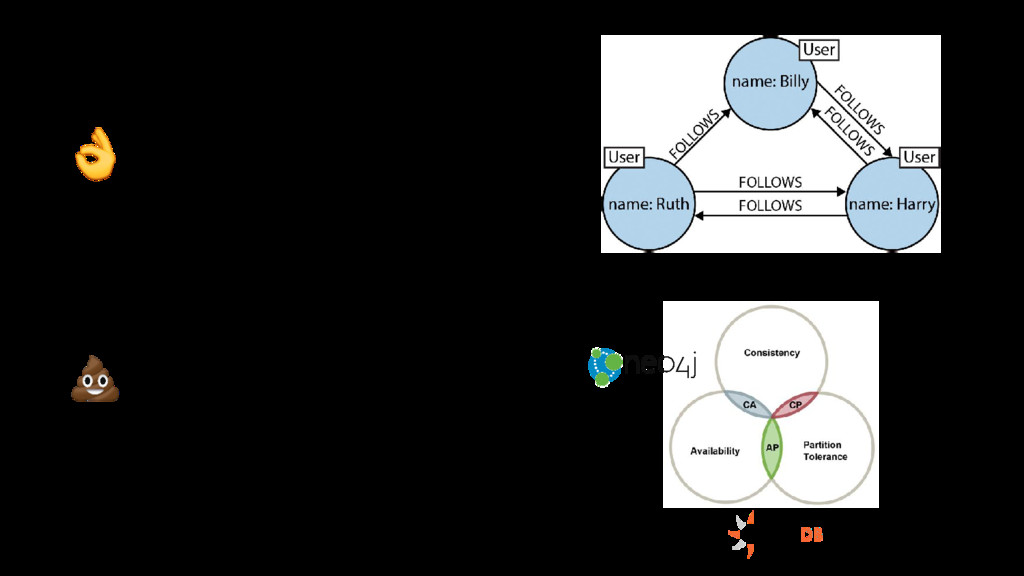
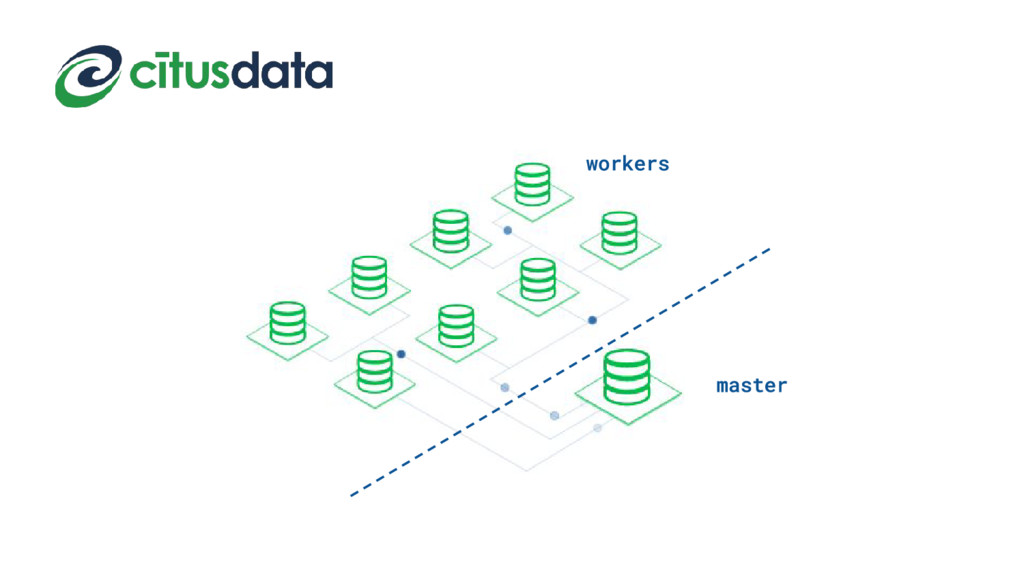
Relational databases were the persistence system of choice for decades, until the Web 2.0 in the 2000s required to process volumes of data so big it needed distributed systems running in parallel. A new type of databases (NoSQL) was adopted to solve this problem in different ways.
