Elasticsearch is famous for being easy to set up and for having good defaults. A single node can go a long way and a handful of nodes will deliver a surprising punch. However, there comes a point where generic defaults become less than ideal and cluster architecture starts to matter. In this session, we will talk about capacity planning and custom setups suitable for large Elasticsearch deployments.
The talk was given at the Elasticsearch meetup in Tel Aviv on 24 Nov 2014
{kind=link}
{kind=link}
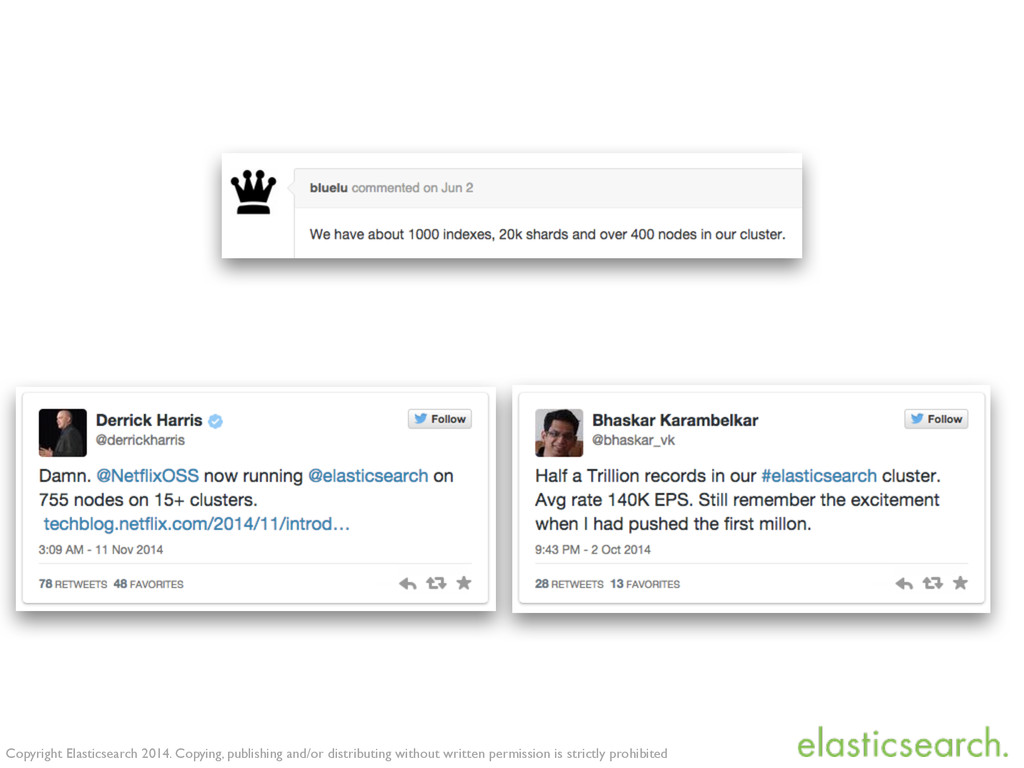{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
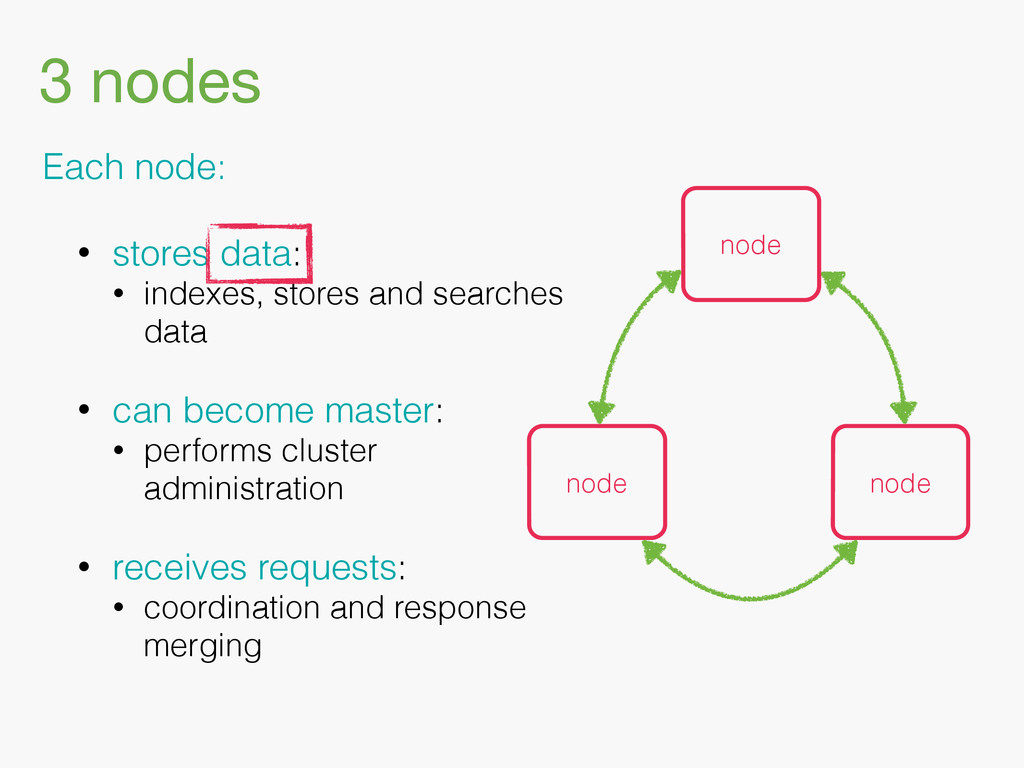