Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
國泰人壽的可觀測性實踐
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Blueswen
September 25, 2023
Programming
350
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
國泰人壽的可觀測性實踐
DevOpsDays Taipei 2023
Blueswen
September 25, 2023
More Decks by Blueswen
See All by Blueswen
Observability in Practice:Grafana 與 Edge Device SRE 的那些事
blueswen
0
190
Grafana:建立系統全知視角的捷徑
blueswen
1
470
當 Grafana 遇見 LLM:AI 時代的可觀測性
blueswen
0
600
從零到一:搭建你的第一個 Observability 平台
blueswen
1
1.5k
快速入門可觀測性
blueswen
1
930
全方位強化 Python 服務可觀測性:以 FastAPI 和 Grafana Stack 為例
blueswen
1
1.9k
Observability 101:從零開始了解可觀測性
blueswen
0
460
從零開始打造可觀測性平台
blueswen
3
2.4k
Other Decks in Programming
See All in Programming
Webフレームワークの ベンチマークについて
yusukebe
0
200
スマートグラスで並列バイブコーディング
hyshu
0
280
AI時代の仕事技芸論〜ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ(スクフェス仙台 2026バージョン)
kuranuki
0
360
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
480
決定論的オーケストレーションの設計と実装 / Design and Implementation of Deterministic Orchestration
nrslib
4
1.6k
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
7
1.6k
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
0
400
Performance Engineering for Everyone
elenatanasoiu
0
260
Signal Forms: Details & Live Coding @enterJS 2026 in Mannheim
manfredsteyer
PRO
0
220
Vue × Nuxt × Oxc どこまで使える?実運用の現在地
andpad
0
360
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
790
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
0
380
Featured
See All Featured
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
270
Making Projects Easy
brettharned
120
6.7k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Claude Code のすすめ
schroneko
67
230k
Side Projects
sachag
455
43k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
Agile that works and the tools we love
rasmusluckow
331
22k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Writing Fast Ruby
sferik
630
63k
Accessibility Awareness
sabderemane
1
150
Transcript
國泰人壽的可觀測性實踐 國泰人壽 DevOps Team 劉義瑋
自介 • 劉義瑋 Blueswen • blueswen @ GitHub • 國泰人壽
投資資訊部 DevOps Team • 偶爾做做 ML 專案的 DevOps 工程師 • 負責導入可觀測性與觀測平台 • 領域 • DevOps • Cloud Native • Machine Learning 2
Outline • 背景與挑戰 • 可觀測性強化 • Observability Signals:Metrics、Logs、Traces • 觀測平台建立
• Signals 搭配綜效 • 多租戶規劃與管理 • Infrastructure as Code with Terraform • 推廣策略與挑戰 • 結論 3
4 日常開發與維運時最痛苦的事情是什麼?
5 日常開發與維運時最痛苦的事情是什麼? 排查問題
6 技術好、運氣好時可能很快解決 但如果不幸兩者都沒有時,就 …
背景與挑戰 – 排查問題效率低落的影響 7 但我們的痛苦,與公司何關?
