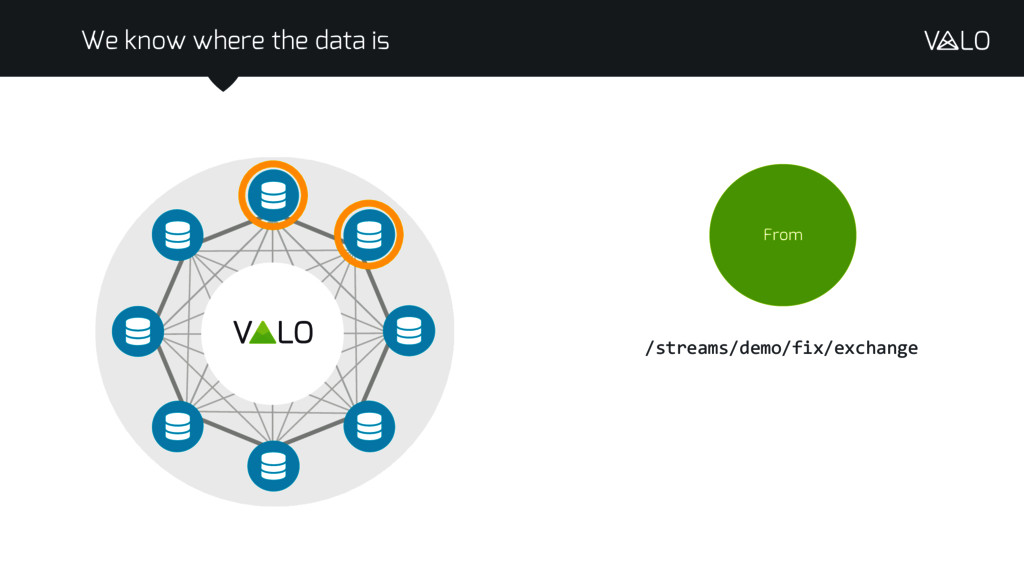
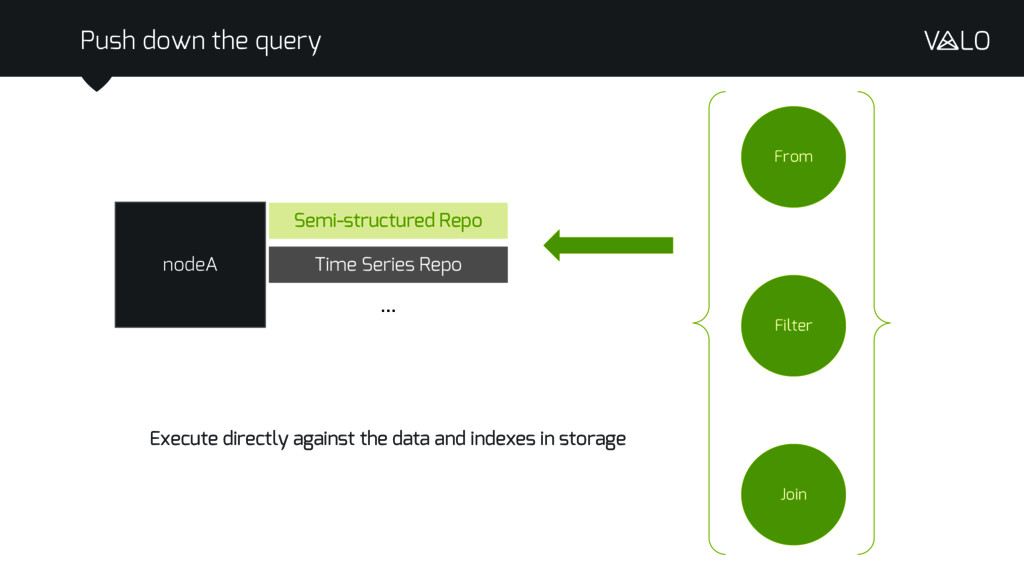
Apache Spark has successfully built on Hadoop infrastructure to encompass real-time processing, moving from rigid Map-Reduce operations to general purpose functional operations distributed across a cluster of machines. However data storage has become a black box. The source data for a query has to be retrieved in full and sent through the analysis pipeline rather than processing the data where it is stored, as in traditional database systems. This introduces significant cost, both in network utilisation and in the time taken to produce a result.
