the index is calculated by a hash function Instead of having to search through the table, comparing the search key to the search key of each item, we can use a hash function on the search key to quickly calculate the index of the item
Could store everyone’s records with name, address, and telephone number using telephone numbers as search key Could use entire telephone number, but wastes too much space (10,000,000,000 array elements)
Better to use last four digits of telephone number (10,000 array elements) For example, use table[4567] rather than table[8081234567] to access records
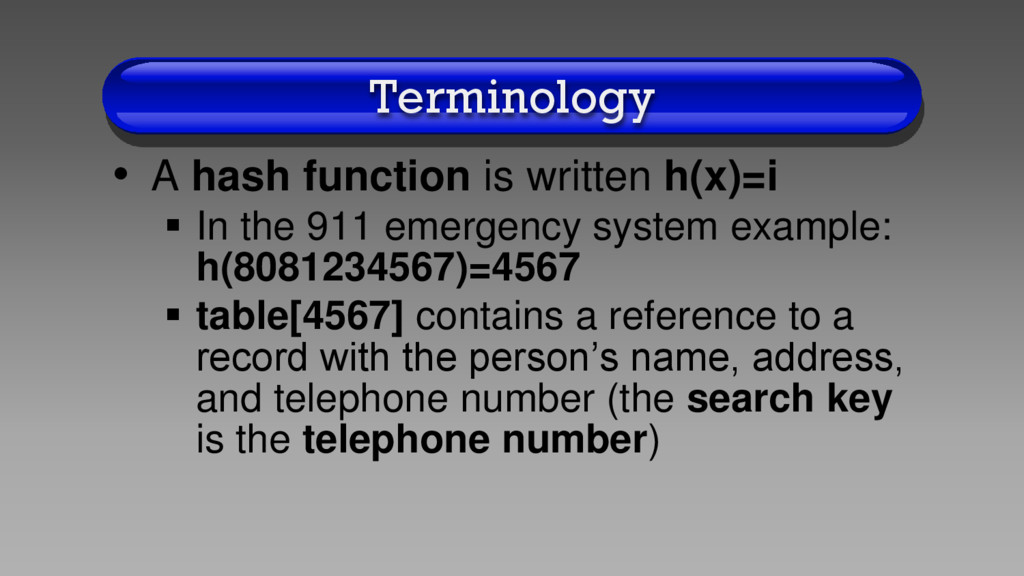
is the name of the function x is the record search key i is the location (index) in the hash table (typically an array) Once i is calculated, then table[i] contains a reference to the corresponding record
the 911 emergency system example: h(8081234567)=4567 table[4567] contains a reference to a record with the person’s name, address, and telephone number (the search key is the telephone number)
& easy to calculate, but usually does not distribute randomly The first three numbers of a social security number are based on location, so people of the same state usually have the same first three numbers for the SS#
digits of the integer together For example, if you have the SS#123- 45-6789, add all the digits together h(123456789)=1+2+3+4+5+6+7+8+9 =45 with hash table index range 0 < h(search key) < 81
in different ways to adjust to hash tables of different sizes (different index ranges) h(123456789)=123+456+789=1368 with hash table index range 0 < h(search key) < 2997
which returns the remainder of a division • int i = 4 % 5; //4 • i = 9 % 5; //4 • i = 19 % 6; //1 • i = 0 % 6; //0 • i = 1 % 7 //1 • i = 7 % 7 //0 • i = 50 % 7 //1
a prime number as tableSize reduces collisions For tableSize = 31, h(123456789) = 123456789 mod 31 = 2 with hash table index range 0 < h(search key) < 30
be designed to operate on integers Although objects such as strings can be used as a search key, they can be easily converted into an integer value Then apply hash function to the integer value
to an integer 1. Assign A to Z the numbers 0 to 25, and add the integers together 2. Use the ASCII or Unicode integer value for each character, and add the integers together
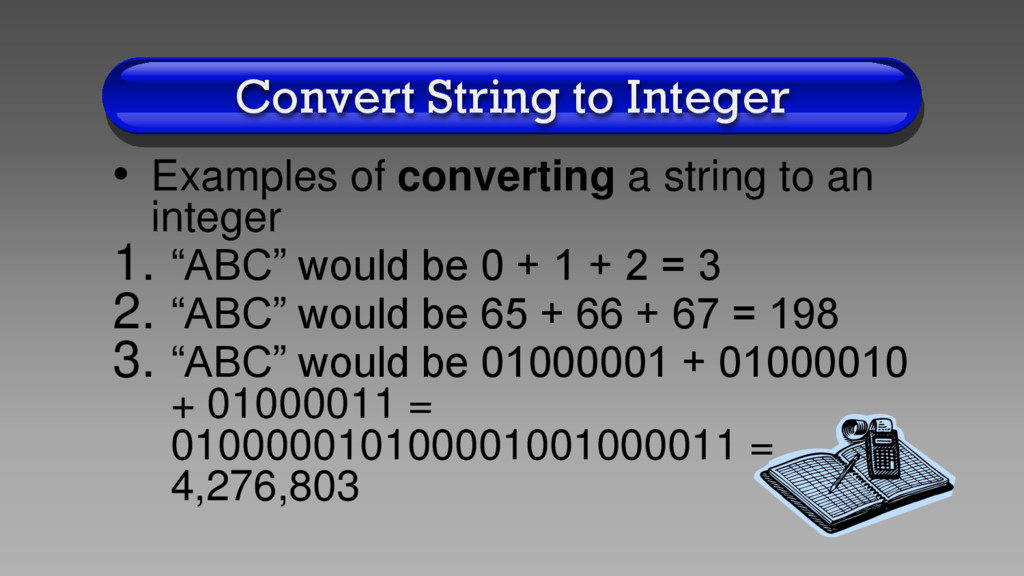
to an integer 1. “ABC” would be 0 + 1 + 2 = 3 2. “ABC” would be 65 + 66 + 67 = 198 3. “ABC” would be 01000001 + 01000010 + 01000011 = 010000010100001001000011 = 4,276,803
object is computed as s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] using int arithmetic, where s[i] is the ith character of the string, n is the length of the string, and ^ indicates exponentiation. (The hash value of the empty string is zero.)