背景與挑戰 – 排查問題效率低落的影響 8 收入 – 成本 = 利潤
收入 – 成本 = 利潤 背景與挑戰 – 排查問題效率低落的影響 9 排查問題慢
客戶不開心 客訴變多 喪失使用者 OPS
收入 – 成本 = 利潤 背景與挑戰 – 排查問題效率低落的影響 10 開發速度慢
DEV 專案時程延宕 同事不開心 加班、加人
收入 – 成本 = 利潤 背景與挑戰 – 排查問題效率低落的影響 11 股東不開心
老闆不開心 你不開心 排查問題慢 客戶不開心 客訴變多 喪失使用者 OPS 專案時程延宕 同事不開心 加班、加人 開發速度慢 DEV
背景與挑戰 – 如何排查問題 12 工具清單 1. IT Portal 2. APM
Tool 3. Grafana 4. Log 查詢系統 5. Configuration 系統設定 6. AP Records 7. 巡檢、迴歸紀錄 8. 監控資訊 9. CathayTracing 10. 瀏覽器開發者工具 11. DB SQL 12. more… 假設問題的根因 使用工具驗證假設
背景與挑戰 – 如何排查問題 13 我們真的有善用資訊與工具查找根因嗎? 資訊不足 導致無法判斷問題狀況 Data Silo 資訊分散在不同工具
造成分裂的查詢體驗 LOG 查詢系統 自建儀錶板 APM Tool
背景與挑戰 – 增加觀測資訊,解決資訊不足 14 Observability 可觀測性 透過各種數據, 「明確」了解系統發生什麼事 Source: meshcloud
背景與挑戰 – 建立單一的平台,打破 Data Silo 可容納各種觀測資訊的現代化查詢平台 15 Source: Grafana
可觀測性強化 增加觀測資訊,解決資訊不足 16
可觀測性強化 – Observability Signals 17 補強三種 Observability Signals 強化可觀測性 指標
不同時間採樣的系統量化數據 如:CPU 使用率、API 回應時間 日誌 紀錄系統中發生的事情 如:Debug 訊息、Exception 鏈路追蹤 紀錄行為在不同服務中的歷程 如:SSO 行為橫跨多個不同服務
指標 不同時間採樣的系統量化數據 如:CPU 使用率、API 回應時間 可觀測性強化 – Observability Signals 18
日誌 紀錄系統中發生的事情 如:Debug 訊息、Exception 鏈路追蹤 紀錄行為在不同服務中的歷程 如:SSO 行為橫跨多個不同服務 脈絡:怎麼發生的 徵狀:發生什麼事
可觀測性強化 – Observability Signals 19 資訊處理四步驟 生成 收集 儲存 使用
可觀測性強化 – Observability Signals:Metrics • Metrics 生成 • 通用格式:Prometheus Metrics/OpenMetrics
• 系統指標 • 機器相關的資訊,如:CPU、Memory、磁碟空間、JVM 資訊 • 產生指標的工具 • 主機:Node Exporter • 容器:cAdvisor • JVM:JMX Exporter • 業務指標 • 應用、業務相關的資訊,如:Request 頻率、API 回應時間、Error Rate • 產生指標的工具 • Java Sprint Boot:Spring Boot Actuator 搭配 Micrometer • 其他語言:Prometheus Client Library 20
可觀測性強化 – Observability Signals:Metrics 收集 透過爬取的方式收集 Metrics 使用 PromQL 查詢
Metrics 當資料量超過千萬筆或需要長期儲存時, 建議搭配其它儲存服務* 儲存 良好的可擴展性 彙整多個 Prometheus 查詢快速,儲存成本低 查詢 API 與 Prometheus 一致,使用 PromQL 查詢 21 *資料來源:I was told Prometheus “doesn't scale”.
可觀測性強化 – Observability Signals:Logs 22 生成 各語言、框架 Logger 良好的格式、分級 Console、File
收集 輕量化的資料處理工具 爬取 Log 與加工後,轉 發至其他服務儲存 儲存 良好的可擴展性 查詢快速,儲存成本低 使用 LogQL 查詢
可觀測性強化 – Observability Signals:Traces • Trace • 用於監控跨服務請求,透過統一的 Trace ID
串聯,紀錄同一個行為在不同服務間的歷程資訊, 可記錄:執行時間、錯誤訊息、請求來源 IP、SQL 語法等 23 time SSO(Single Sign-On) Redis 登入服務 Google Trace Spans Trace ID: a03fc269e4f Trace ID: a03fc269e4f Trace ID: a03fc269e4f
可觀測性強化 – Observability Signals:Traces • Trace 生成 • 通用格式:OpenTelemetry Protocol(OTLP)
• OpenTelemetry • A Collection of APIs, SDKs, and tools • Instrumentation Libraries:生成、發送 Traces 資訊 • Instrumentation 分為兩種: • Manual 手動設定:搭配 Library 自行調整程式 • Automatic 自動設定:搭配語言、框架的機制,自動注入到程式中,無須調整程式碼 24 Python 與 Java 使用 Automatic Instrumentation 範例
可觀測性強化 – Observability Signals:Traces 25 OpenTelemetry Automatic Instrumentation SSO (Application)
Redis Trace ID: a03fc2 Trace ID: a03fc2 使用 OpenTelemetry 的 Java Automatic Instrumentation 時 會自動記錄進出該服務的 HTTP 與資料庫等網路請求 Google DB Trace ID: a03fc2 Trace ID: a03fc2
可觀測性強化 – Observability Signals:Traces 收集 轉發 Trace 資訊至其他儲存服務 Plugin 支援
Trace 資訊的加工或篩選 儲存 良好的可擴展性 查詢快速,儲存成本低 使用 TraceQL 查詢 26
可觀測性強化 – Observability Signals:Span Metrics 27 你也有祖傳十八代的系統嗎?
