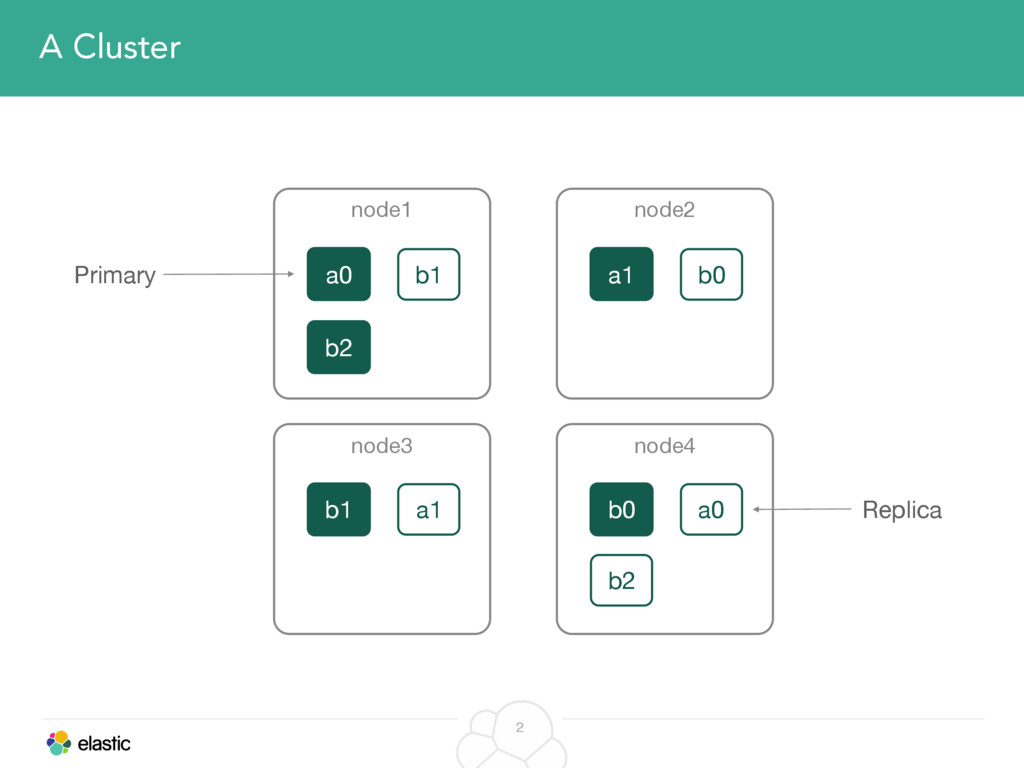
This talk was given at the Elastic meetup in Tel Aviv. The talk is about the journey of a shard in Elasticsearch. It will cover the mechanics and the reasons for how ES decides to allocate shards to nodes and how those decisions are executed.
