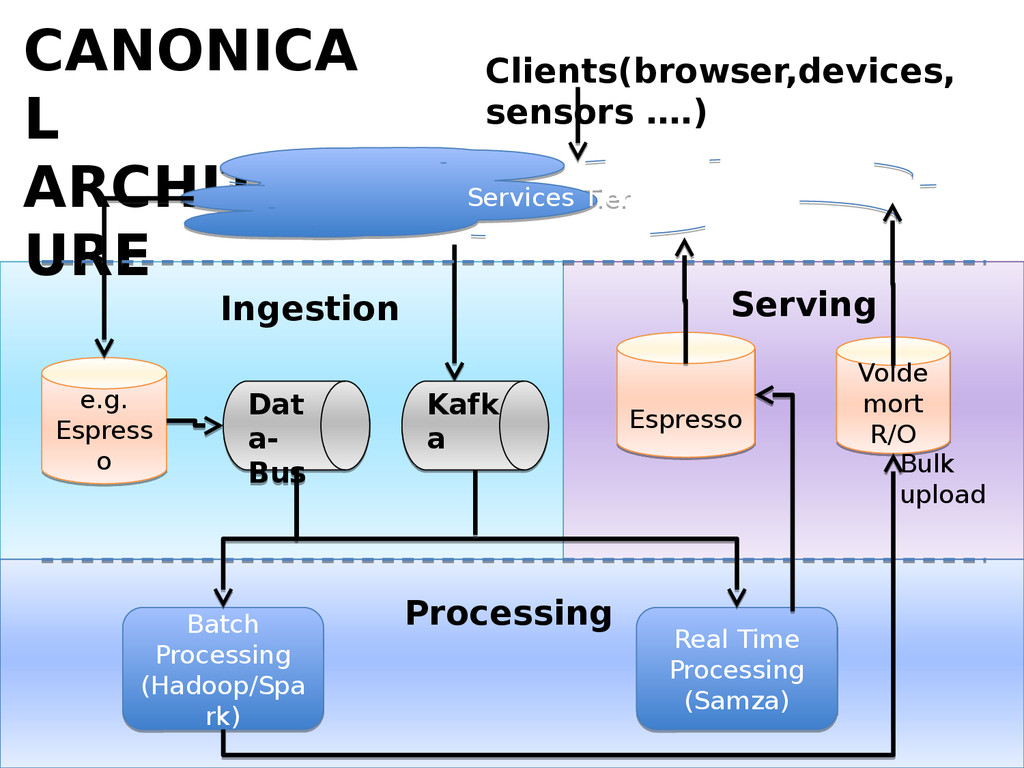
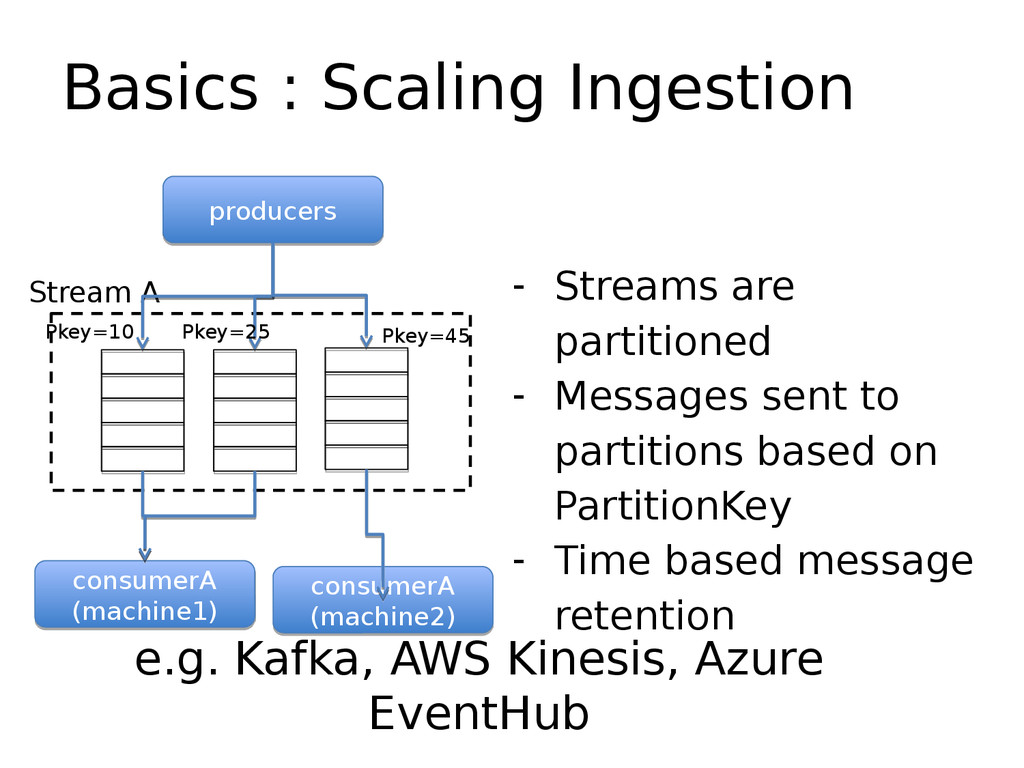
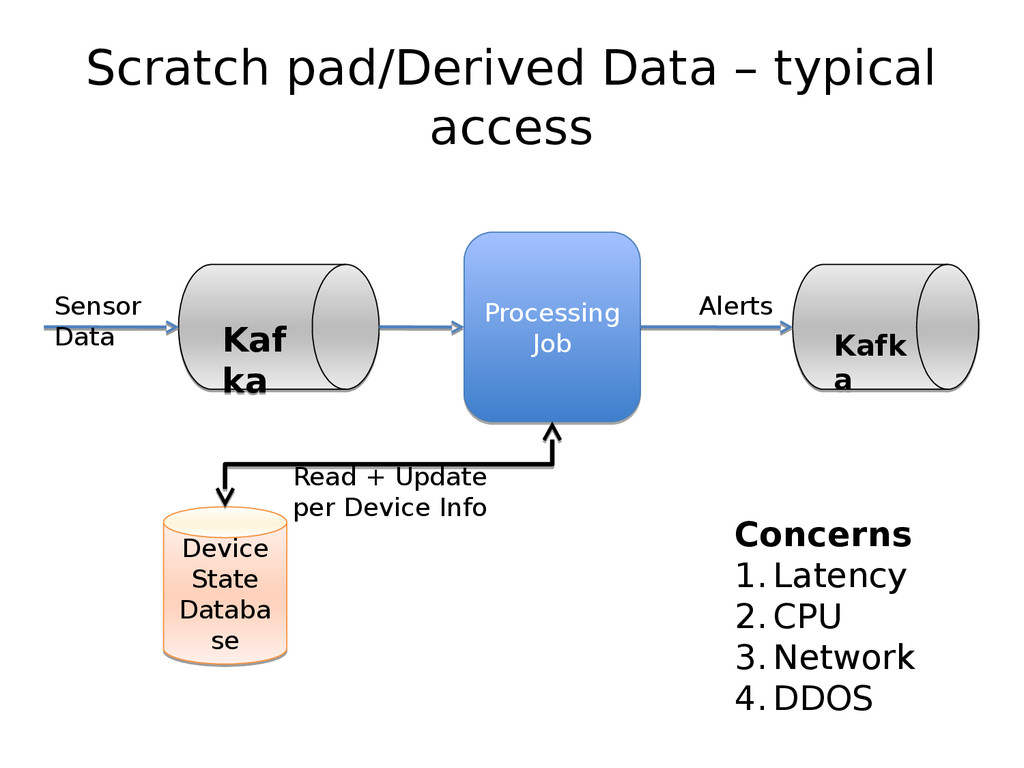
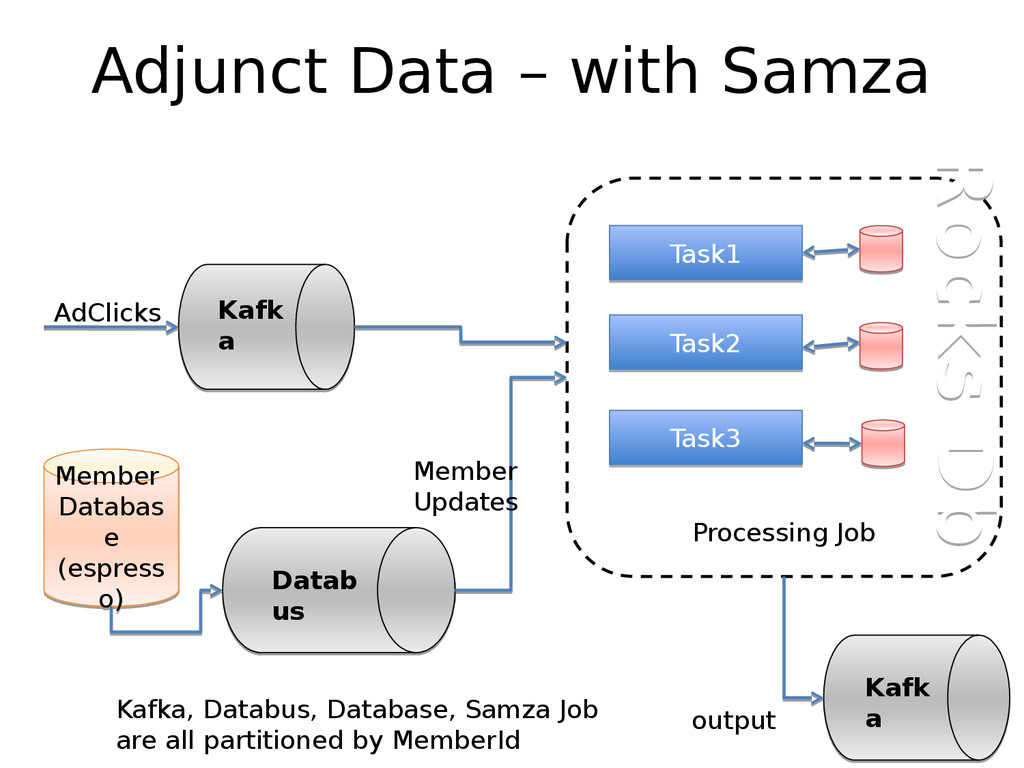
At LinkedIn, we ingest more than 1 Trillion events per