memory-mapped files i.e. read-through write-through memory caching. • Runs nearly everywhere • Data serialized as BSON (fast parsing) • Full support for primary & secondary indexes • Document model = less work
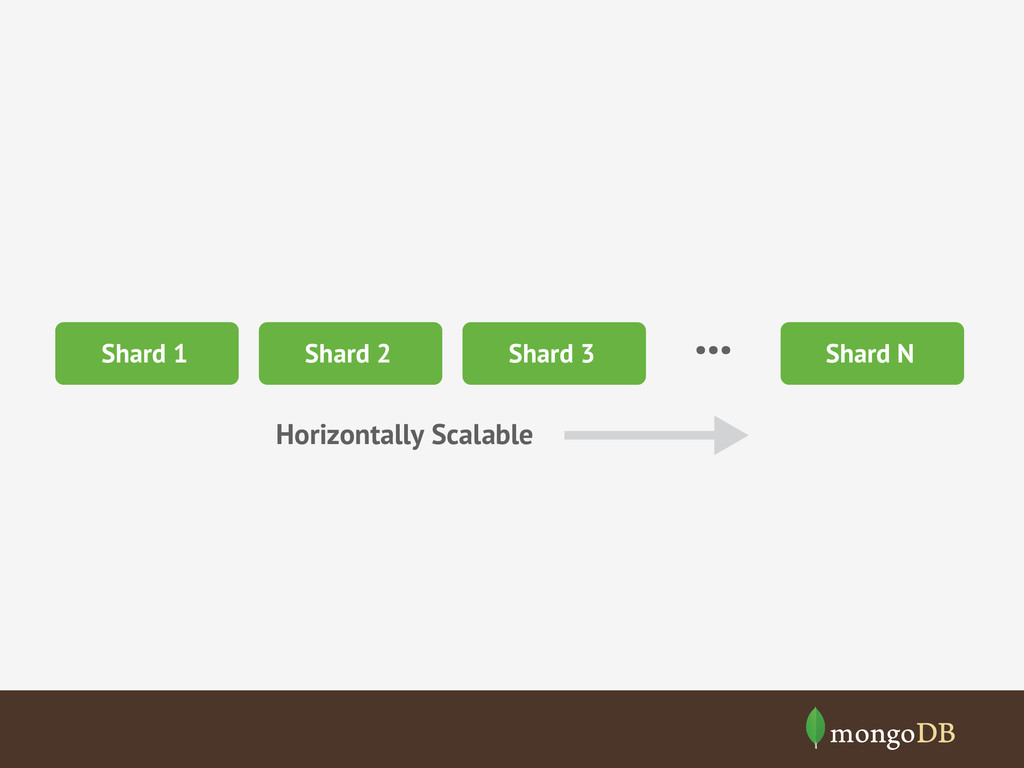
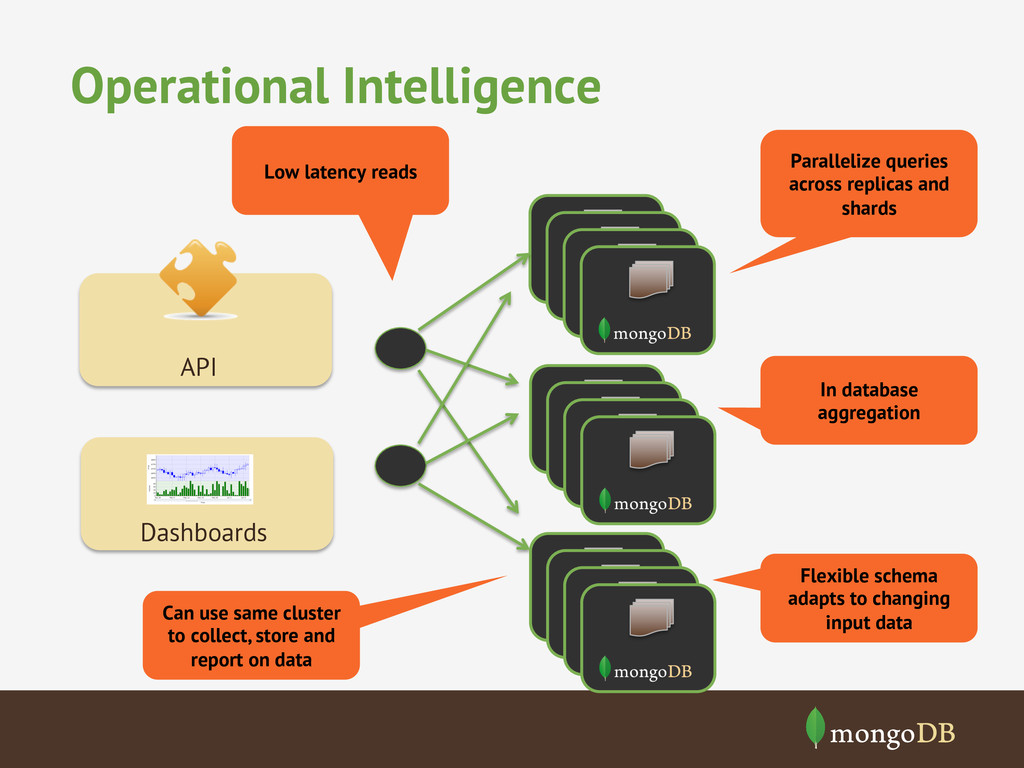
Sparse data • Semi-structured data • Agile development High Data Throughput • Reads • Writes Big Data • Aggregate Data Size • Number of Objects Low Latency • For reads and writes • Millisecond Latency Cloud Computing • Runs everywhere • No special hardware Commodity Hardware • Ethernet • Local data storage • JSON Based • Dynamic Schemas • Replica Sets