https://www.bigdataspain.org/2017/talk/relational-is-the-new-big-data
Big Data Spain 2017
16th - 17th November Kinépolis Madrid
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
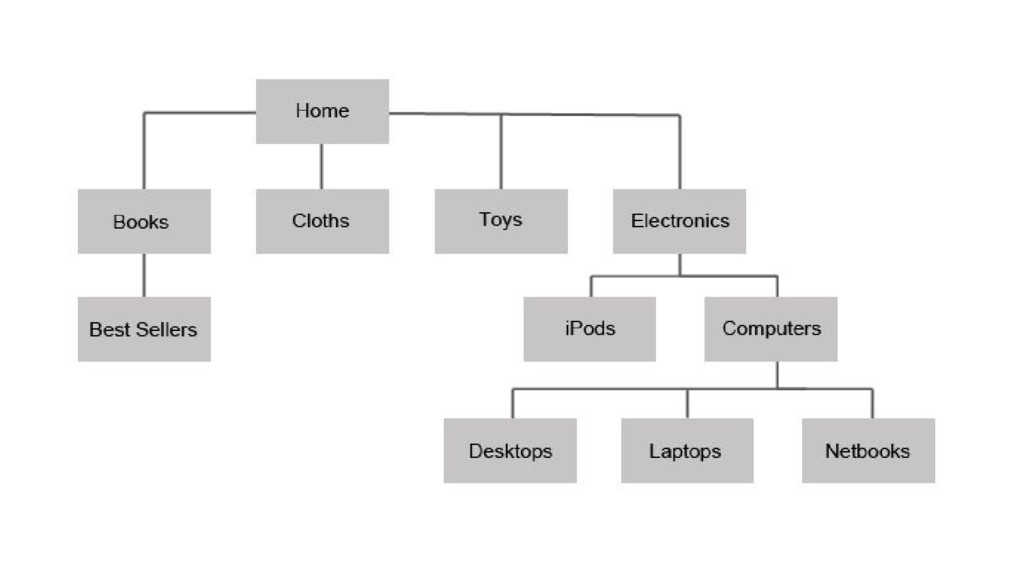{kind=link}
{kind=link}