{kind=link}
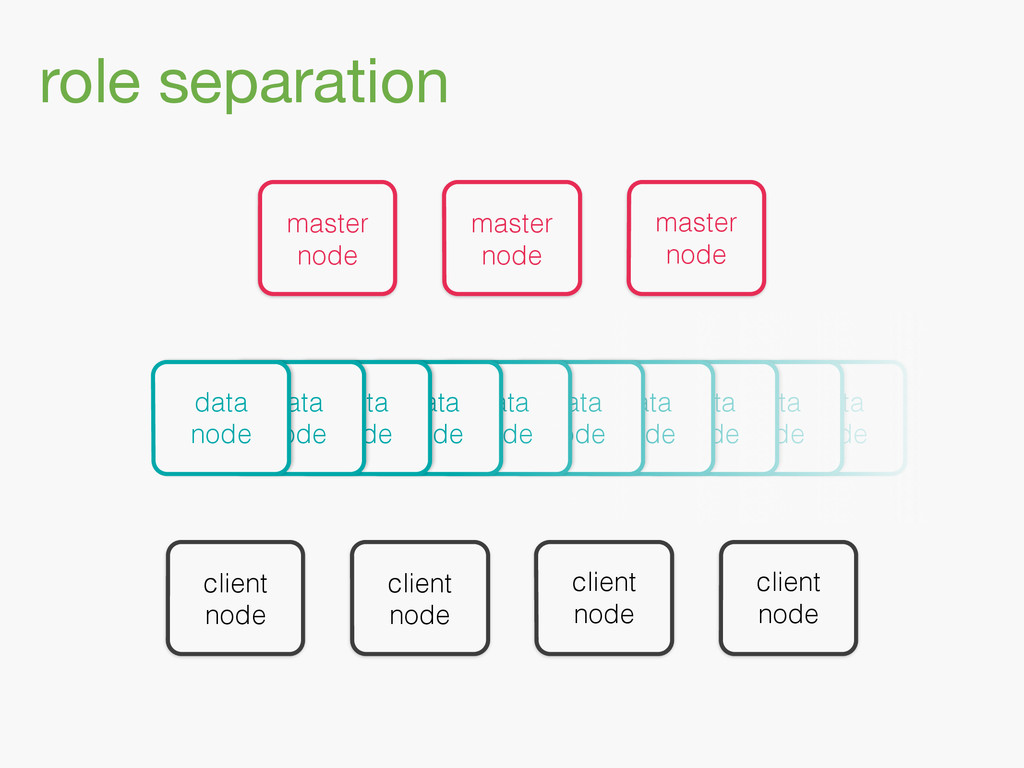{kind=link}
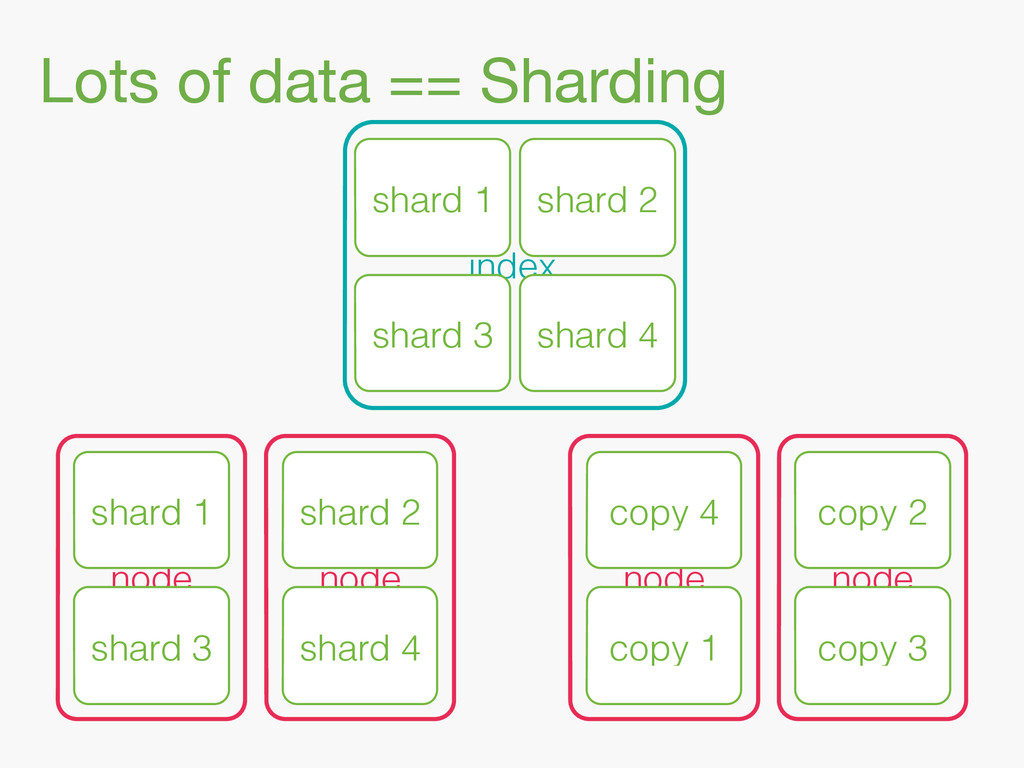{kind=link}
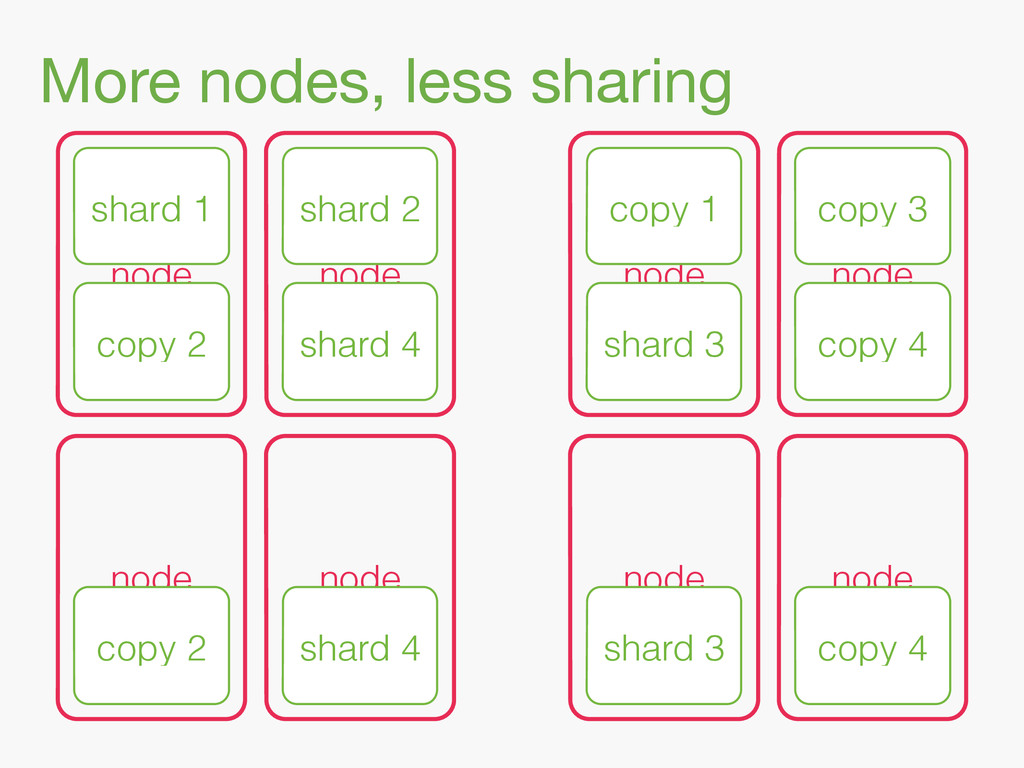