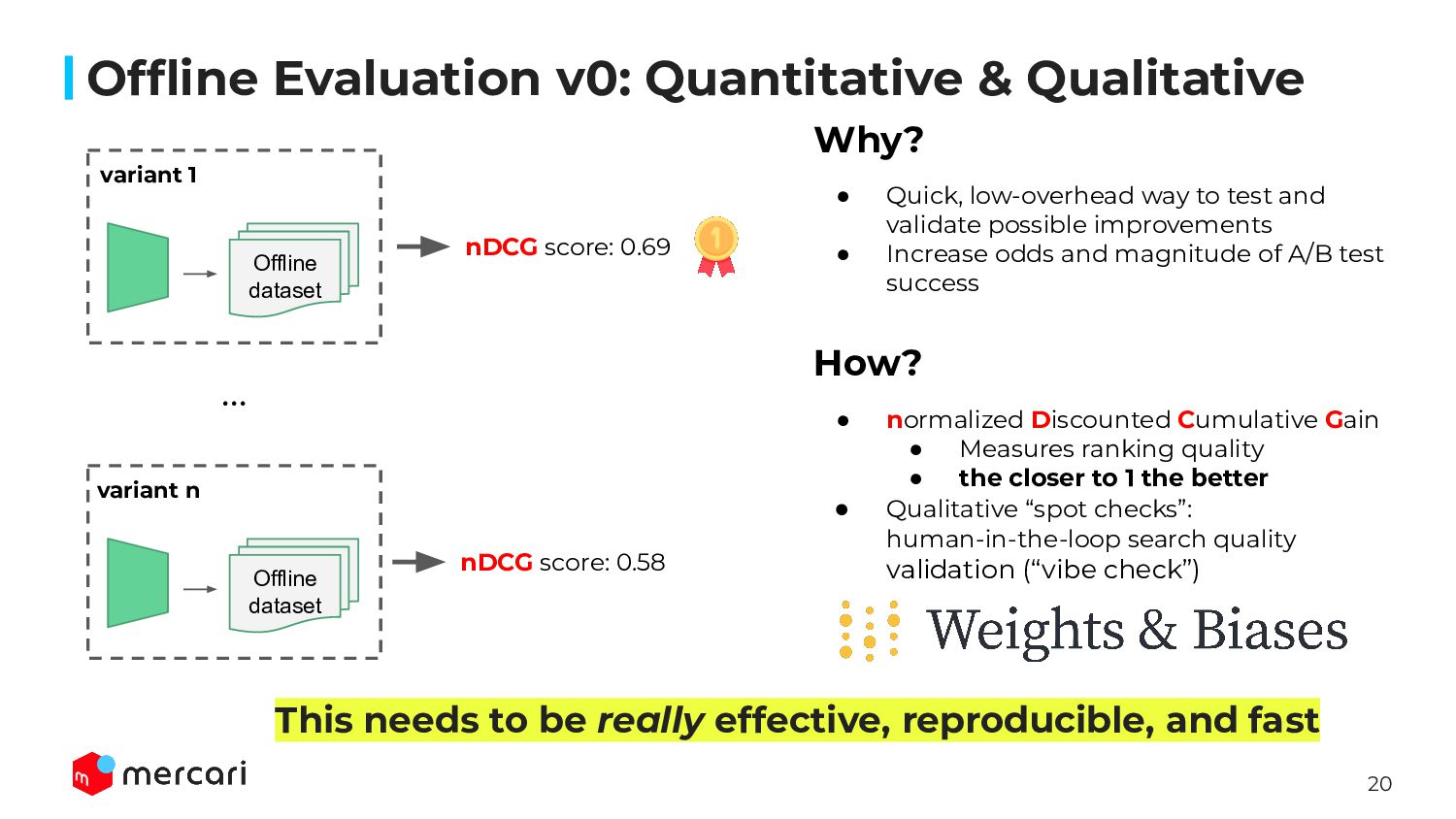
Model Tracking & Monitoring: Showing how we approach tracking and monitoring our ML ranking models, including key custom metrics we’ve developed for robust evaluation. We will show how