In this talk, we will present our ongoing work introducing computational thinking to humanists as part of the Computational Thinking and Learning Initiative (CTLI) at Vanderbilt University. Our approach was specifically tailored toward text analysis and exploring how quantitative approaches can complement existing qualitative techniques in literary scholarship. We found blocks-based programming effective in supporting a powerful paradigm of interaction and facilitated a deep understanding of the content. Furthermore, we explored the use of a blocks-based environment to facilitate the integration of a diverse set of related tools including data storage and exploration.
For more information, check out https://medium.com/swlh/teaching-text-mining-online-dfd94926b18e
{kind=link}
{kind=link}
{kind=link}
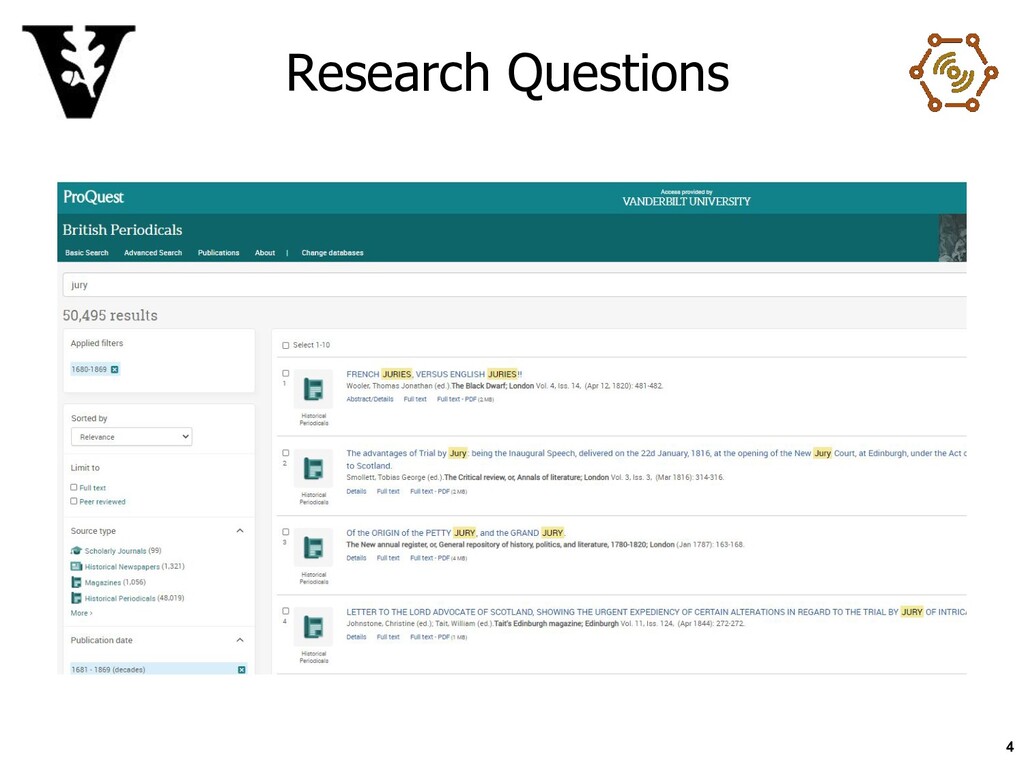{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}