Charla impartida por Marco Antonio Sanz Molina Prados, Fundador de CloudAppi, que repasa las tecnologías más habituales del mundo Big Data y su aplicación en el desarrollo de las Apis.
En la ponencia se tratan os siguientes puntos:
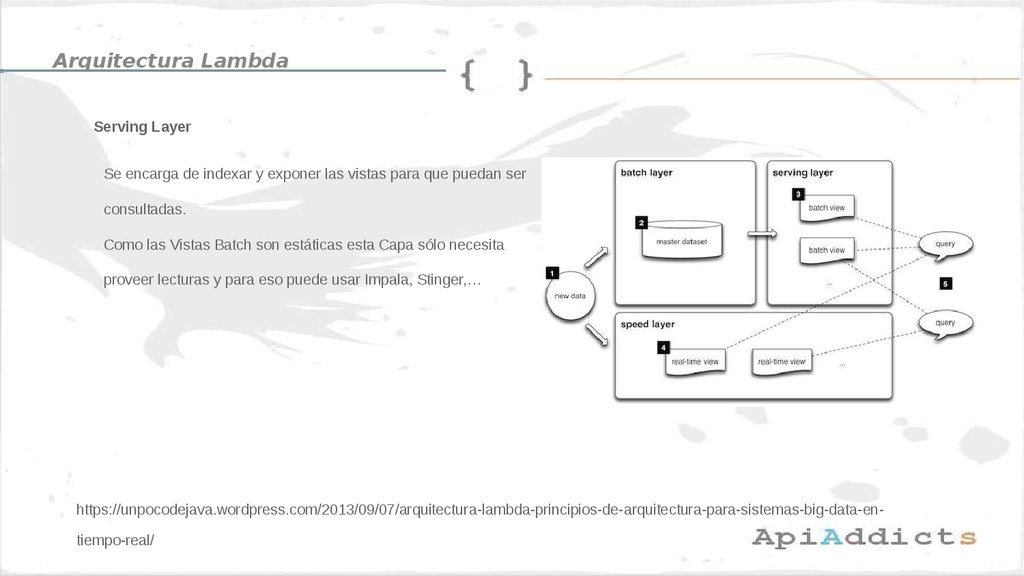
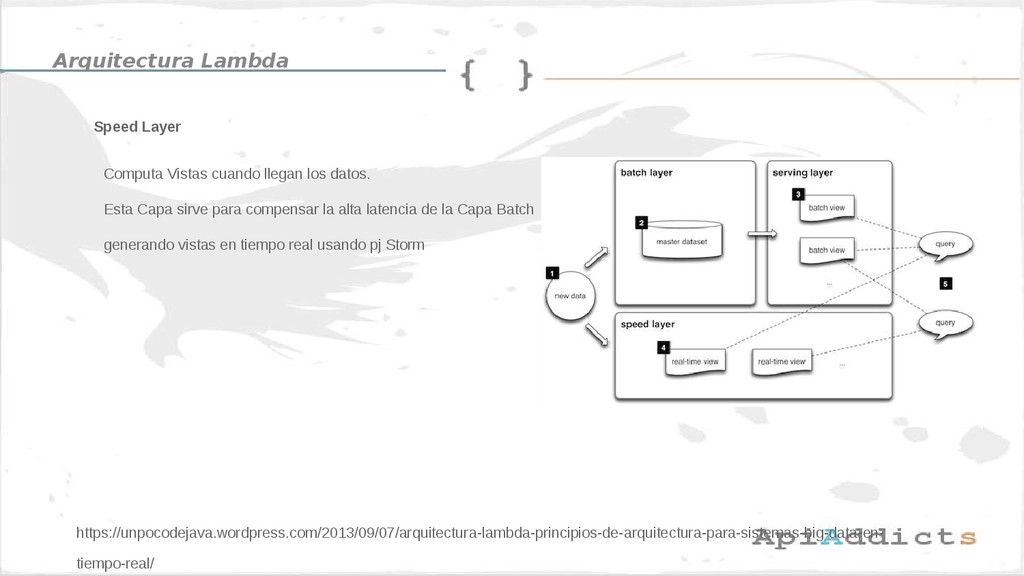
• Arquitectura Lambda
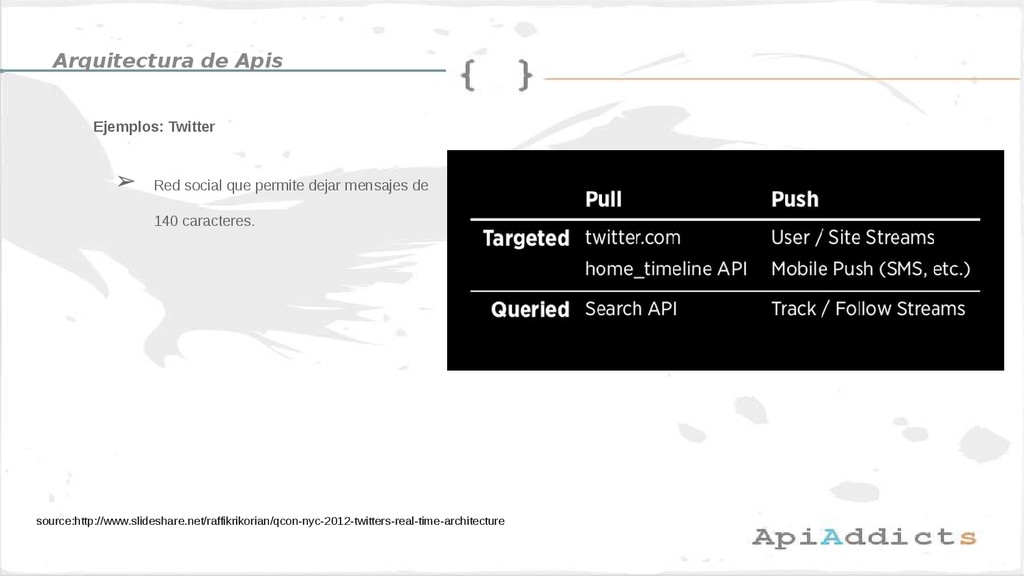
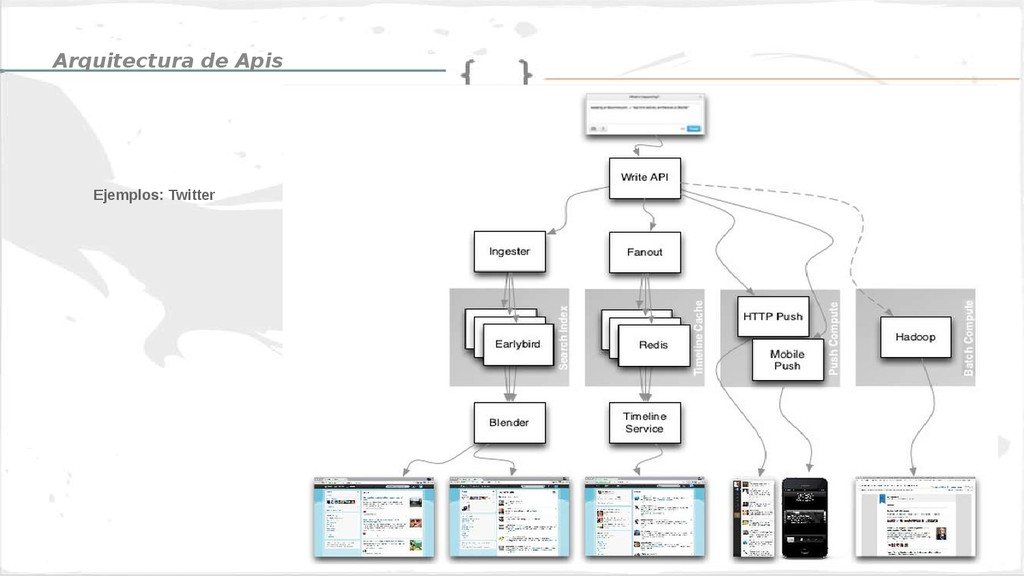
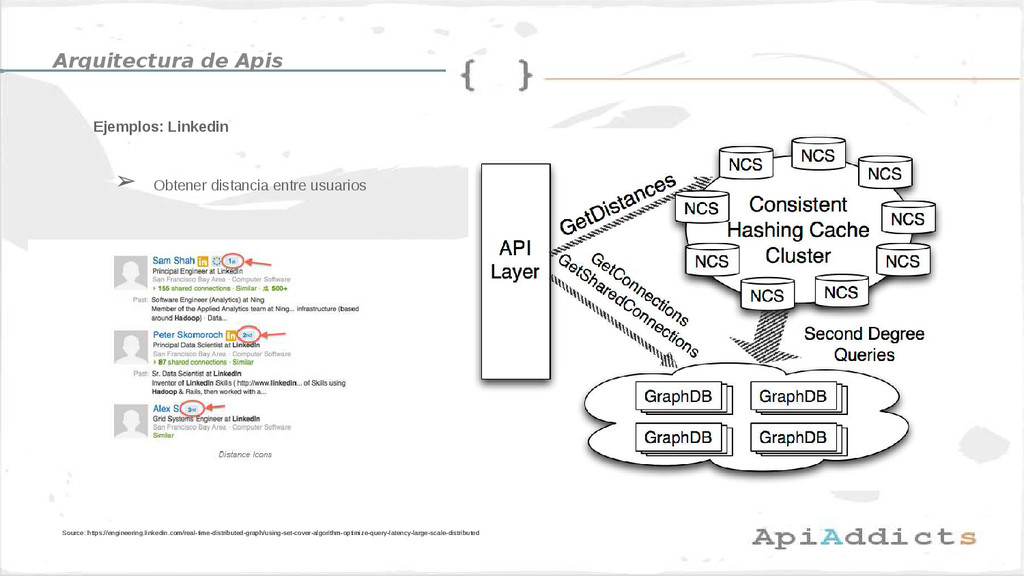
