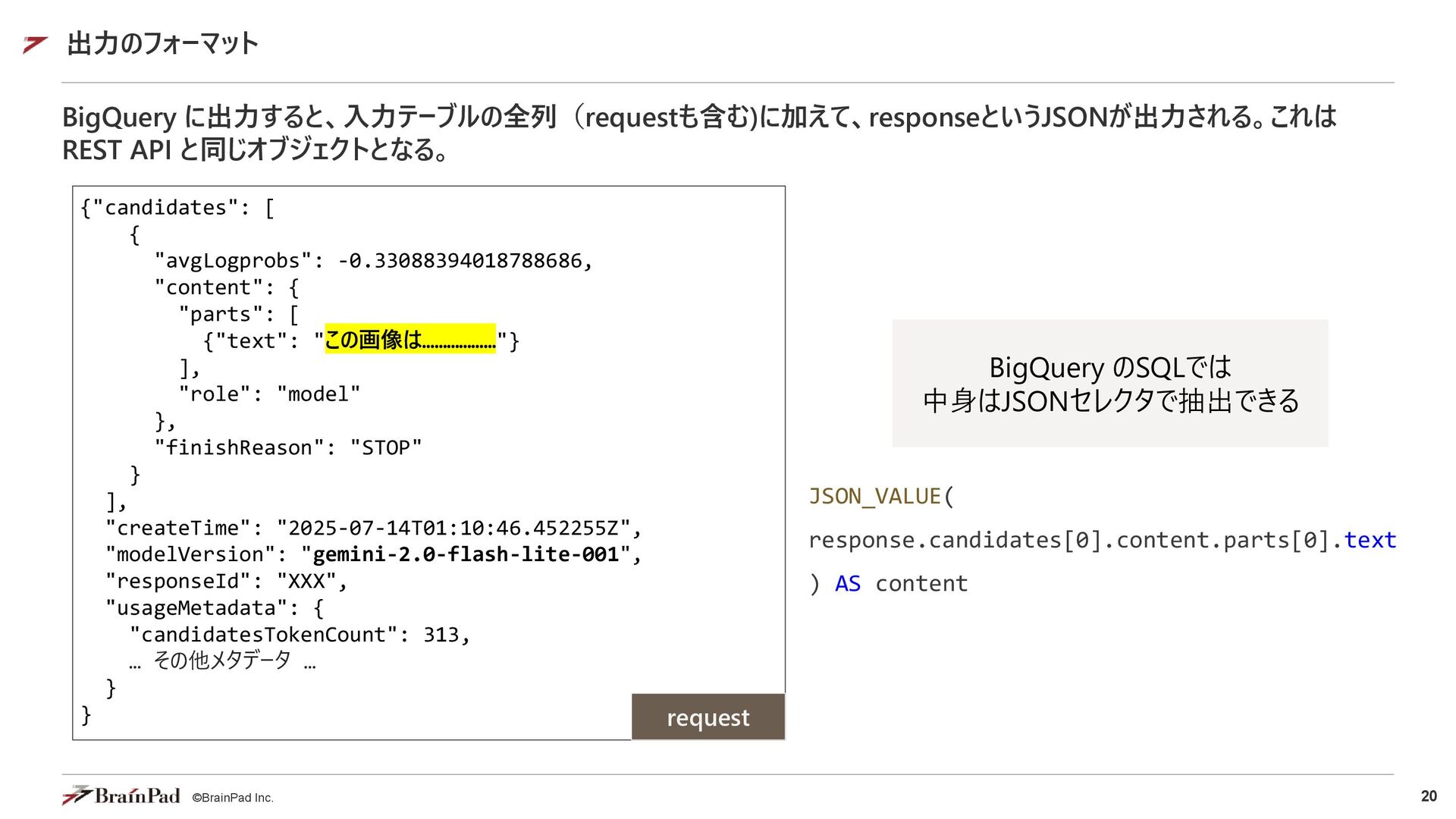
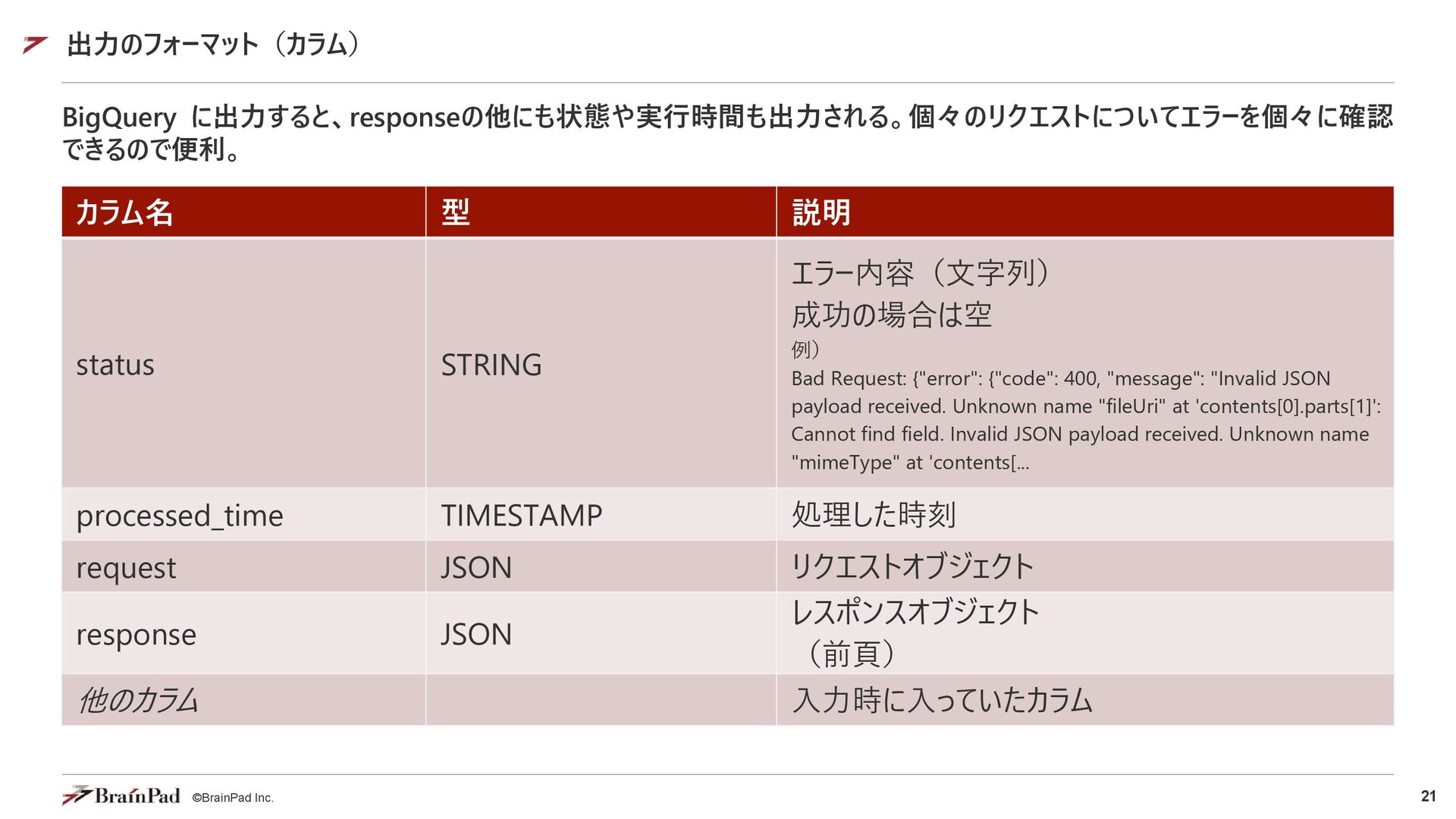
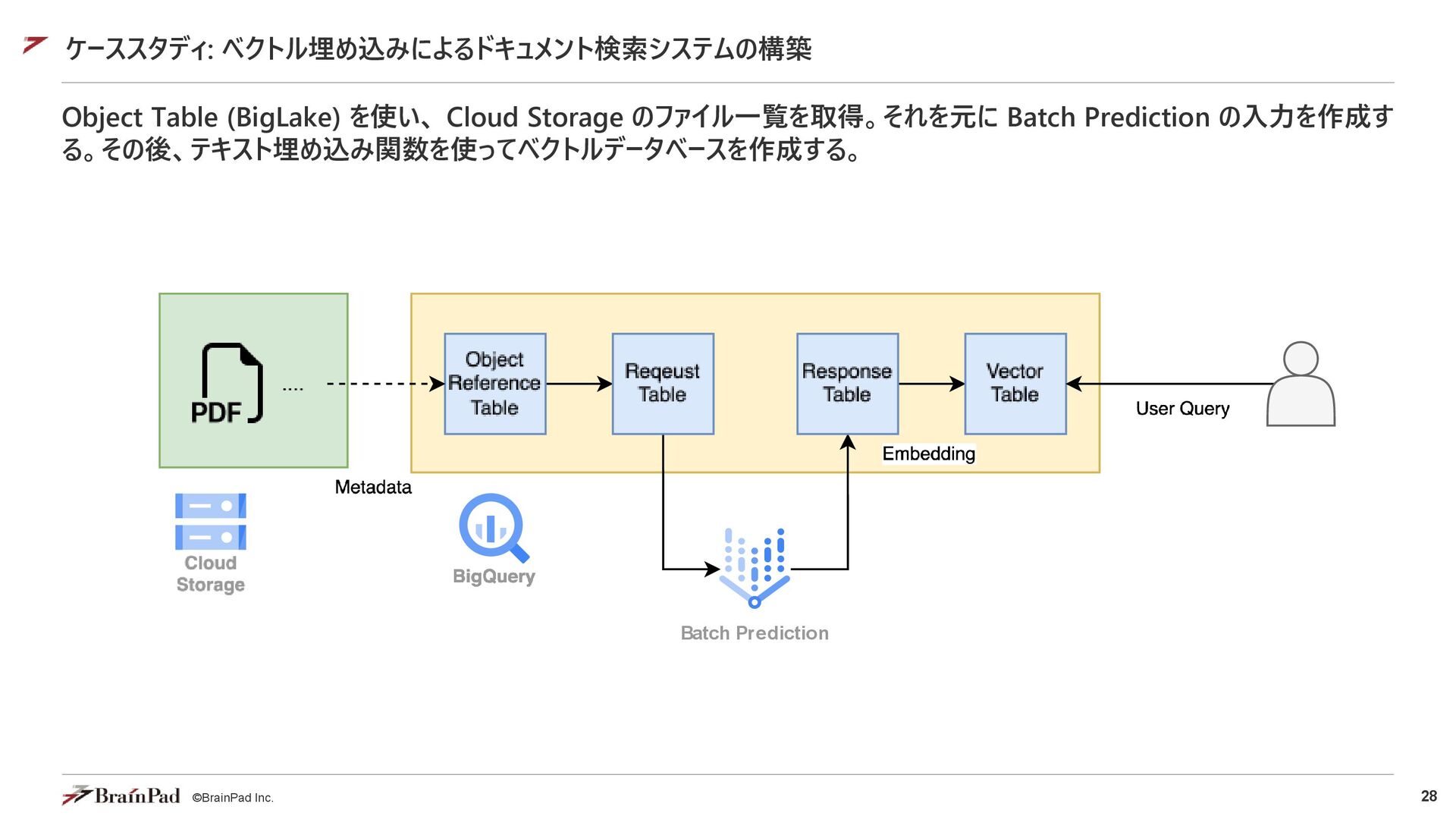
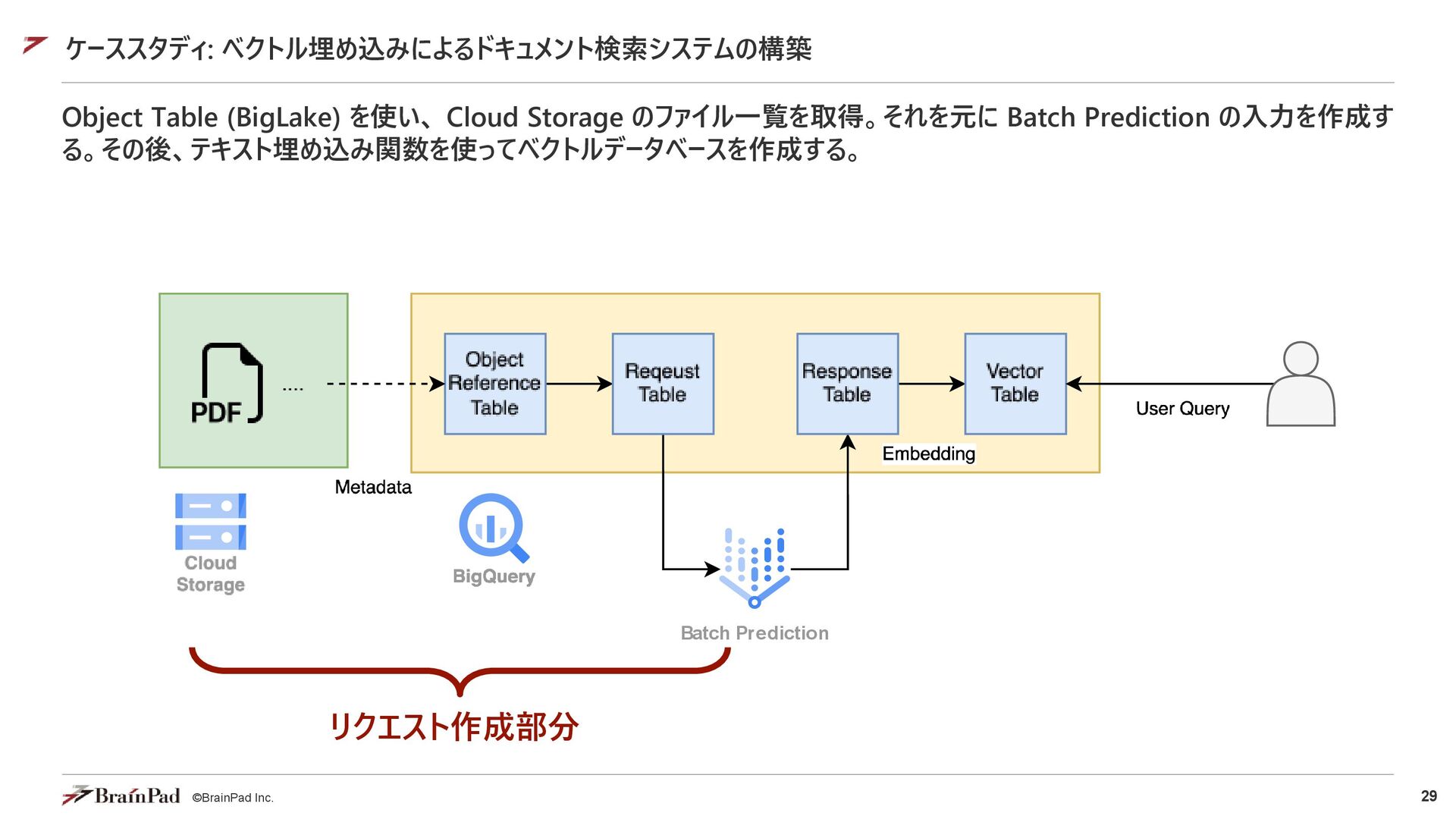
{"contents": [{"role": "user", "parts": [{"text": "この画像について説明してください。"