our custom metrics make our model debugging simpler and ensure our features have a measurable business impact in online testing.
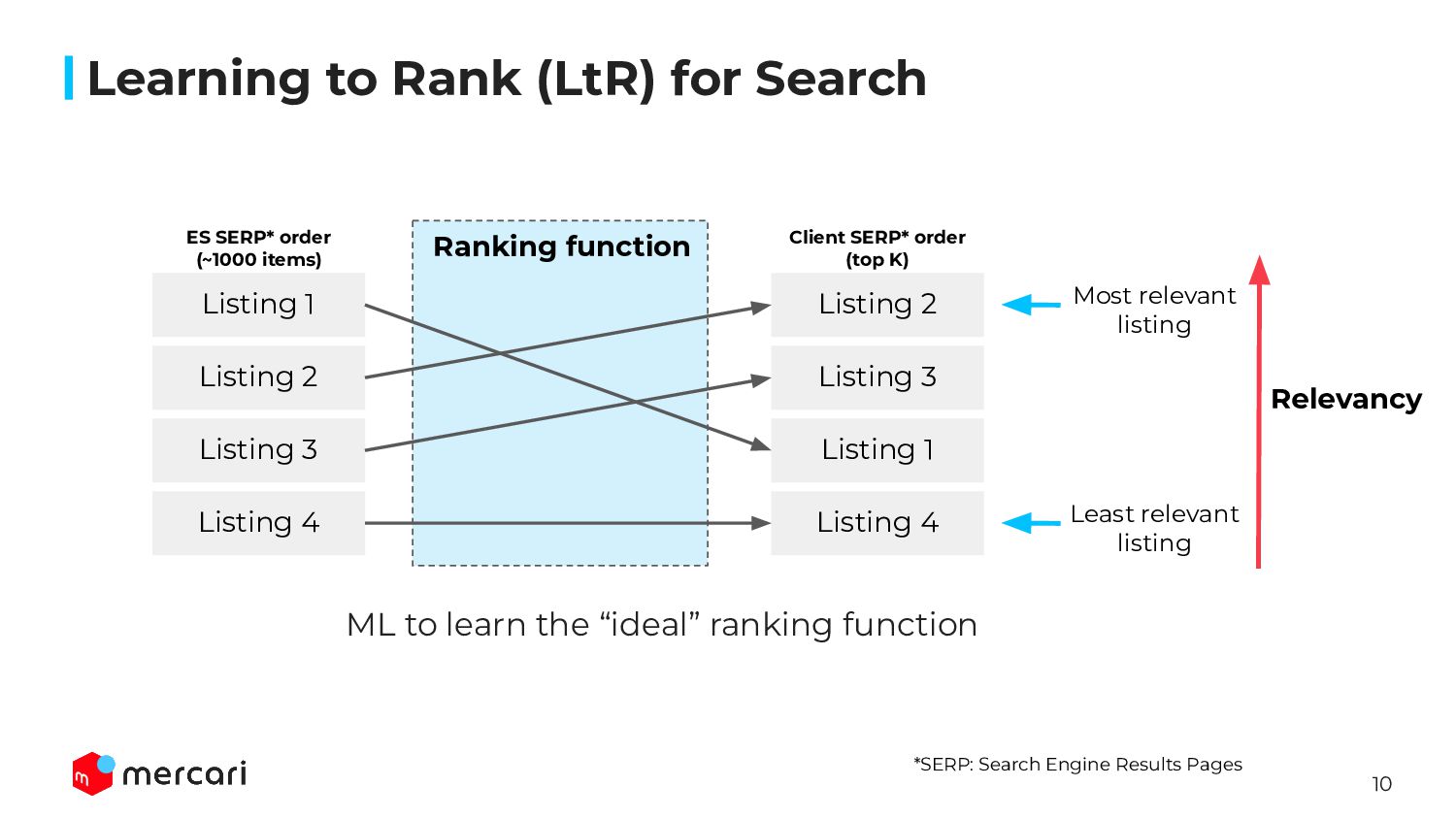
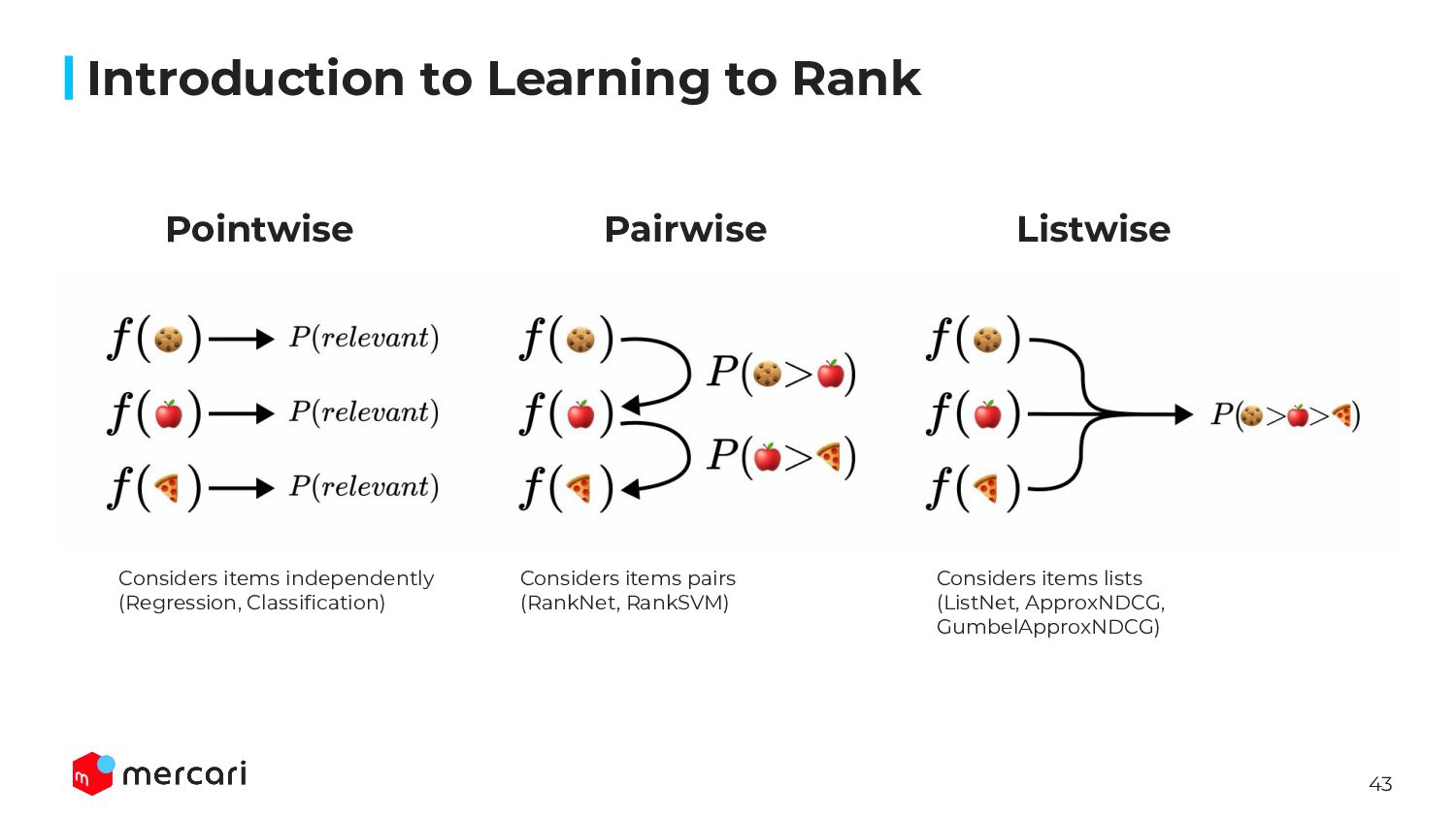