Session presented at Big Data Spain 2015 Conference
15th Oct 2015
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/program/thu/slot-14.html
{kind=link}
{kind=link}
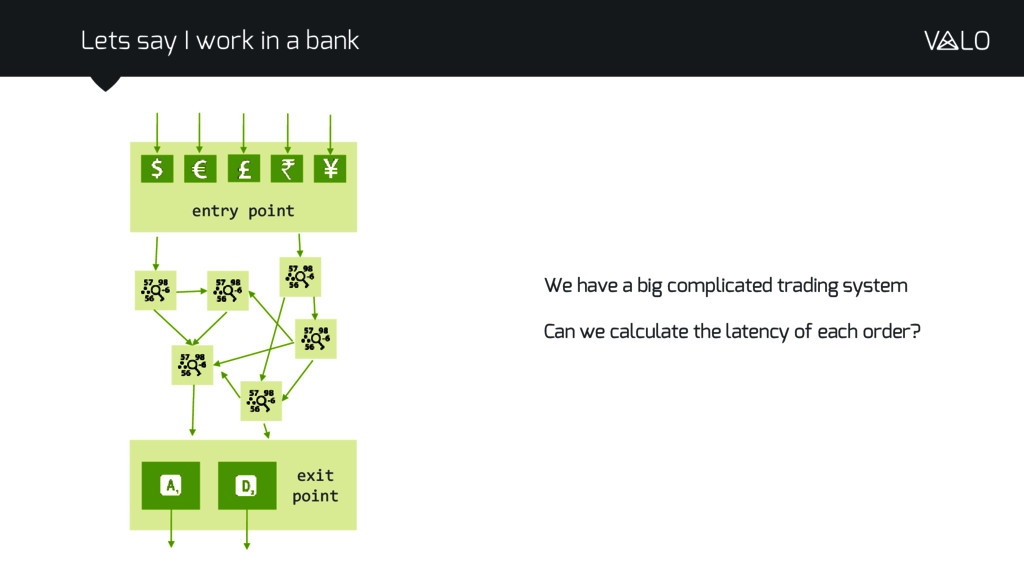{kind=link}