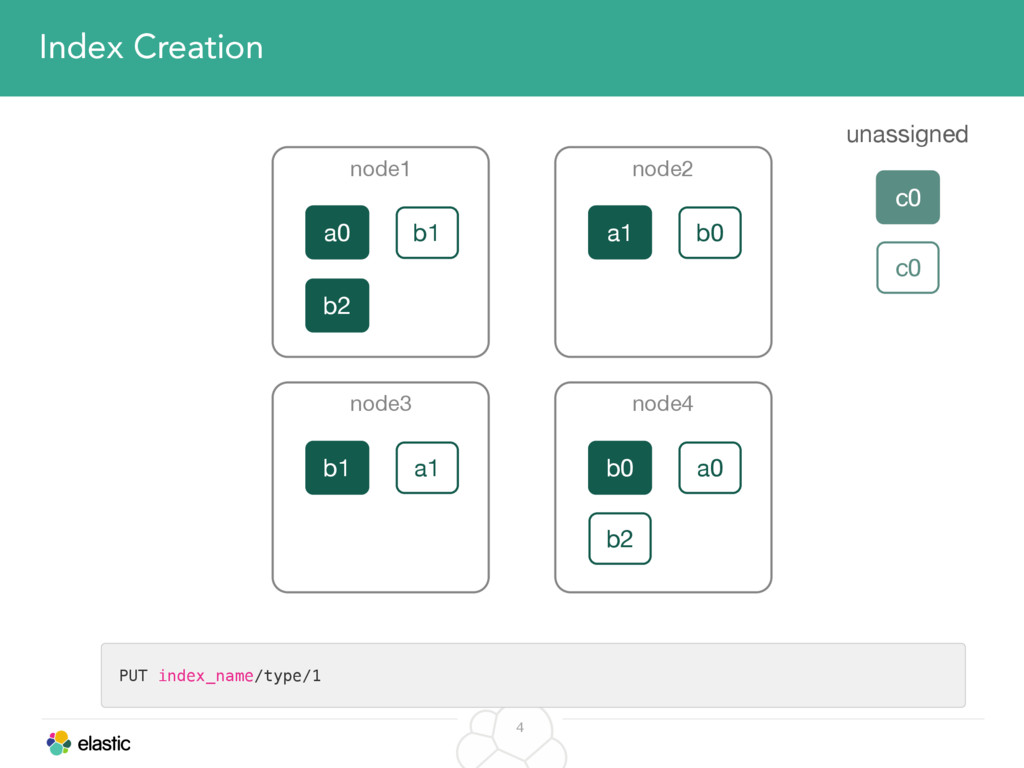
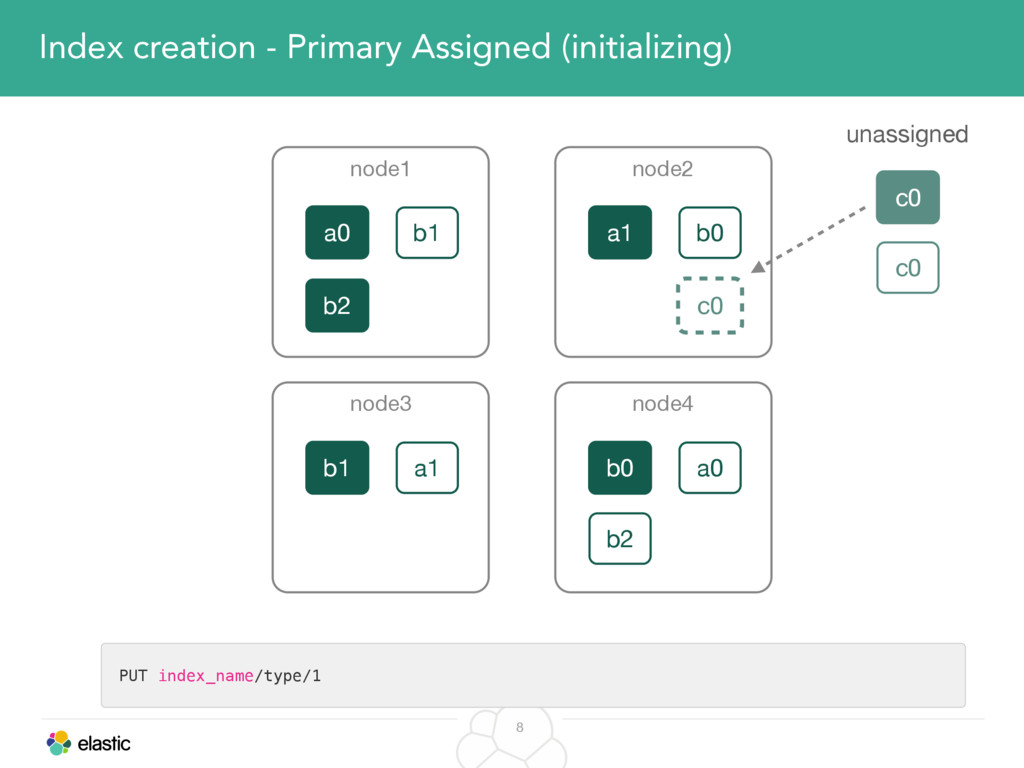
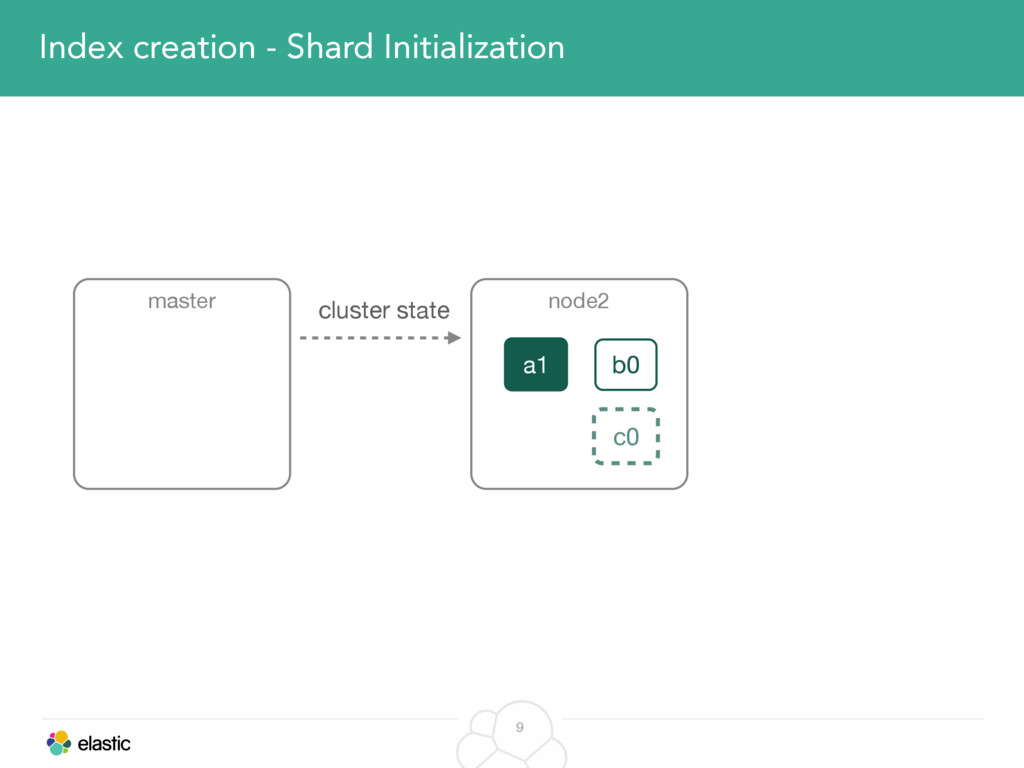
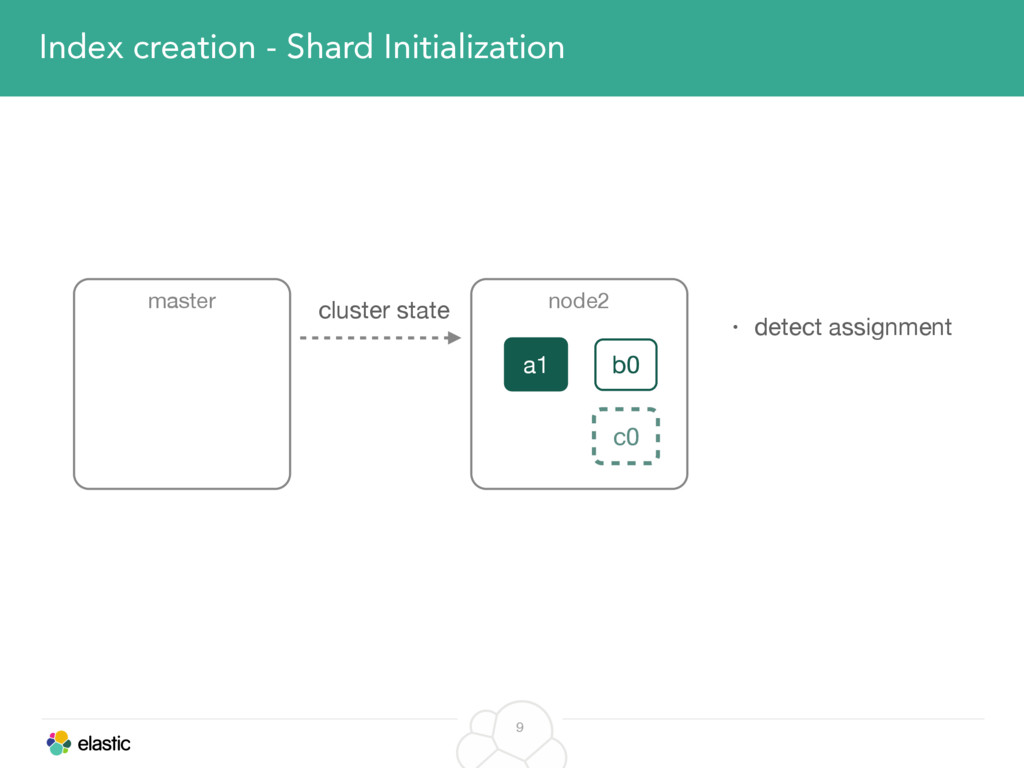
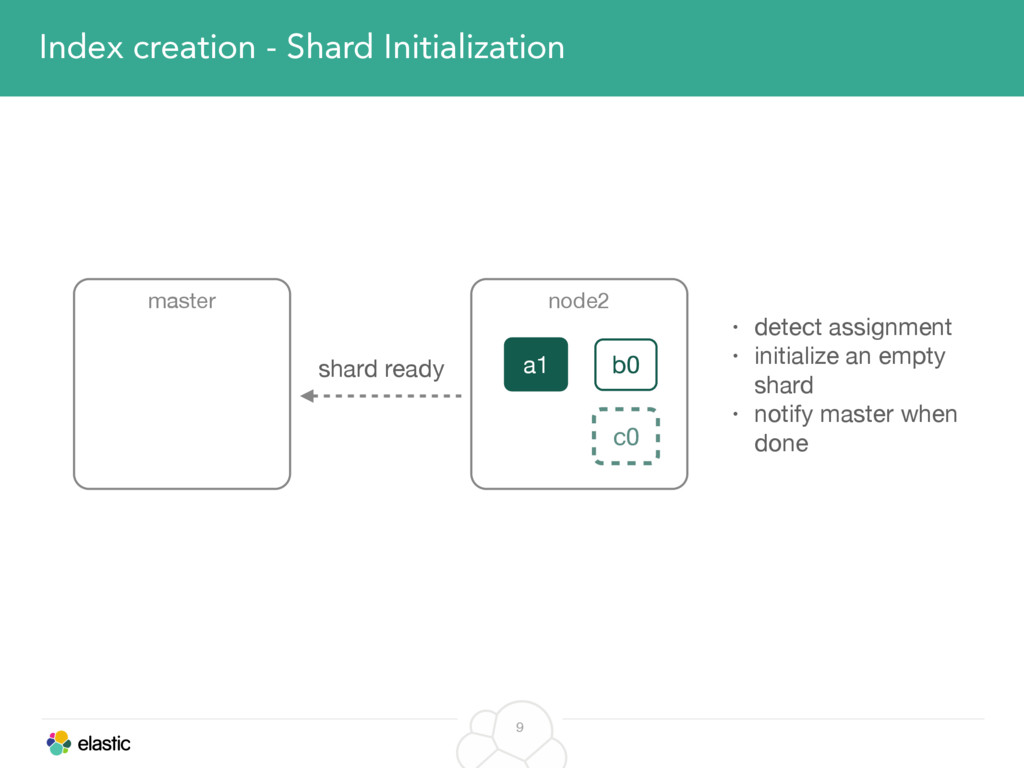
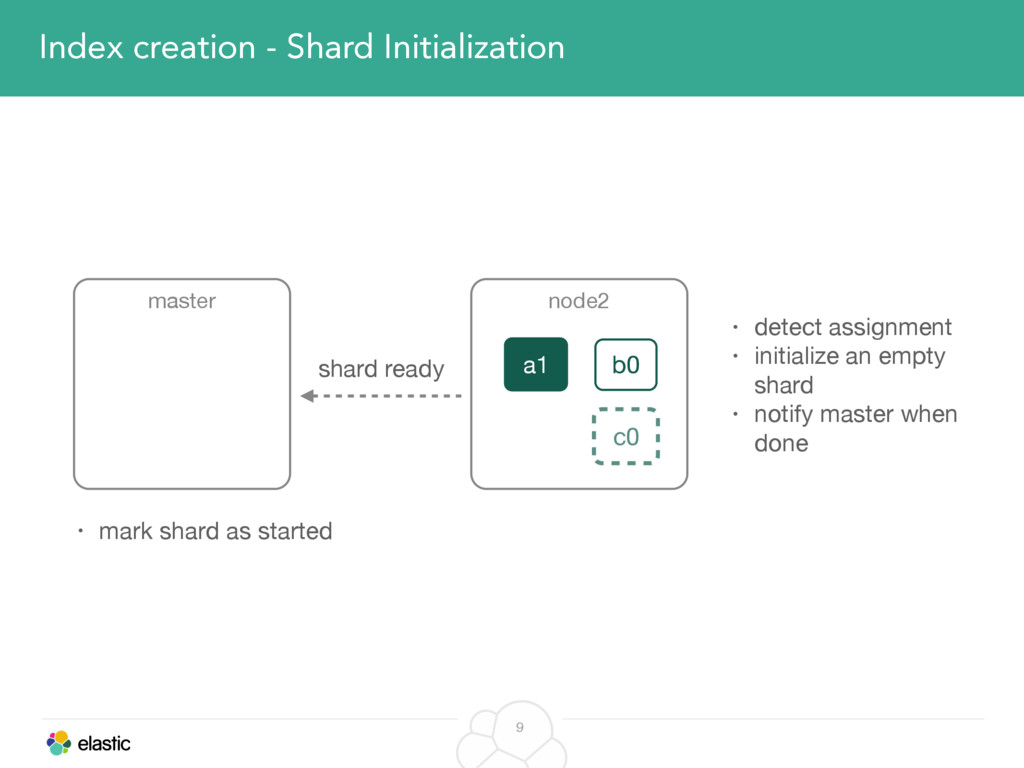
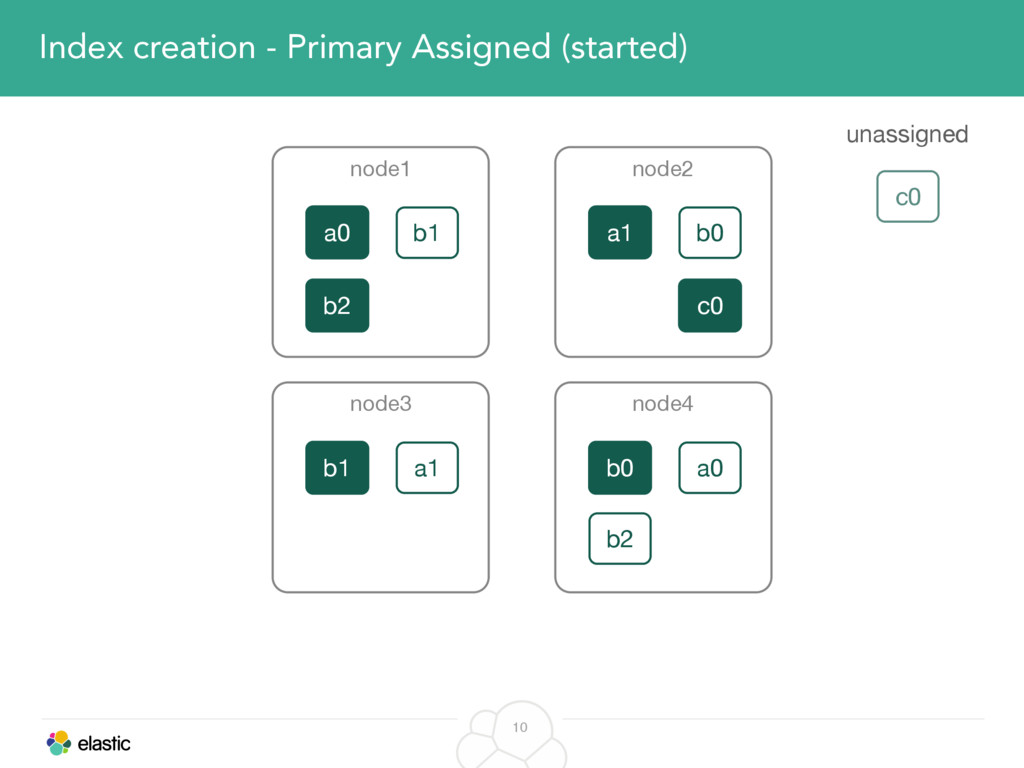
