An Introduction to the Theano and Lasagne libraries for Deep Learning. Accompanying material for the Deep Learning - Advanced Techniques tutorial at PyData London 2016, May 6th.
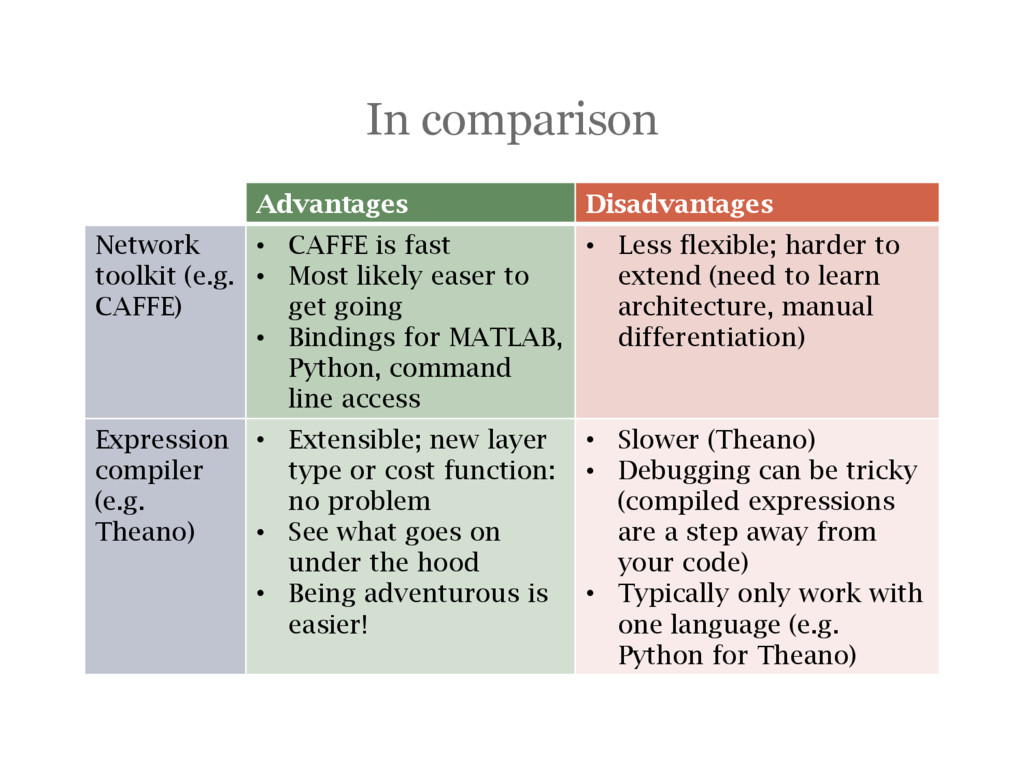
is fast • Most likely easer to get going • Bindings for MATLAB, Python, command line access • Less flexible; harder to extend (need to learn architecture, manual differentiation) Expression compiler (e.g. Theano) • Extensible; new layer type or cost function: no problem • See what goes on under the hood • Being adventurous is easier! • Slower (Theano) • Debugging can be tricky (compiled expressions are a step away from your code) • Typically only work with one language (e.g. Python for Theano)
it into Theano shared variables • Create a Theano expression representing matrix multiplication • Evaluate a the matrix multiplication expression to get the result
lasagne.utils import floatX a = floatX(np.arange(10).reshape((2,5))) b = floatX(np.arange(10,20).reshape((5,2))) a_t = theano.shared(a, name=‘a’) b_t = theano.shared(b) ab_t = T.dot(a_t, b_t) print(ab_t.eval()) Create some data to work with. Note: floatX converts to appropriate type, e.g. float32 for GPU.
lasagne.utils import floatX a = floatX(np.arange(10).reshape((2,5))) b = floatX(np.arange(10,20).reshape((5,2))) a_t = theano.shared(a, name=‘a’) b_t = theano.shared(b) ab_t = T.dot(a_t, b_t) print(ab_t.eval()) Call the eval method to evaluate the expression and get the result.