ICS 211 students based on student ID Student ID has 8 digits, so need array of size 100,000,000 This is a waste of space, so instead use an array of size 31, with hash function h(x) = x mod 31
resolution scheme must be implemented • Collision resolution: assigns the search keys with the same hash function to different locations in the hash table
placed evenly in the hash table in order to avoid these collisions • Two main approaches to collision resolution 1. Open addressing 2. Restructure the hash table
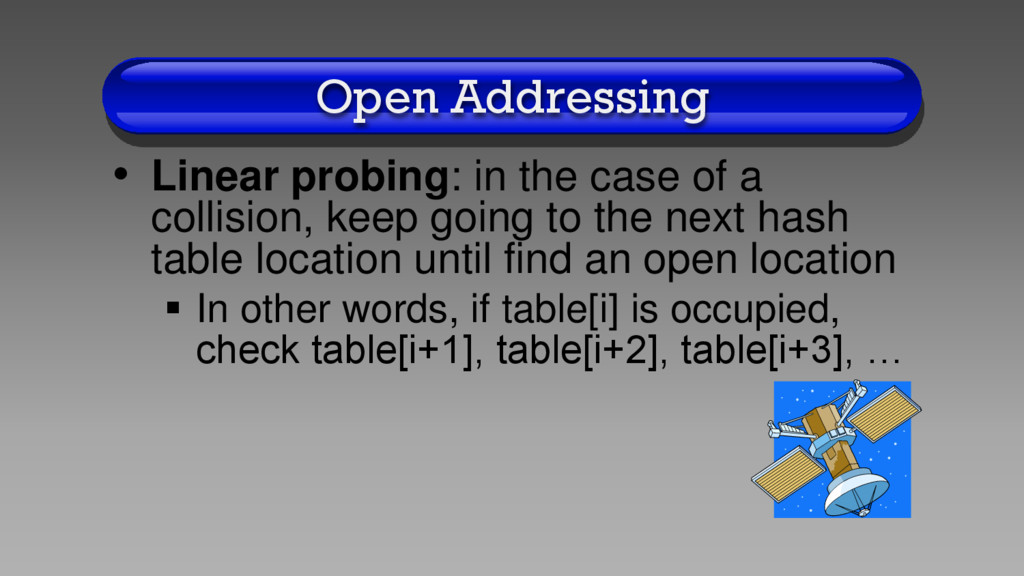
collision, keep going to the next hash table location until find an open location In other words, if table[i] is occupied, check table[i+1], table[i+2], table[i+3], …
= 4055 mod 31 = 25 We have a collision with Sally Suzuki’s record, which is also stored index 25 So we add one to the number • Put Bubba Smith’s record at index 26 table[26] = 4055, Bubba Smith, 3.9
location sequentially, check the next location based on a sequence of squares In other words, if table[i] is occupied, check table[i+12], table[i+22], table[i+32], table[i+42], table[i+52], …
(called “secondary clustering”), but this method is not as problematic as linear probing It is possible that an item cannot be inserted, even when the table is not full, so it may have wasted space
second hash function determines the step size to next hash table index • Some restrictions h2(searchKey) != 0 (step size should not be zero) h2 != h1 (avoids clustering)
reduce collisions When increasing the size, the hash function needs to be reapplied to every item in the old hash table to place it in the new hash table
that has an array at each location table[i], so that items of the same hash index are stored here • Choosing the size of the bucket is problematic If too small, will have collisions If too big, will waste space
that has linked list (a chain) at each location table[i], so that items of the same hash index are stored here Size of the table is dynamic Less problematic than static bucket implementation
calculate the average case efficiency of hashing Load factor = number of items / table size Load factor should stay below 2/3 Unsuccessful searches generally take longer than successful searches
1.Do the assignment corresponding to this lecture 2.Email me any questions you may have about the material 3.Turn in the assignment before the next lecture 4.Be a slacker and go surfing!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Open Addressing • h(1234) = 25 table[25] = 1234 •](https://files.speakerdeck.com/presentations/3702ef701dea013278dd06e915146373/slide_40.jpg){kind=link}
{kind=link}
![Open Addressing • h(1234) = 25 table[25] = 1234 •](https://files.speakerdeck.com/presentations/3702ef701dea013278dd06e915146373/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Open Addressing • h(1234) = 25 table[25] = 1234 •](https://files.speakerdeck.com/presentations/3702ef701dea013278dd06e915146373/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Open Addressing • h1(1234) = 25 table[25] = 1234 •](https://files.speakerdeck.com/presentations/3702ef701dea013278dd06e915146373/slide_51.jpg){kind=link}
![Open Addressing • h1(1766) = 30 table[30] = 1766 •](https://files.speakerdeck.com/presentations/3702ef701dea013278dd06e915146373/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Restructuring the Hash Table • h(1234) = 25 table[25][0] =](https://files.speakerdeck.com/presentations/3702ef701dea013278dd06e915146373/slide_59.jpg){kind=link}
{kind=link}
{kind=link}
![Restructuring the Hash Table • h(1234) = 25, table[25]=>1234 •](https://files.speakerdeck.com/presentations/3702ef701dea013278dd06e915146373/slide_62.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}