• Arquitectura de APIs
• Bases de datos noSQL
• Datawarehouses Big Data
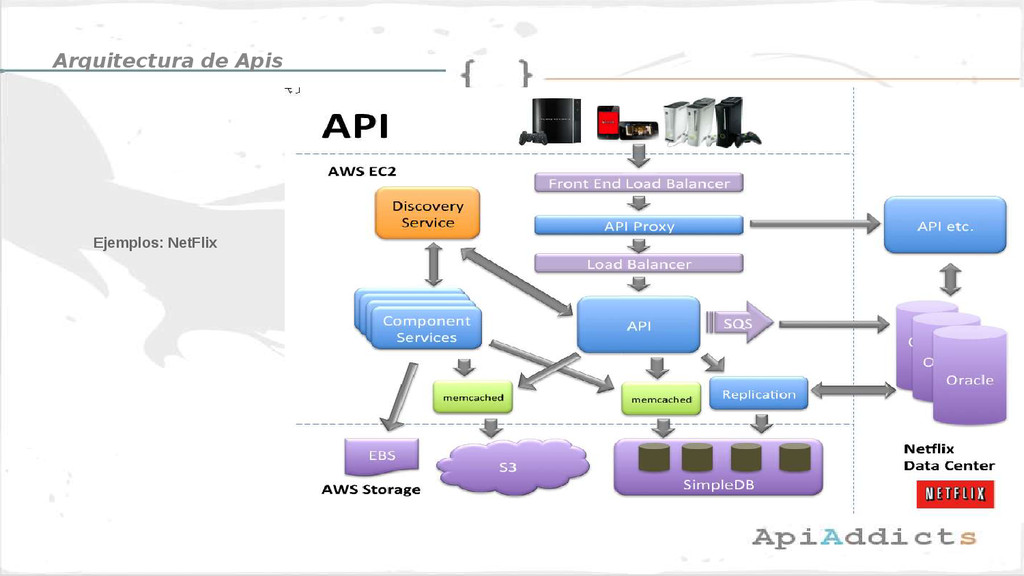
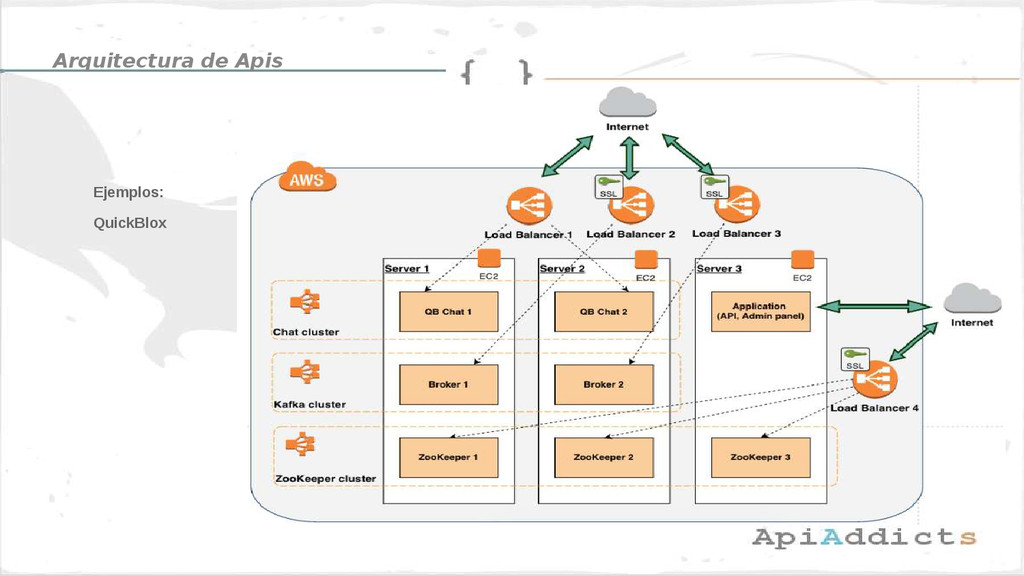
• Ejemplos de arquitecturas
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