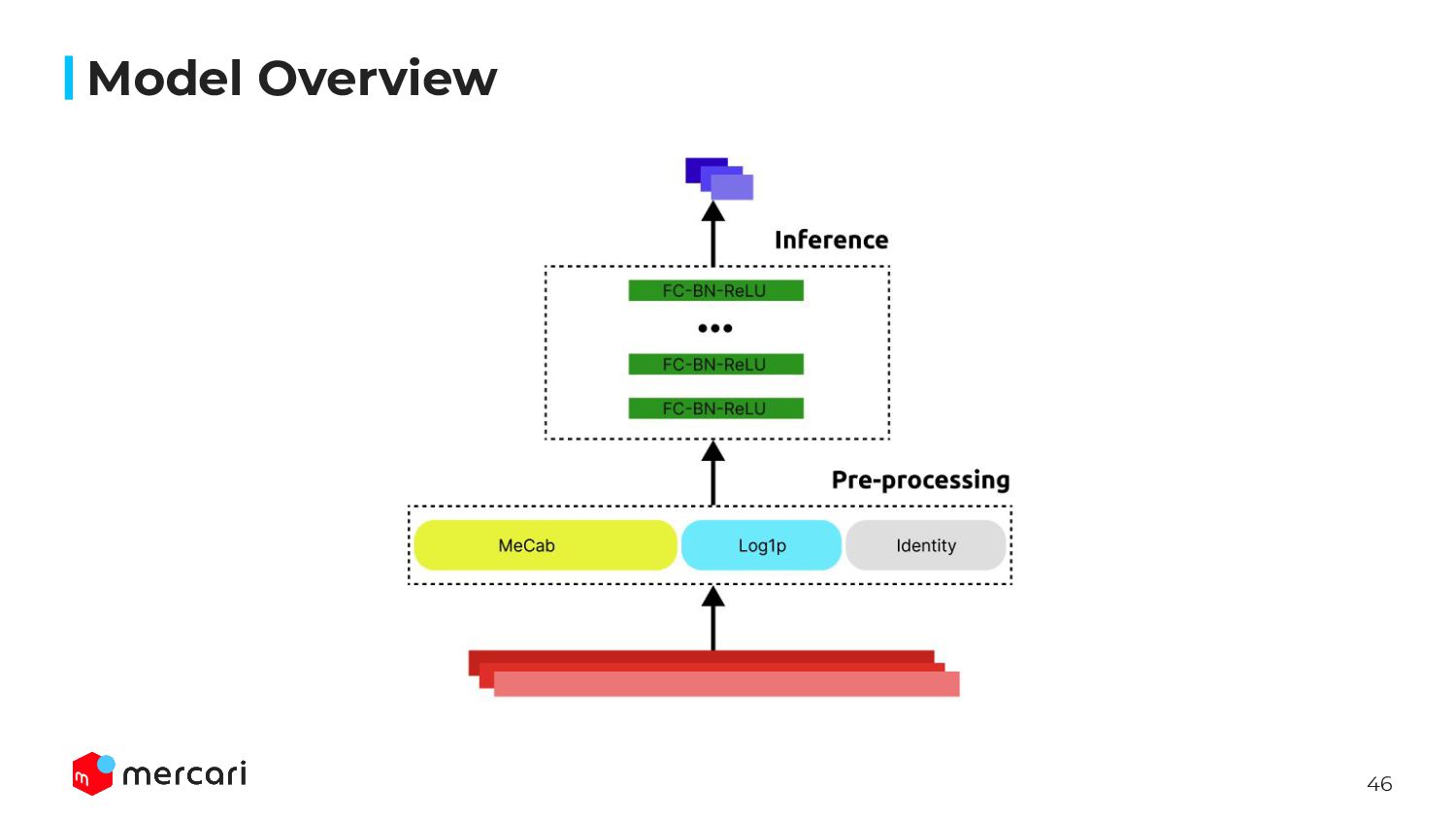
Model Building: Sharing the technical details of our model building process, exploring what learning-to-rank is as well as our goals for optimal performance.
De-biasing through Historical Data: Outlining the potential problems inherent in implicit feedback and how we deal with potential biases in our ranking models through counterfactual learning. We will show how biased behavior affects the model learning process, what factors can trigger specific user behaviors, and how we mitigate these biases in a way that maintains and enhances model performance over time.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
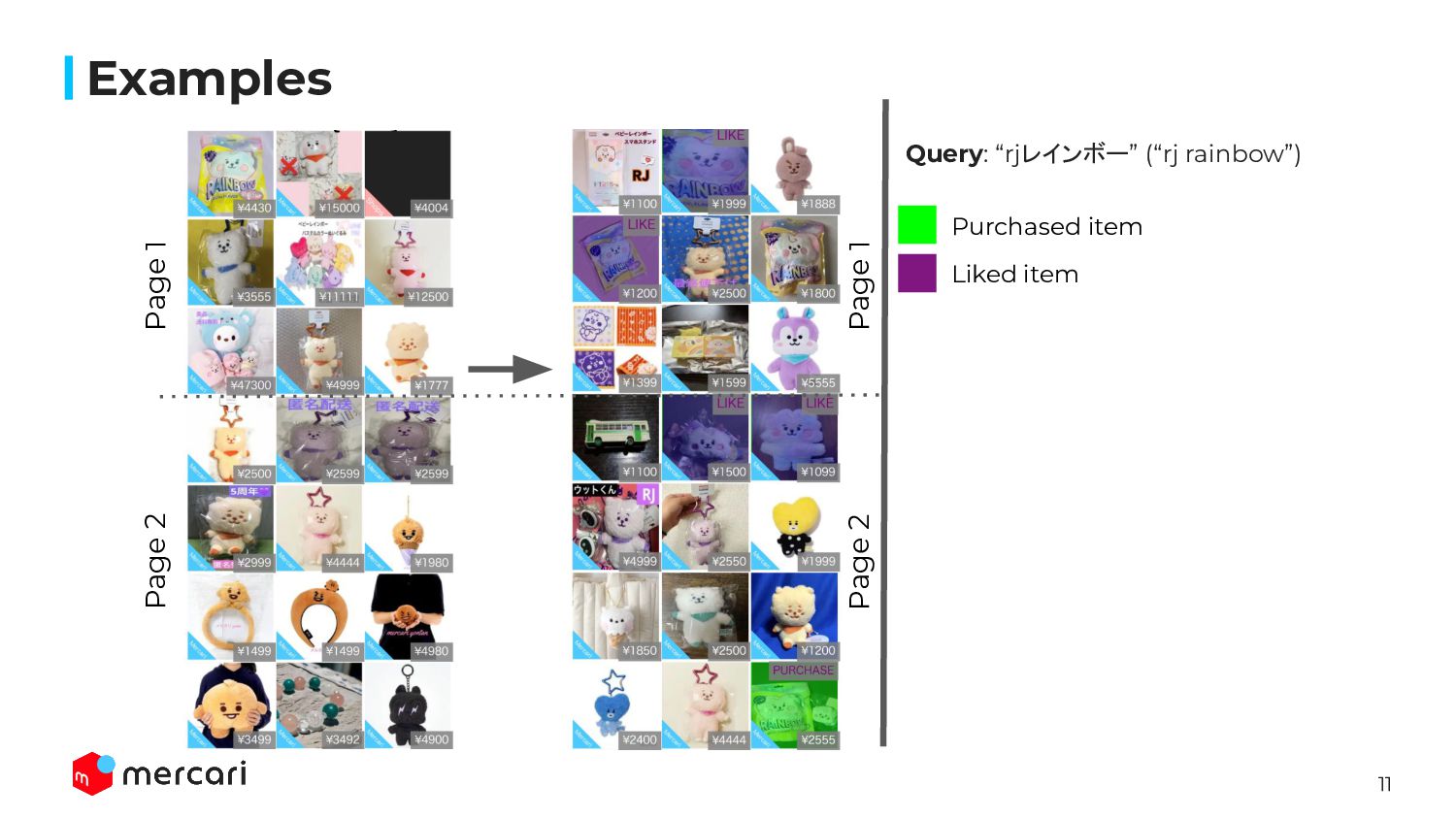{kind=link}
{kind=link}
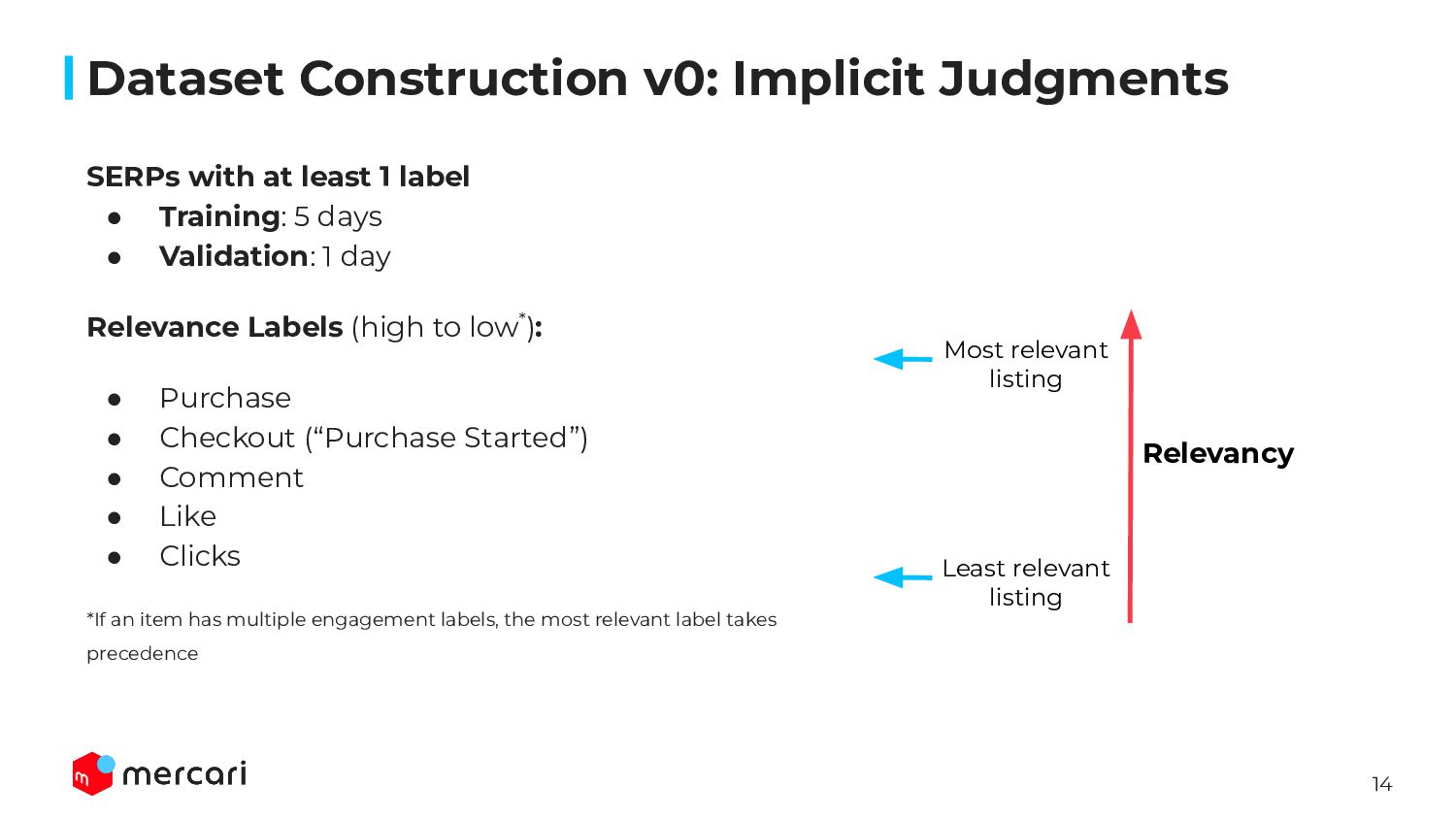{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
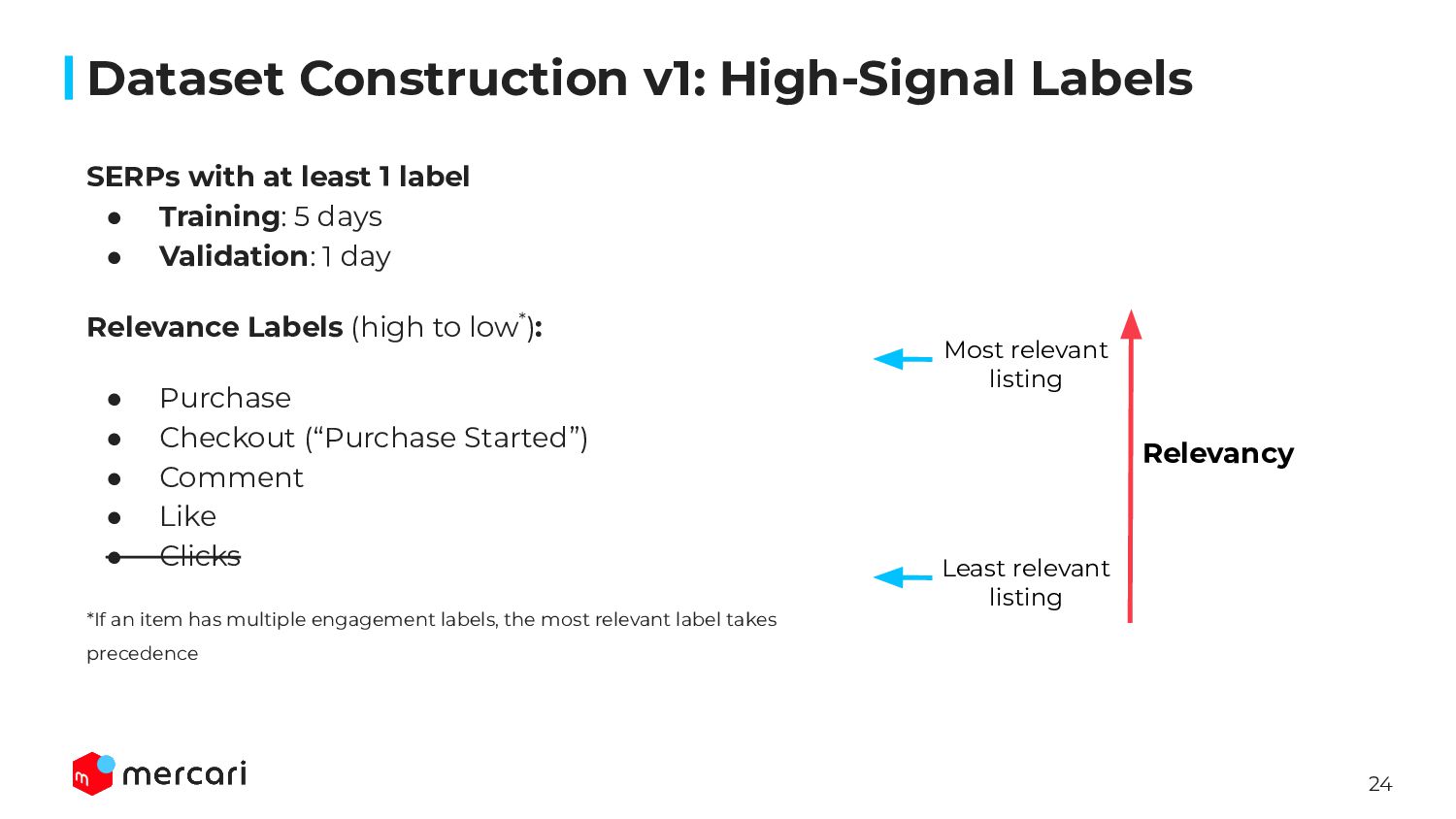{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