{kind=link}
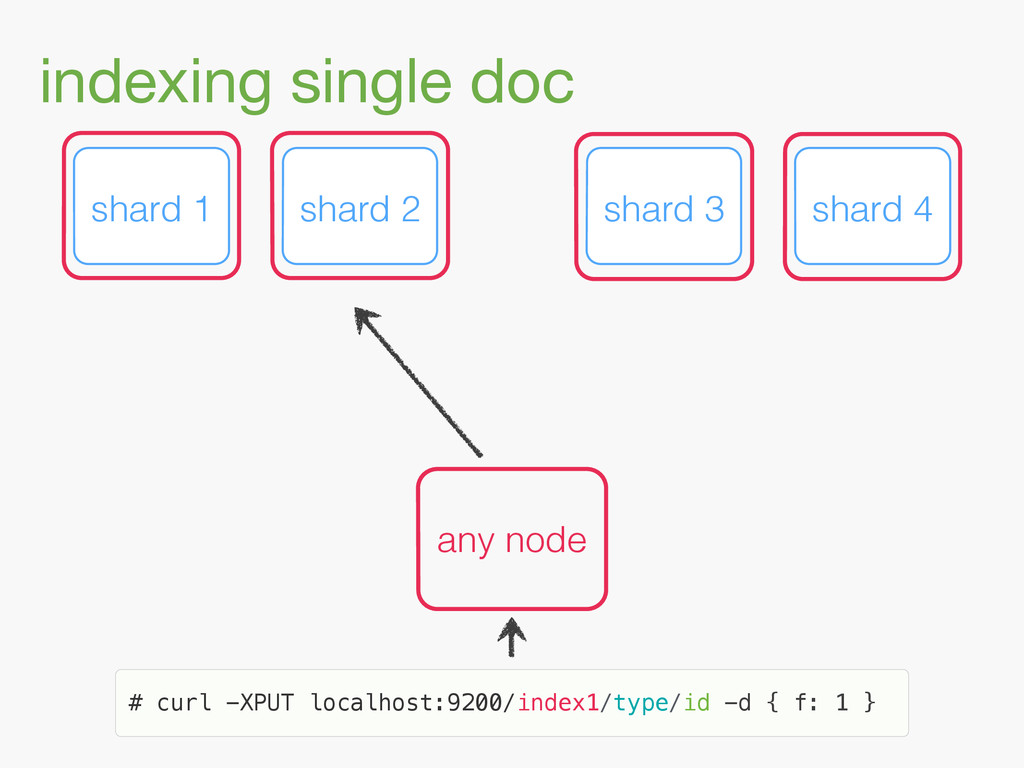{kind=link}
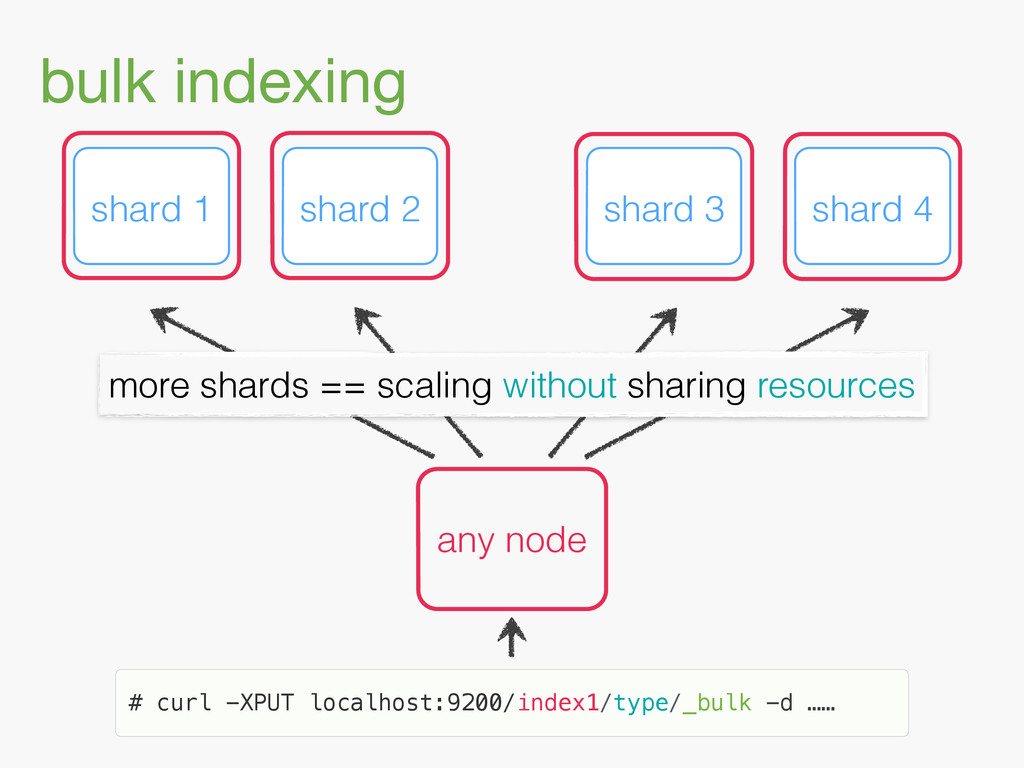{kind=link}
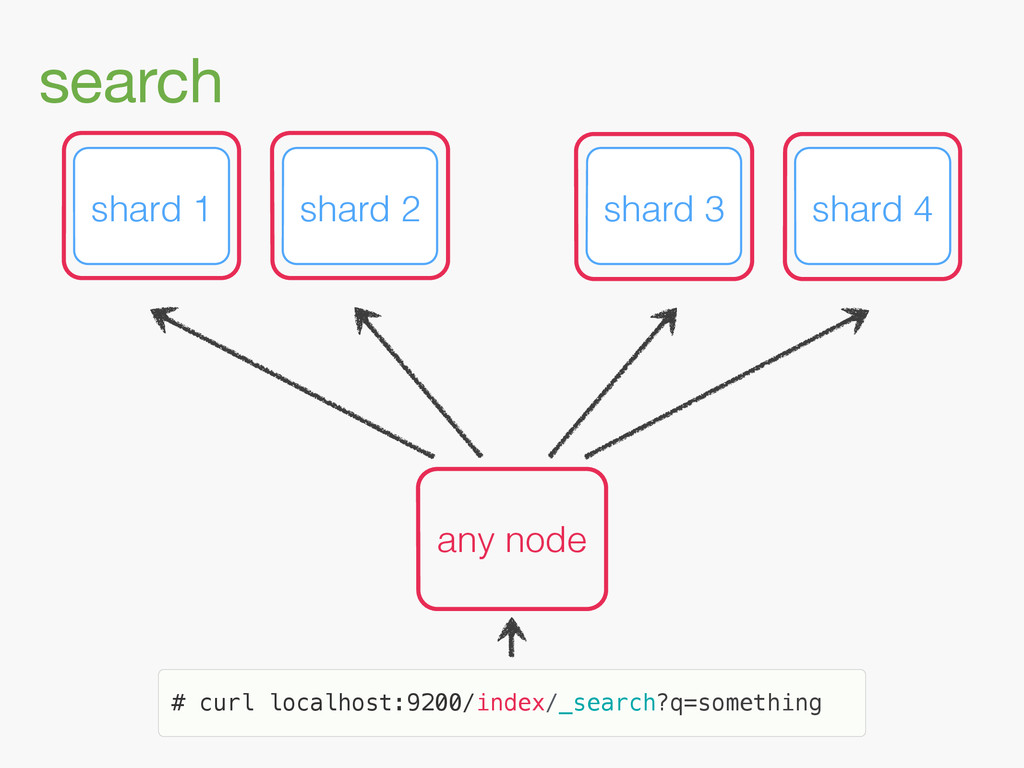