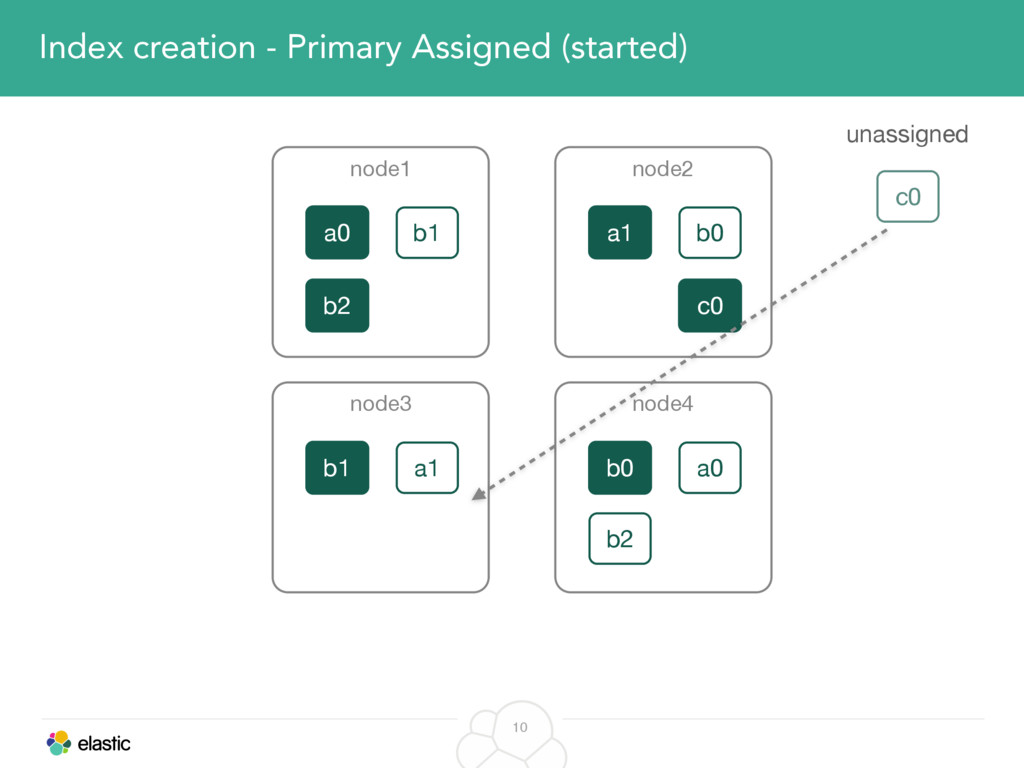
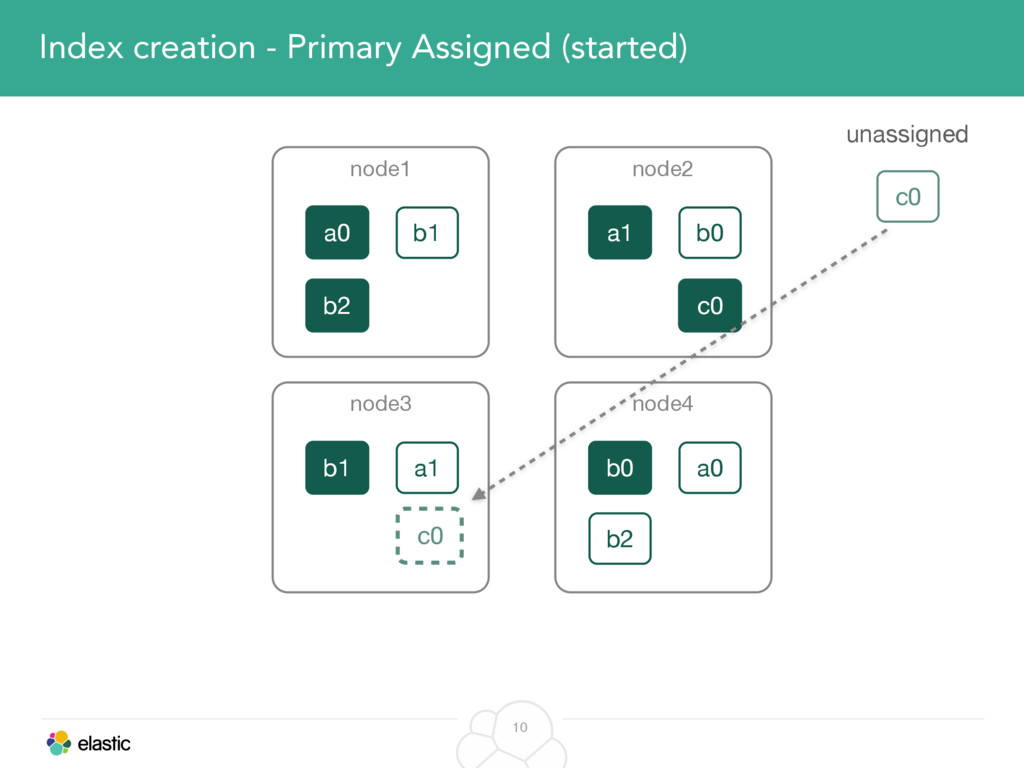
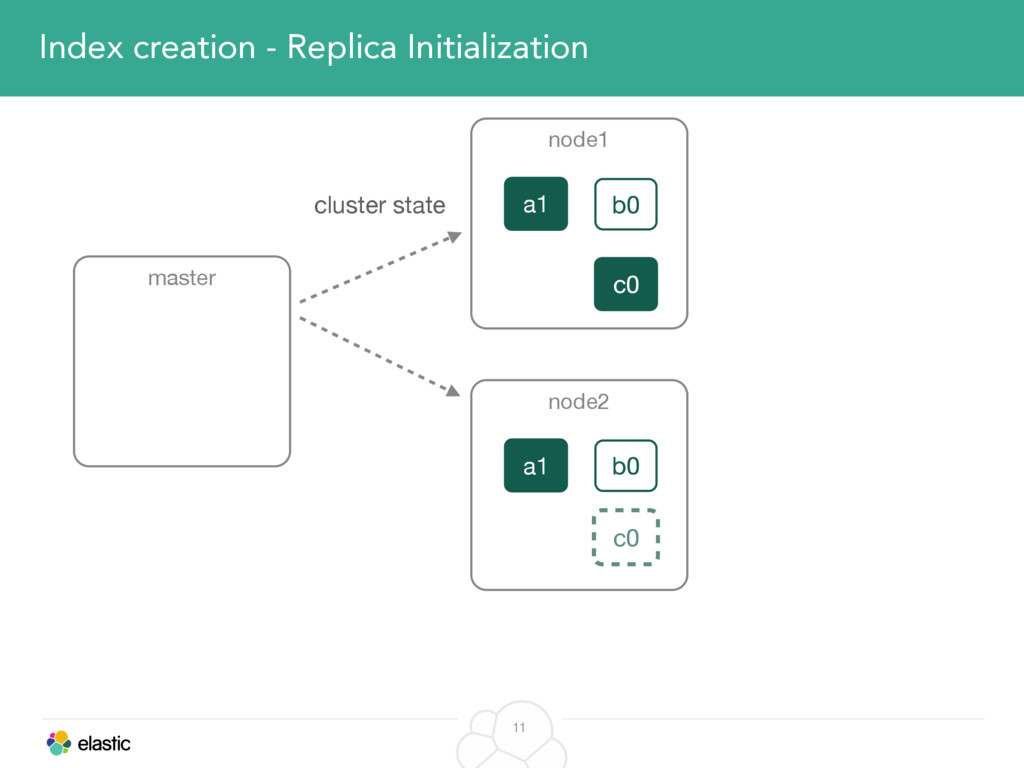
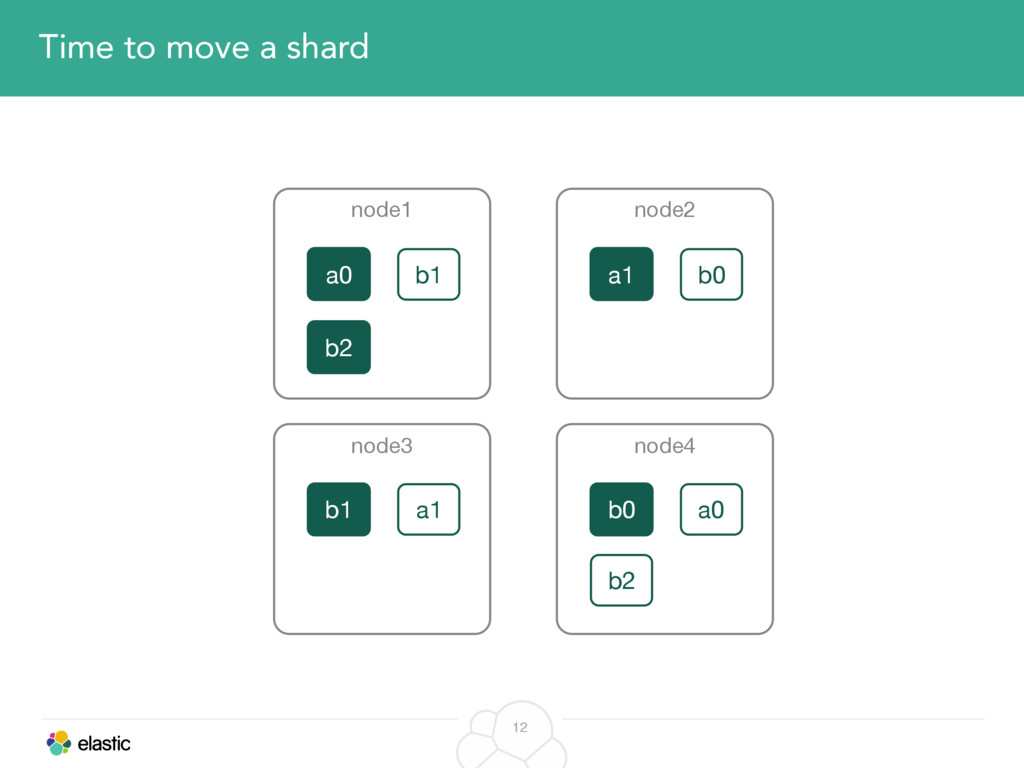
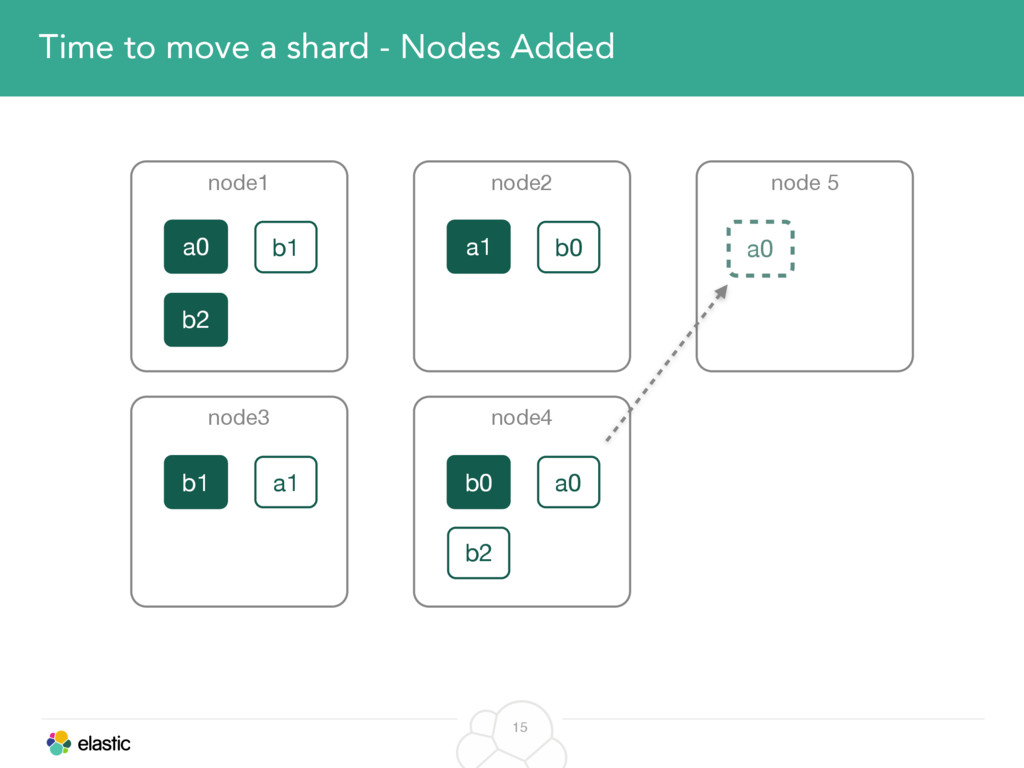
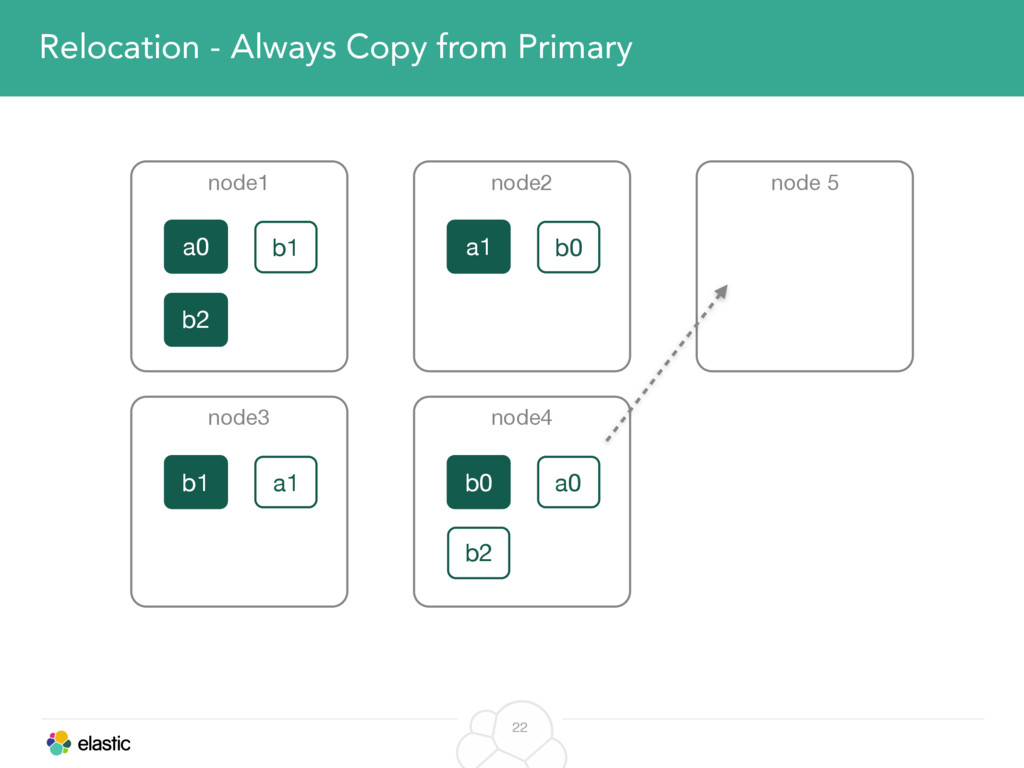
