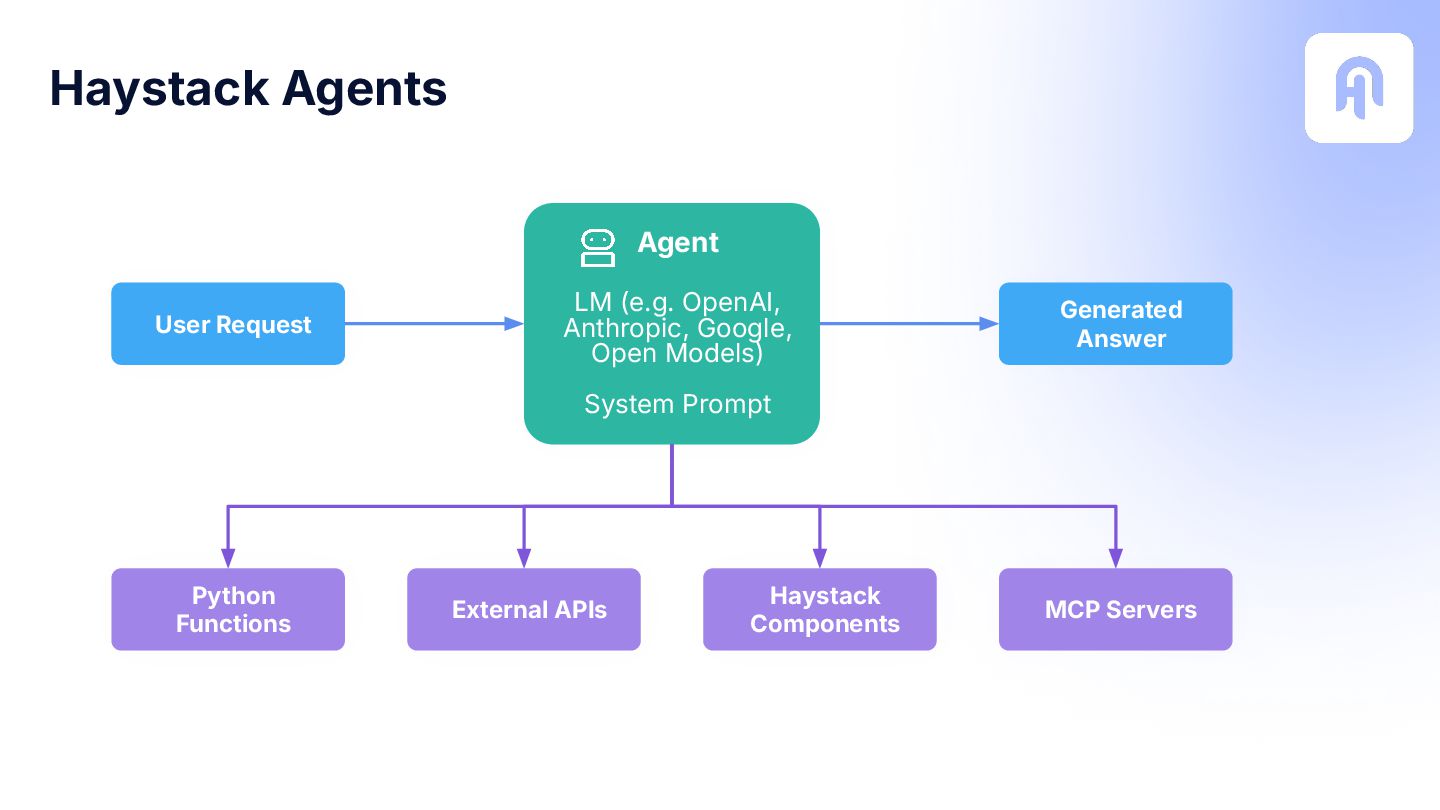
This tutorial shows developers how to build multimodal, vision-enabled agents with Haystack, combining LLM reasoning with visual understanding. In this session, you’ll learn to:
- Extend agents with vision-language models to process images and PDFs, then build an end-to-end agent that answers from text + visuals.
- Deploy your multimodal agent with tools like Open WebUI and Hayhooks for real-world use.
Colab notebook: https://github.com/bilgeyucel/presentations/blob/main/agentic_ai_conference_2025/Multimodal_Agent.ipynb
Multimodal Agent demo: https://github.com/deepset-ai/haystack-demos/tree/main/multimodal_agent
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}