{kind=link}
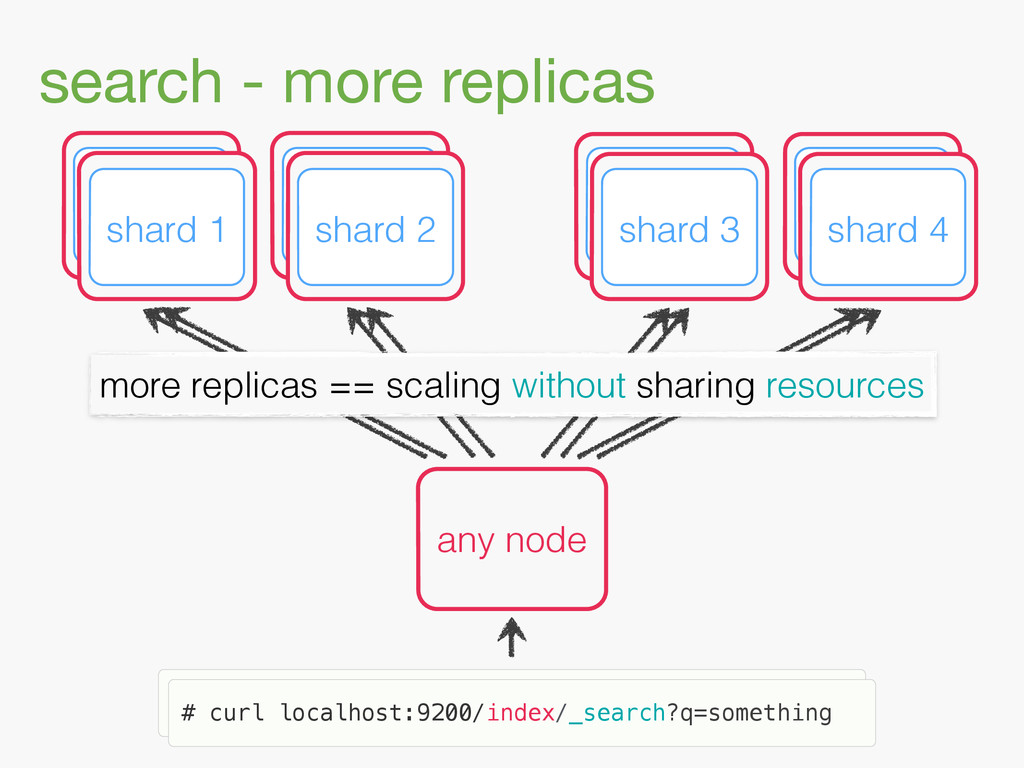{kind=link}
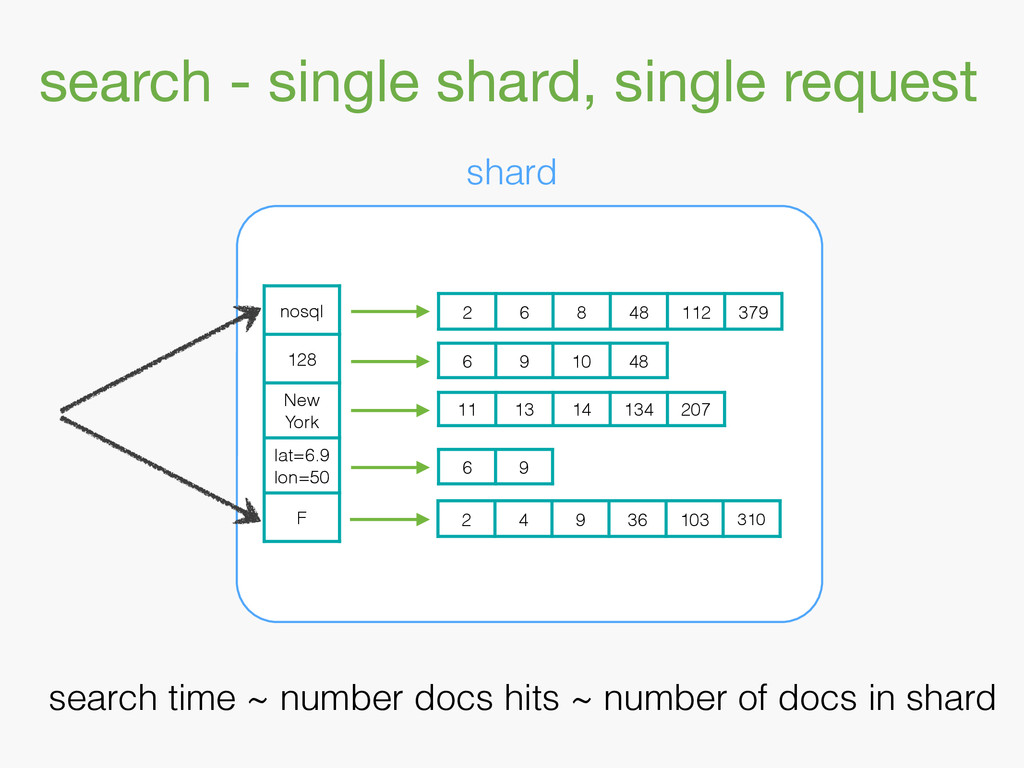{kind=link}
{kind=link}
{kind=link}