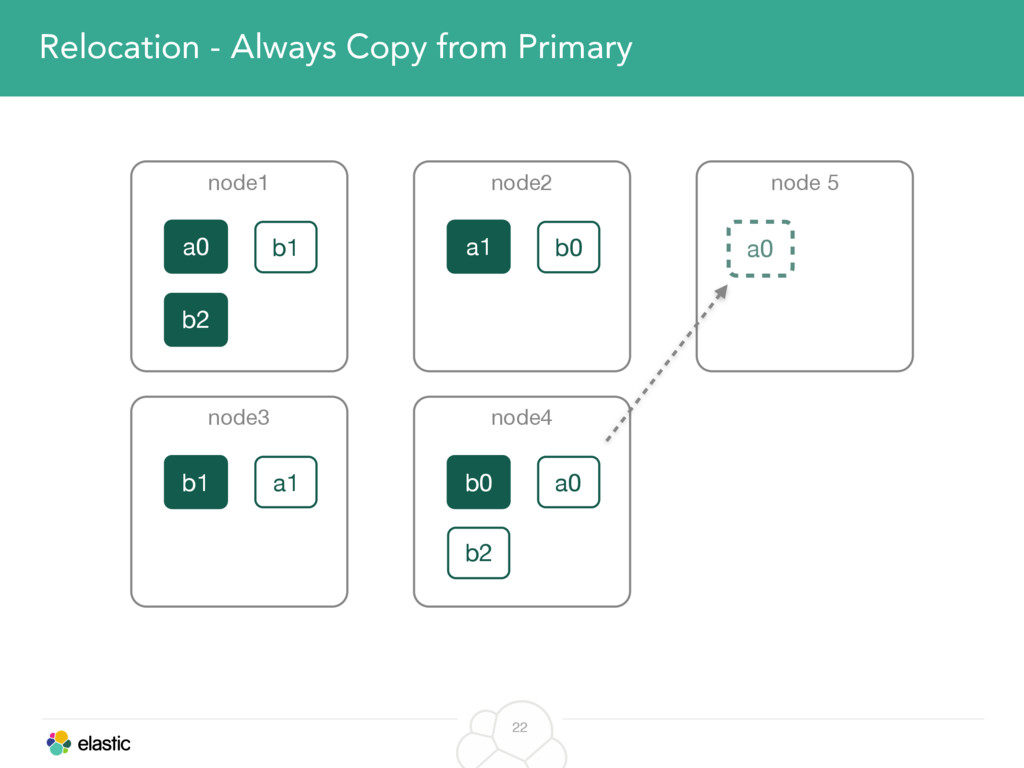
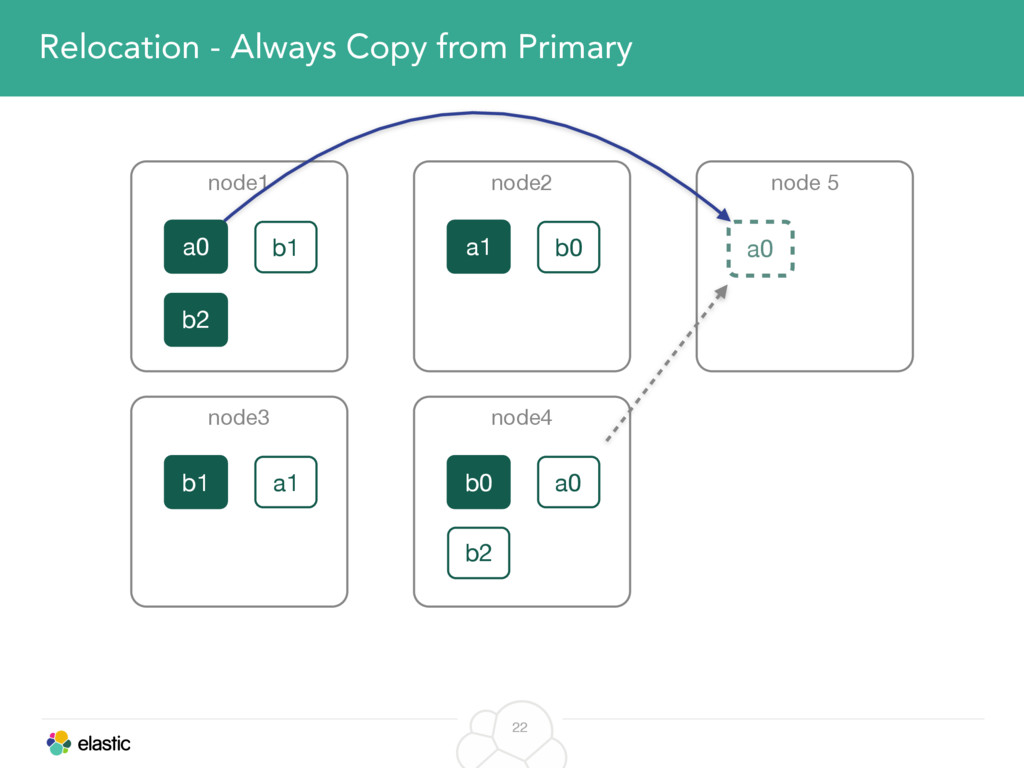
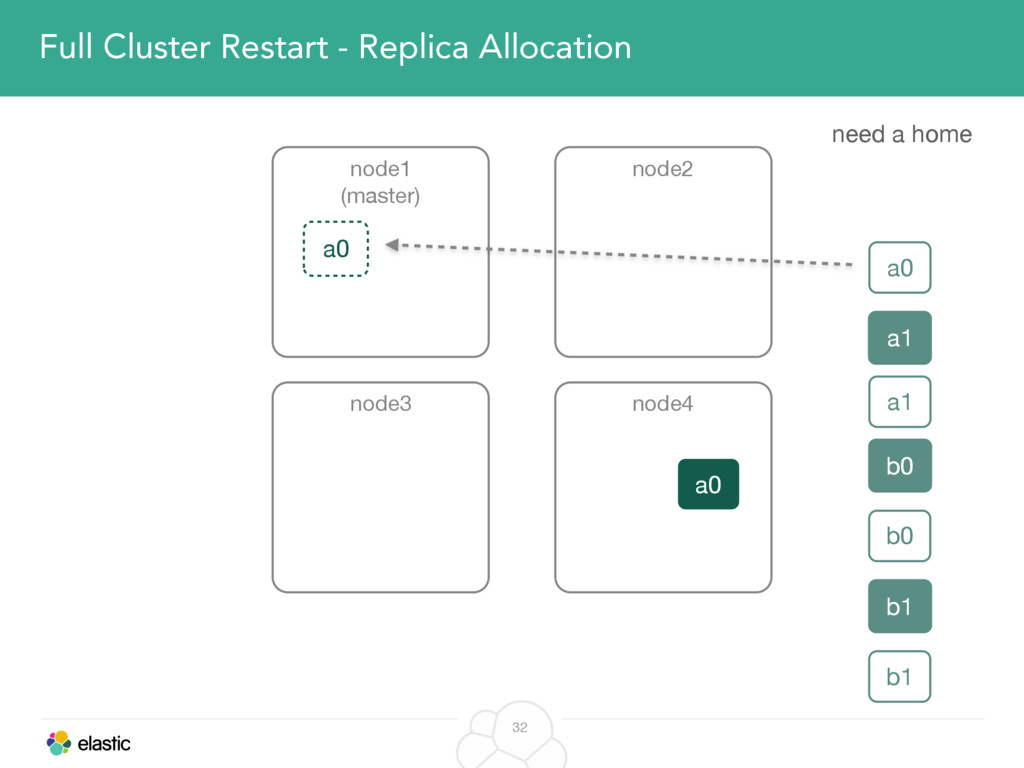
We will start with the assignment of new shards, conforming to the current Allocation Filtering, disk space usage and other factors. Once shards are started, they may be