Set the contents of the Theano shared variables to randomly generated matrices • Show how the existing matrix multiplication expression can be evaluated to get the new result
that will take a value passed as an argument to a Theano function • Theano functions act just like Python functions; you specify the arguments and the expression whose result should be returned.
b = theano.shared(floatX(np.zeros((2,)))) linear = T.dot(x, W) + b eval_linear = theano.function([x], linear) data_x = floatX(rng.uniform(0, 1, (10,5))) print(data_x) print(eval_linear(data_x)) Create a seeded random number generator
b = theano.shared(floatX(np.zeros((2,)))) linear = T.dot(x, W) + b eval_linear = theano.function([x], linear) data_x = floatX(rng.uniform(0, 1, (10,5))) print(data_x) print(eval_linear(data_x)) Create an input variable for a simple linear model of shape (sample, channel)
b = theano.shared(floatX(np.zeros((2,)))) linear = T.dot(x, W) + b eval_linear = theano.function([x], linear) data_x = floatX(rng.uniform(0, 1, (10,5))) print(data_x) print(eval_linear(data_x)) Create parameters (weights and biases) for the linear model, as shared data
b = theano.shared(floatX(np.zeros((2,)))) linear = T.dot(x, W) + b eval_linear = theano.function([x], linear) data_x = floatX(rng.uniform(0, 1, (10,5))) print(data_x) print(eval_linear(data_x)) Create a Theano function that accepts data into the variable x and returns the model’s output
b = theano.shared(floatX(np.zeros((2,)))) linear = T.dot(x, W) + b eval_linear = theano.function([x], linear) data_x = floatX(rng.uniform(0, 1, (10,5))) print(data_x) print(eval_linear(data_x)) Example data for variable x
b = theano.shared(floatX(np.zeros((2,)))) linear = T.dot(x, W) + b eval_linear = theano.function([x], linear) data_x = floatX(rng.uniform(0, 1, (10,5))) print(data_x) print(eval_linear(data_x)) Evaluate model by calling the eval_linear function that was created by Theano
y)**2).mean() d_grad_d_W = T.grad(loss, wrt=W) d_grad_d_b = T.grad(loss, wrt=b) updates = {W: W - d_grad_d_W * lr, b: b - d_grad_d_b * lr} train_linear = theano.function([x, y, lr], loss, updates=updates) << continued in next code block >> Theano can symbolically compute gradient for us; gradient of loss w.r.t. W and b (weight and bias). THIS IS A HUGE EFFORT AND BUG SAVER.
y)**2).mean() d_grad_d_W = T.grad(loss, wrt=W) d_grad_d_b = T.grad(loss, wrt=b) updates = {W: W - d_grad_d_W * lr, b: b - d_grad_d_b * lr} train_linear = theano.function([x, y, lr], loss, updates=updates) << continued in next code block >> Dictionary representing updates of W and b according to stochastic gradient descent (SGD)
y)**2).mean() d_grad_d_W = T.grad(loss, wrt=W) d_grad_d_b = T.grad(loss, wrt=b) updates = {W: W - d_grad_d_W * lr, b: b - d_grad_d_b * lr} train_linear = theano.function([x, y, lr], loss, updates=updates) << continued in next code block >> Training function that computes loss and updates W and b parameters.
previous code block >> data_y = floatX(rng.uniform(0, 1, (10,2))) for i in xrange(1000): l = train_linear(data_x, data_y, 0.01) print(eval_linear(data_x)) Example data for target variable y.
previous code block >> data_y = floatX(rng.uniform(0, 1, (10,2))) for i in xrange(1000): l = train_linear(data_x, data_y, 0.01) print(eval_linear(data_x)) SGD training iterations; will evaluate loss and update parameters to minimise it.