day pertaining to user behavior, application and system health etc. into our pub-sub system (Kafka). Another source of events are the updates that are happening on our SQL and No-SQL databases. For e.g. every time a user changes their linkedIn profile, a ton of downstream applications need to know what happened and need to react to it. We have a system (DataBus) which listens to changes in the database transaction logs and makes them available for down stream processing. We process ~2.1 Trillion of such database change events per week.
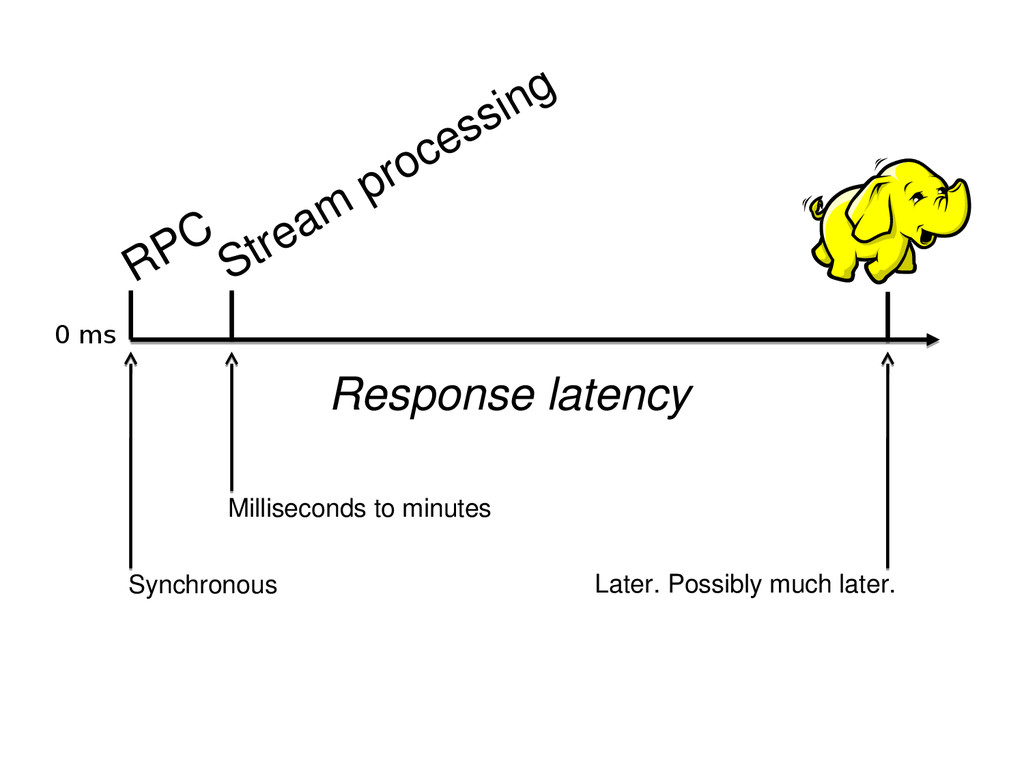
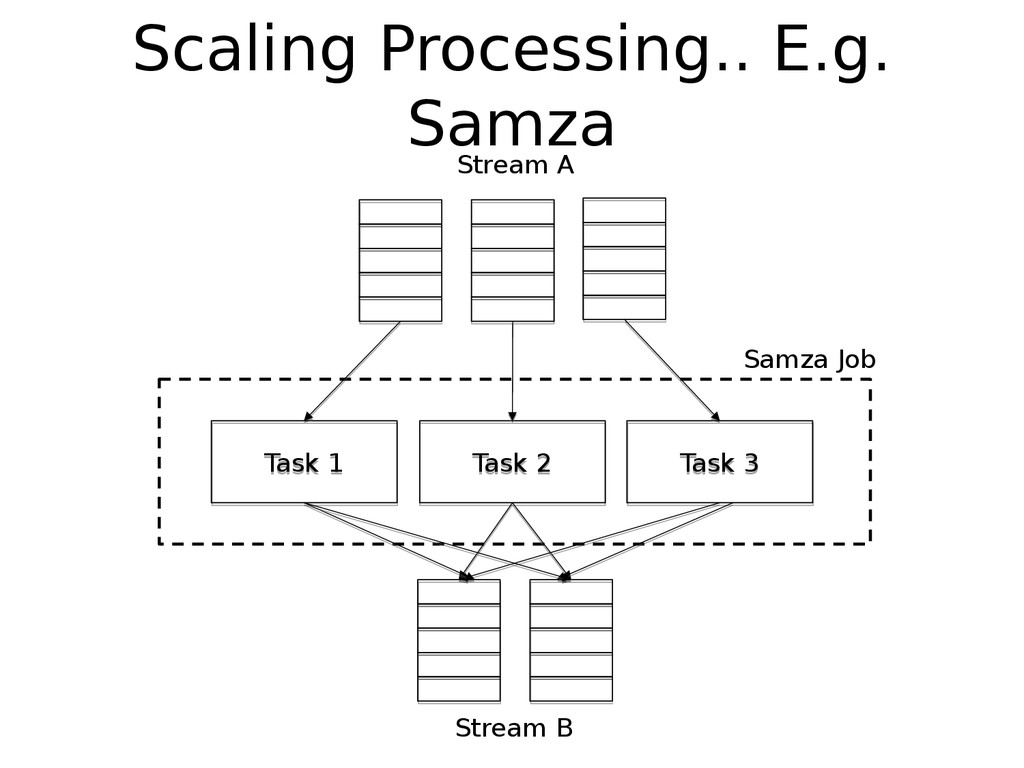
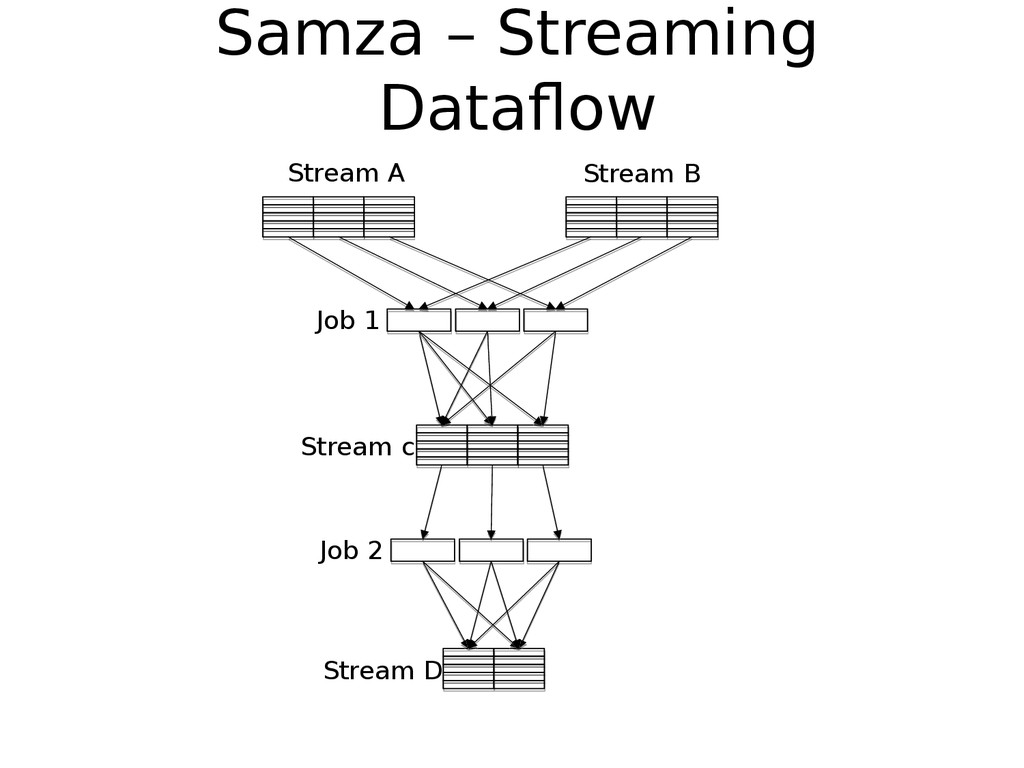