needed to be moved around. This can be due to a cluster topology change, data volumes or when someone instructed ES to so through the index management APIs.
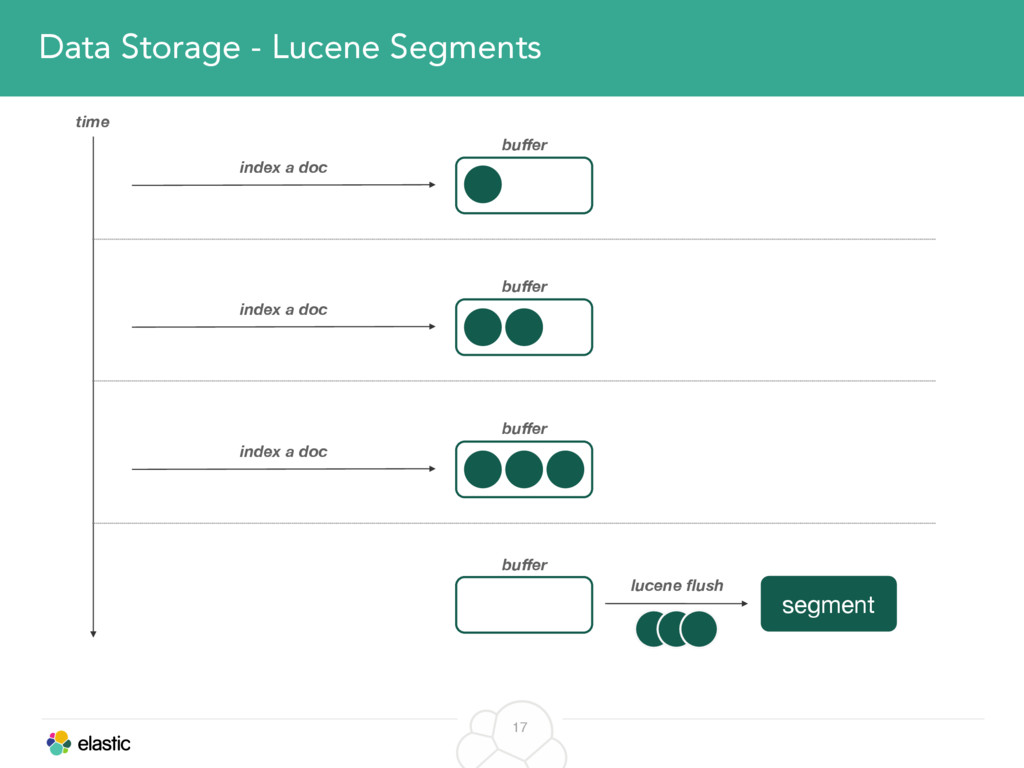
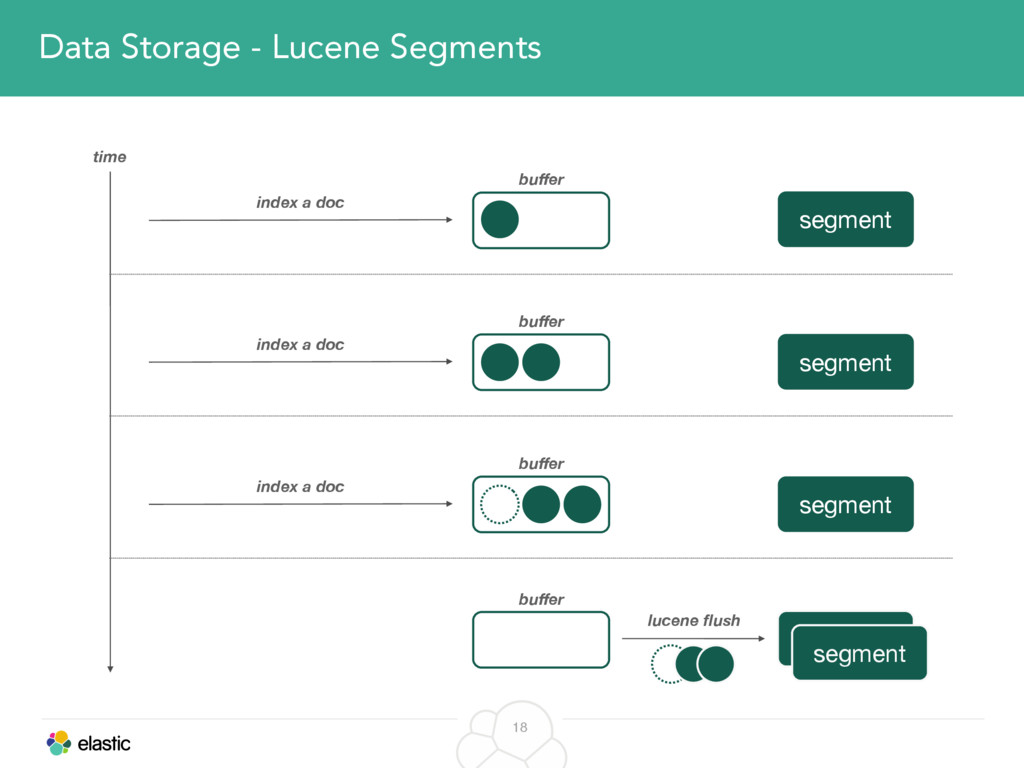
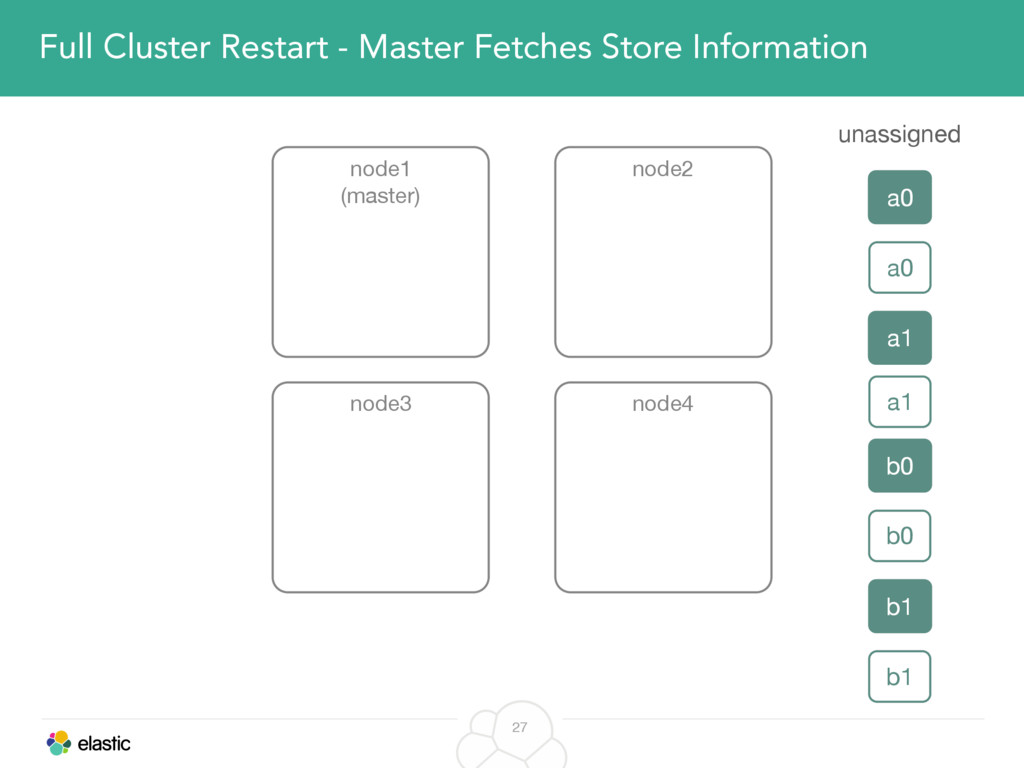