to scale reads • Sharding to scale writes • 1000s of shards in a single DB • Data partitioning • Designed for “typical” OS and local file system • Scale-out to overcome hardware limitations • In-memory cache • Scale-out working set
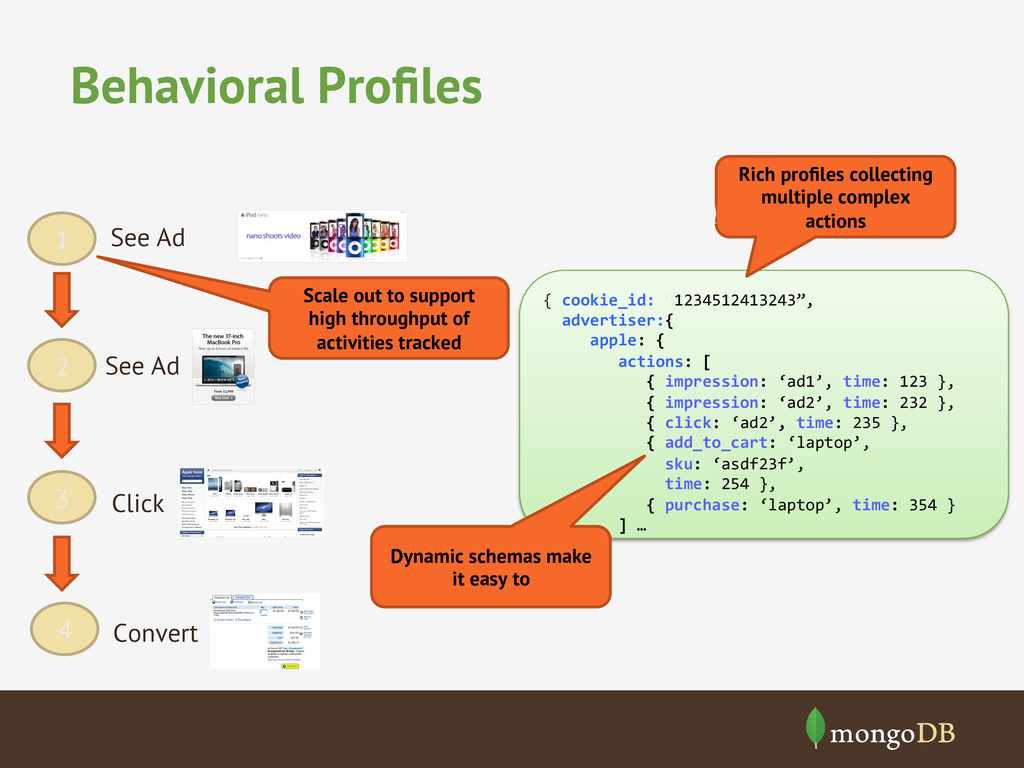
data • Variably structured Machine Generated Data • High frequency trading • Daily closing price Securities Data • Multiple data sources • Each changes their format consistently • Student Scores, Telecom logs Social Media
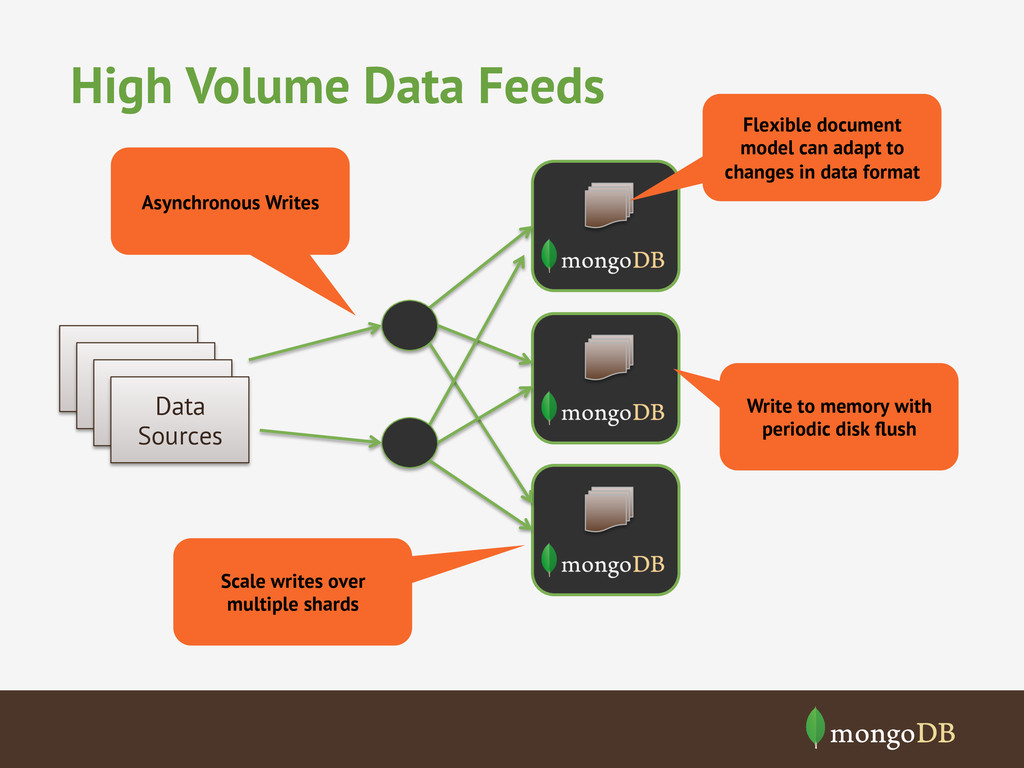
model can adapt to changes in data format Write to memory with periodic disk flush Data Sources Data Sources Data Sources Scale writes over multiple shards