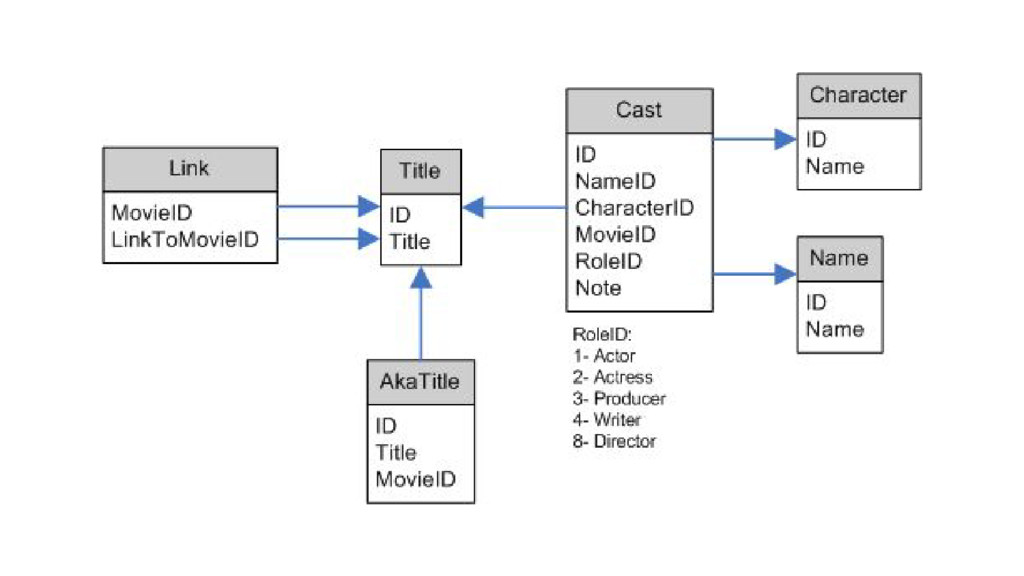{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
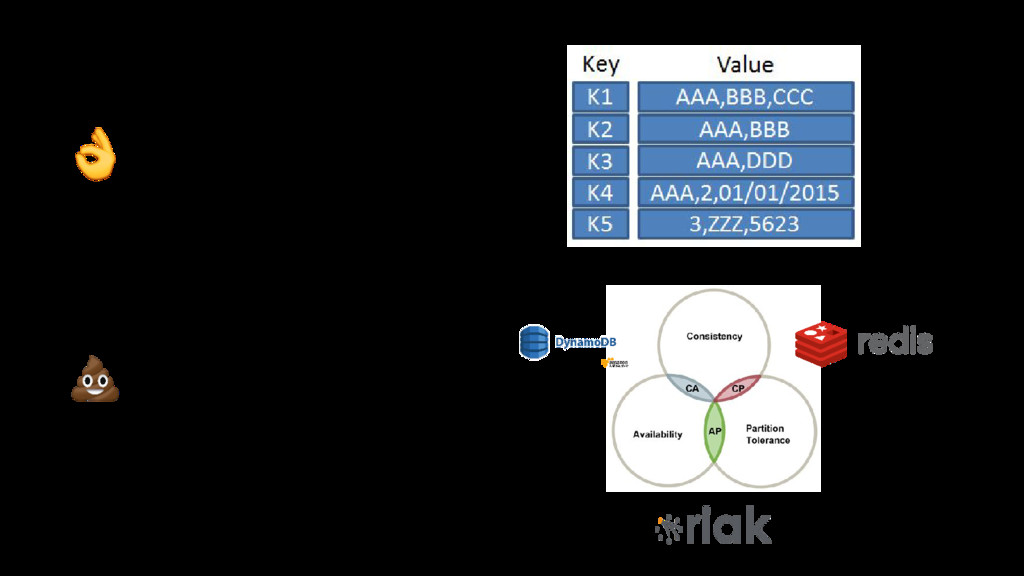{kind=link}
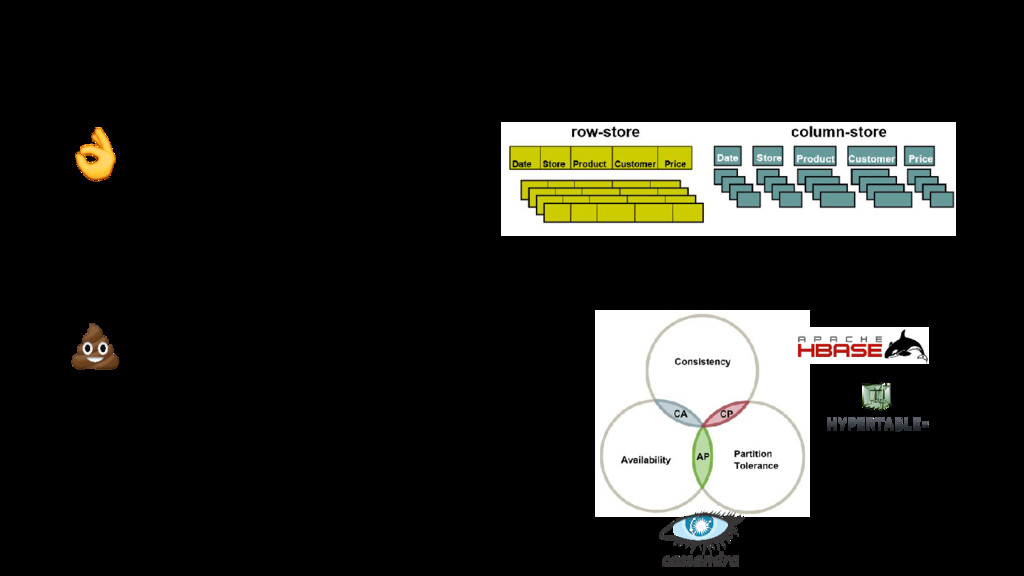{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}