- https://github.com/google-research/recsim で紹介されている概念 - Chocolate: 短期的な食いつきは良いが、長期的な満足度は下がるコンテンツ - 釣りサムネイルで内容は薄い動画みたいな - Kale: クリックは集めにくいが、長期的には満足度が上がるコンテンツ - Chocolate, Kaleのバランスをアルゴリズム的にうまくとることで、 「直近のクリック率」ではなく、「現在から未来までのユーザの満足度」が最大化される - 多腕バンディットアルゴリズムの世界観では明らかにカバーできないが重要な概念
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
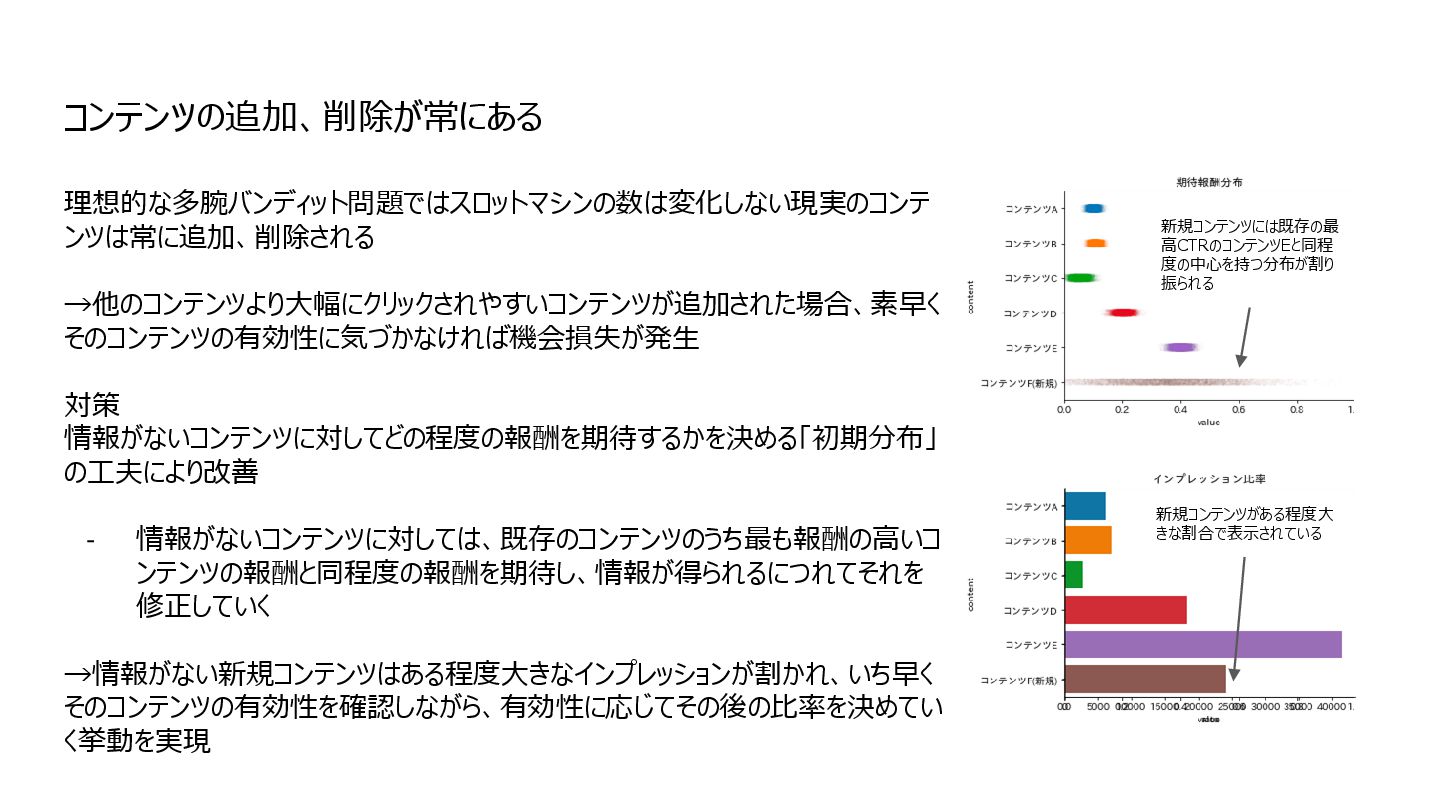{kind=link}
{kind=link}
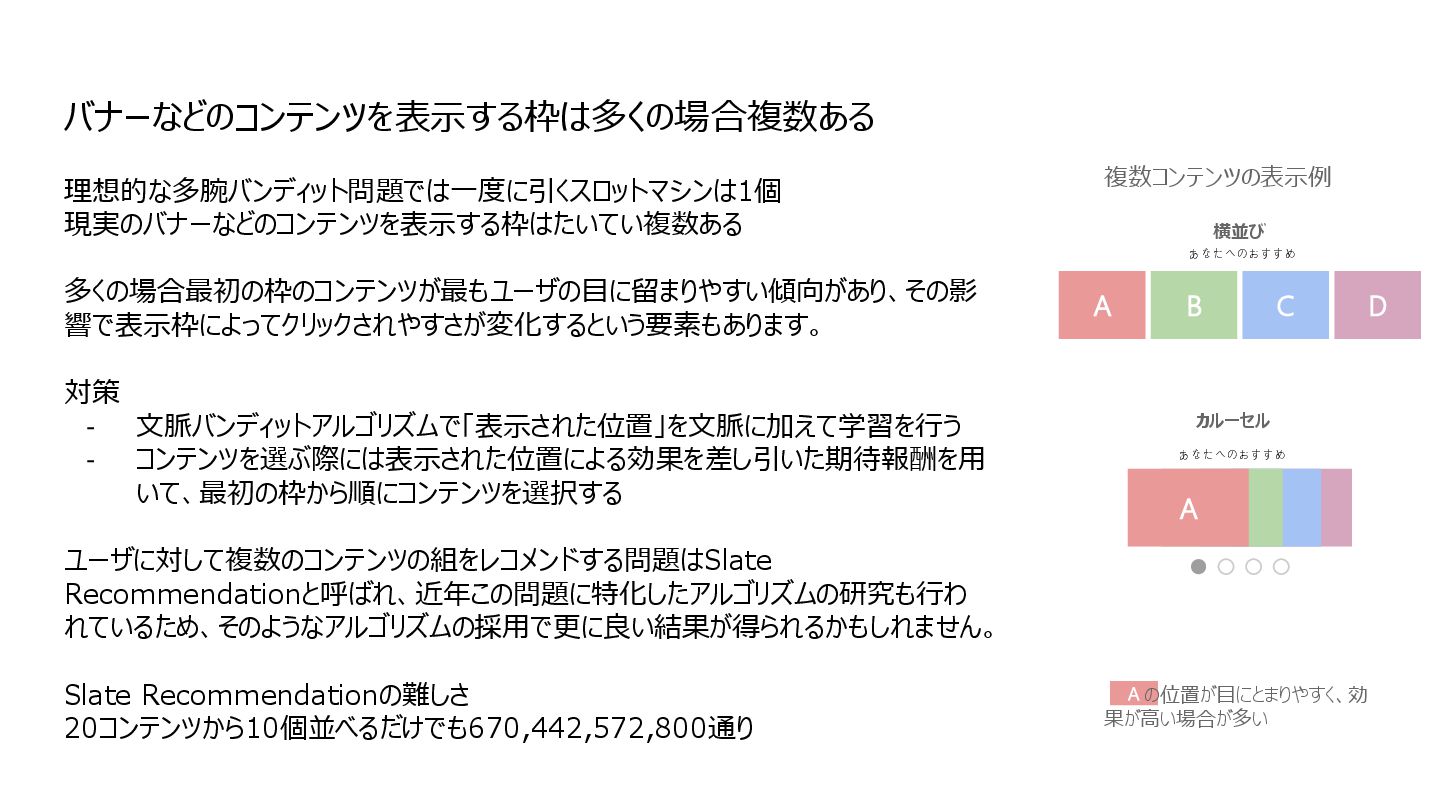{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}