We use Apache Samza for processing these event-streams in real time. In this presentation we will discuss some of challenges we faced and the various techniques we used to overcome them.
Session presented at Big Data Spain 2015 Conference
15th Oct 2015
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.bigdataspain.org/program/thu/slot-3.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
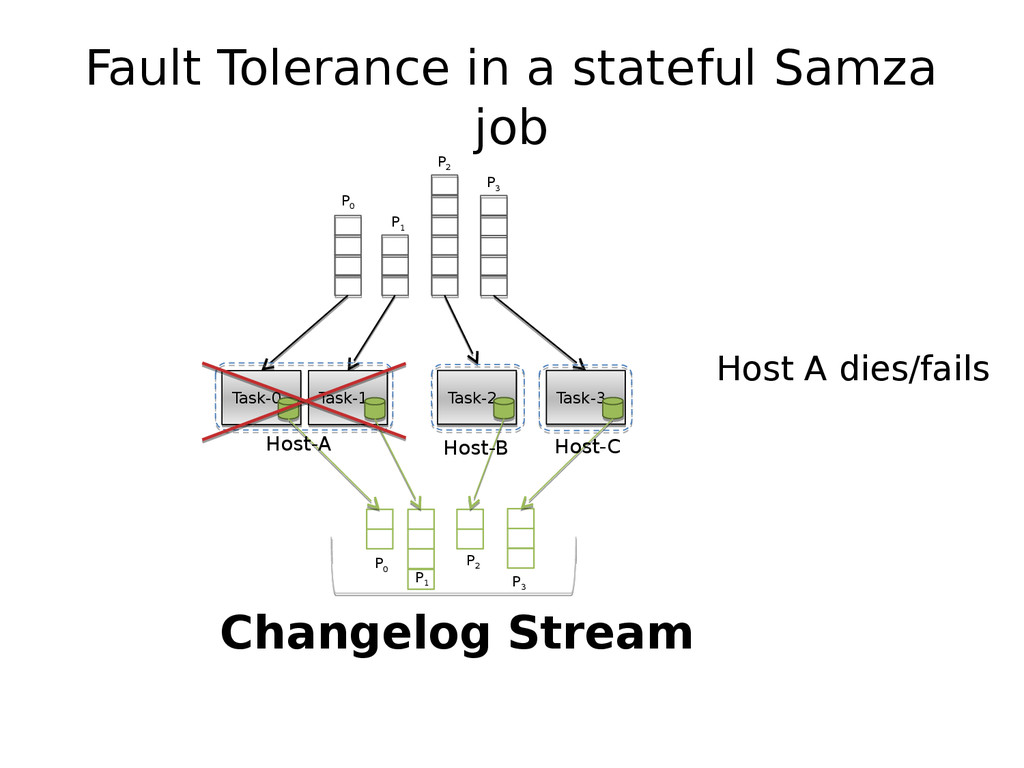{kind=link}