OpenTelemetry Automatic Instrumentation 可觀測性強化 – Observability Signals:Span Metrics 28 Collector
解析 Trace 資訊生成 Request 相關 Metrics Java 8+ 祖傳系統不宜異動,但可使用侵入性小的 Automatic Instrumentation 搭配 OpenTelemetry Collector Span Metrics Connector 產生業務指標 Push Scrape
可觀測性強化 – Observability Signals:資料流 29
可觀測性強化 – Observability Signals:LGTM 30 Grafana 體系 Infra 設計理念、查詢語法類似,降低維運、使用負擔
觀測平台建立 建立單一的平台,打破 Data Silo
觀測平台建立 – Grafana • 使用 Grafana 建立單一的查詢平台,避免分裂的查詢體驗 • 開源的資料視覺化和監控儀表板工具 •
支援查詢各種不同資料源,如 Loki、Mimir、Tempo 32 Log 查詢 Metrics 查詢 Trace 查詢
觀測平台建立 – 預設儀錶板 33 提供預設儀錶板供使用者快速上手
觀測平台建立 – Signals 搭配綜效 34 將 Logs、Metrics、Traces 互相連結,互相搭配參照產生綜效 時間區段同步 Trace
ID 連結 Exemplar Span Metrics
觀測平台建立 – Signals 搭配綜效:Metrics & Logs 35 同步時間區段,同時查詢 Metrics 與
Log 時間同步
觀測平台建立 – Signals 搭配綜效:Metrics & Logs 36 同時顯示 Metrics 與
Log 的預設儀表板
觀測平台建立 – Signals 搭配綜效:Traces & Logs 37 利用 Trace 的
Trace ID 查詢對應的 Log
觀測平台建立 – Signals 搭配綜效:Traces & Logs 38 利用 Log 中的
Trace ID 查詢對應的 Trace
觀測平台建立 – Signals 搭配綜效:Traces to Metrics 39 透過 Trace 資訊生成
Request 相關 Metrics,如:執行時間、次數
觀測平台建立 – Signals 搭配綜效:Metrics to Traces 40 在 Metrics 中增加
Exemplar,直接記錄某筆 Request 的指標與 Trace ID
觀測平台建立 – Grafana 41 支援查詢各種資料來源,包括:PostgreSQL、MongoDB、ElasticSearch 等 Source: Grafana
