API (feline love for the dev op) Distributed Percolation (put some nitro in your coffee) Snapshot & Restore (point in time, API driven backup) Federated search (get your results from multiple clusters) many, many more (memory circuit breaker, geo points compression, major improvement in allocation decision speed, ….)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
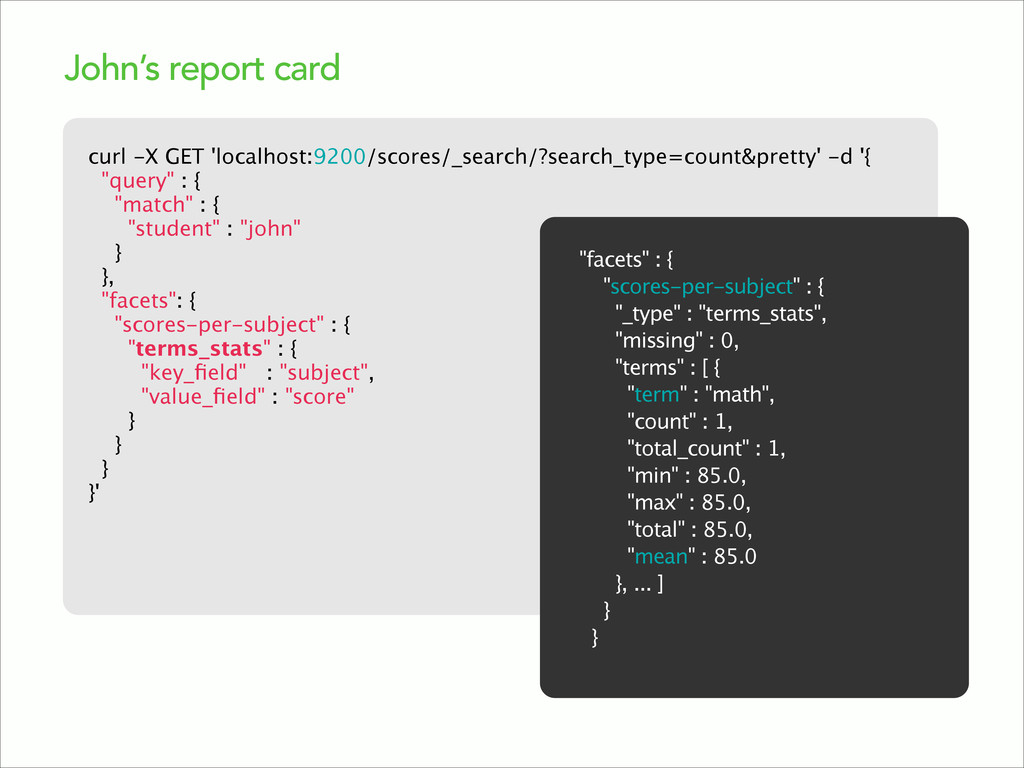{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
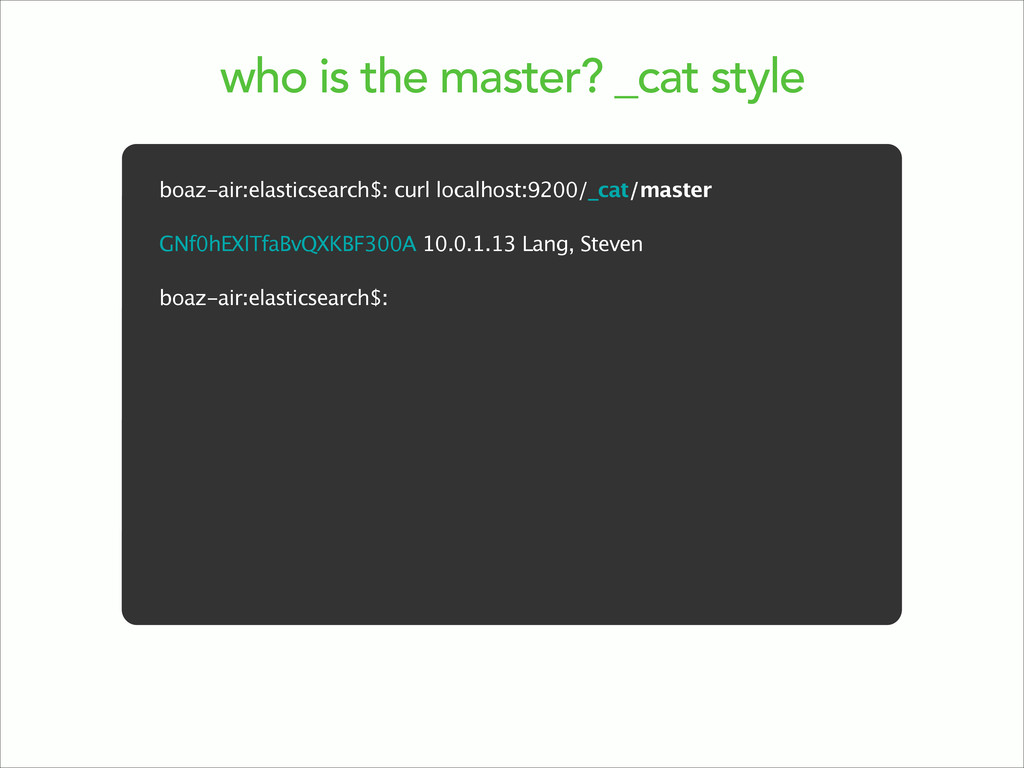{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}