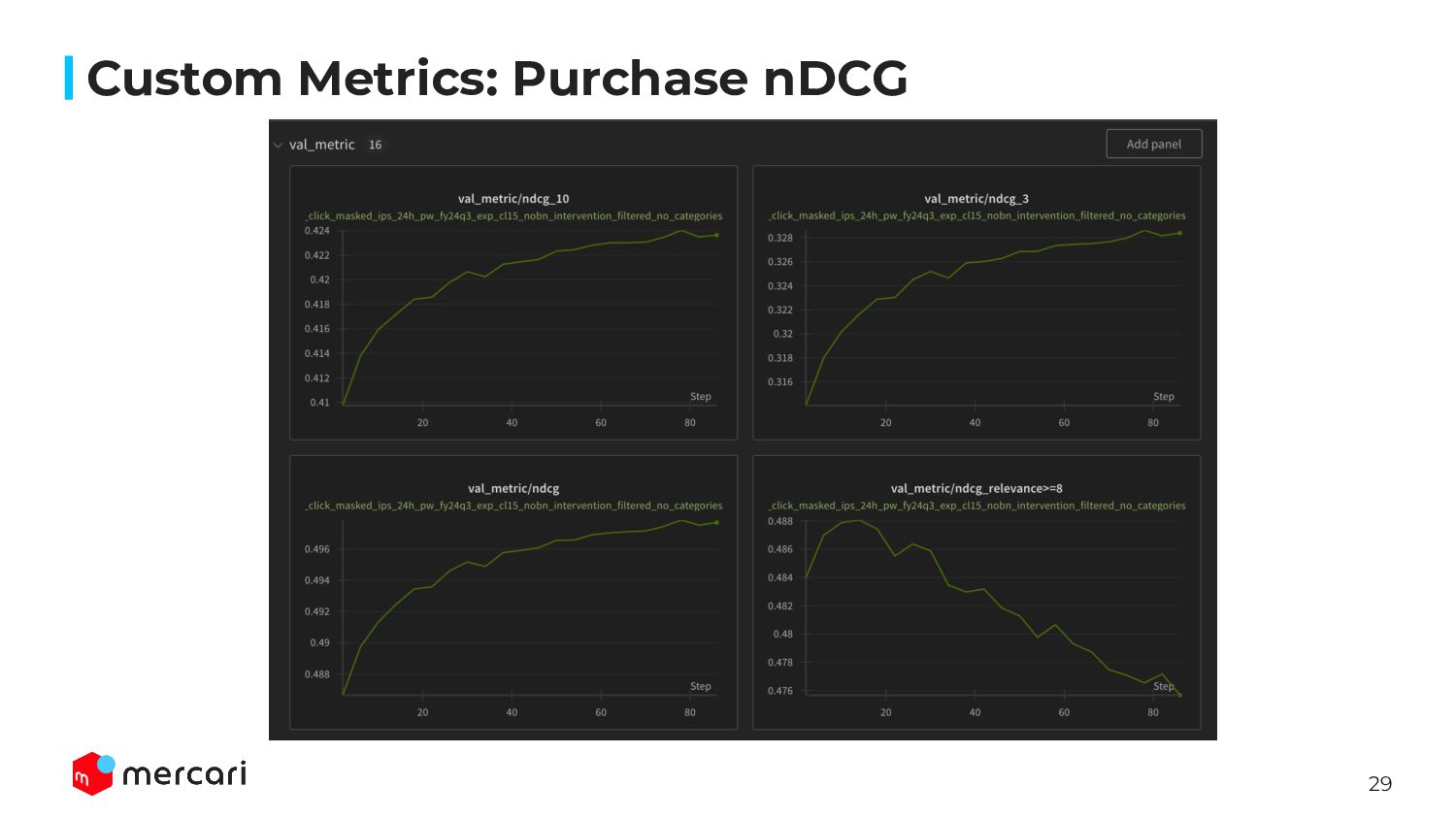{kind=link}
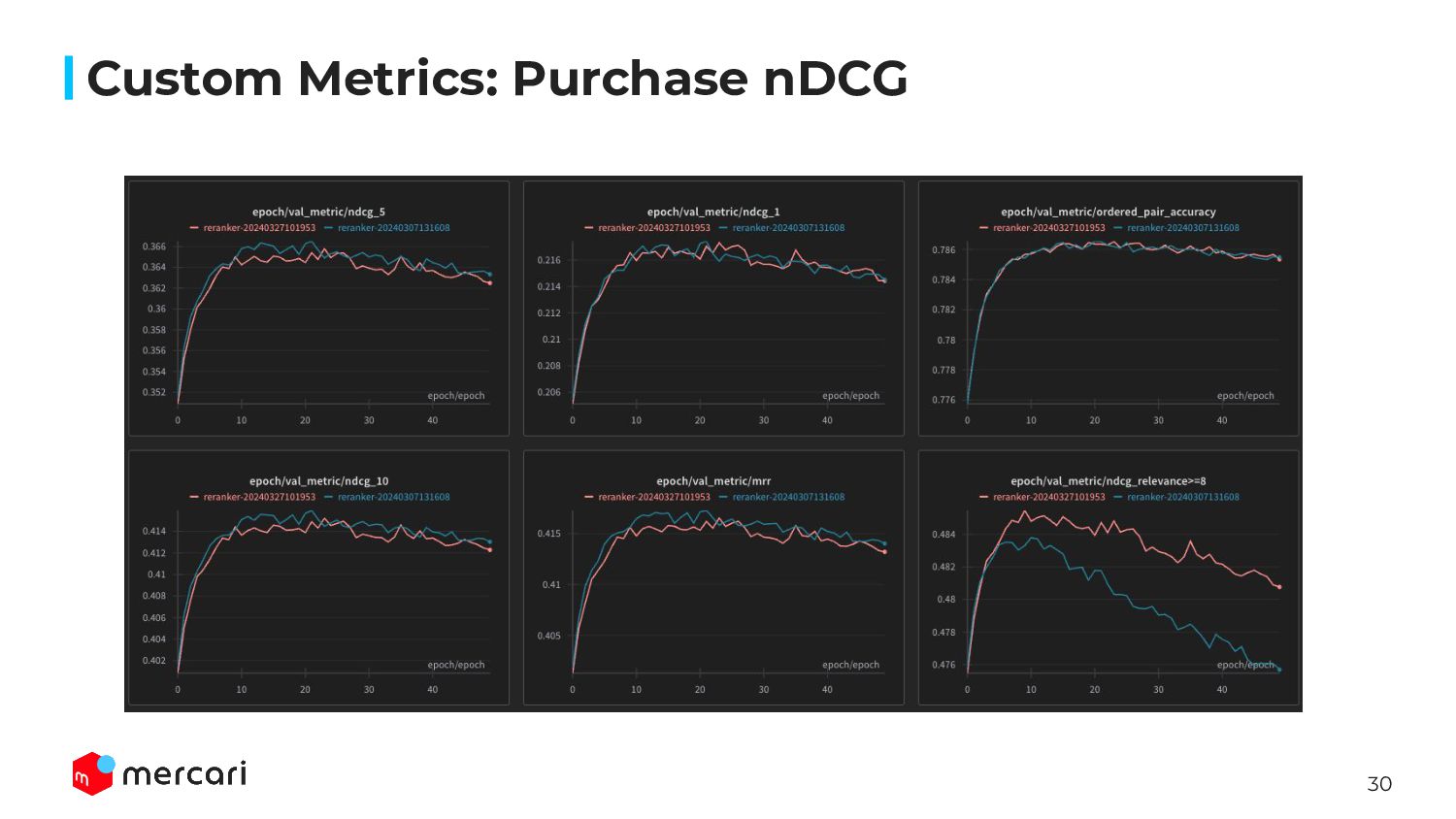{kind=link}
{kind=link}
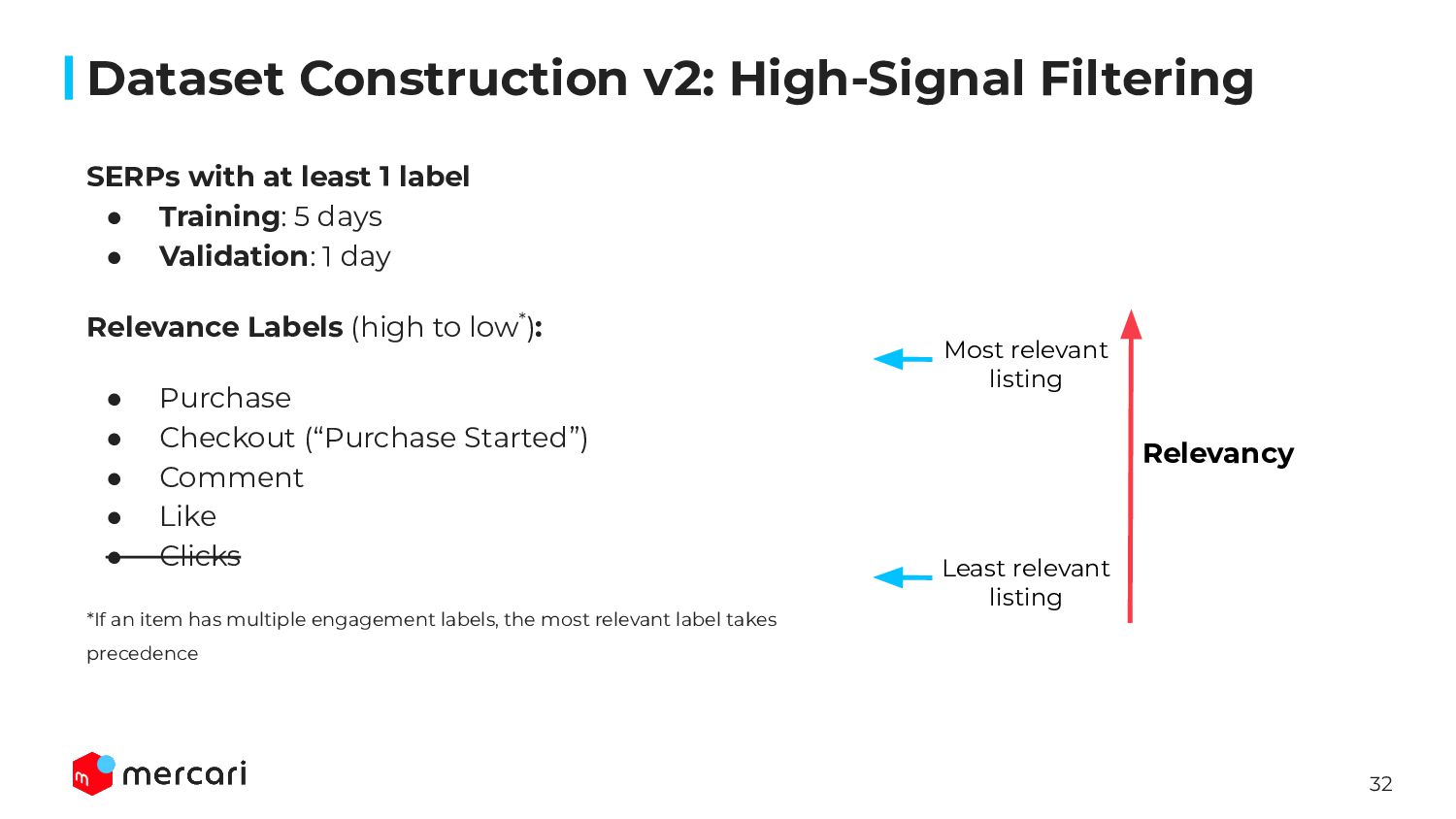{kind=link}
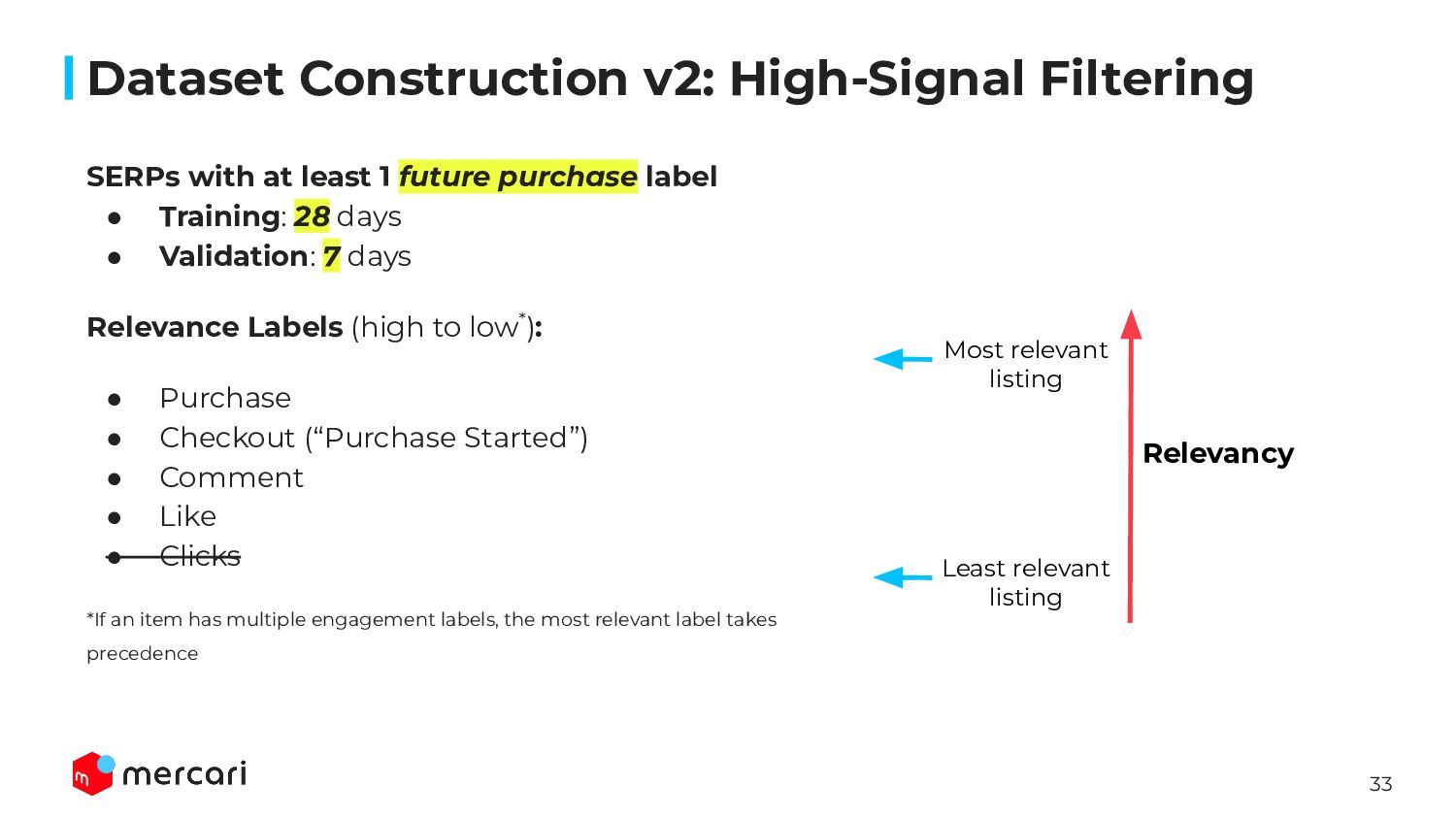{kind=link}