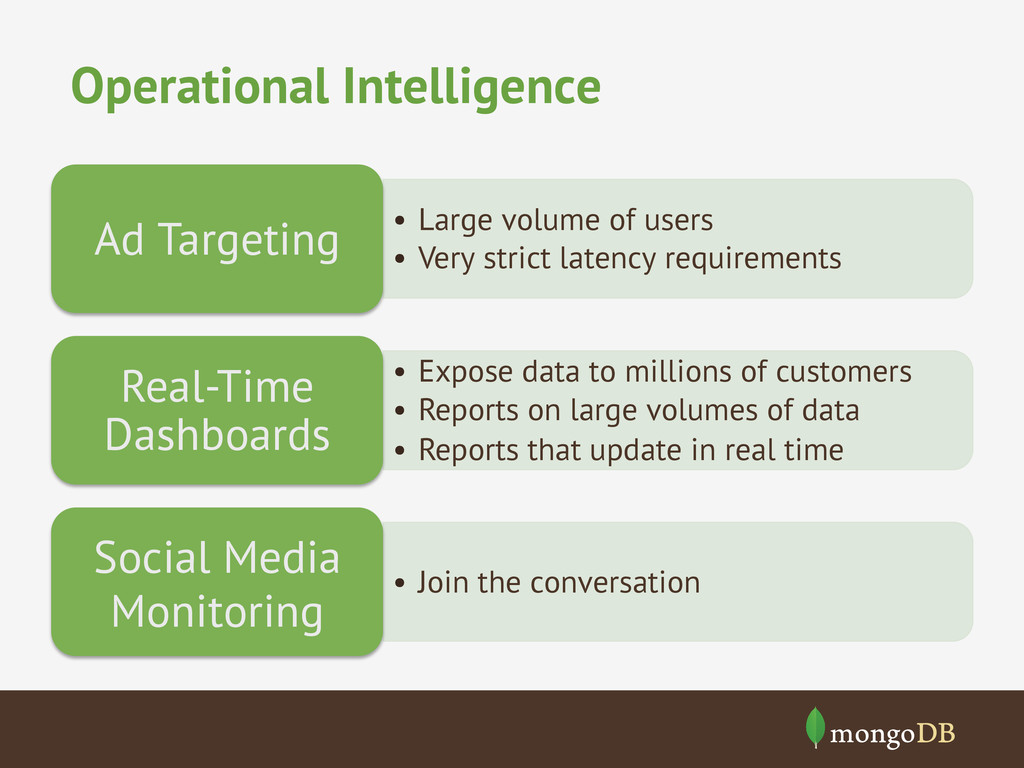
latency requirements Ad Targeting • Expose data to millions of customers • Reports on large volumes of data • Reports that update in real time Real-Time Dashboards • Join the conversation Social Media Monitoring
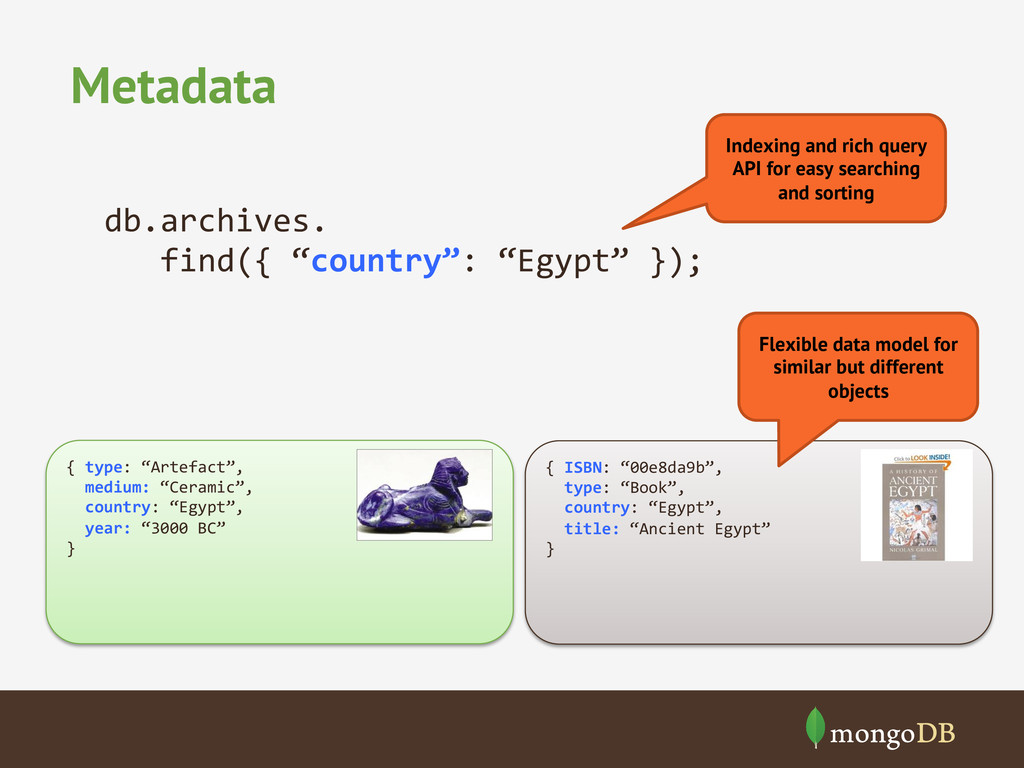
country: “Egypt”, title: “Ancient Egypt” } { type: “Artefact”, medium: “Ceramic”, country: “Egypt”, year: “3000 BC” } Flexible data model for similar but different objects Indexing and rich query API for easy searching and sorting db.archives. find({ “country”: “Egypt” });
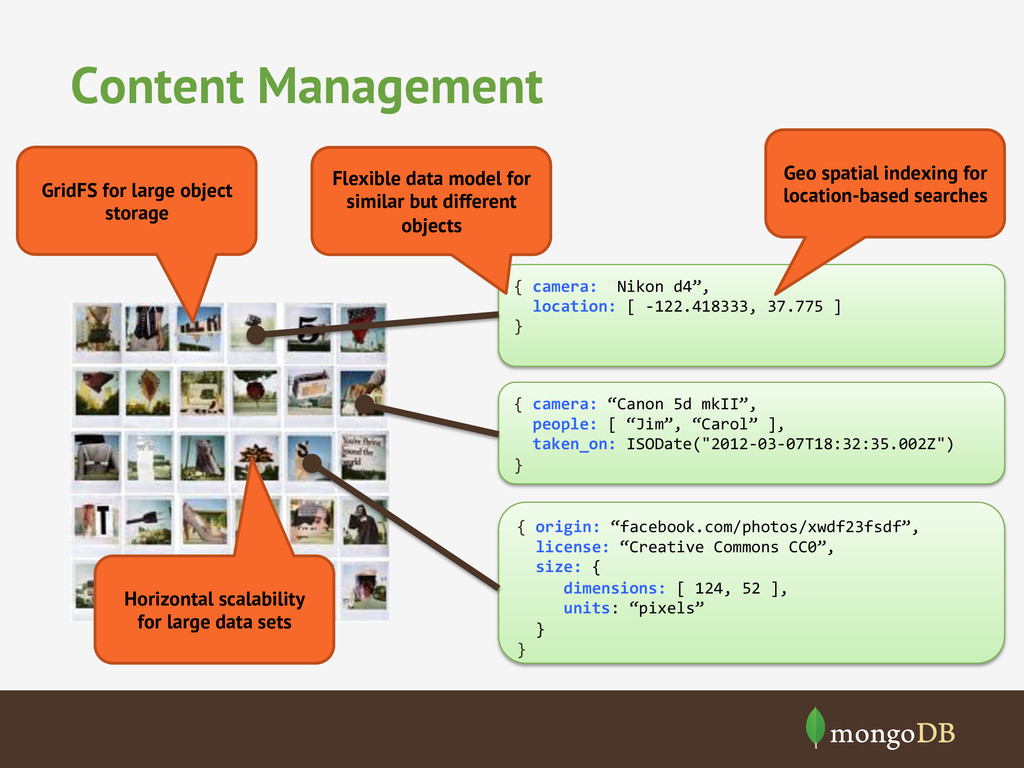
of content, layout News Site • Generate layout on the fly • No need to cache static pages Multi-device rendering • Store large objects • Simpler modeling of metadata Sharing
-‐122.418333, 37.775 ] } { camera: “Canon 5d mkII”, people: [ “Jim”, “Carol” ], taken_on: ISODate("2012-‐03-‐07T18:32:35.002Z") } { origin: “facebook.com/photos/xwdf23fsdf”, license: “Creative Commons CC0”, size: { dimensions: [ 124, 52 ], units: “pixels” } } Flexible data model for similar but different objects Horizontal scalability for large data sets Geo spatial indexing for location-based searches GridFS for large object storage
of objects to store Sharding lets you split objects across multiple servers High write or read throughput Sharding + Replication lets you scale read and write traffic across multiple servers Low latency access Memory mapped storage engine caches documents in RAM, enabling in-memory performance. Data locality of documents can significantly improve latency over join-based approaches Variable data in objects Dynamic schema and JSON data model enable flexible data storage without sparse tables or complex joins Cloud based deployment Sharding and replication let you work around hardware limitations in clouds.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}