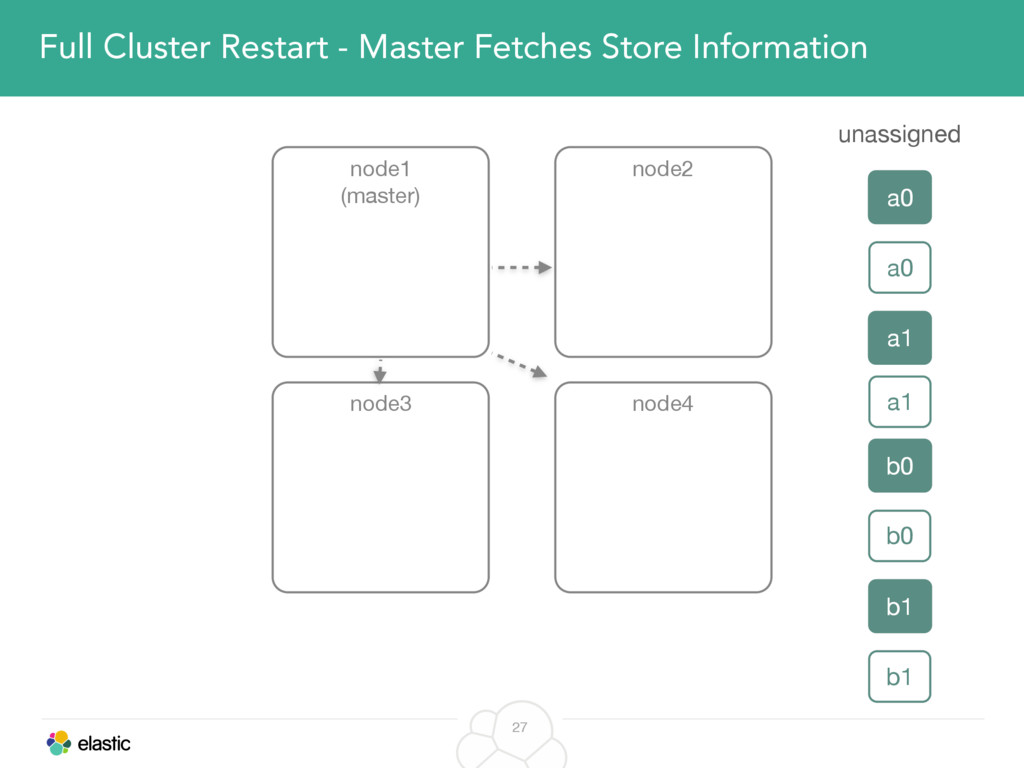
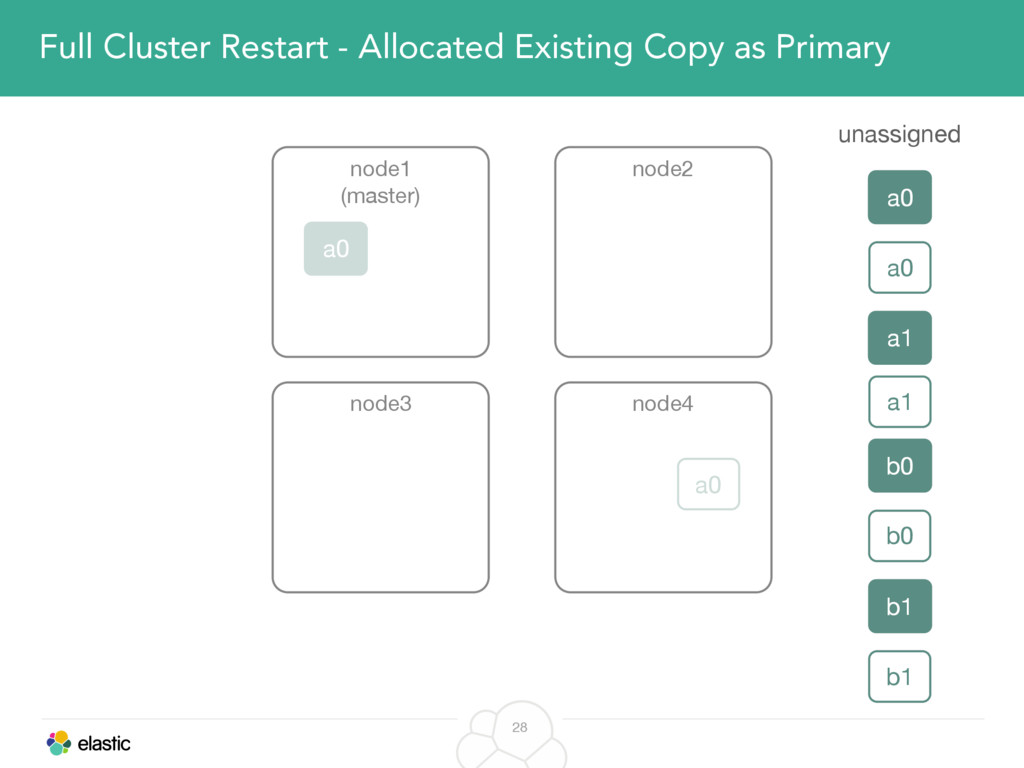
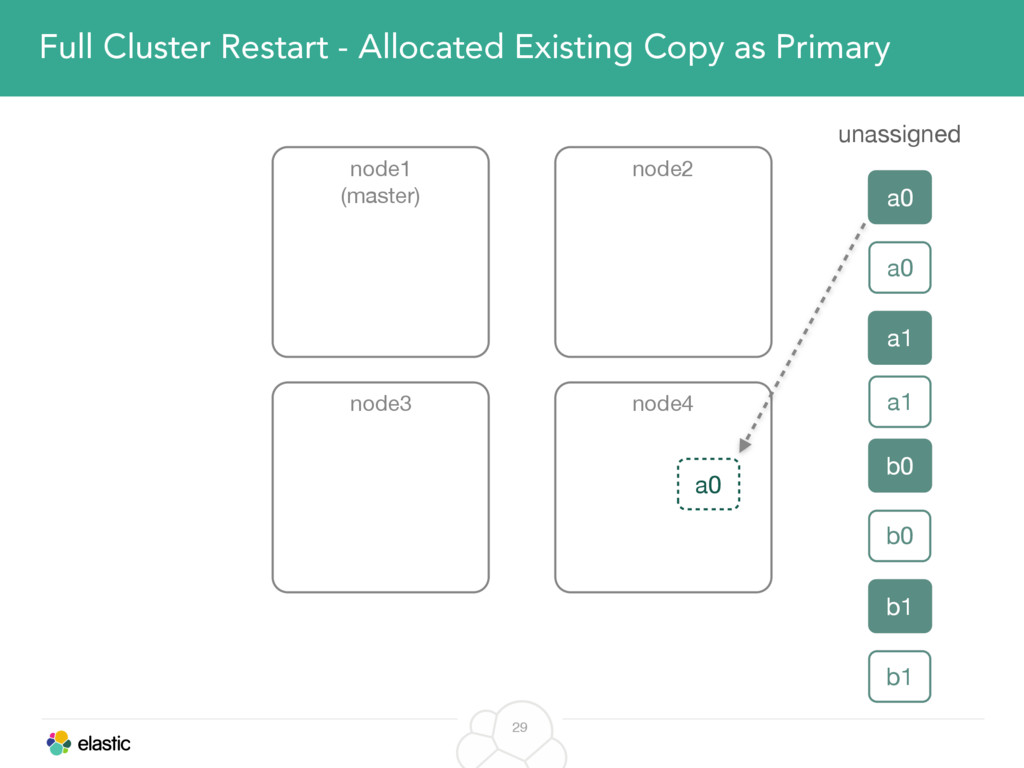
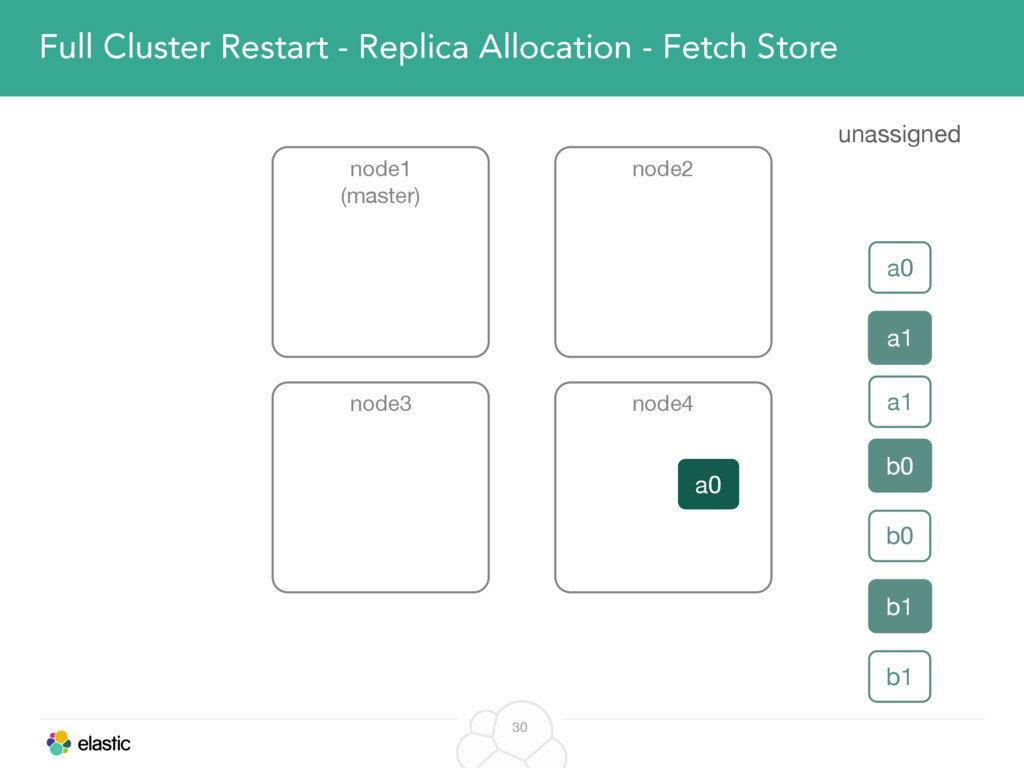
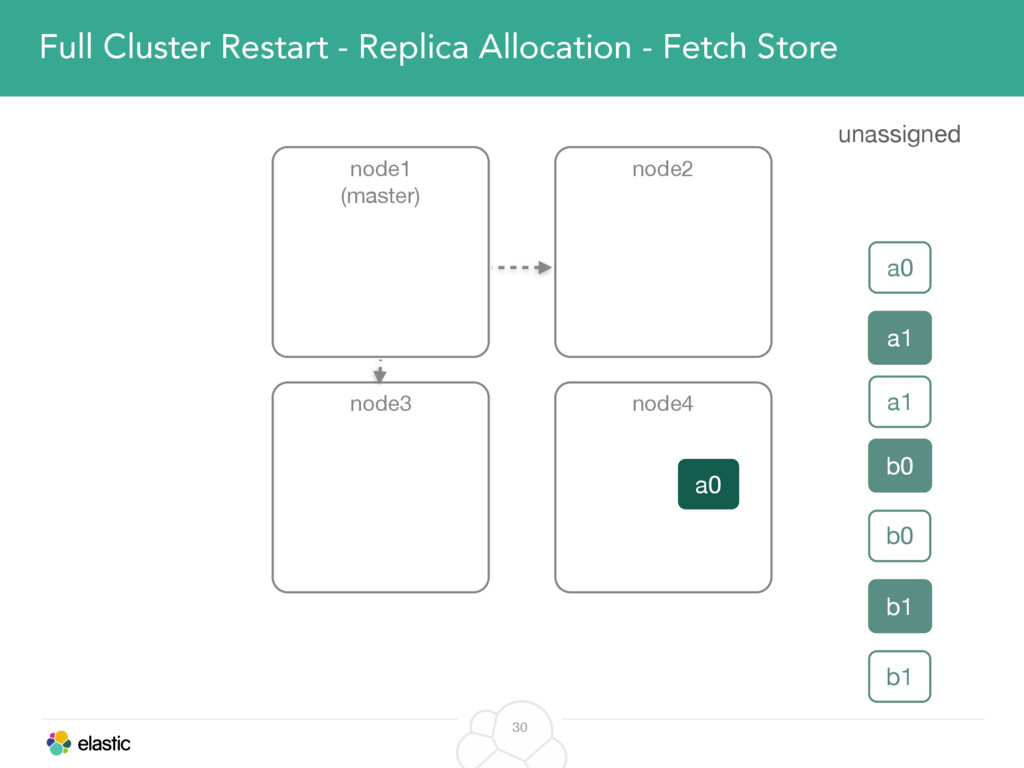
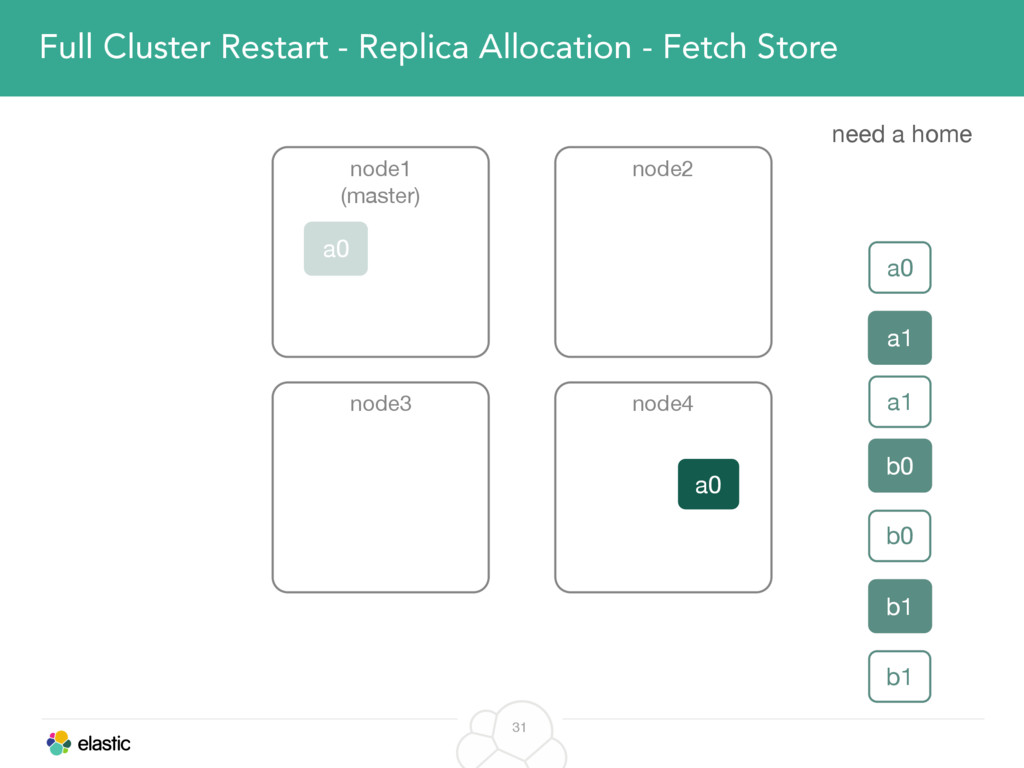
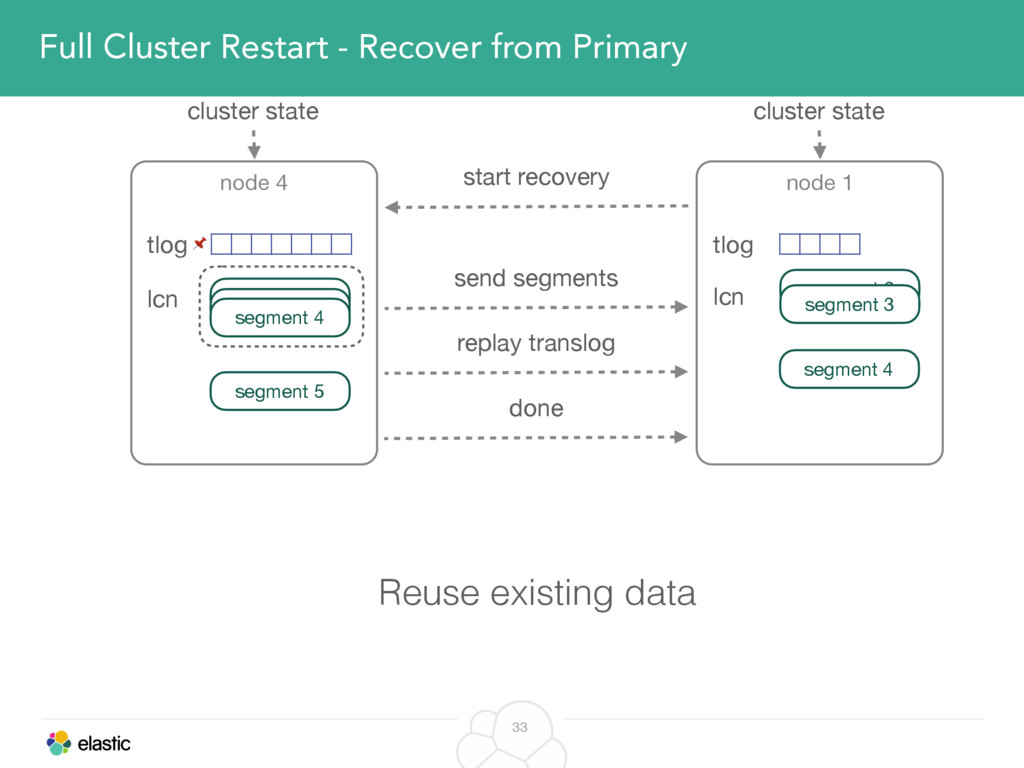