{kind=link}
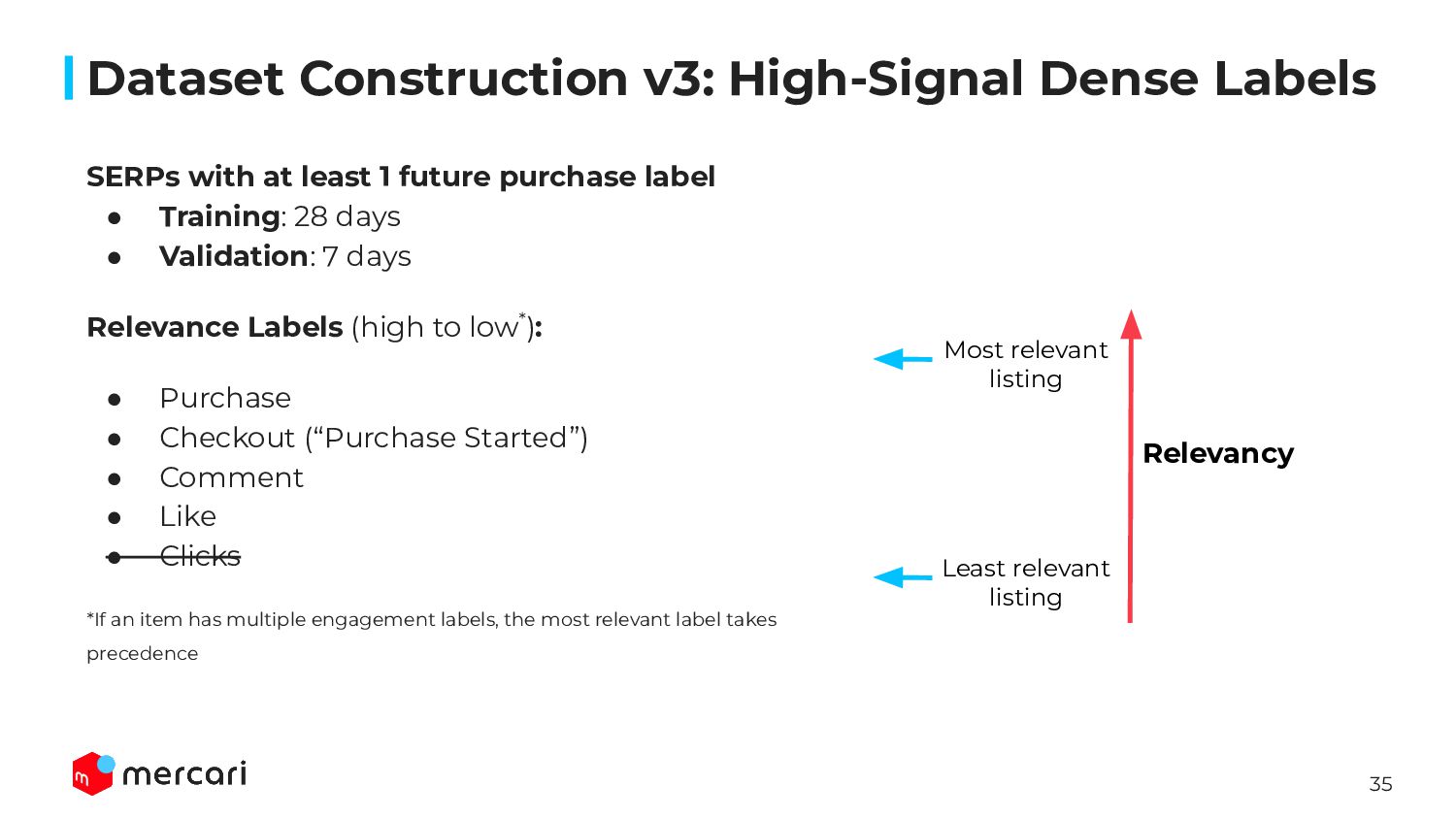{kind=link}
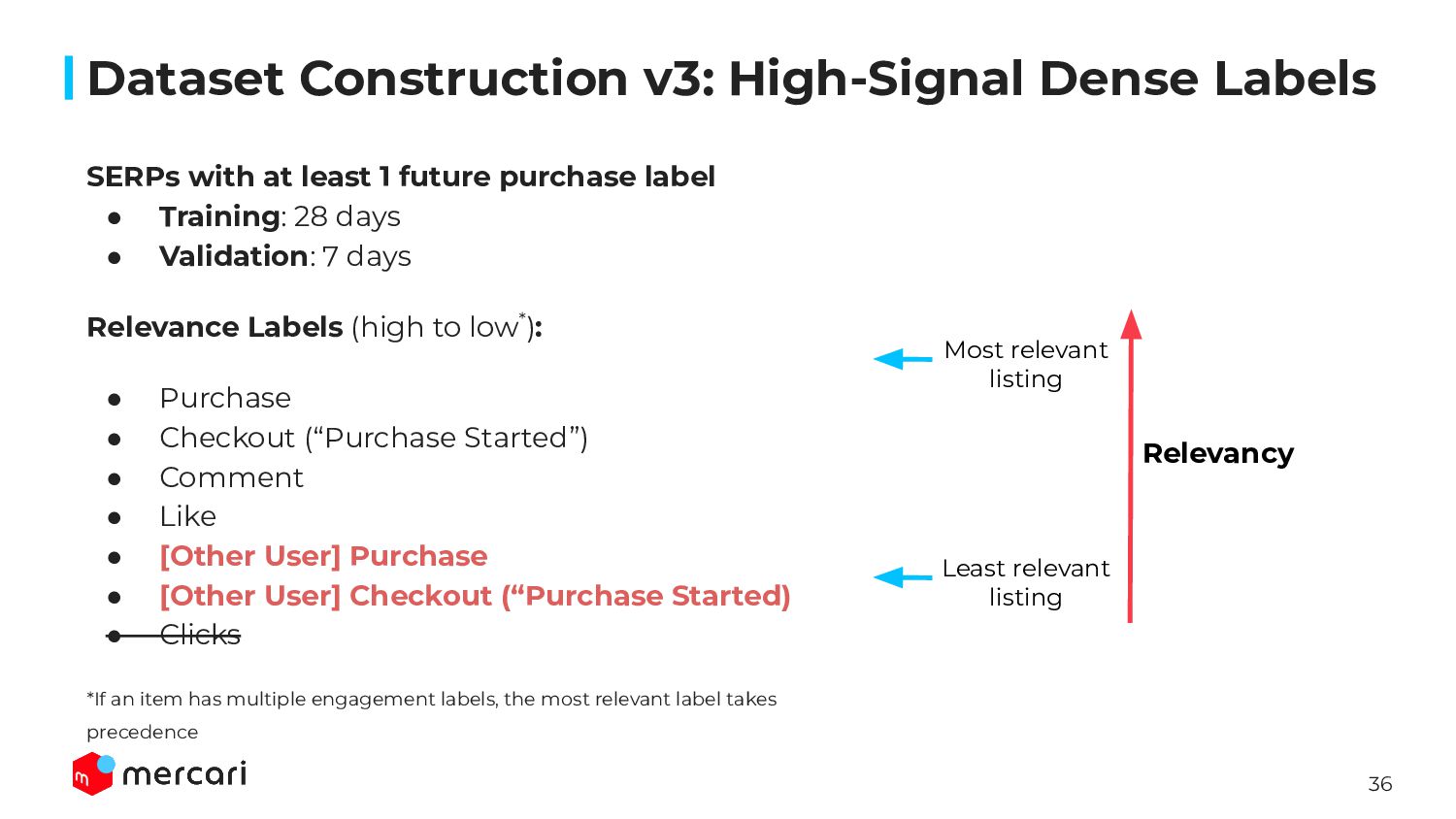{kind=link}
{kind=link}
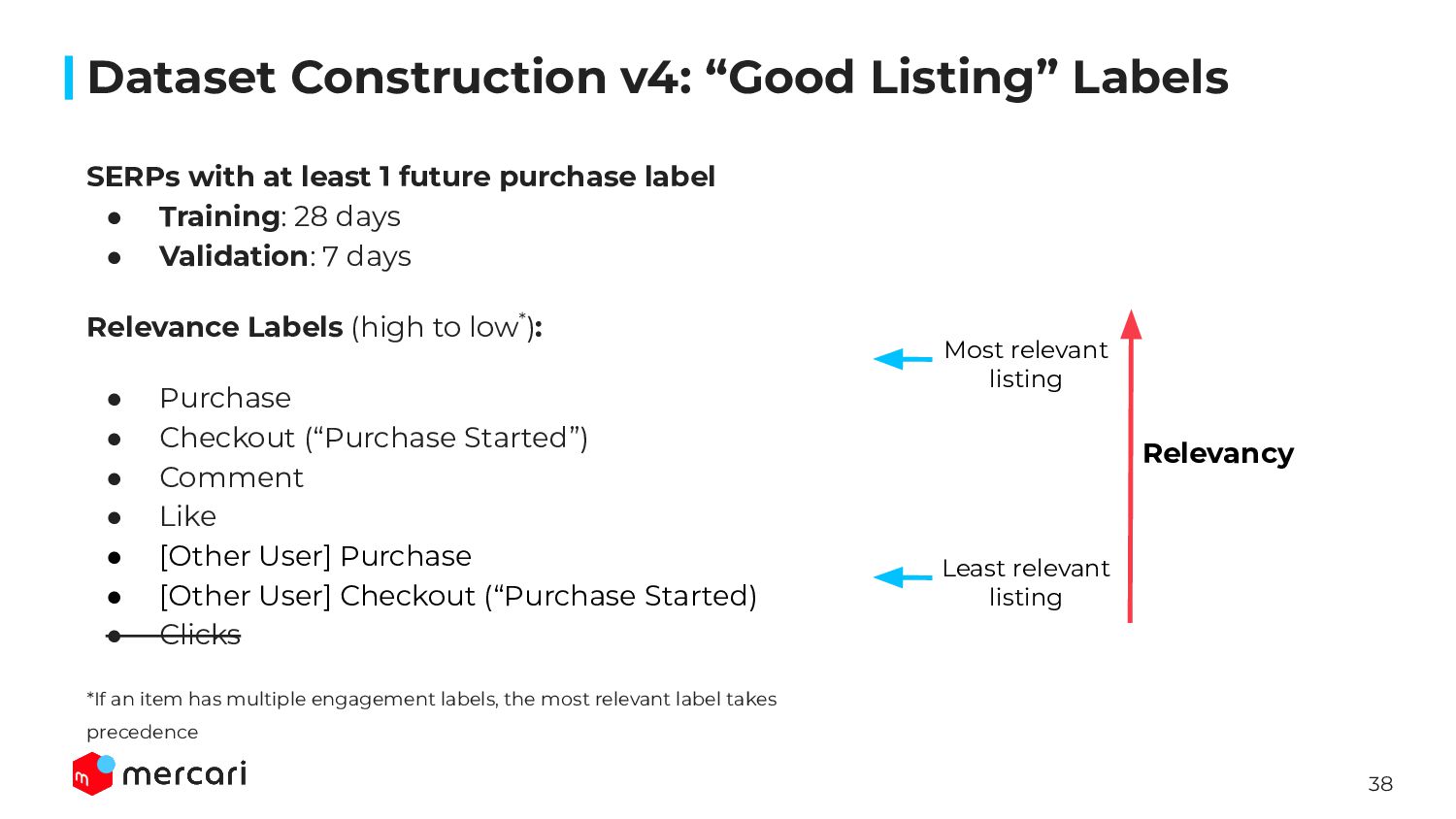{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}