}, {"fileData": {"mimeType": "image/jpeg", "fileUri": "gs://my-bucket/image1.jpg"}}]}]} {"contents": [{"role": "user", "parts": [{"text": "この動画を要約してください。"}, {"fileData": {"mimeType": "video/mp4", "fileUri": "gs://my-bucket/movie1.mp4"}}]}]} // Web上のファイル指定 {"contents": [{"role": "user", "parts": [{"text": "この画像について説明してください。"}, {"fileData": {"mimeType": "image/jpeg", "fileUri": "https://domain.name/image1.jpg"}}]}]} {"contents": [{"role": "user", "parts": [{"text": "この動画を要約してください。"}, {"fileData": {"mimeType": "video/mp4", "fileUri": "https://domain.name/movie1.mp4"}}]}]} 対応ファイルタイプ (Pro 2.5) • 画像 PNG, JPEG, WebP • 文章 PDF, プレーンテキスト • 音声 AAC, FLAC, MP3, M4A, MPEG Audio, MPGA, MP4 Audio, Opus, PCM, WAV, WebM Audio • 映像 FLV, QuickTime, MPEG Video, MP4, WebM Video, WMV, 3GPP
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
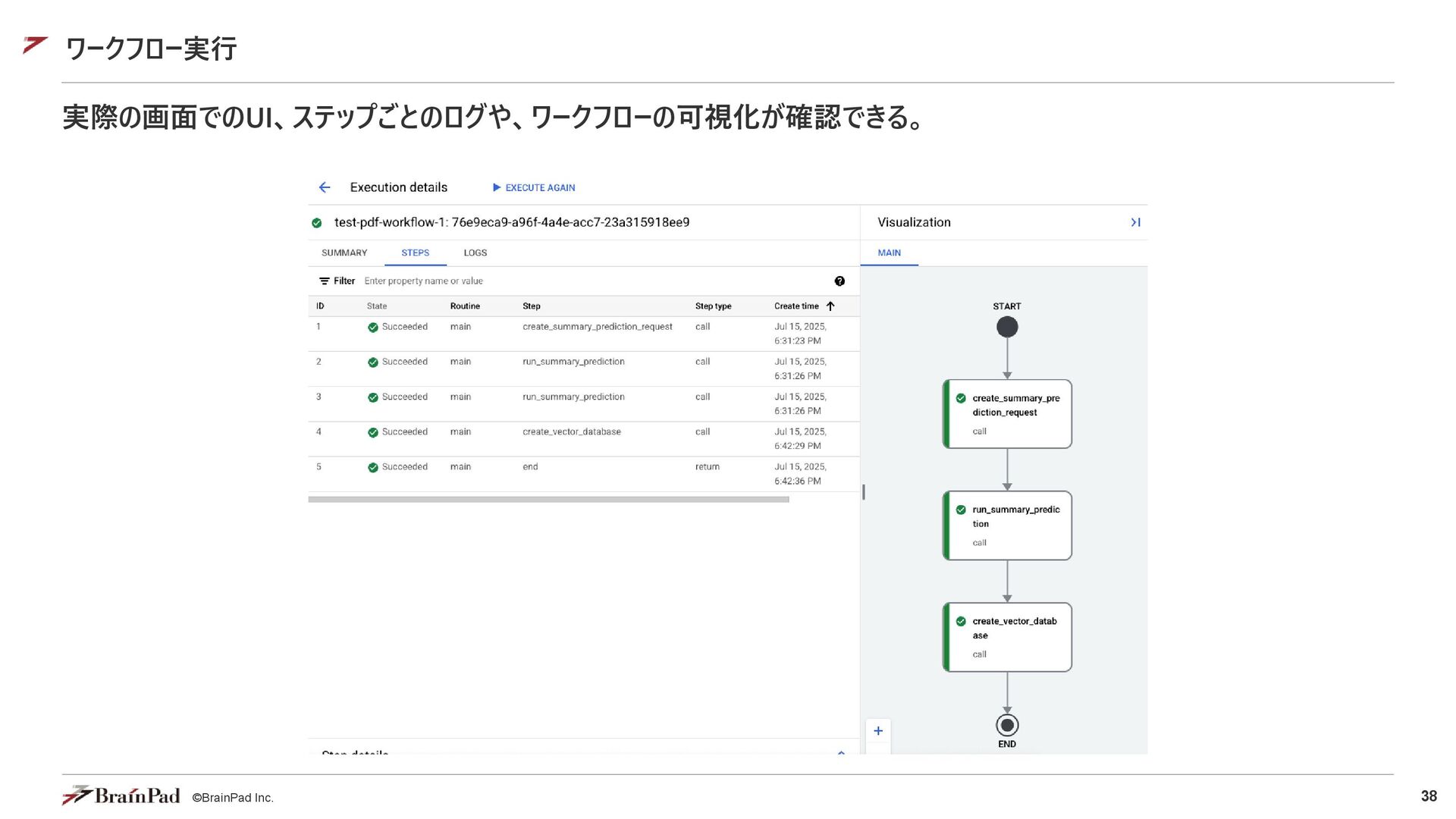{kind=link}
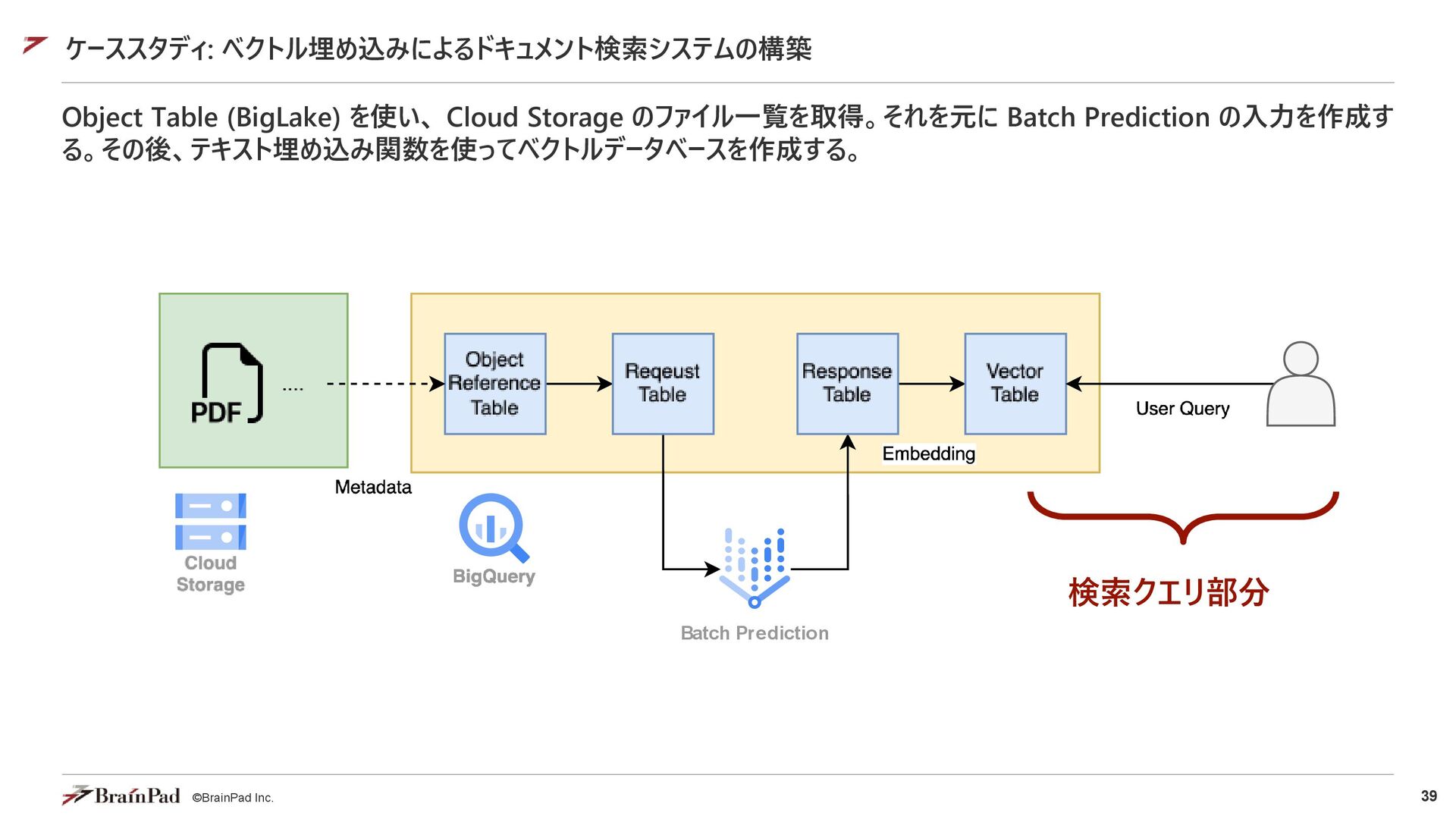{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![株式会社ブレインパッド 106-0032 東京都港区六本木三丁目1番1号 六本木ティーキューブ TEL:03-6721-7002 FAX:03-6721-7010 www.brainpad.co.jp [email protected] 本資料は、未刊行文書として日本及び各国の著作権法に基づき保護されております。また、株式会社ブレインパッドによる書面での許可なく、それら情報の一部または全文を使用または公開することは、いかなる場合も禁じられております。 ©BrainPad](https://files.speakerdeck.com/presentations/7df7e5ab69f441fea3df53b7ca6b679d/slide_44.jpg){kind=link}