previous code block >> data_y = floatX(rng.uniform(0, 1, (10,2))) for i in xrange(1000): l = train_linear(data_x, data_y, 0.01) print(eval_linear(data_x)) Evaluate model
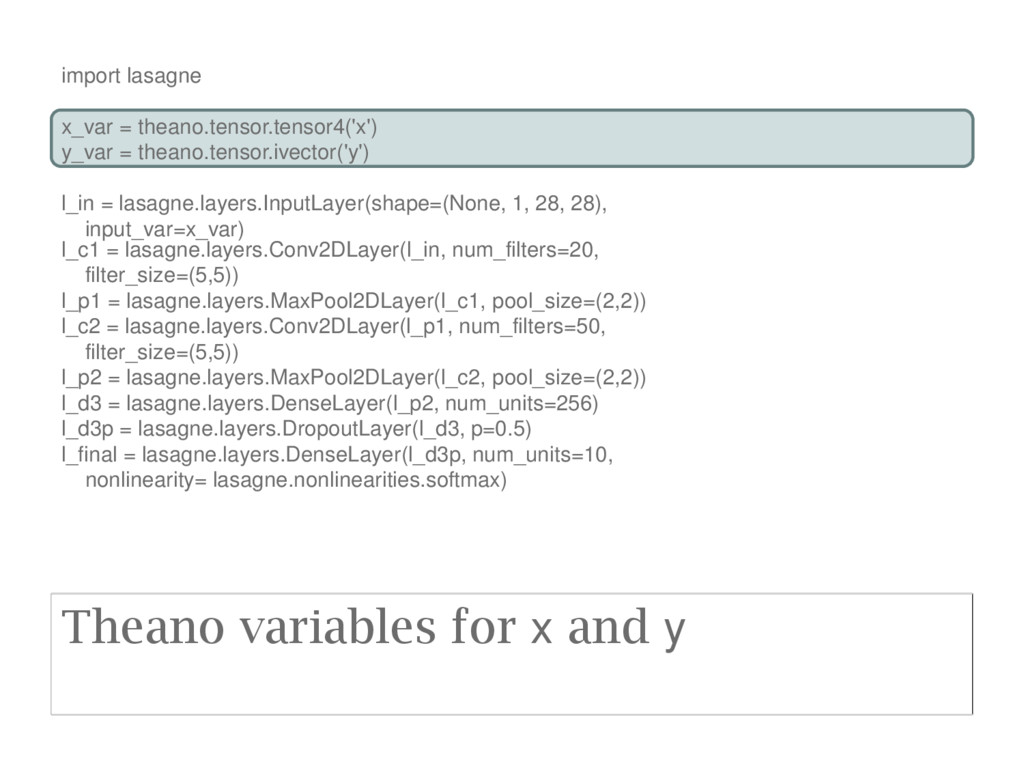
output • Define loss expression • Get trainable parameters of network • Generate updates for training network acccording to Nesterov Momentum update rule • Create Theano functions for training and prediction
trainable=True) updates = lasagne.updates.nesterov_momentum(train_loss.mean(), params, learning_rate=0.01, momentum=0.9) eval_pred = lasagne.layers.get_output(l_final, deterministic=True) eval_loss = lasagne.objectives.categorical_crossentropy(eval_pred, y_var) train_fn = theano.function([x_var, y_var], train_loss.sum(), updates=updates) eval_fn = theano.function([x_var, y_var], eval_loss.sum()) pred_prob_fn = theano.function([x_var], eval_pred) Get expression for final layer output (predicted probabilities) during evaluation time, with dropout OFF (deterministic=True results in a Theano expression that excludes stochastic processes e.g. dropout). Then get evaluation loss.