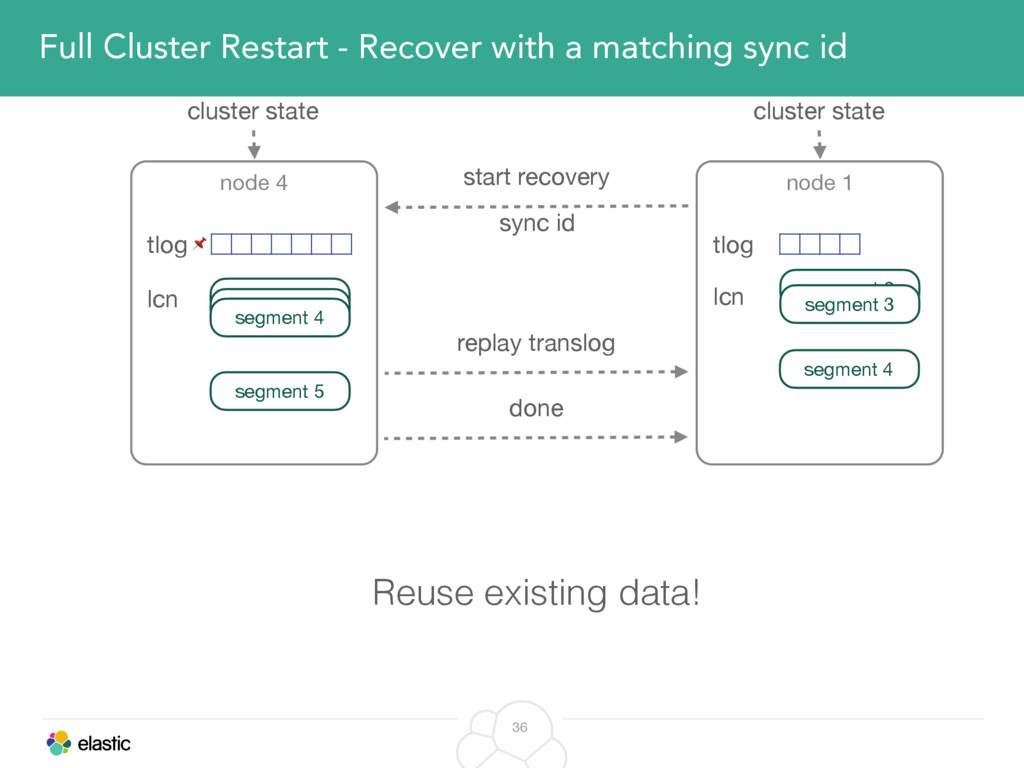
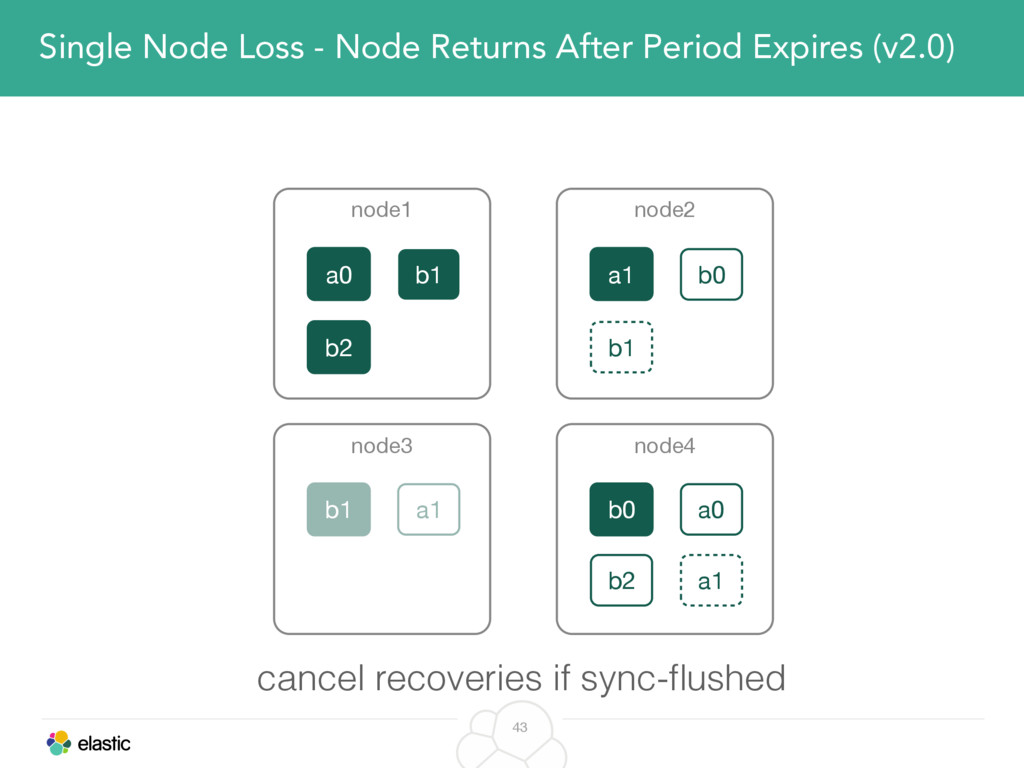
We will cover these triggers and how ES executes on those decisions, moving potentially tens of gigabytes of data from one node to another, without dropping any search or an indexing request. We will finalize with the mechanics of full/rolling cluster restarts and the recent improvements such as synced flush, delayed assignment on node leave and cancelling ongoing relocations if a perfect match is found.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}