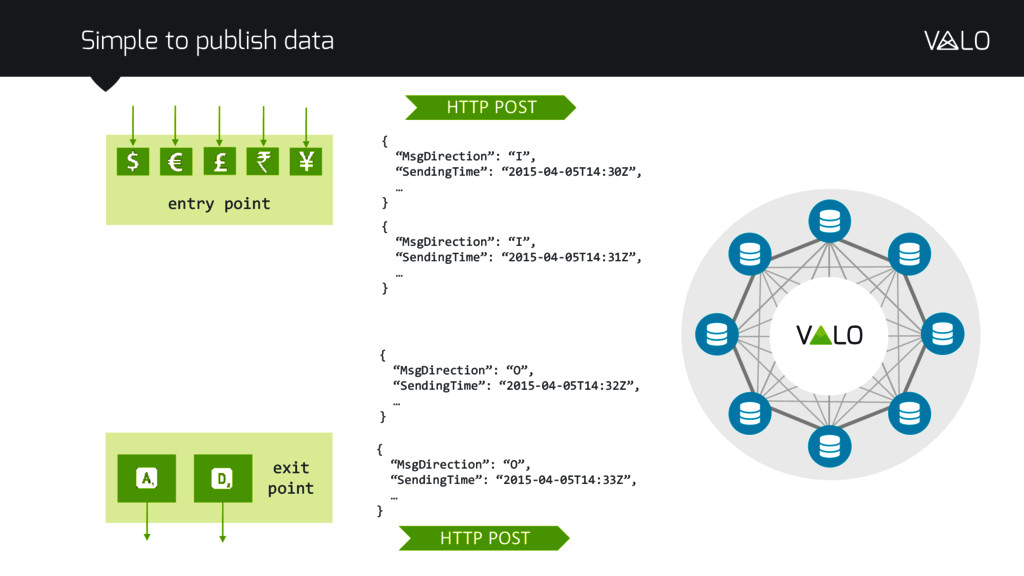{kind=link}
{kind=link}
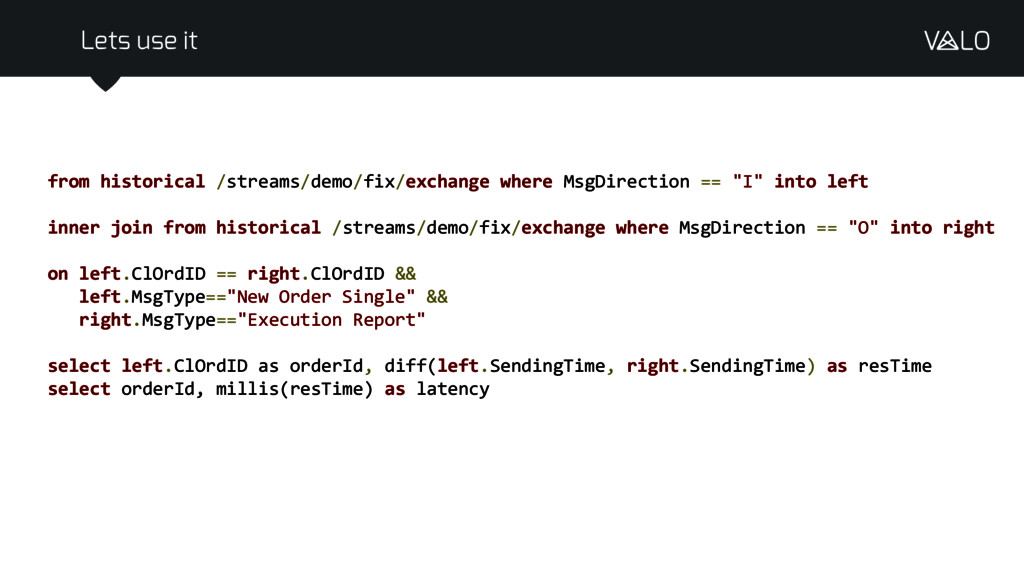{kind=link}
{kind=link}
{kind=link}
{kind=link}
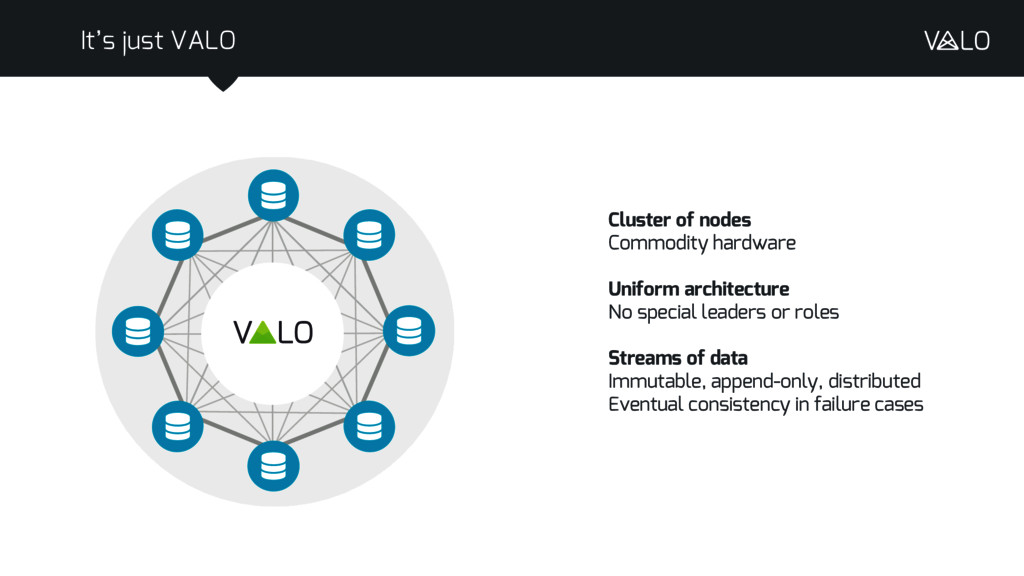{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}