{kind=link}
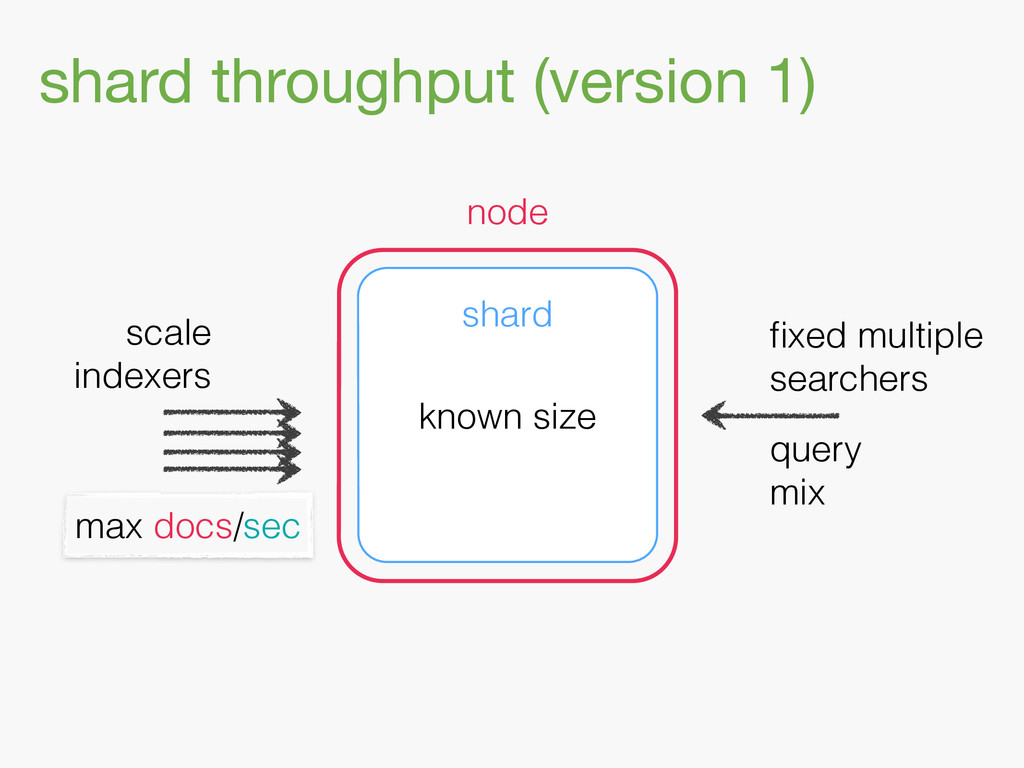{kind=link}
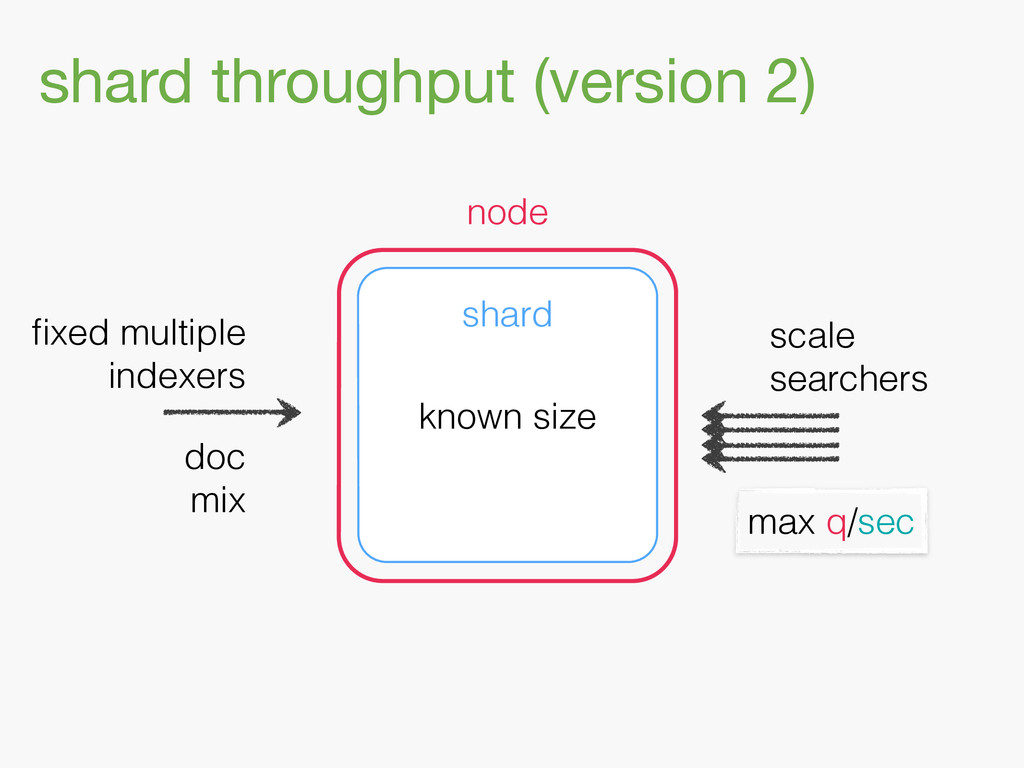{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}