觀測平台建立 – 多租戶規劃與管理 42 平台建立完成後,就可以開心的使用了嗎? Single Tenant 單一使用者,管理議題較少 Multi Tenant
多組使用者,須確保資料隔離、權限卡控
觀測平台建立 – 多租戶規劃與管理 43 平台建立完成後,就可以開心的使用了嗎? 一般組織都會面臨的需求 Single Tenant 單一使用者,管理議題較少 Multi
Tenant 多組使用者,須確保資料隔離、權限卡控
觀測平台建立 – 多租戶規劃與管理:資料隔離、權限卡控 44 指標 系統的量化數據 無敏感資訊,被其他人查閱無影響 日誌 可能包含個資、敏感資訊 必須有對應權限才能查看
鏈路追蹤 跨服務、系統的歷程 若依系統別隔離反而失去了詳細歷程
觀測平台建立 – 多租戶規劃與管理:資料隔離、權限卡控 45 指標 系統的量化數據 無敏感資訊,被其他人查閱無影響 日誌 可能包含個資、敏感資訊 必須有對應權限才能查看
鏈路追蹤 跨服務、系統的歷程 若依系統別隔離反而失去了詳細歷程 只有 Logs 有隔離的需求
觀測平台建立 – 多租戶規劃與管理:資料隔離、權限卡控 Multi-tenancy 模式 Log 依 Tenant 分別儲存 Loki
資料源必須指定 Tenant Grafana Organization 隔離使用者、儀錶板、資料源等 達到 Multi-tenancy 46 Organization Organization Organization Organization
觀測平台建立 – 多租戶規劃與管理 47 Public Cloud On-Premise SIT UAT PROD
X 系統 Y 系統 Z 系統 預設儀錶板 User Role 資料源 2 3 m n × × × 環境別 位置 系統別(Organization) Grafana 資源設定 環境、多租戶與設定排列組合後維運複雜度急遽上升
觀測平台建立 – 多租戶規劃與管理:IaC with Terraform 48 Public Cloud On-Premise SIT
UAT PROD X 系統 Y 系統 Z 系統 預設儀錶板 User Role 資料源 2 3 m n × + 環境別 位置 系統別(Organization) Grafana 資源設定 × 使用 Infrastructure as Code 的方式管理 Grafana 使用 Terraform 搭配 Grafana Provider 開發 Terraform Module 簡化管理 Terraform Module
推廣策略與挑戰 49
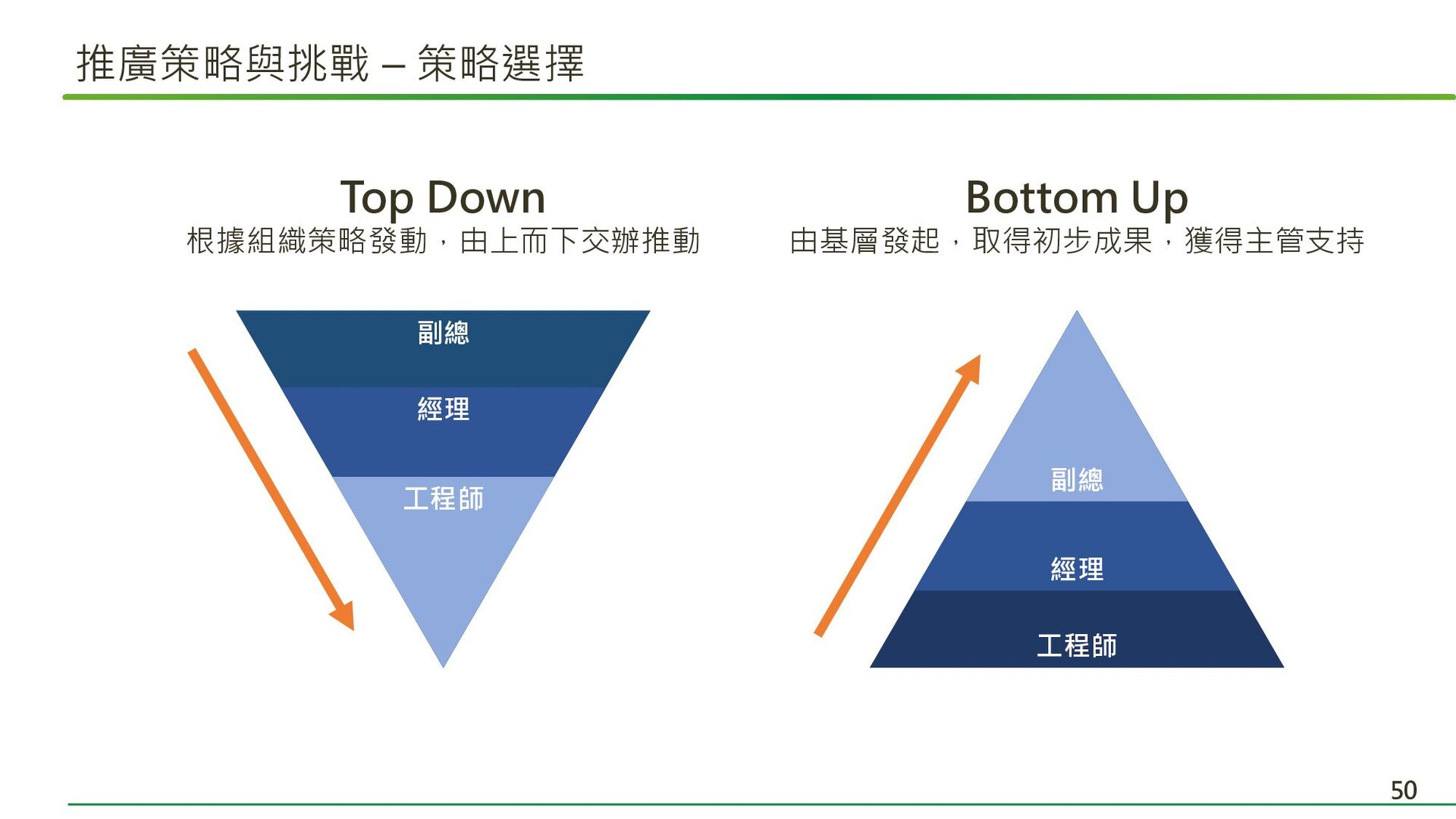
Top Down 根據組織策略發動,由上而下交辦推動 副總 經理 工程師 推廣策略與挑戰 – 策略選擇 50
Bottom Up 由基層發起,取得初步成果,獲得主管支持 工程師 經理 副總
