In an era of growing data complexity and volume and the advent of Big Data, feature selection has a key role to play in helping reduce high-dimensionality in machine learning problems.
https://www.bigdataspain.org/2017/talk/feature-selection-for-big-data-advances-and-challenges
Big Data Spain 2017
November 16th - 17th Kinépolis Madrid
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
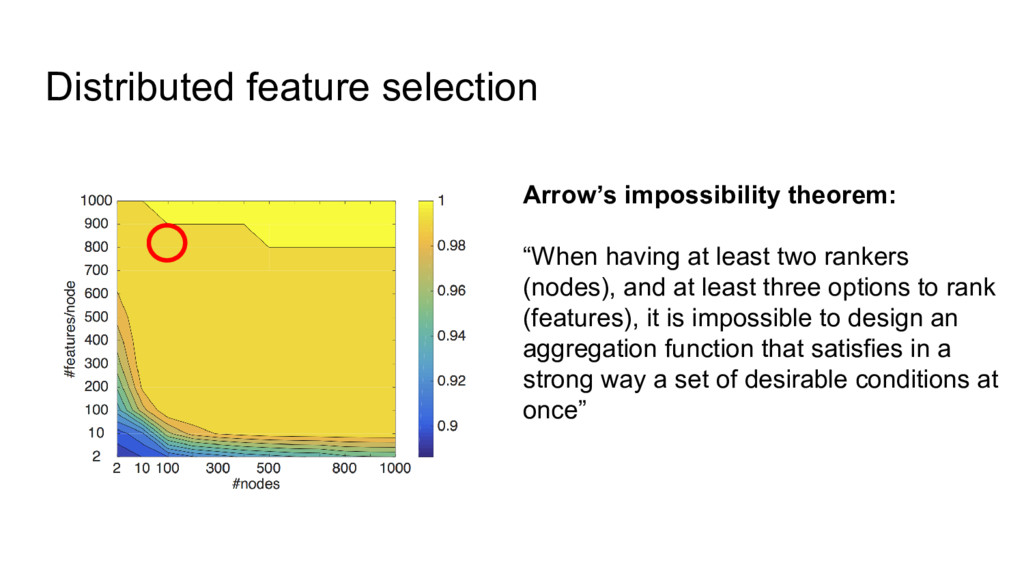{kind=link}
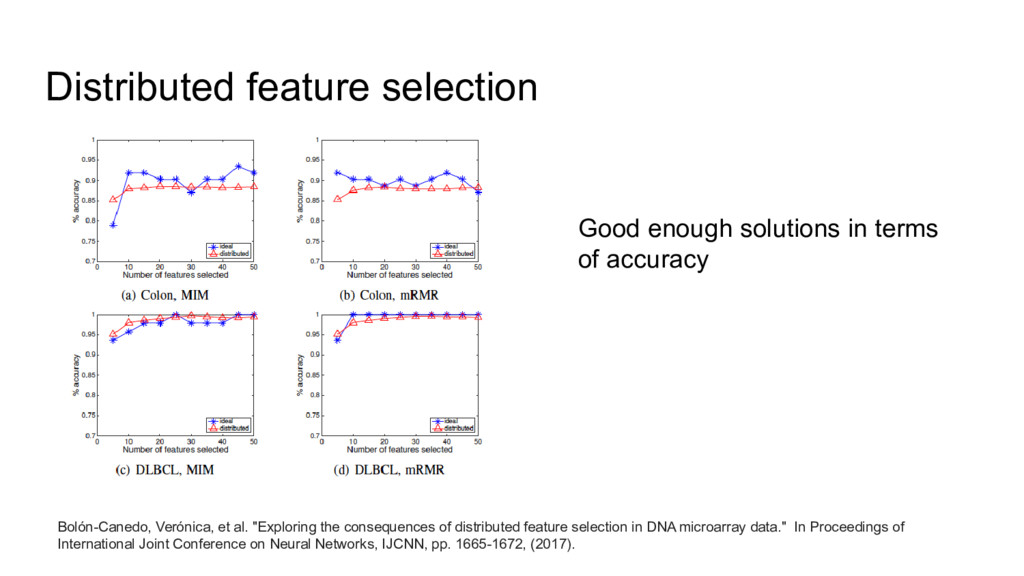{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}