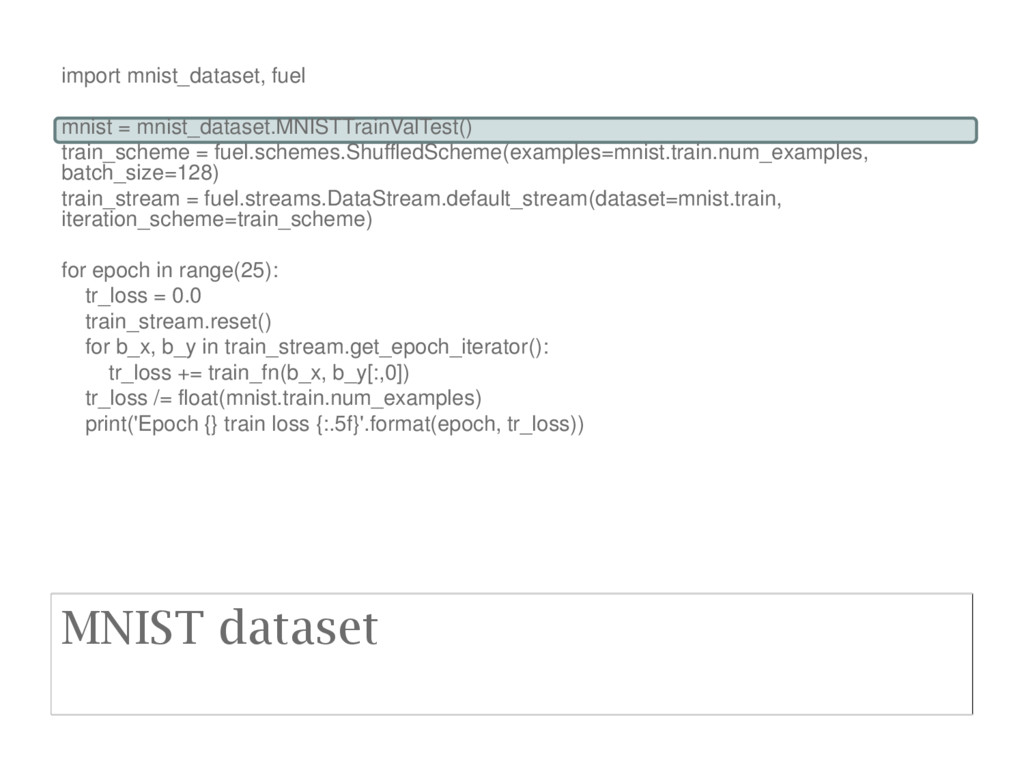
train_stream = fuel.streams.DataStream.default_stream(dataset=mnist.train, iteration_scheme=train_scheme) for epoch in range(25): tr_loss = 0.0 train_stream.reset() for b_x, b_y in train_stream.get_epoch_iterator(): tr_loss += train_fn(b_x, b_y[:,0]) tr_loss /= float(mnist.train.num_examples) print('Epoch {} train loss {:.5f}'.format(epoch, tr_loss)) For each epoch, initialise training loss sum to 0 and reset data stream to beginning
train_stream = fuel.streams.DataStream.default_stream(dataset=mnist.train, iteration_scheme=train_scheme) for epoch in range(25): tr_loss = 0.0 train_stream.reset() for b_x, b_y in train_stream.get_epoch_iterator(): tr_loss += train_fn(b_x, b_y[:,0]) tr_loss /= float(mnist.train.num_examples) print('Epoch {} train loss {:.5f}'.format(epoch, tr_loss)) For each mini-batch, remove dimension 1 from y and pass x and y to training function
train_stream = fuel.streams.DataStream.default_stream(dataset=mnist.train, iteration_scheme=train_scheme) for epoch in range(25): tr_loss = 0.0 train_stream.reset() for b_x, b_y in train_stream.get_epoch_iterator(): tr_loss += train_fn(b_x, b_y[:,0]) tr_loss /= float(mnist.train.num_examples) print('Epoch {} train loss {:.5f}'.format(epoch, tr_loss)) Get mean loss and report epoch results
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![train_linear = theano.function([x, y, lr], loss, updates=updates) << continued from](https://files.speakerdeck.com/presentations/85eaa6eaf902434687bf039f951545b2/slide_39.jpg){kind=link}
![train_linear = theano.function([x, y, lr], loss, updates=updates) << continued from](https://files.speakerdeck.com/presentations/85eaa6eaf902434687bf039f951545b2/slide_40.jpg){kind=link}
![train_linear = theano.function([x, y, lr], loss, updates=updates) << continued from](https://files.speakerdeck.com/presentations/85eaa6eaf902434687bf039f951545b2/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}