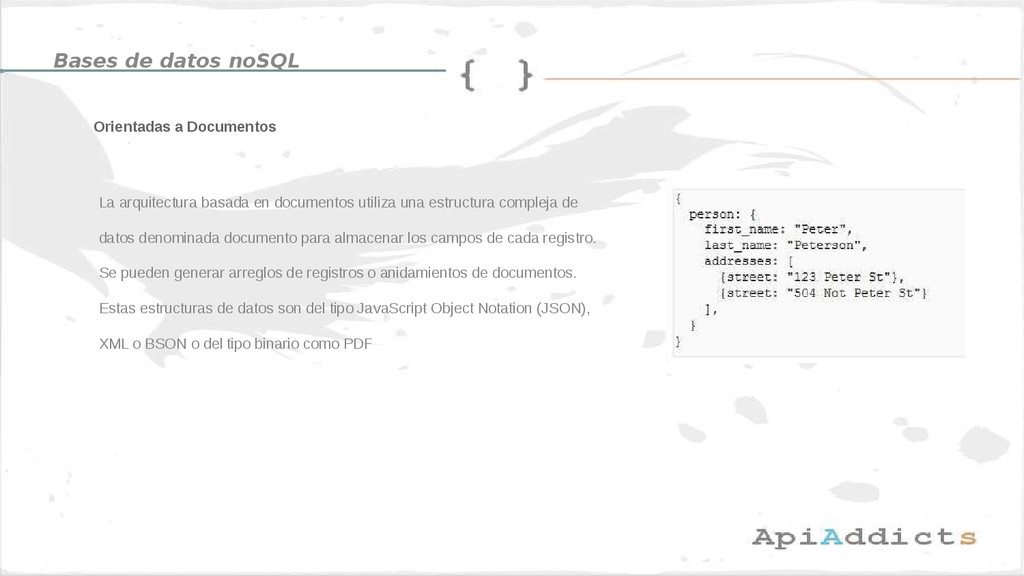{kind=link}
{kind=link}
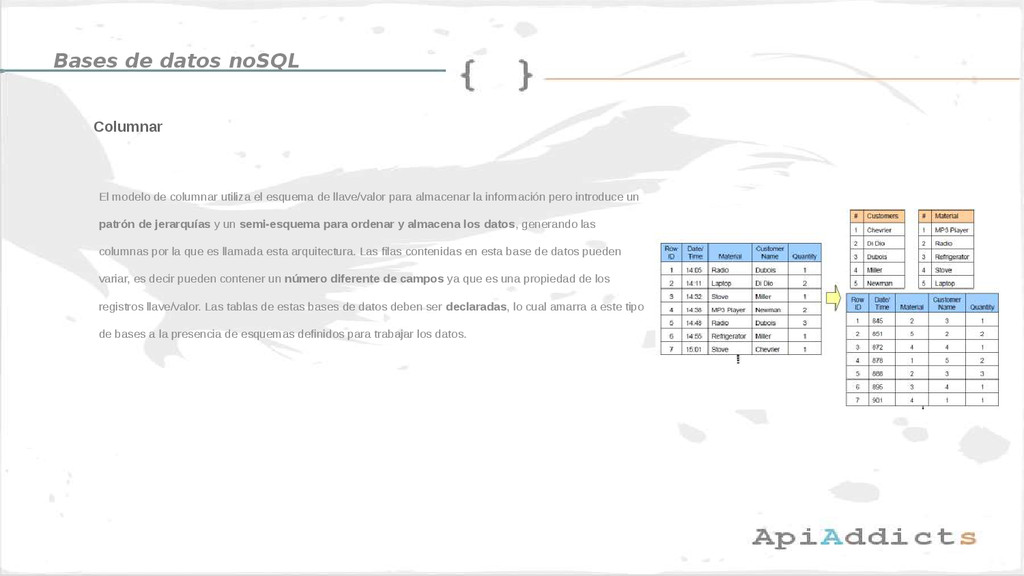{kind=link}
{kind=link}
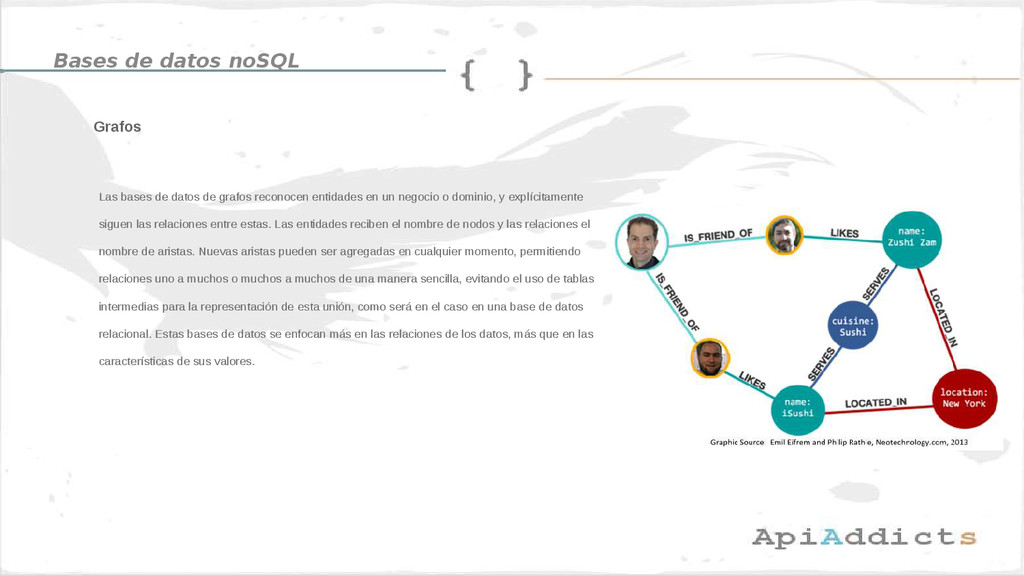{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contacta en: Email: [email protected] Web: http://www.meetup.com/APIAddicts Siguenos en: Linkedin:ApiAddicts Twitter:](https://files.speakerdeck.com/presentations/929199bcefdd48ceac31d489383b5493/slide_43.jpg){kind=link}
{kind=link}