推廣策略與挑戰 – 策略選擇:提供工具融入現行組織架構 51 權責 能力 目標 提供工具融入現行組織架構 熟悉 Cloud
Native 工具 與 Dev 和 Ops 有良好的關係 團隊負責 CICD 與 Kubernetes 維運 了解現有系統框架,有權限建立平台 DevOps Team 工程師 經理 副總 Bottom Up 由基層發起,取得初步成果,獲得主管支持
推廣策略與挑戰 – 推廣策略:STEP 1 – 意識啟發 行銷第一步:Awareness,讓大家認識這個好東西! 可觀測性是近幾年技術文章、社群、研討會熱門主題,已經深植人心 52
推廣策略與挑戰 – 推廣策略:STEP 2 – Pilot User 驗證應用場景 • Pilot
User:觀測平台與現有監控部分功能重疊,鎖定對差異買單的團隊 • POC Demo Project:Talk is cheap. Show me the code. • 應用場景驗證:依據實務需求設計平台與儀錶板 53 POC Demo Project Spring Boot Observability
推廣策略與挑戰 – 推廣策略:STEP 3 – 持續擴散與優化 • 擴散 • 舉辦
Workshop、技術講座 • 讓大家知道有這個工具,增加使用者 • 優化 • 收集需求、使用案例 • 支援更多類型的系統 • 目標 • 提高 DEV 與 OPS 對系統狀況的掌握度 • 散播 SRE 觀念,透過工具提升品質 • 可觀測的系統達 30 套以上 54
結論 55
Recap • 可觀測性強化 • 提高系統可觀測性,透過 Logs、Metrics、Traces 清楚了解系統狀態 • 統一各類資訊格式,搭配開源規範、套件加快導入,如 Prometheus、OpenTelemetry
• 觀測平台建立 • 使用 Grafana 建立單一的觀測平台,資訊搭配使用產生綜效 • 提供預設儀錶板,同時保留使用者的客製化權限,降低使用門檻 • 利用 Grafana Organization 與 Loki 的 Tenant 功能滿足平台多租戶需求 • 使用 Terraform 以 Infrastructure as Code 方式建立觀測平台,降低維運複雜度 • 推廣策略 • 以提供工具為目標,並搭配足夠的權責與能力 • 尋找 Pilot User,建立成功典範與口碑 • 持續優化與推廣,舉辦 Workshop、技術講座擴大使用者、收集需求 56
結論 – Key Takeaways 57 善用開源工具 降低使用門檻 POC 搭配 Pilot
User Workshop、預設儀錶板 Support Engineer Grafana Stack Prometheus OpenTelemetry
結論 58 完善的量測,讓系統可管理與優化
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}