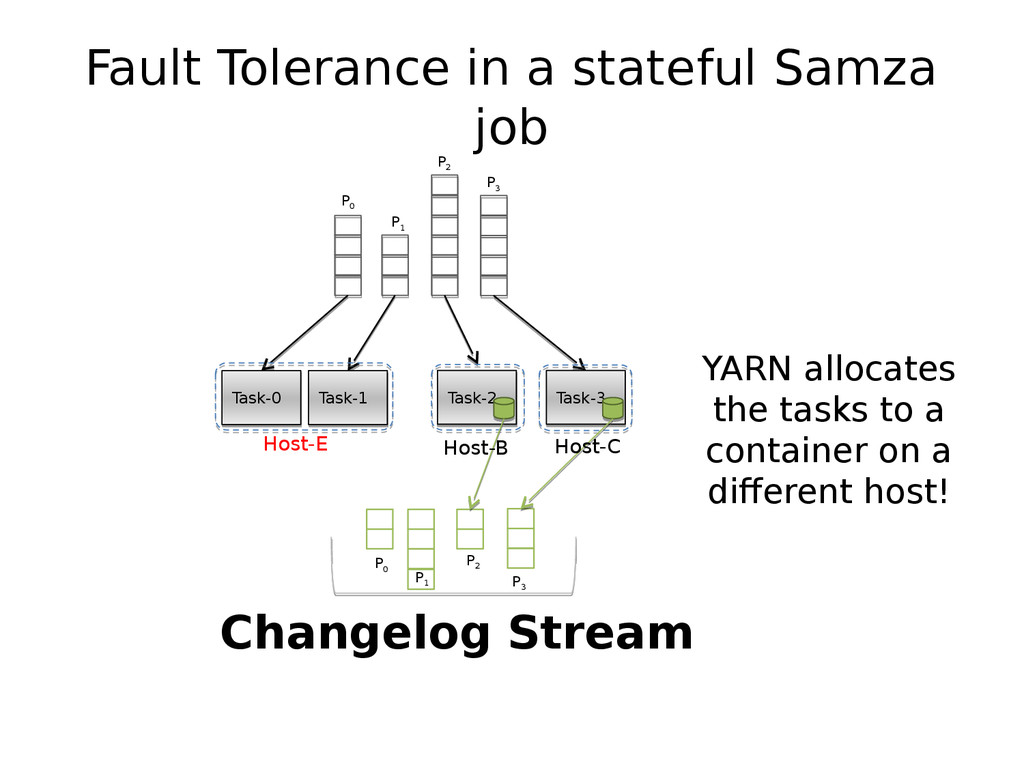{kind=link}
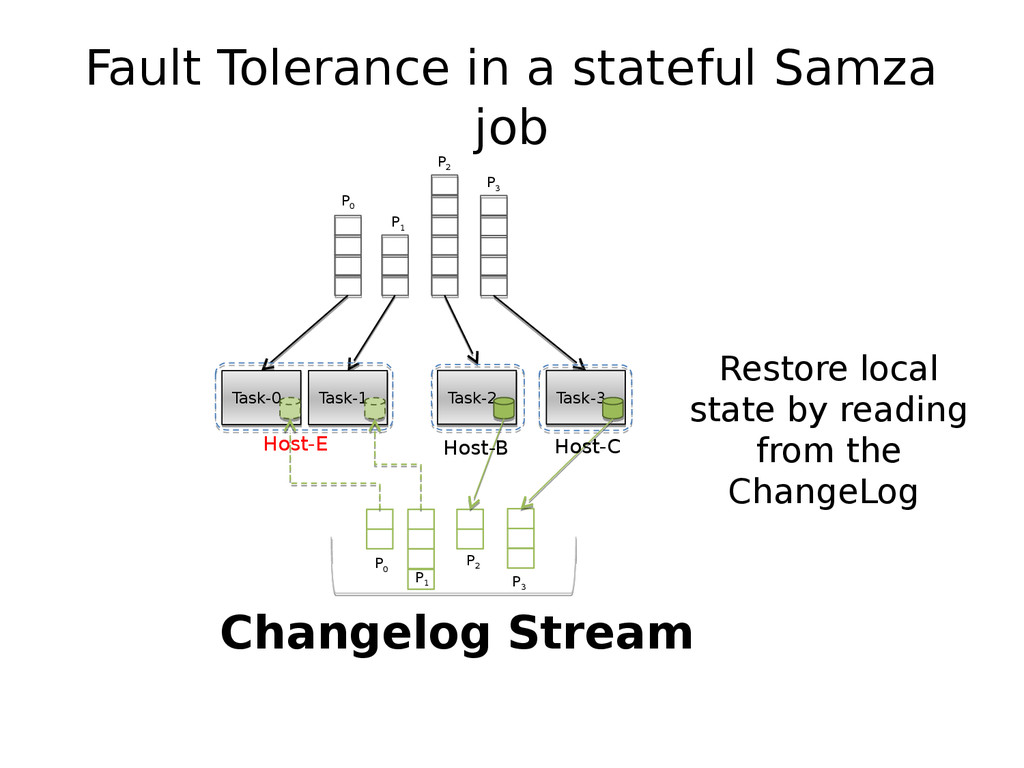{kind=link}
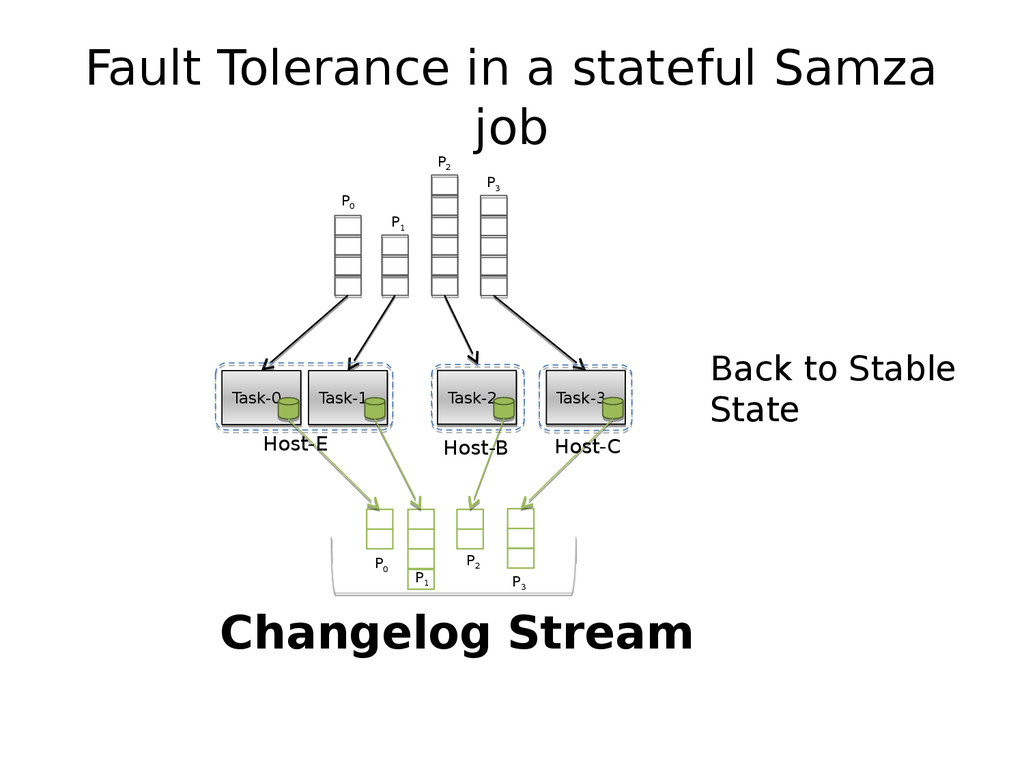{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}